托管对象本质-第四部分-字段布局
托管对象本质-第四部分-字段布局
原文地址:https://devblogs.microsoft.com/premier-developer/managed-object-internals-part-4-fields-layout/
原文作者:Sergey
译文作者:杰哥很忙
目录
托管对象本质1-布局
托管对象本质2-对象头布局和锁成本
托管对象本质3-托管数组结构
托管对象本质4-字段布局
在最近的博客文章中,我们讨论了CLR中对象布局的不可见部分:
这次我们将重点讨论实例本身的布局,特别是实例字段在内存中的布局。
目前还没有关于字段布局的官方文档,因为CLR作者保留了在将来更改它的权利。但是,如果您有兴趣或者正在开发一个需要高性能的应用程序,那么了解布局可能会有帮助。
我们如何检查布局?我们可以在Visual Studio中查看原始内存或在SOS调试扩展中使用!dumpobj命令。这些方法单调乏味,因此我们将尝试编写一个工具,在运行时打印对象布局。
如果您对工具的实现细节不感兴趣,可以跳到在运行时检查值类型布局部分。
在运行时获取字段偏移量
我们不会使用非托管代码或分析API,而是使用LdFlda指令的强大功能。此IL指令返回给定类型字段的地址。不幸的是,这条指令没有在C#语言中公开,所以我们需要编写一些代码来解决这个限制。
在剖析C#中的new()约束时,我们已经做了类似的工作。我们将使用必要的IL指令生成一个动态方法。
该方法应执行以下操作:
- 创建数组用来存储所有字段地址。
- 枚举对象的每个FieldInfo,通过调用LdFlda指令获取偏移量。
- 将LdFlda指令的结果转换为long并将结果存储在数组中。
- 返回数组。
private static Func<object, long[]> GenerateFieldOffsetInspectionFunction(FieldInfo[] fields)
{
var method = new DynamicMethod(
name: "GetFieldOffsets",
returnType: typeof(long[]),
parameterTypes: new[] { typeof(object) },
m: typeof(InspectorHelper).Module,
skipVisibility: true);
ILGenerator ilGen = method.GetILGenerator();
// Declaring local variable of type long[]
ilGen.DeclareLocal(typeof(long[]));
// Loading array size onto evaluation stack
ilGen.Emit(OpCodes.Ldc_I4, fields.Length);
// Creating an array and storing it into the local
ilGen.Emit(OpCodes.Newarr, typeof(long));
ilGen.Emit(OpCodes.Stloc_0);
for (int i = 0; i < fields.Length; i++)
{
// Loading the local with an array
ilGen.Emit(OpCodes.Ldloc_0);
// Loading an index of the array where we're going to store the element
ilGen.Emit(OpCodes.Ldc_I4, i);
// Loading object instance onto evaluation stack
ilGen.Emit(OpCodes.Ldarg_0);
// Getting the address for a given field
ilGen.Emit(OpCodes.Ldflda, fields[i]);
// Converting field offset to long
ilGen.Emit(OpCodes.Conv_I8);
// Storing the offset in the array
ilGen.Emit(OpCodes.Stelem_I8);
}
ilGen.Emit(OpCodes.Ldloc_0);
ilGen.Emit(OpCodes.Ret);
return (Func<object, long[]>)method.CreateDelegate(typeof(Func<object, long[]>));
}
我们可以创建一个帮助函数用来提供给定的每个字段的偏移量。
public static (FieldInfo fieldInfo, int offset)[] GetFieldOffsets(Type t)
{
var fields = t.GetFields(BindingFlags.Public | BindingFlags.Instance | BindingFlags.NonPublic);
Func<object, long[]> fieldOffsetInspector = GenerateFieldOffsetInspectionFunction(fields);
var instance = CreateInstance(t);
var addresses = fieldOffsetInspector(instance);
if (addresses.Length == 0)
{
return Array.Empty<(FieldInfo, int)>();
}
var baseLine = addresses.Min();
// Converting field addresses to offsets using the first field as a baseline
return fields
.Select((field, index) => (field: field, offset: (int)(addresses[index] - baseLine)))
.OrderBy(tuple => tuple.offset)
.ToArray();
}
函数非常简单,有一个警告:LdFlda 指令需要计算堆栈上的对象实例。对于值类型和具有默认构造函数的引用类型,解决方案是不难的:可以直接使用Activator.CreateInstance(Type)。但是,如果想要检查没有默认构造函数的类,该怎么办?
