从c代码到可执行文件
概述:针对c/cpp从代码到可执行文件的一个简单剖析。
序
技术的发展,总是越来越好的,因为人是越来越卷的,没办法。简单日常,windows编程c或者cpp,在vs中一键运行,代码就跑起来了,就可以在debug或者release目录找到可执行文件了;在linux中,就要比windows稍微复杂点,但也是编辑-gcc编译,然后运行。windows有IDE,linux有好的命令体系,总之,实现起来都不复杂。那这些个简单动作的底层是怎样的呢?这就是下面的具体内容宗旨。
简单的拆解
如下是一个Hello, world代码:
#include <stdio.h>
int main() {
printf("Hello, world.\n");
return 0;
}
然后执行命令,生成可执行文件,然后运行:
PS D:\Desktop> gcc hello.c -o hello
PS D:\Desktop> ls
目录: D:\Desktop
Mode LastWriteTime Length Name
---- ------------- ------ ----
-a---- 2023/5/26 0:24 83 hello.c
-a---- 2023/5/26 0:25 54022 hello.exe
PS D:\Desktop> ./hello
Hello, world.
PS D:\Desktop>
命令行跑起来就这样,编译、运行,放在vs这IDE中就是简单的点一下运行了。
拆解
一个可执行文件,在windows中就是一个exe后缀文件,但在linux中没有那么多限制(也有说是ELF文件),但一个共同的地方就是,为了能在CPU中跑起来,文件必须是机器指令集,所以编译就是一个得到机器指令集的过程。早期,为了克服编写机器指令的麻烦,就出现了汇编语言,它把机器指令和人们的常用语句做了个映射,如下:
pushq %rbp
.seh_pushreg %rbp
movq %rsp, %rbp
这样,编程语言就算开始了第一步迈进,直至现在的c/cpp高级语言。现在的c/cpp已经相当接近人类的自然语言(当然是英语角度),完成自然语言向机器指令的转译工作的,就是编译器了,现在编译器要进行的阶段分别是预编译阶段、编译阶段,汇编阶段,但这样还不够,经历长期的工作检验,c/cpp就有了标准库,所以在汇编完成后得到目标文件以后,还需要进行链接,把库文件和目标文件进行链接,最后才得到可执行文件。
预编译阶段,预编译也常被称为预处理,主要进行的工作是把include包含的头文件中的声明和在代码中的位置进行更替也就是拓展include头文件位置为头文件声明,如果有函数定义当然就包含进去,如果没有,那就只是简单声明;除此以外就是宏替换,把代码文件中定义的宏和后面的使用进行替换扩展,还有注释的删除以及条件编译指令的处理。这一步可以使用命令:gcc -E hello.c -o hello.i,把上面的示例代码预处理一下,查看一下:
# 1 "hello.c"
# 1 "<built-in>"
# 1 "<command-line>"
# 1 "hello.c"
# 1 "D:/software/mingw-w64/x86_64-w64-mingw32/include/stdio.h" 1 3
# 9 "D:/software/mingw-w64/x86_64-w64-mingw32/include/stdio.h" 3
# 1 "D:/software/mingw-w64/x86_64-w64-mingw32/include/crtdefs.h" 1 3
# 10 "D:/software/mingw-w64/x86_64-w64-mingw32/include/crtdefs.h" 3
# 1 "D:/software/mingw-w64/x86_64-w64-mingw32/include/_mingw.h" 1 3
# 12 "D:/software/mingw-w64/x86_64-w64-mingw32/include/_mingw.h" 3
# 1 "D:/software/mingw-w64/x86_64-w64-mingw32/include/_mingw_mac.h" 1 3
# 98 "D:/software/mingw-w64/x86_64-w64-mingw32/include/_mingw_mac.h" 3
# 107 "D:/software/mingw-w64/x86_64-w64-mingw32/include/_mingw_mac.h" 3
# 13 "D:/software/mingw-w64/x86_64-w64-mingw32/include/_mingw.h" 2 3
# 1 "D:/software/mingw-w64/x86_64-w64-mingw32/include/_mingw_secapi.h" 1 3
# 14 "D:/software/mingw-w64/x86_64-w64-mingw32/include/_mingw.h" 2 3
# 282 "D:/software/mingw-w64/x86_64-w64-mingw32/include/_mingw.h" 3
# 1 "D:/software/mingw-w64/x86_64-w64-mingw32/include/vadefs.h" 1 3
# 9 "D:/software/mingw-w64/x86_64-w64-mingw32/include/vadefs.h" 3
# 1 "D:/software/mingw-w64/x86_64-w64-mingw32/include/_mingw.h" 1 3
# 578 "D:/software/mingw-w64/x86_64-w64-mingw32/include/_mingw.h" 3
# 1 "D:/software/mingw-w64/x86_64-w64-mingw32/include/sdks/_mingw_directx.h" 1 3
# 579 "D:/software/mingw-w64/x86_64-w64-mingw32/include/_mingw.h" 2 3
# 1 "D:/software/mingw-w64/x86_64-w64-mingw32/include/sdks/_mingw_ddk.h" 1 3
# 580 "D:/software/mingw-w64/x86_64-w64-mingw32/include/_mingw.h" 2 3
# 10 "D:/software/mingw-w64/x86_64-w64-mingw32/include/vadefs.h" 2 3
中间省略一大堆
