通用增量数据同步方案
通用增量数据同步方案
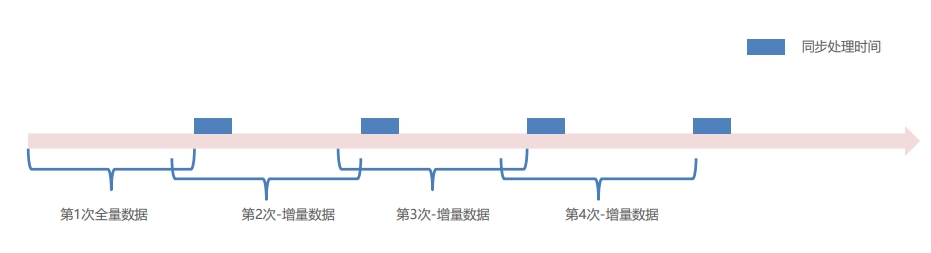
同步处理时间
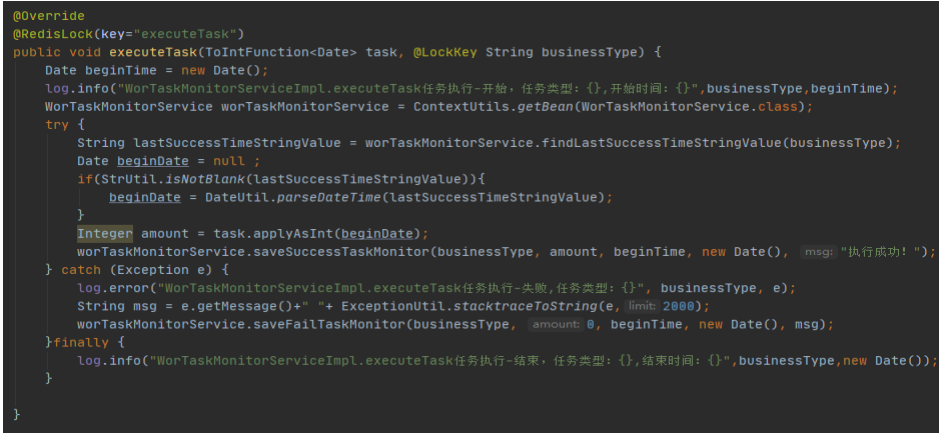
① 每次增量同步时间为上一次同步成功的开始时间往前推5分钟。而不是同步成功的结束时间(往前推5分钟的目的是避免服务方数据落地事务
延迟导致的数据丢失问题);
② 是否需要开启事务:评估如果部分失败不影响系统功能和业务,则同步任务不需要开启事务,避免大事务连接超时,主从同步等问题;
③ 数据查询需要做分页查询,避免数据量过大导致内存溢出或者请求超时等问题;
④ 分页查询需要按照有序的、没有重复数据的、而且不会发生变化的字段进行升序排序,比如,自增id(否则会导致数据丢失或者重复等问
题);
⑤ 使用增量同步数据的前提是:数据源每次的数据变化必须都更新最后更改时间,记录的删除采用逻辑删除(is_deleted=N/Y)。
通用增量数据同步方案-数据丢失问题1