在这种情况下我们可以使用不常使用的通用工厂,调用FormatterServices.GetUninitializedObject(Type)。
译者补充: FormatterServices.GetUninitializedObject方法不会调用默认构造函数,所有字段都保持默认值。
private static object CreateInstance(Type t)
{
return t.IsValueType ? Activator.CreateInstance(t) : FormatterServices.GetUninitializedObject(t);
}
让我们来测试一下 GetFieldOffsets 获取下面类型的布局。
class ByteAndInt
{
public byte b;
public int n;
}
Console.WriteLine(
string.Join("\r\n",
InspectorHelper.GetFieldOffsets(typeof(ByteAndInt))
.Select(tpl => $"Field {tpl.fieldInfo.Name}: starts at offset {tpl.offset}"))
);
输出是:
Field n: starts at offset 0
Field b: starts at offset 4
有意思,但是做的还不够。我们可以检查每个字段的偏移量,但是知道每个字段的大小来理解布局的空间利用率,了解每个实例有多少空闲空间会很有用。
计算类型实例的大小
同样,没有"官方"方法来获取对象实例的大小。sizeof 运算符仅适用于没有引用类型字段的基元类型和用户定义结构。Marshal.SizeOf 返回非托管内存中的对象的大小,并不满足我们的需求。
我们将分别计算值类型和对象的实例大小。为了计算结构的大小,我们将依赖于 CLR 本身。我们会创建一个包含两个字段的简单泛型类型:第一个字段是泛型类型字段,第二个字段用于获取第一个字段的大小。
struct SizeComputer<T>
{
public T dummyField;
public int offset;
}
public static int GetSizeOfValueTypeInstance(Type type)
{
Debug.Assert(type.IsValueType);
var generatedType = typeof(SizeComputer<>).MakeGenericType(type);
// The offset of the second field is the size of the 'type'
var fieldsOffsets = GetFieldOffsets(generatedType);
return fieldsOffsets[1].offset;
}
为了得到引用类型实例的大小,我们将使用另一个技巧:我们获取最大字段偏移量,然后将该字段的大小和该数字四舍五入到指针大小边界。我们已经知道如何计算值类型的大小,并且我们知道引用类型的每个字段都占用 4 或 8 个字节(具体取决于平台)。因此,我们获得了所需的一切信息:
public static int GetSizeOfReferenceTypeInstance(Type type)
{
Debug.Assert(!type.IsValueType);