# 3 "hello.c"
int main(){
printf("Hello, world.\n");
return 0;
}
预处理展开后的代码过长,干脆把记录放在代码仓,虽然都是用的GNU规范的gcc进行编译,但系统的不同还是会使得生成有所差异,简单的差异。在vs中可以修改一下[项目属性],[c/c++]选项,点击[预处理器],把[预处理到文件]给确认一下为[是],再点击运行,项目debug目录就有.i文件了(一般修改以后点击运行会报错,不过.i文件还是可以生成的,个人也不知道为何,要正常使用改回来就是了)。
编译阶段,这一步主要针对c/cpp限定语法语义,在指定的语法语义下把预处理后代码转译为汇编代码,很多的编译器优化针对的就是这里吧。很多语法上的问题,都是在这里检测出来的。命令执行为:gcc -S hello.i -o hello.s,然后代码又回归简单:
.file "hello.c"
.text
.def __main; .scl 2; .type 32; .endef
.section .rdata,"dr"
.LC0:
.ascii "Hello, world.\0"
.text
.globl main
.def main; .scl 2; .type 32; .endef
.seh_proc main
main:
pushq %rbp
.seh_pushreg %rbp
movq %rsp, %rbp
.seh_setframe %rbp, 0
subq $32, %rsp
.seh_stackalloc 32
.seh_endprologue
call __main
leaq .LC0(%rip), %rcx
call puts
movl $0, %eax
addq $32, %rsp
popq %rbp
ret
.seh_endproc
.ident "GCC: (x86_64-posix-seh-rev0, Built by MinGW-W64 project) 8.1.0"
.def puts; .scl 2; .type 32; .endef
在vs中,这部分可以在vs中进行反汇编查看,不过还不太熟练,简单做起来就是打断点,然后编译,然后[crtl+alt+D],就可以查看汇编码了。
汇编阶段,这部分负责的是把前面的汇编码转译为目标文件,得到包含了机器指令集合全局数据的目标文件,当然还有个很重要的隐藏信息。命令执行:gcc -c hello.s -o hello.o,这一步估计也是修改编译选项才能得到目标文件。
重要的链接
针对各种大量的重复使用的功能代码,很多人都会选择把它复用起来,比如c/cpp标准库,这种别人写好的功能库,一般都是以静态库或者动态库的形式出现,而非直接的源代码。链接步骤失败,就会出现"undefined reference to xxxx",这样的错误在windows中非常常见,准确来说就是vs中,这样的问题就是第三方库链接失败导致。那么链接器是如何进行工作的?
链接器工作原理
在上面的简单代码中,其实就只是调用了标准库中的输出语句printf,而在代码中,这样的外部引用,其实就相当于书本的标注,具体实现需要查看某某地址那样,而当链接器进行链接的时候,引用的标注必须有对应实现,否则就会报错。在前面,编译器处理printf这类外部引用的时候,为了方便后续的链接器工作,它会把源文件对外可用的或者外部引用的标识符进行记录,并存放在一张表保存在目标文件中,这个就是上面我说的隐藏信息。使用gcc进行链接的命令:gcc hello.o -o hello,也可以使用链接器ld。
到这里,.o目标文件的结构体就比较明了了,主要包含机器指令的代码区,包含全局变量的数据区以及方便链接的符号表信息,来检查一下文件结构:
jam@jam-ubuntu:~/Desktop/course$ size hello.o
text data bss dec hex filename
132 0 0 132 84 hello.o
jam@jam-ubuntu:~/Desktop/course$ size hello
text data bss dec hex filename
1376 600 8 1984 7c0 hello
size命令可以查看目标文件、可执行文件和库文件的信息,不同格式会有不同样式的展示,就上面的直接使用会默认格式为伯克利样式,所以text就是只读数据,也就是机器指令集,如果用的是GNU,只读数据就会展示在data栏且数据略有差异。另外想要使用readelf来检查文件信息,但篇幅过长,干脆上传到代码仓了,文件以record为后缀。通过对比可以发现,两者区别甚大。
注:还有一件事,很多时候代码中会定义各种各样五花八门的函数或者变量,但不一定会拿来用,有时候甚至只有声明而无定义,这些个函数或者变量在golang中就是unused,是会报错的,但在c/cpp中是可以存在的,除非你拿来用的时候只有声明而无定义。如下:
// 编译通过且能运行
#include <stdio.h>
void ff();
int main(){
printf("Hello, world.\n");
return 0;
}
//编译不通过
#include <stdio.h>
void ff();
int main(){
ff();
printf("Hello, world.\n");
return 0;
}
// ld直接报错:
/* PS D:\Desktop\GitHub\compilation-process> gcc hello.c -o hello
C:\Users\penta\AppData\Local\Temp\ccogx5wD.o:hello.c:(.text+0xe): undefined reference to `ff'
collect2.exe: error: ld returned 1 exit status */
这大概就是代码中的“言之须有物”了。
链接静态库和动态库