因排序不当导致数据丢失/重复的情况演绎:按照last_update_date排序

解决:按照id这种有序的而且字段值不会重复和发生变化的字段进行排序。
通用增量数据同步方案-数据丢失问题2
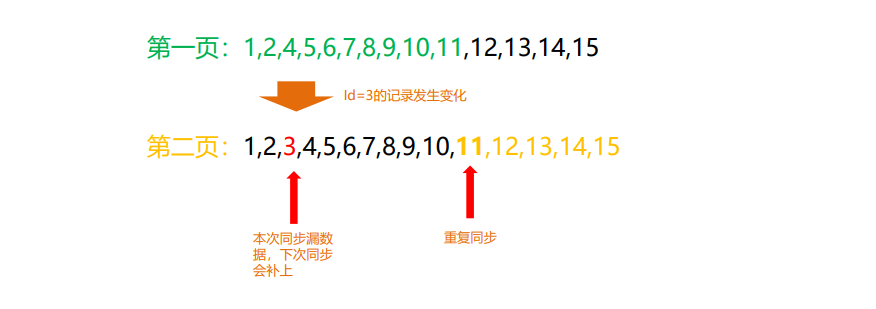
结论:不会丢失。因为Id=3的记录最后更改时间其实是大于本次同步
的开始时间,在下一次同步的时候这条记录会被捞取到。
解决方案演绎:通过Id排序
通用增量数据同步方案-数据丢失问题3
数据源应用中,数据落地延迟导致数据丢失的情况演绎:
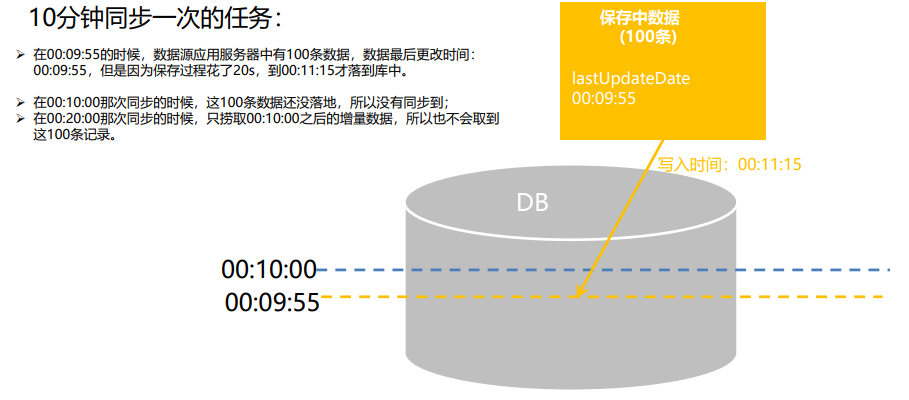
解决:每次同步的时间设置为上次的同步开始时间再往前推5分钟。
分页查询性能问题解决方案
问题:MySQL并不是跳过offset行,而是取offset+N行,然后放弃前offset行,返回N行,
那当offset特别大的时候,效率就非常的低下,要么控制返回的总页数,要么对超过特定阈