var fields = GetFieldOffsets(type);
if (fields.Length == 0)
{
// Special case: the size of an empty class is 1 Ptr size
return IntPtr.Size;
}
// The size of the reference type is computed in the following way:
// MaxFieldOffset + SizeOfThatField
// and round that number to closest point size boundary
var maxValue = fields.MaxBy(tpl => tpl.offset);
int sizeCandidate = maxValue.offset + GetFieldSize(maxValue.fieldInfo.FieldType);
// Rounding the size to the nearest ptr-size boundary
int roundTo = IntPtr.Size - 1;
return (sizeCandidate + roundTo) & (~roundTo);
}
public static int GetFieldSize(Type t)
{
if (t.IsValueType)
{
return GetSizeOfValueTypeInstance(t);
}
return IntPtr.Size;
}
我们有足够的信息在运行时获取任何类型实例的正确布局信息。
在运行时检查值类型布局
我们从值类型开始,并检查以下结构:
public struct NotAlignedStruct
{
public byte m_byte1;
public int m_int;
public byte m_byte2;
public short m_short;
}
调用TypeLayout.Print<NotAlignedStruct>()结果如下:
Size: 12. Paddings: 4 (%33 of empty space)
|================================|
| 0: Byte m_byte1 (1 byte) |
|--------------------------------|
| 1-3: padding (3 bytes) |
|--------------------------------|
| 4-7: Int32 m_int (4 bytes) |
|--------------------------------|
| 8: Byte m_byte2 (1 byte) |
|--------------------------------|
| 9: padding (1 byte) |
|--------------------------------|
| 10-11: Int16 m_short (2 bytes) |
|================================|
默认情况下,用户定义的结构具有sequential布局,Pack 等于 0。下面是 CLR 遵循的规则:
字段必须与自身大小的字段(1、2、4、8 等、字节)或比它小的字段的类型的对齐方式对齐。由于默认的类型对齐方式是以最大元素的大小对齐(大于或等于所有其他字段长度),这通常意味着字段按其大小对齐。例如,即使类型中的最大字段是 64 位(8 字节)整数,或者 Pack 字段设置为 8,byte字段在 1 字节边界上对齐,Int16 字段在 2 字节边界上对齐,Int32 字段在 4 字节边界上对齐。
译者补充:当较大字段排列在较小字段之后时,会进行对内对齐,以最大基元元素的大小填齐使得内存对齐。
在上面的情况,4个字节对齐会有比较合理的开销。我们可以将 Pack 更改为 1,但由于未对齐的内存操作,性能可能会下降。相反,我们可以使用LayoutKind.Auto 来允许 CLR 自动寻找最佳布局:
译者补充:内存对齐的方式主要有2个作用:一是为了跨平台。并不是所有的硬件平台都能访问任意地址上的任意数据的;某些硬件平台只能在某些地址处取某些特定类型的数据,否则抛出硬件异常。二是内存对齐可以提高性能,原因在于,为了访问未对齐的内存,处理器需要作两次内存访问;而对齐的内存访问仅需要一次访问。
[StructLayout(LayoutKind.Auto)]
public struct NotAlignedStructWithAutoLayout
{
public byte m_byte1;
public int m_int;
public byte m_byte2;
public short m_short;
}
Size: 8. Paddings: 0 (%0 of empty space)
|================================|
| 0-3: Int32 m_int (4 bytes) |
|--------------------------------|
| 4-5: Int16 m_short (2 bytes) |
|--------------------------------|
| 6: Byte m_byte1 (1 byte) |
|--------------------------------|
| 7: Byte m_byte2 (1 byte) |
|================================|
记住,只有当类型中没有"指针"时,才可能同时使用值类型和引用类型的顺序布局。如果结构或类至少有一个引用类型的字段,则布局将自动更改为 LayoutKind.Auto。
在运行时检查引用类型布局
引用类型的布局和值类型的布局之间存在两个主要差异。首先,每个对象实例都有一个对象头和方法表指针。其次,对象的默认布局是自动的(Auto)的,而不是顺序的(sequential)的。与值类型类似,顺序布局仅适用于没有任何引用类型的类。
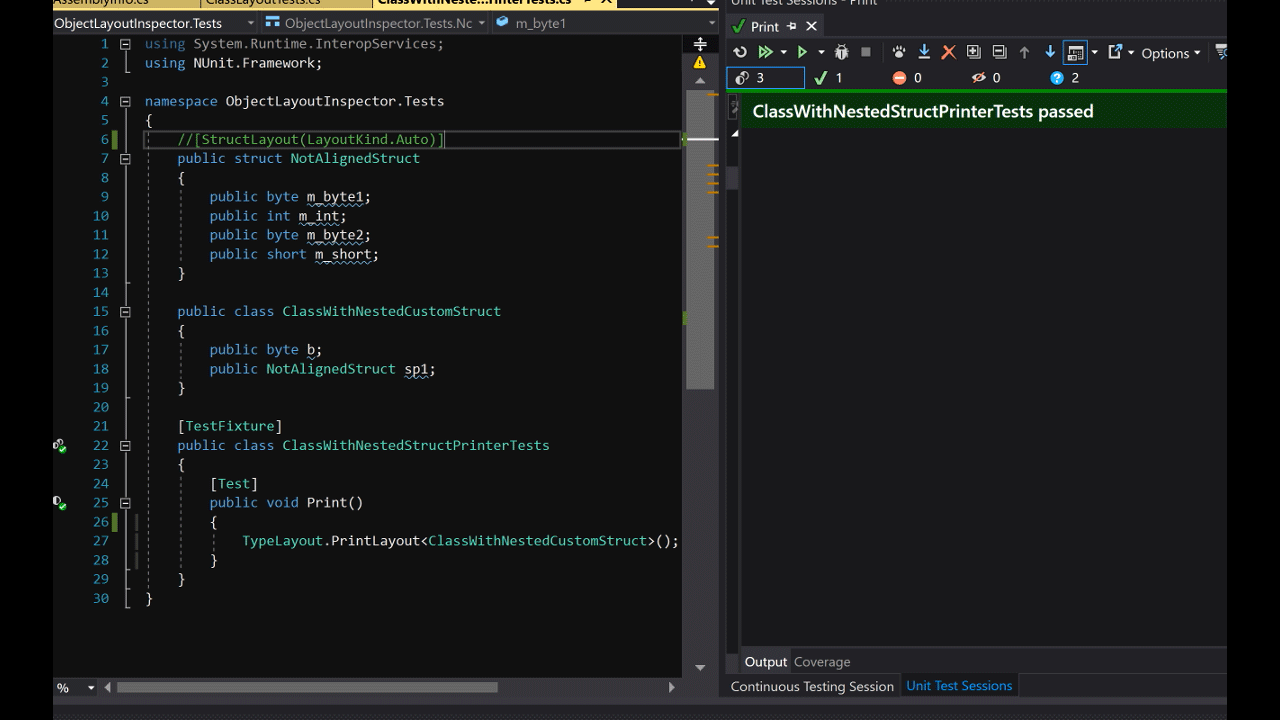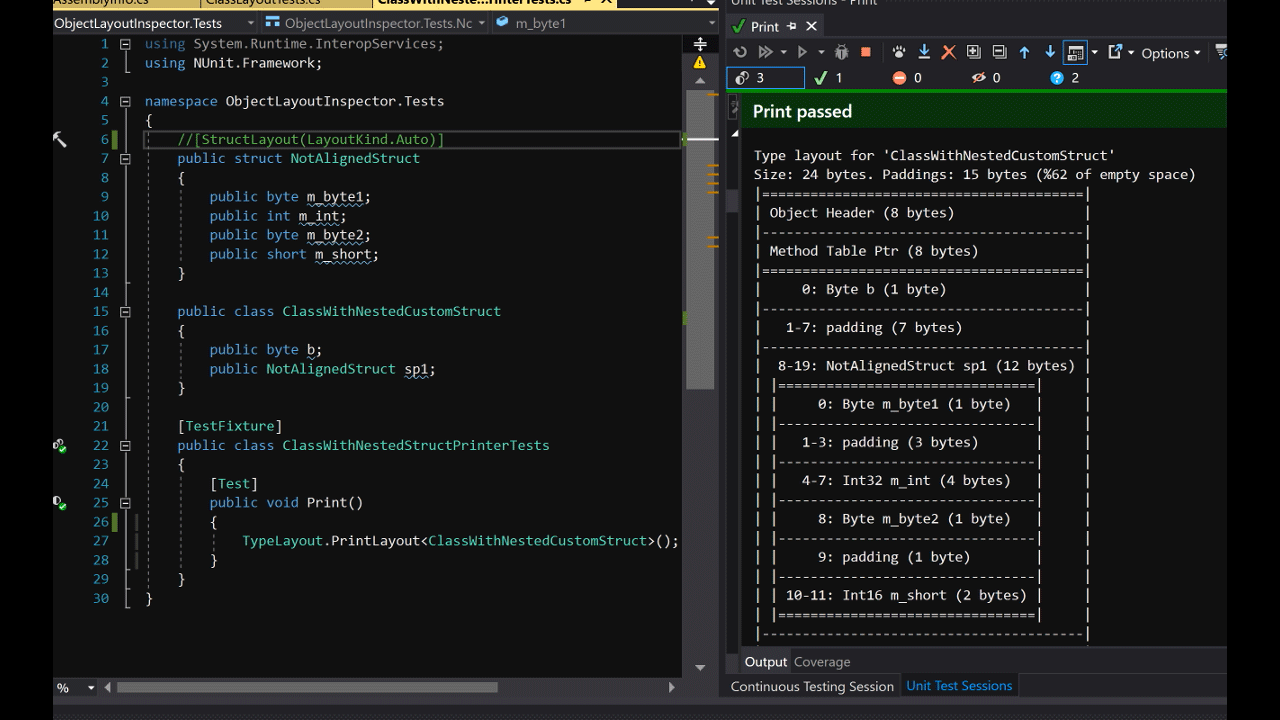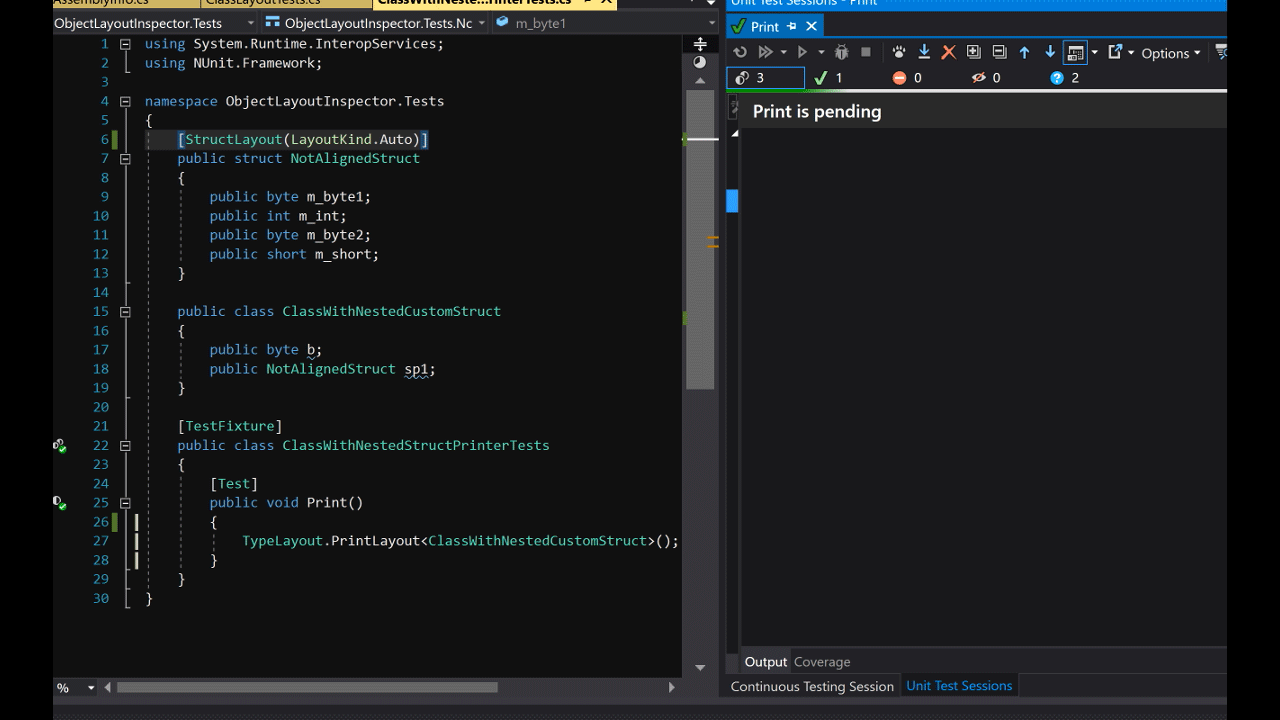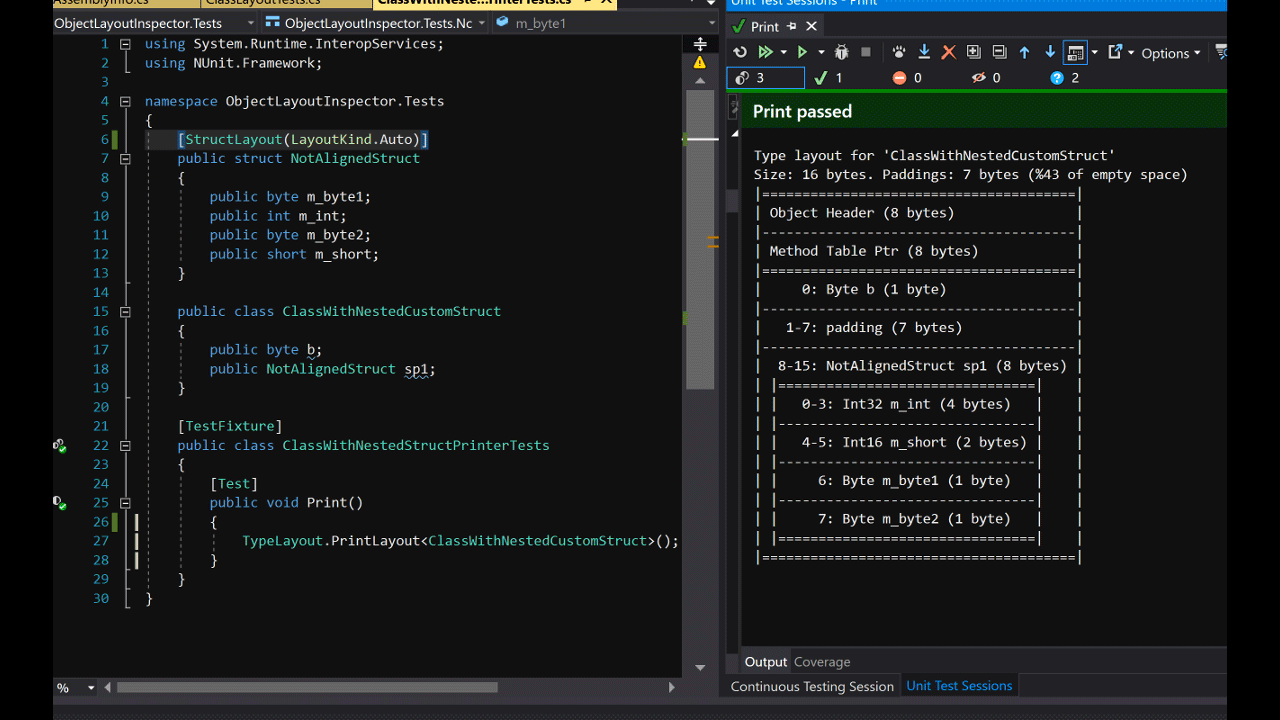
方法 TypeLayout.PrintLayout<T>(bool recursively = true)采用一个参数,允许打印嵌套类型。
public class ClassWithNestedCustomStruct
{
public byte b;
public NotAlignedStruct sp1;