静态库文件在linux中就是以.a为后缀的文件,在windows中是以.lib为后缀的文件,主打大而全,这些个提前编译好的静态库文件在使用的时候,只需要把已经编译好的个人代码的目标文件和静态库进行链接即可,链接中,主要就是复制需要的静态库到可执行文件中,这样也可加快编译,不然每次项目构建都需要重新把可复用的库文件编译一次就太费劲了。要知道的是,静态库也是一个个目标文件,所以它们也是由代码区、数据区和符号表构成。编译时,抛开标准库,某些特定的静态库需要指定链接,比如一个使用到线程api的程序在编译时就需要指定l参数:gcc pthread_test.c -o pthread_test -lpthread,在vs中就是使用pragma来指定,比如winsock的使用:
#include <winsock2.h>
#pragma comment(lib, "Ws2_32.lib")
针对静态库的链接,c标准库几乎是所有c代码都会用到的,如同上面的hello.c例子,目标文件只是132的简单机器指令,但链接了标准库以后,就直接编程了1984,而且这只是一个简单代码,如果逻辑变得复杂项目结构随之变得庞大,最后得到的就是一个异常庞大的可执行文件,这么一个文件仅是放在硬盘中就很要命,更何况运行起来需要加载到内存中。除此以外,如果后续静态库有修改,那就需要重新编译静态库然后再链接生成可执行文件,工作量就很大。
针对这种情况的解决方案就是动态库,动态库在windows中被大规模使用,常常见到的就是某某软件运行因为缺失了某某.DLL文件而宕机,然后需要到微软官网去下载补丁。另外,在linux中,这些个动态库文件就是各种lib开头的.so文件。和静态库不同,静态库是在链接的时候把代码区和数据区给复制到可执行文件中,动态库则是在可执行文件中留下一部分库信息,比如库名、符号表以及定位信息,而不是全部代码和数据都丢到可执行文件中。
动态库的链接过程,是在可执行文件中保留了一部分定位信息,那这些信息什么时候派上用场?第一种情况就是在程序加载的时候,众所周知的是程序时运行在CPU的,所以在运行前需要进行加载,而这一步会有特定的加载器完成,并且检测程序是否有动态依赖,如果有就会另有动态链接器来进行动态库的信息确认,就是查户口看看这个动态库是否存在,没有就会出现windows中的经典报错,确认有的话就正常运行。通常会在编译的时候会有信息指定
gcc test.c test.so -o test,所以windows中各种软件的发布,安装路径下往往有着各种各样的DLL依赖,防止加载出错。这种依赖,也是插件的实现原理,在源码中声明那么几个函数,在插件中实现那么几个函数,那这个插件就可以编译成动态库从而供给软件主体调用。
第二种情况就是在程序运行的时候,这种情况往往需要使用dlopen、dlsym、dlclose等等函数镞来在代码中指定,后续在运行到特定位置才会出现加载,算是比较特殊。
就上面来看,无论动态库还是静态库,在运行的时候,往往都需要把使用的第三方库加载到CPU中,但相比静态库的所有文件都完整复制到可执行文件使得各种可执行文件都有着这么一份备份,动态库在系统中保留独一份,只在运行时才加载的情况,就显得很是节省硬盘空间了,因为各种需要使用到该动态库的可执行文件都共用一份动态库,只在运行时才加载,而且内存中只需要保留一份动态库代码,各种使用到该动态库的进程都可以共享这份代码资源,也节省了内存的空间。除此以外,当代码结构有所修改,就只需要修改库文件,然后重新编译生成一份.so文件即可,而不需要去动可执行文件。
不过动态库也有着自己的缺点,那就是因为动态库文件加载后,在内存中就只存在一份,而不是多份拷贝,所以它在进程结构的调用的时候,就不算是直接的内部执行,而是需要"跑出门"拿一下实现,再来执行对应代码,所以就会出现满一步的情况。所以具体的静态库还是动态库的实现方式,都得看具体情况。
编译自己的静态库动态库
上面介绍的很明了了,静态库和动态库实质上都是目标文件,只是编译方式有点不同,然后得到的不同的目标文件,那接下来就做一个自己的静态库和动态库,先在linux中跑一圈。下面是简单代码:
// sayhi.h
#include <stdio.h>
void sayhi();
// sayhi.c
#include "sayhi.h"
void sayhi(){
printf("Hi.\n");
}
//test.c
#include "sayhi.h"
int main(){
sayhi();
return 0;
}
编译运行一下:
jam@jam-ubuntu:~/Desktop/test$ vim sayhi.h
jam@jam-ubuntu:~/Desktop/test$ vim sayhi.c
jam@jam-ubuntu:~/Desktop/test$ vim test.c
jam@jam-ubuntu:~/Desktop/test$ ls
sayhi.c sayhi.h test.c
jam@jam-ubuntu:~/Desktop/test$ gcc test.c sayhi.c -o test
jam@jam-ubuntu:~/Desktop/test$ ./test
Hi.
jam@jam-ubuntu:~/Desktop/test$
上面的逻辑很简单,自定义一个sayhi库,这个库包括sayhi.h库头,实现就在sayhi.c中,然后在test.c中引入,编译也通过了,接下来就把自定义库编译成静态库:
# 把实际定义的库文件编译得到目标文件
jam@jam-ubuntu:~/Desktop/test$ gcc -c sayhi.c -o sayhi.o
# 打包目标文件为静态库文件
jam@jam-ubuntu:~/Desktop/test$ ar crs libsayhi.a sayhi.o
# 检查一下库文件是否有定义的符号接口
jam@jam-ubuntu:~/Desktop/test$ nm libsayhi.a
sayhi.o:
U puts
0000000000000000 T sayhi
# 为了保证编译没有原来的.c库文件作怪,把它干掉
jam@jam-ubuntu:~/Desktop/test$ rm sayhi.c
jam@jam-ubuntu:~/Desktop/test$ ls
libsayhi.a sayhi.h sayhi.o test test.c
# 编译,-l指定库,-L指定库路径
jam@jam-ubuntu:~/Desktop/test$ gcc test.c -o test -lsayhi -L .
