
REDIS主从频繁切换事件排查
前言
目前生产配置了2台redis一主一从1.193和12.6,和3个哨兵。1.193,3.10,12.6,搭建的redis高可用环境。突然发生了redis频繁无响应。
现象
2台生产redis突然发生频繁的主从切换。由于目前redis配置主从切换全量同步先生成rdb数据文件保存到硬盘,然后将rdb文件传输到从库。因此redis目录下产生了大量的rdb文件
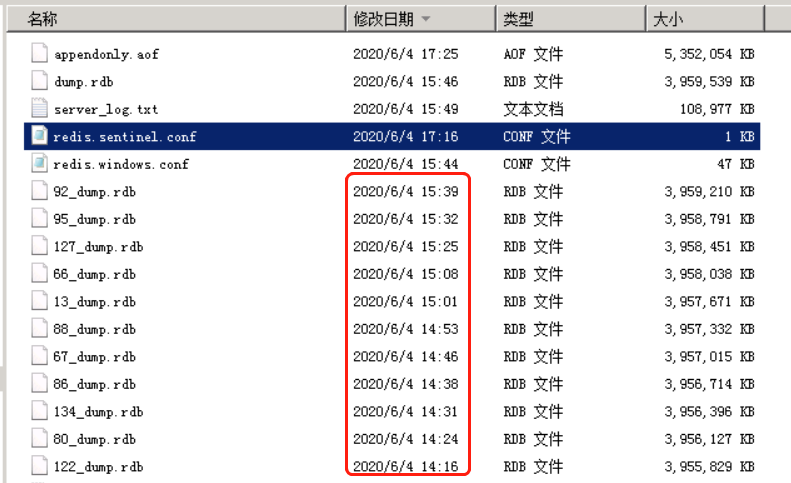
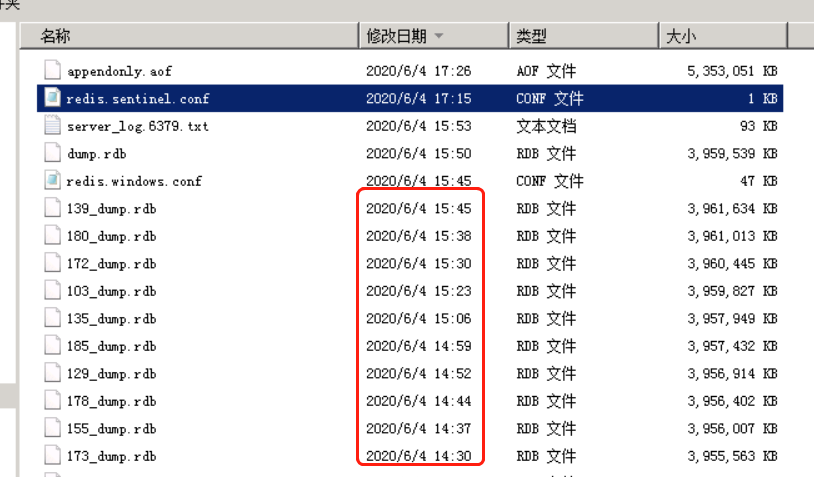
可以看出大约7分钟左右会产生一个rdb文件。
排查
查看2个redis服务日志,可以看到两个redis每隔一段时间就会变为主,且有许多连接丢失的情况,同时存在频繁主从全量同步。
1.193 redis
...
[3932] 04 Jun 14:18:32.846 * MASTER MODE enabled (user request from 'id=107487221 addr=172.19.12.1:49610 fd=188 name=sentinel-872f1eee-cmd age=71 idle=0 flags=x db=0 sub=0 psub=0 multi=3 qbuf=0 qbuf-free=32768 obl=36 oll=0 omem=0 events=r cmd=exec')
[3932] 04 Jun 14:18:32.862 # CONFIG REWRITE executed with success.