值的页数进行SQL改写
解决:先快速定位分页数据对应的id,再根据id关联取得对应的行数据。
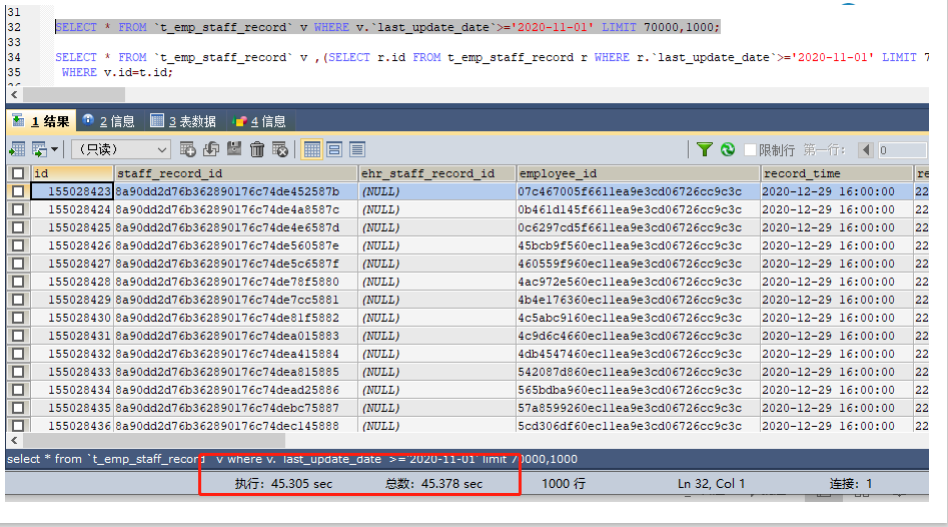
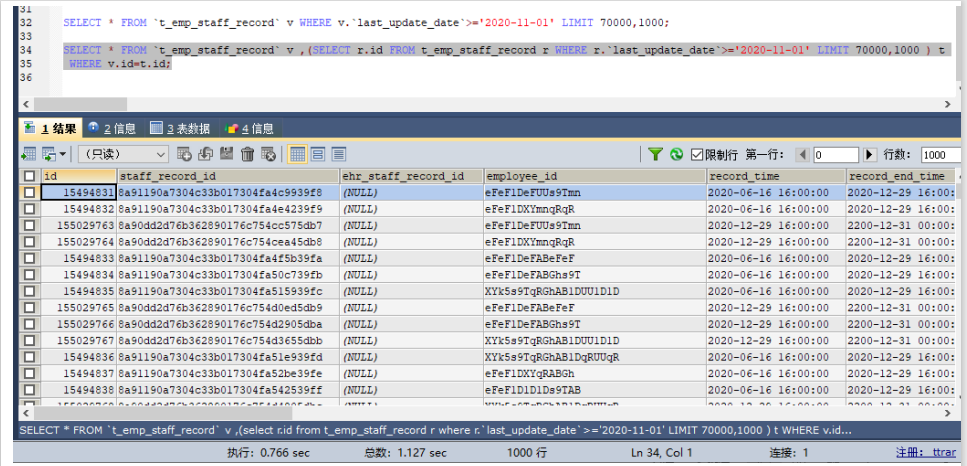
通过索引index_last_update_date直接查找到id,不需要回表,所以定位到这1000个id是很快的。再按照这1000个
id拿1000条数据,这是按照主键索引取得,性能也不错。整个处理方式避免了查询过程中大量的IO,从而提高查
询性能。
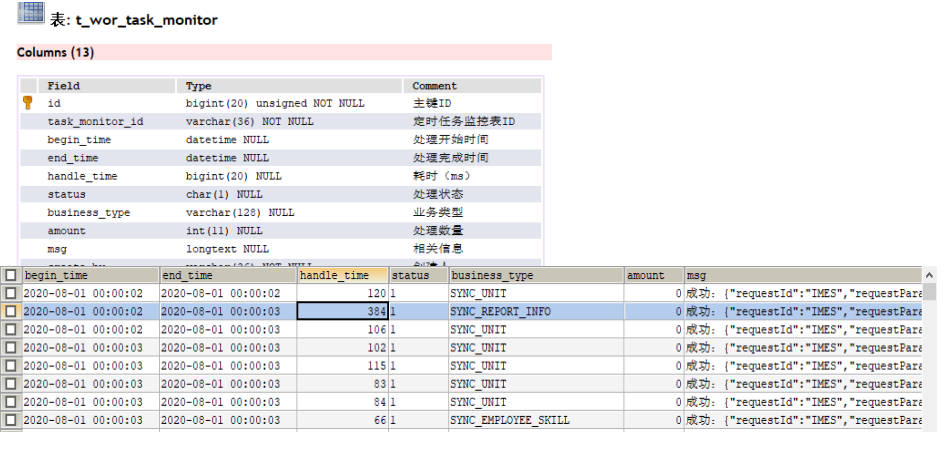
增量同步记录表设计
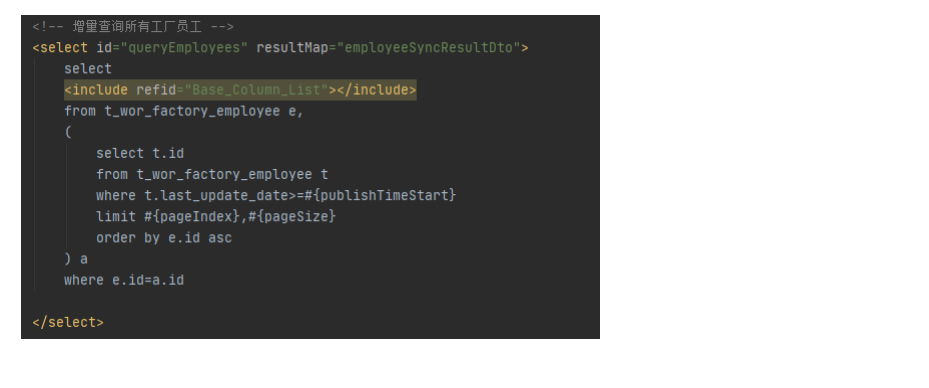
增量同步例子-分页小批量处理

增量同步例子-数据源查询
其他同步方案

 浙公网安备 33010602011771号
浙公网安备 33010602011771号