# 运行看看效果
jam@jam-ubuntu:~/Desktop/test$ ./test
Hi.
jam@jam-ubuntu:~/Desktop/test$
好的,这样就是一个自定义的静态库在命令行的整个流程了(因为也在windows命令行尝试过,当然配置好了mingw环境的),然后再来进行一下动态库的尝试:
# 获取目标文件
jam@jam-ubuntu:~/Desktop/test$ gcc -c -fPIC sayhi.c -o sayhi.o
# 编译生成动态库文件
jam@jam-ubuntu:~/Desktop/test$ gcc -shared sayhi.o -o libsayhi.so
# 编译得到可执行文件
jam@jam-ubuntu:~/Desktop/test$ gcc test.c libsayhi.so -o test
jam@jam-ubuntu:~/Desktop/test$ ./test
./test: error while loading shared libraries: libsayhi.so: cannot open shared object file: No such file or directory
jam@jam-ubuntu:~/Desktop/test$
结果运行出错,显示无法找到动态库文件,检查一下:
# nm命令检查生成的动态库是否有对应符号文件
jam@jam-ubuntu:~/Desktop/test$ nm libsayhi.so | grep sayhi
0000000000001119 T sayhi
# 检查可执行文件的动态依赖,发现没有加载到内存中
jam@jam-ubuntu:~/Desktop/test$ ldd test
linux-vdso.so.1 (0x00007ffe0acbb000)
libsayhi.so => not found
libc.so.6 => /lib/x86_64-linux-gnu/libc.so.6 (0x00007fa3b5a00000)
/lib64/ld-linux-x86-64.so.2 (0x00007fa3b5dc7000)
程序运行,会根据可执行文件依赖,在LD_LIBRARY_PATH变量指定路径中去加载动态库,所以问题应该是在这个变量上,一般情况都不会把本地路径添加到改变量中。
# 检查一下变量指定路径
jam@jam-ubuntu:~/Desktop/test$ echo $LD_LIBRARY_PATH
# 临时添加一下路径,退出终端就没了的
jam@jam-ubuntu:~/Desktop/test$ export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/home/jam/Desktop/test
# 添加成功
jam@jam-ubuntu:~/Desktop/test$ echo $LD_LIBRARY_PATH
:/home/jam/Desktop/test