[3932] 04 Jun 14:18:44.983 * Slave 172.18.12.6:6380 asks for synchronization
[3932] 04 Jun 14:18:44.983 * Full resync requested by slave 172.18.12.6:6380
[3932] 04 Jun 14:18:44.983 * Starting BGSAVE for SYNC with target: disk
[3932] 04 Jun 14:18:45.061 * Background saving started by pid 140176
[3932] 04 Jun 14:22:42.416 # fork operation complete
[3932] 04 Jun 14:22:44.381 * Background saving terminated with success
[3932] 04 Jun 14:22:49.186 # Connection with slave 172.18.12.6:6380 lost.
[3932] 04 Jun 14:22:59.373 * SLAVE OF 172.18.12.6:6380 enabled (user request from 'id=107487264 addr=172.18.12.6:56951 fd=188 name=sentinel-7a359562-cmd age=10 idle=0 flags=x db=0 sub=0 psub=0 multi=3 qbuf=0 qbuf-free=32768 obl=36 oll=0 omem=0 events=r cmd=exec')
[3932] 04 Jun 14:22:59.388 # CONFIG REWRITE executed with success.
[3932] 04 Jun 14:22:59.700 * Connecting to MASTER 172.18.12.6:6380
[3932] 04 Jun 14:22:59.700 * MASTER <-> SLAVE sync started
[3932] 04 Jun 14:22:59.700 * Non blocking connect for SYNC fired the event.
[3932] 04 Jun 14:22:59.700 * Master replied to PING, replication can continue...
[3932] 04 Jun 14:22:59.700 * Partial resynchronization not possible (no cached master)
[3932] 04 Jun 14:22:59.763 * Full resync from master: f391e124ded4a1bbe62f0e1d0214b823943f3461:1
[3932] 04 Jun 14:25:52.642 * MASTER MODE enabled (user request from 'id=107487264 addr=172.18.12.6:56951 fd=188 name=sentinel-7a359562-cmd age=183 idle=0 flags=x db=0 sub=0 psub=0 multi=3 qbuf=0 qbuf-free=32768 obl=36 oll=0 omem=0 events=r cmd=exec')
[3932] 04 Jun 14:25:52.658 # CONFIG REWRITE executed with success.
[3932] 04 Jun 14:26:04.077 * Slave 172.18.12.6:6380 asks for synchronization
[3932] 04 Jun 14:26:04.077 * Full resync requested by slave 172.18.12.6:6380
[3932] 04 Jun 14:26:04.077 * Starting BGSAVE for SYNC with target: disk
[3932] 04 Jun 14:26:04.171 * Background saving started by pid 1428
[3932] 04 Jun 14:30:08.342 # fork operation complete
[3932] 04 Jun 14:30:10.277 * Background saving terminated with success
[3932] 04 Jun 14:30:15.659 # Connection with slave 172.18.12.6:6380 lost.
[3932] 04 Jun 14:30:25.705 * SLAVE OF 172.18.12.6:6380 enabled (user request from 'id=107487335 addr=172.18.12.6:57160 fd=161 name=sentinel-7a359562-cmd age=17 idle=0 flags=x db=0 sub=0 psub=0 multi=3 qbuf=0 qbuf-free=32768 obl=36 oll=0 omem=0 events=r cmd=exec')
[3932] 04 Jun 14:30:25.721 # CONFIG REWRITE executed with success.
[3932] 04 Jun 14:30:26.064 * Connecting to MASTER 172.18.12.6:6380
[3932] 04 Jun 14:30:26.064 * MASTER <-> SLAVE sync started
...