}
Size: 40. Paddings: 11 (%27 of empty space)
|========================================|
| Object Header (8 bytes) |
|----------------------------------------|
| Method Table Ptr (8 bytes) |
|========================================|
| 0: Byte b (1 byte) |
|----------------------------------------|
| 1-7: padding (7 bytes) |
|----------------------------------------|
| 8-19: NotAlignedStruct sp1 (12 bytes) |
| |================================| |
| | 0: Byte m_byte1 (1 byte) | |
| |--------------------------------| |
| | 1-3: padding (3 bytes) | |
| |--------------------------------| |
| | 4-7: Int32 m_int (4 bytes) | |
| |--------------------------------| |
| | 8: Byte m_byte2 (1 byte) | |
| |--------------------------------| |
| | 9: padding (1 byte) | |
| |--------------------------------| |
| | 10-11: Int16 m_short (2 bytes) | |
| |================================| |
|----------------------------------------|
| 20-23: padding (4 bytes) |
|========================================|
结构包装的成本
尽管类型布局非常简单,但我发现了一个有趣的特性。
我最近正在调查项目中的一个内存问题,我注意到一些奇怪的现象:托管对象的所有字段的总和都高于实例的大小。我大致知道 CLR 如何布置字段的规则,所以我感到困惑。我已经开始研究这个工具来理解这个问题。
我已经将问题缩小到以下情况:
internal struct ByteWrapper
{
public byte b;
}
internal class ClassWithByteWrappers
{
public ByteWrapper bw1;
public ByteWrapper bw2;
public ByteWrapper bw3;
}
--- Automatic Layout --- --- Sequential Layout ---
Size: 24 bytes. Paddings: 21 bytes Size: 8 bytes. Paddings: 5 bytes
(%87 of empty space) (%62 of empty space)