# 再检查一下test的动态依赖,可以了
jam@jam-ubuntu:~/Desktop/test$ ldd test
linux-vdso.so.1 (0x00007fff4e3d9000)
libsayhi.so (0x00007f4361033000)
libc.so.6 => /lib/x86_64-linux-gnu/libc.so.6 (0x00007f4360e00000)
/lib64/ld-linux-x86-64.so.2 (0x00007f436103f000)
jam@jam-ubuntu:~/Desktop/test$ ./test
Hi.
jam@jam-ubuntu:~/Desktop/test$
嗯,在windows中尝试,倒是不需要设置动态库变量,不过这个应该是因为windows针对动态库的应用非常好,而且会默认在可执行文件路径下去查找动态依赖。
在vs中的尝试
vs中使用的编译器和linux中的不是同一种,linux中的应用,是GNU,vs中现在基本都是clang,另外这是一个IDE,所以主要是想玩一下设置。不过,现在的vs虽然可以编辑c项目,但它本身还是主打cpp,所以它提供的动态库方案或者静态库项目方案就没法使用了,只能创建空项目来调试设置再来生成静态库动态库了。首先,创建项目:
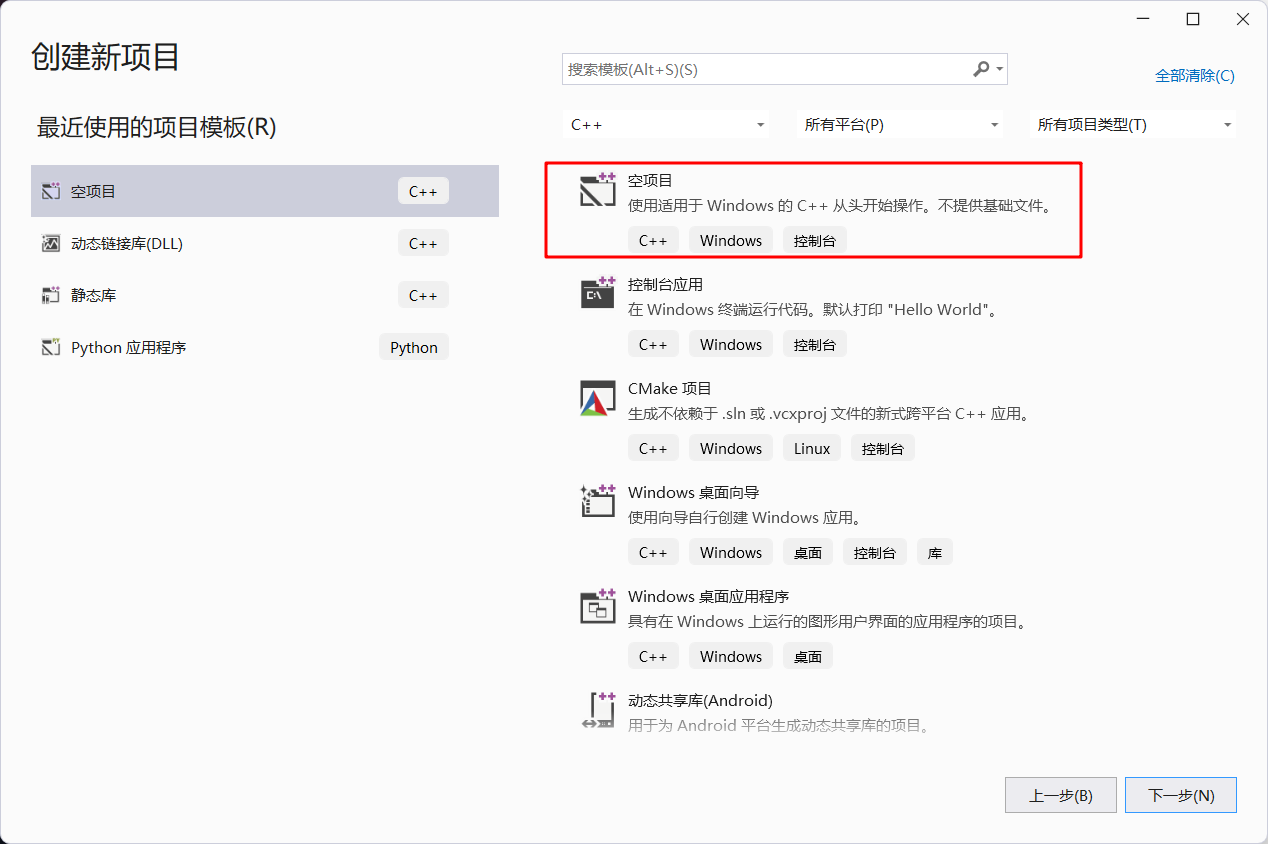
然后添加sayhi.h头文件和sayhi.c源文件:
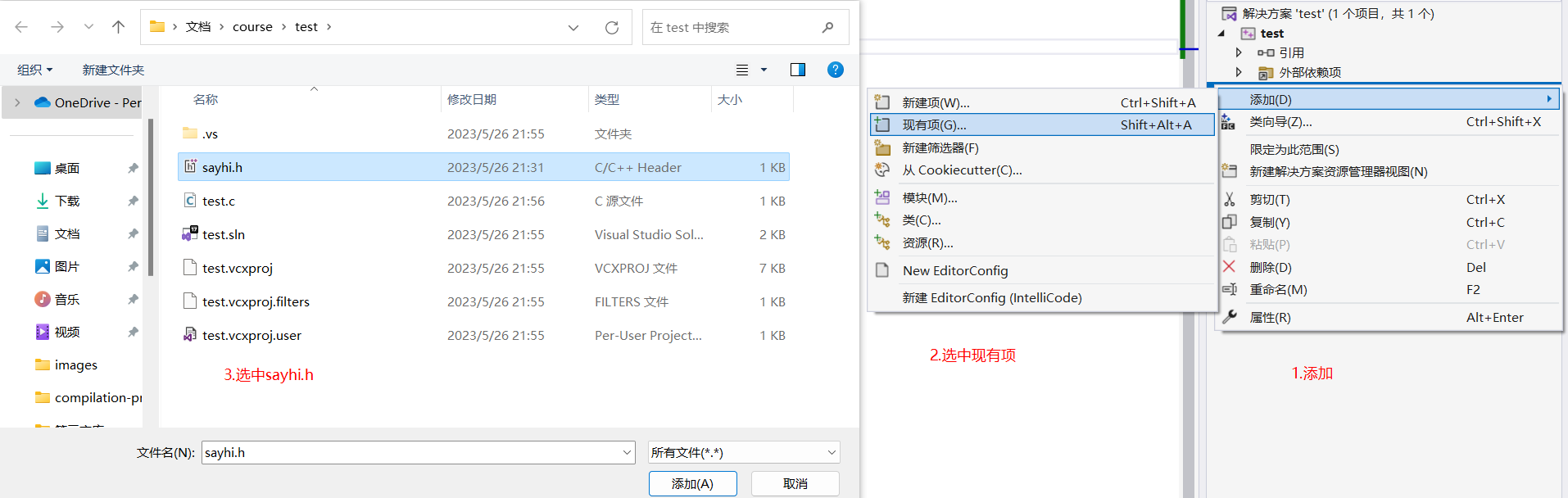