MASTER MODE enabled被哨兵设置为主CONFIG REWRITE executed with success配置重写成功Slave 172.18.12.6:6380 asks for synchronization从redis请求主从同步Full resync requested by slave 172.18.12.6:6380全量同步Starting BGSAVE for SYNC with target: disk后台保存到硬盘Background saving started by pid 140176子进程开始保存fork operation complete子线程操作完成Background saving terminated with success保存成功Connection with slave 172.18.12.6:6380 lost.连接到从连接丢失SLAVE OF 172.18.12.6:6380 enabled被哨兵设置为从Connecting to MASTER 172.18.12.6:6380连接到主MASTER <-> SLAVE sync started主从同步开始Partial resynchronization not possible (no cached master)无法部分同步Full resync from master: f391e124ded4a1bbe62f0e1d0214b823943f3461:1全量同步
查看哨兵日志(下面是其中一个哨兵日志),每个哨兵日志都显示频繁发生重新选举。
172.17.1.193的哨兵
[132436] 04 Jun 14:07:19.705 # +sdown master master 172.17.1.193 6379
[132436] 04 Jun 14:07:19.939 # +new-epoch 3
[132436] 04 Jun 14:07:19.955 # +vote-for-leader 7a359562268faaf4b588343b75fea8afbd6a2816 3
[132436] 04 Jun 14:07:20.345 # -sdown master master 172.17.1.193 6379
[132436] 04 Jun 14:07:21.234 # +config-update-from sentinel 7a359562268faaf4b588343b75fea8afbd6a2816 172.18.12.6 16380 @ master 172.17.1.193 6379
[132436] 04 Jun 14:07:21.234 # +switch-master master 172.17.1.193 6379 172.18.12.6 6380
[132436] 04 Jun 14:07:21.234 * +slave slave 172.17.1.193:6379 172.17.1.193 6379 @ master 172.18.12.6 6380
[132436] 04 Jun 14:07:31.280 * +convert-to-slave slave 172.17.1.193:6379 172.17.1.193 6379 @ master 172.18.12.6 6380
[132436] 04 Jun 14:10:23.333 # +sdown master master 172.18.12.6 6380
[132436] 04 Jun 14:10:23.442 # +odown master master 172.18.12.6 6380 #quorum 2/2
[132436] 04 Jun 14:10:23.442 # +new-epoch 4
[132436] 04 Jun 14:10:23.442 # +try-failover master master 172.18.12.6 6380
[132436] 04 Jun 14:10:23.442 # +vote-for-leader 1e28fa3c46c51d90d497412d75326034b9e439a0 4
[132436] 04 Jun 14:10:23.458 # 7a359562268faaf4b588343b75fea8afbd6a2816 voted for 7a359562268faaf4b588343b75fea8afbd6a2816 4
[132436] 04 Jun 14:10:23.489 # 872f1eee7d73890b2b4d75a2a0bead3f0a33603e voted for 7a359562268faaf4b588343b75fea8afbd6a2816 4
[132436] 04 Jun 14:10:24.643 # -sdown master master 172.18.12.6 6380
[132436] 04 Jun 14:10:24.643 # -odown master master 172.18.12.6 6380
[132436] 04 Jun 14:10:34.456 # -failover-abort-not-elected master master 172.18.12.6 6380
[132436] 04 Jun 14:12:33.734 # +sdown slave 172.17.1.193:6379 172.17.1.193 6379 @ master 172.18.12.6 6380
[132436] 04 Jun 14:13:46.929 # -sdown slave 172.17.1.193:6379 172.17.1.193 6379 @ master 172.18.12.6 6380
...