|=================================| |=================================|
| Object Header (8 bytes) | | Object Header (8 bytes) |
|---------------------------------| |---------------------------------|
| Method Table Ptr (8 bytes) | | Method Table Ptr (8 bytes) |
|=================================| |=================================|
| 0: ByteWrapper bw1 (1 byte) | | 0: ByteWrapper bw1 (1 byte) |
|---------------------------------| |---------------------------------|
| 1-7: padding (7 bytes) | | 1: ByteWrapper bw2 (1 byte) |
|---------------------------------| |---------------------------------|
| 8: ByteWrapper bw2 (1 byte) | | 2: ByteWrapper bw3 (1 byte) |
|---------------------------------| |---------------------------------|
| 9-15: padding (7 bytes) | | 3-7: padding (5 bytes) |
|---------------------------------| |=================================|
| 16: ByteWrapper bw3 (1 byte) |
|---------------------------------|
| 17-23: padding (7 bytes) |
|=================================|
即使 ByteWrapper 的大小为 1 字节,CLR 在指针边界上对齐每个字段! 如果类型布局是LayoutKind.Auto CLR 将填充每个自定义值类型字段! 这意味着,如果你有多个结构,仅包装一个 int 或 byte类型,而且它们广泛用于数百万个对象,那么由于填充的现象,可能会有明显的内存开销。
默认包大小为4或8,根据平台而定。
参考文档
- StructLayout特性
- Compiling C# Code Into Memory and Executing It with Roslyn
- StructLayoutAttribute.Pack
- 有助于在运行时查看 CLR 类型的内部结构的工具
微信扫一扫二维码关注订阅号杰哥技术分享
出处:https://www.cnblogs.com/Jack-Blog/p/12259258.html
作者:杰哥很忙
本文使用「CC BY 4.0」创作共享协议。欢迎转载,请在明显位置给出出处及链接。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号