修改项目属性,“解决方案资源管理器”栏目中,右键"sayhi"项目,打开[属性]:
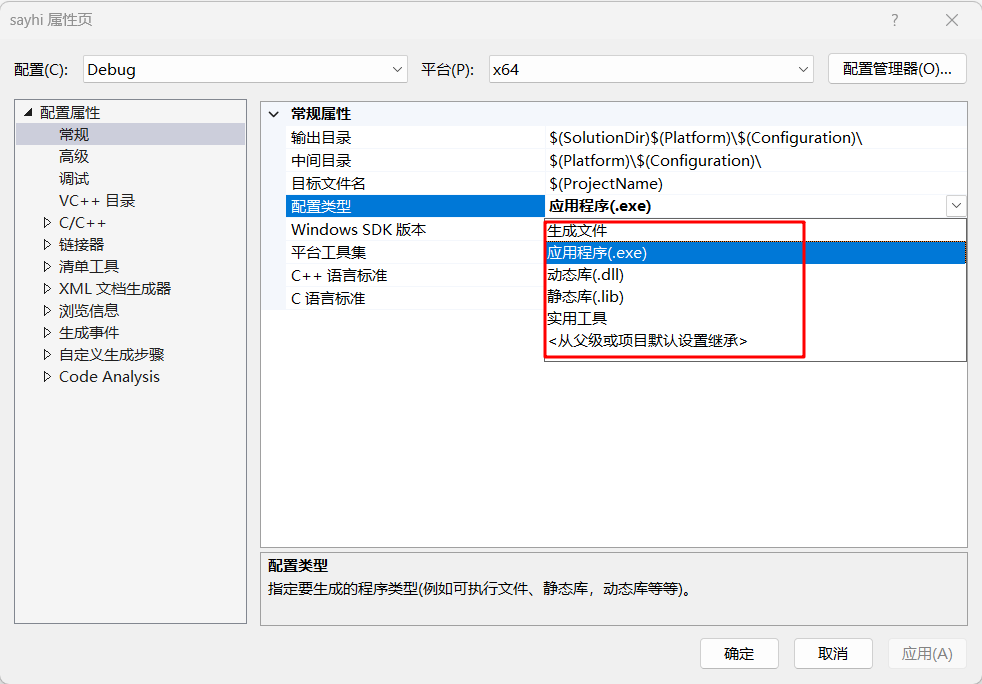
如上所示,在[配置属性]-[常规]-[配置类型]中就可以修改项目生成文件,无论是静态库lib还是动态库dll,首要修改这个配置。现在需要的静态库,所以点击[静态库lib],然后生成解决方案。因为只是生成文件,而不是运行,初次玩的话还是有点懵懂因为只有输出栏显示一些信息,而没有常见的黑窗口之类的东西。然后在项目的debug目录或者release目录中去找lib文件,如下就是debug目录下lib:
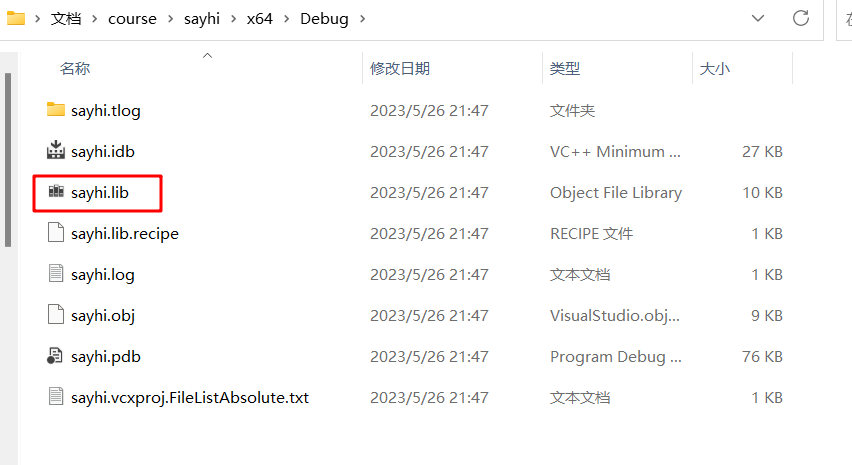
新建一个test项目进行检验,复制前面sayhi.h头文件到test项目中,然后引入:
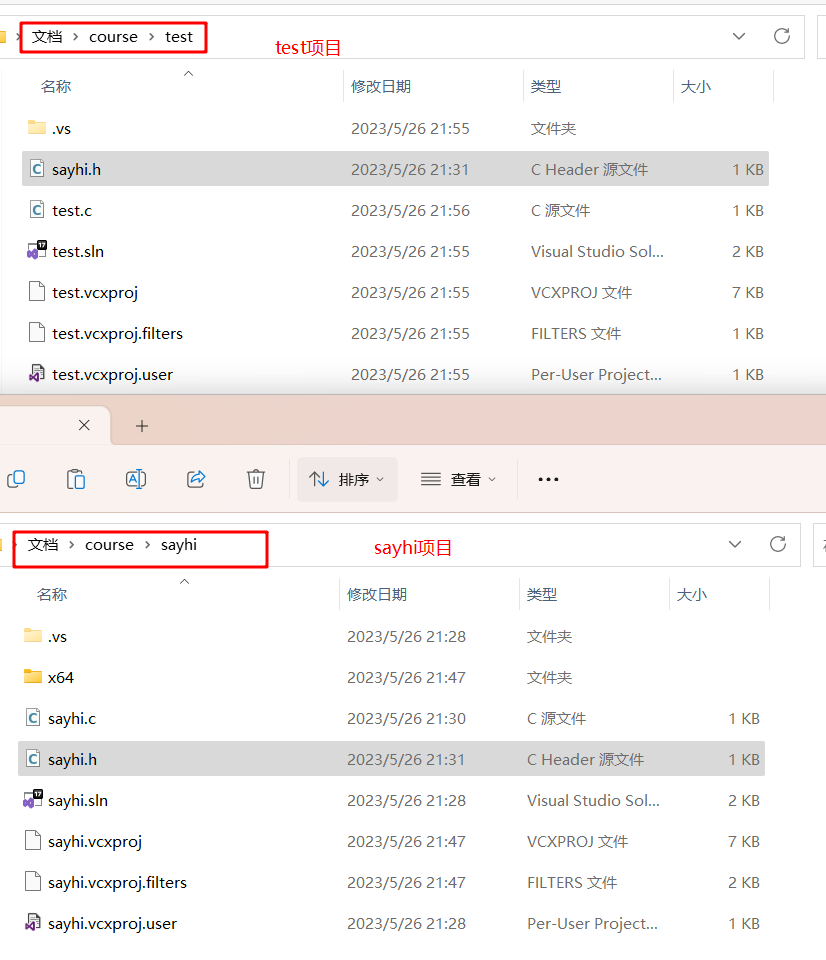
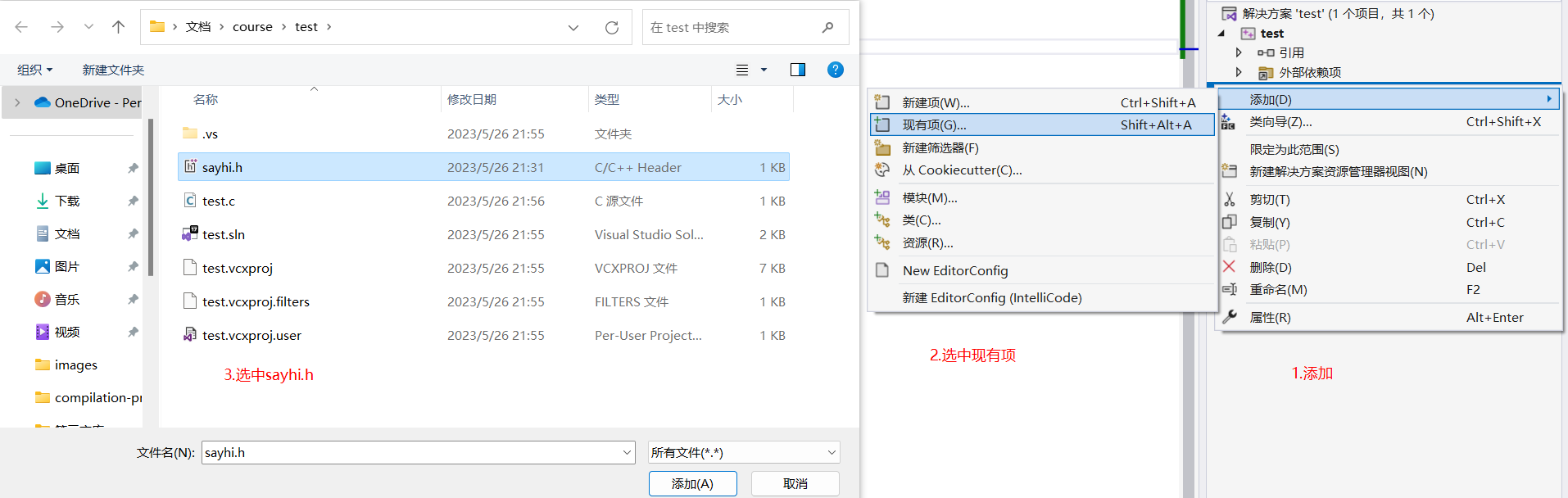
添加test源文件:
#include "sayhi.h"
int main() {
sayhi();
return 0;
}
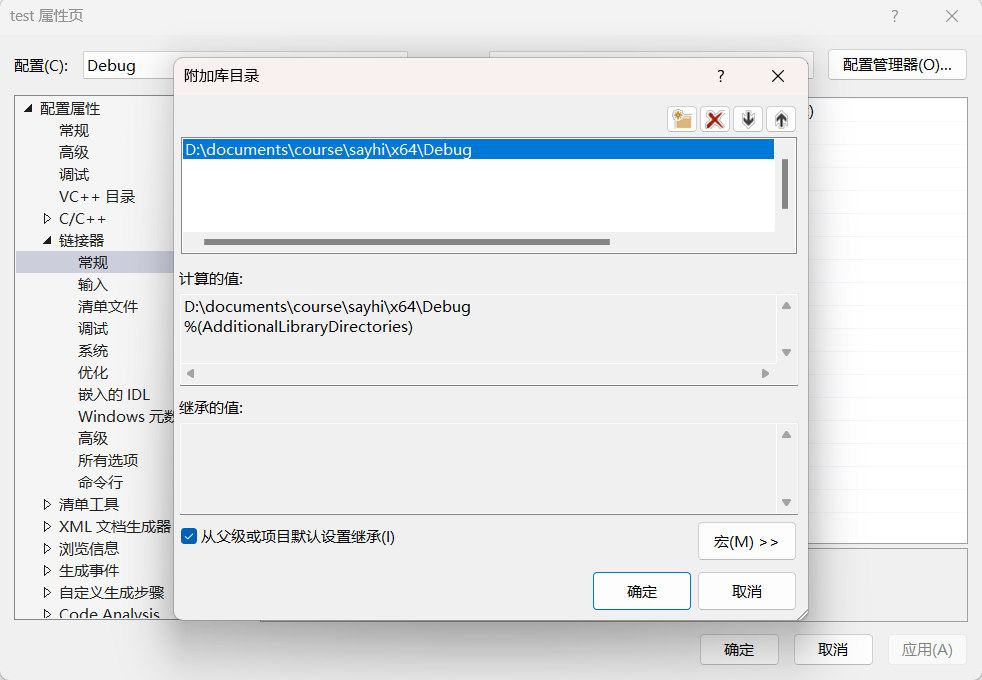
后面的动态库也是用这份代码,都不用改了,然后重新进入项目[属性]界面,在[链接器]-[常规]-[附加库目录]一项进行编辑,添加前面sayhi静态库的生成路径:
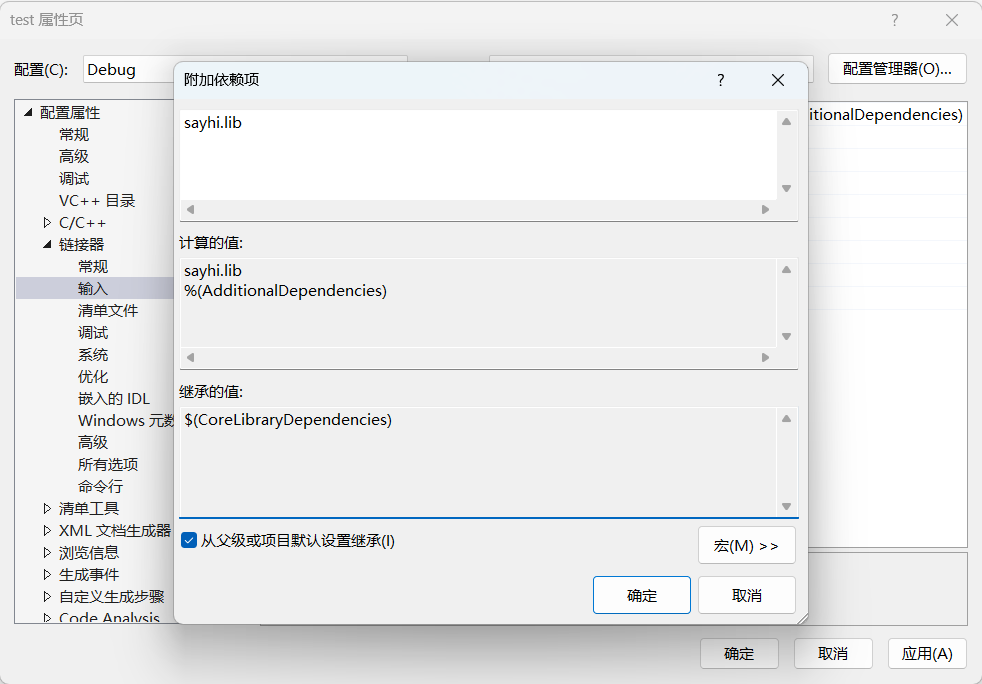