+sdown master master主观下线主redisnew-epoch 3新一轮投票vote-for-leader 7a359562268faaf4b588343b75fea8afbd6a2816 3选举哨兵领导者+sdown master master客观下线主redisconfig-update-from sentinel从哨兵更新配置,更新到本地,最终选举出的主redisswitch-master master切换到主redisslave slave设置从redisconvert-to-slave主节点转换为从节点failover-abort-not-elected选举中止
+sdown表示认定主观下线,-sdown是撤销主观下线
另一台哨兵日志
172.17.3.10的哨兵
[7152] 04 Jun 14:05:34.856 # +new-epoch 3
[7152] 04 Jun 14:05:34.872 # +vote-for-leader 7a359562268faaf4b588343b75fea8afbd6a2816 3
[7152] 04 Jun 14:05:35.106 # +sdown master master 172.17.1.193 6379
[7152] 04 Jun 14:05:35.185 # +odown master master 172.17.1.193 6379 #quorum 3/2
[7152] 04 Jun 14:05:35.185 # Next failover delay: I will not start a failover before Thu Jun 04 14:06:35 2020
[7152] 04 Jun 14:05:35.247 # -sdown master master 172.17.1.193 6379
[7152] 04 Jun 14:05:35.247 # -odown master master 172.17.1.193 6379
[7152] 04 Jun 14:05:36.153 # +config-update-from sentinel 7a359562268faaf4b588343b75fea8afbd6a2816 172.18.12.6 16380 @ master 172.17.1.193 6379
[7152] 04 Jun 14:05:36.153 # +switch-master master 172.17.1.193 6379 172.18.12.6 6380
[7152] 04 Jun 14:05:36.153 * +slave slave 172.17.1.193:6379 172.17.1.193 6379 @ master 172.18.12.6 6380
[7152] 04 Jun 14:08:37.880 # +sdown master master 172.18.12.6 6380
[7152] 04 Jun 14:08:38.380 # +new-epoch 4
[7152] 04 Jun 14:08:38.380 # +vote-for-leader 7a359562268faaf4b588343b75fea8afbd6a2816 4
[7152] 04 Jun 14:08:39.021 # +odown master master 172.18.12.6 6380 #quorum 3/2
[7152] 04 Jun 14:08:39.021 # Next failover delay: I will not start a failover before Thu Jun 04 14:09:39 2020
[7152] 04 Jun 14:08:39.568 # -sdown master master 172.18.12.6 6380
[7152] 04 Jun 14:08:39.568 # -odown master master 172.18.12.6 6380
[7152] 04 Jun 14:10:48.584 # +sdown slave 172.17.1.193:6379 172.17.1.193 6379 @ master 172.18.12.6 6380
[7152] 04 Jun 14:12:01.781 # -sdown slave 172.17.1.193:6379 172.17.1.193 6379 @ master 172.18.12.6 6380
...
Next failover delay 选举时间间太短,等下一次选举,避免网络短时间内波动造成频繁主从切换。该时间间隔是down-after-milliseconds值的10倍
结论
仔细看哨兵redis发现,服务器1.193的哨兵也会认为1.193的redis主观下线sdown master master 172.17.1.193 6379,怀疑有可能是redis服务的问题,而不是网络问题。
查看日志发现有频繁的fork operation complete 日志,由于有全量同步和aof同步出现,fork线程和子线程处理完通知父线程后的逻辑处理都会有短暂阻塞。因此在RDB和AOF持久化时造成阻塞(当时的redis数据量达到9G),可能会导致哨兵误认为节点主观下线。
主从同步阻塞时,当增量数据超过配置的阈值或配置的时间,则会触发全量数据同步。
redis主从配置注意点
- 控制Redis实例最大可用内存,fork耗时跟内存成正比。10GB的redis内存大约需要20MB的内存页表,因此内存越大fork越耗时,正常情况大约每GB需要消耗20ms左右。可以通过
latest_fork_usec查看最后一次fork时间,单位是微秒。 - rdb每次会全量保存文件(通过写时复制技术只需要保存修改的数据),保存需要双倍数据内存,主从同步方式可以使用无硬盘模式,尽可能使用aof每秒保存,若是4.X版本的redis,则使用rdb-aof模式,增量数据以aof追加,aof重写时以rbd数据保存。
- 哨兵主观下线时间配置
down-after-milliseconds不要配置太短,配置太短很可能造成频繁发生主从切换。 - 增大主从同步的缓存大小
repl-backlog-size,当主从连接断开重连后,若增量同步数据小于缓存大小, 则仅需增量同步即可,无需全量同步。默认1MB - 适当增大主从断开全量同步时间超过配置的
repl-backlog-ttl值会触发全量同步,单位时秒。 - 当搭建了集群,若超过半数节点无响应,则整个集群会挂掉。当发生主从同步,持久化时节点可能阻塞,适当调整集群通讯超时时间。
cluster-node-timeout单位是毫秒。
每天收获一点点

 浙公网安备 33010602011771号
浙公网安备 33010602011771号