同样在[链接器]一栏,选中[输入],编辑[附加依赖项],输入前面生成的sayhi.lib:
然后就是一键运行的事儿了,结果如下:
动态库DLL的尝试
和上面一样,修改sayhi项目属性中[项目生成文件]属性,这次是动态库DLL嘛,但vs2022有点毛病(其他的我不知道),它需要添加def文件:
然后编辑添加如下:
LIBRARY
EXPORTS
sayhi @1
如果有比较多的自定义的函数接口,这里就有点抓瞎了,不过这里只是一个实验,另外,vs的使用还是专注于它的本职cpp吧。上面添加完,设置完以后,重新生成一下解决方案,就有了需要用到的lib和dll了。
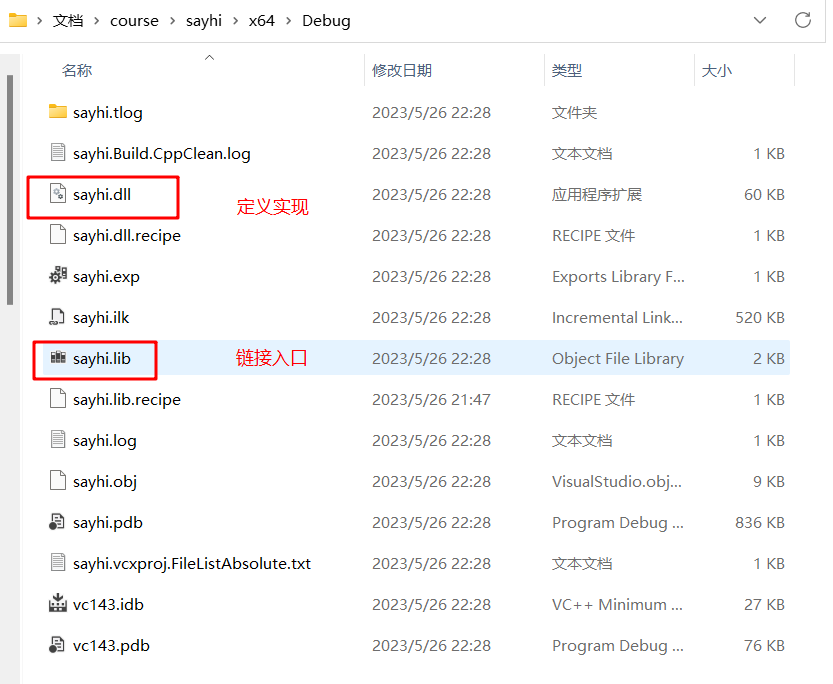
啥?要用lib?对啊,在windows里面,vs生成动态库时需要有一个lib文件负责记录函数地址和连接,具体实现,还是在dll文件中。所以,这里的使用设置,也很像lib静态库的引入使用,走上面一样的步骤就好,唯一不同的地方,就是需要把dll文件丢到test项目生成可执行文件的debug目录下,不然运行起来会报错。
嗯,因为两种方式都使用到lib,所以其实也可以简单设置了lib所在目录,然后用pragma设置所需依赖,结果都一样。好,实验结束。
注:使用vs的动态库或者静态库模板,然后使用cpp语法,重新走一遍上面的路子,可行,一样的操作。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号