托管对象本质-第三部分-托管数组结构
托管对象本质-第三部分-托管数组结构
原文地址:https://devblogs.microsoft.com/premier-developer/managed-object-internals-part-3-the-layout-of-a-managed-array-3/
原文作者:Sergey
译文作者:杰哥很忙
目录
托管对象本质1-布局
托管对象本质2-对象头布局和锁成本
托管对象本质3-托管数组结构
托管对象本质4-字段布局
数组是每个应用程序的基本构建基块之一。即使你不是每天直接使用数组,你也可以将他们作为库包的一部分间接使用。
C# 一直都有数组结构,数组结构也是唯一一个类似泛型而且类型安全的数据结构。现在你可能没有那么频繁的直接使用他们,但是为了提升性能,都有可能会从一些更高级的数据结构(比如List<T>)切换回数组。
数组和CLR有着非常特殊的关系,但是今天我们将从用户的角度来探讨它们。我们将讨论以下内容:
* 探索一个最奇怪的 C# 功能,称为数组协方差
* 讨论数组的内部结构
* 探索一些性能技巧,我们可以这样做,从数组中挤压更多的性能
数组协方差和一些历史
C# 语言中最奇怪的特征之一是数组协方差:能够将T类型的数组赋值给object类型或任何其他T类型的基类的数组的能力。
string[] strings = new[] { "1", "2" };
object[] objects = strings;
这个转换并完全是类型安全的。如果objects变量仅用于读取数据,那么一切正常。但是,如果尝试修改数组时,如果参数的类型不兼容,则可能会失败。
objects[0] = 42; //运行时错误
关于这个特性,.NET 社区中有一个众所周知的笑话:C# 作者在一开始非常努力地将 Java 生态系统的各个方面复制到 CLR 世界,所以他们也复制了语言设计问题。
但是我并不认为这是原因:)
在 90 年代后期,CLR 并没有泛型,对吗?在这种情况下,语言用户如何编写处理任意数据类型数组的可重用代码?例如,如何编写将任意数组转储到控制台的函数?
一种方法是定义接收object[]的函数,并通过将数组复制到对象数组来强制每个调用方手动转换数组。这是可行的,但效率很低。另一种解决方案是允许从任何引用类型的数组转换为object[],即保留 Derived[]到 Base[] 的 IS-A 关系,其中派生类从基类继承。在值类型的数组中,转换不起作用,但至少可以实现一些通用性。
第一个 CLR 版本中缺少泛型,迫使设计人员削弱类型系统。但是这个决定(我想)是经过深思熟虑的,而不仅仅是来自Java生态系统的模仿。
内部结构和实现细节
数组协方差在编译时在类型系统中打开一个洞,但这并不意味着类型错误会使应用程序崩溃(C++中的类似"错误"将导致"未定义行为")。CLR 将确保类型安全,但检查会在运行时进行。为此,CLR 必须存储数组元素的类型,并在用户尝试更改数组实例时进行检查。幸运的是,此检查仅对引用类型的数组是必需的,因为struct是密封的(sealed),因此不支持继承。
译者补充:struct由于是值类型,我们可以查看它的IL语言,可以看到struct前会有
sealed关键字。
尽管不同值类型(如 int 到 byte)之间存在隐式转换,但 int[] 和 byte[]之间没有隐式或显式转换。数组协方差转换是引用转换,它不会更改转换对象的布局,并保留要转换对象的引用标识。
在旧版本的 CLR 中,引用数组和值类型具有不同的布局。引用类型的数组具有对每个实例中元素的类型句柄的引用:
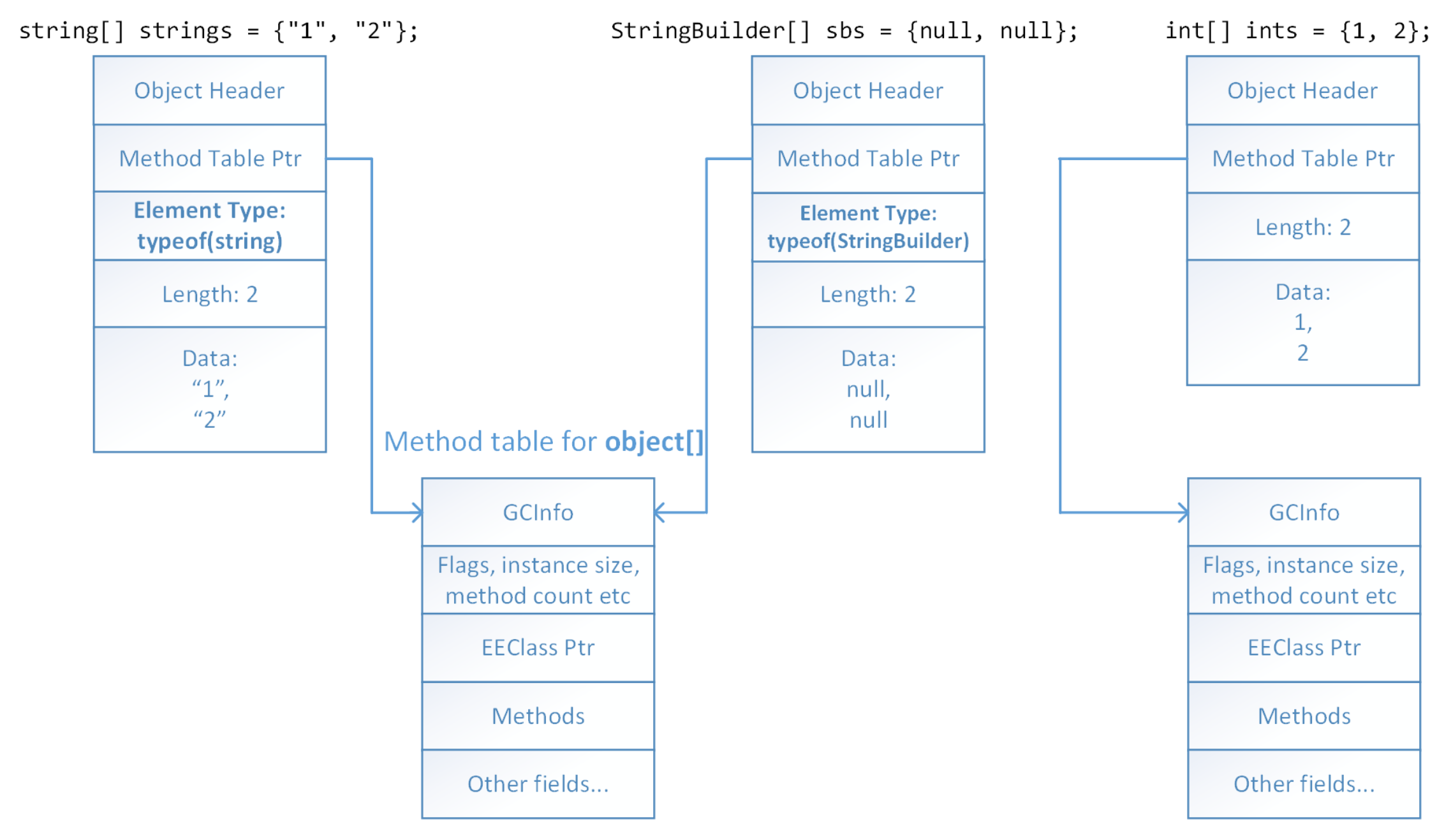
这在最新版本的 CLR 中已更改,现在元素类型存储在方法表中:
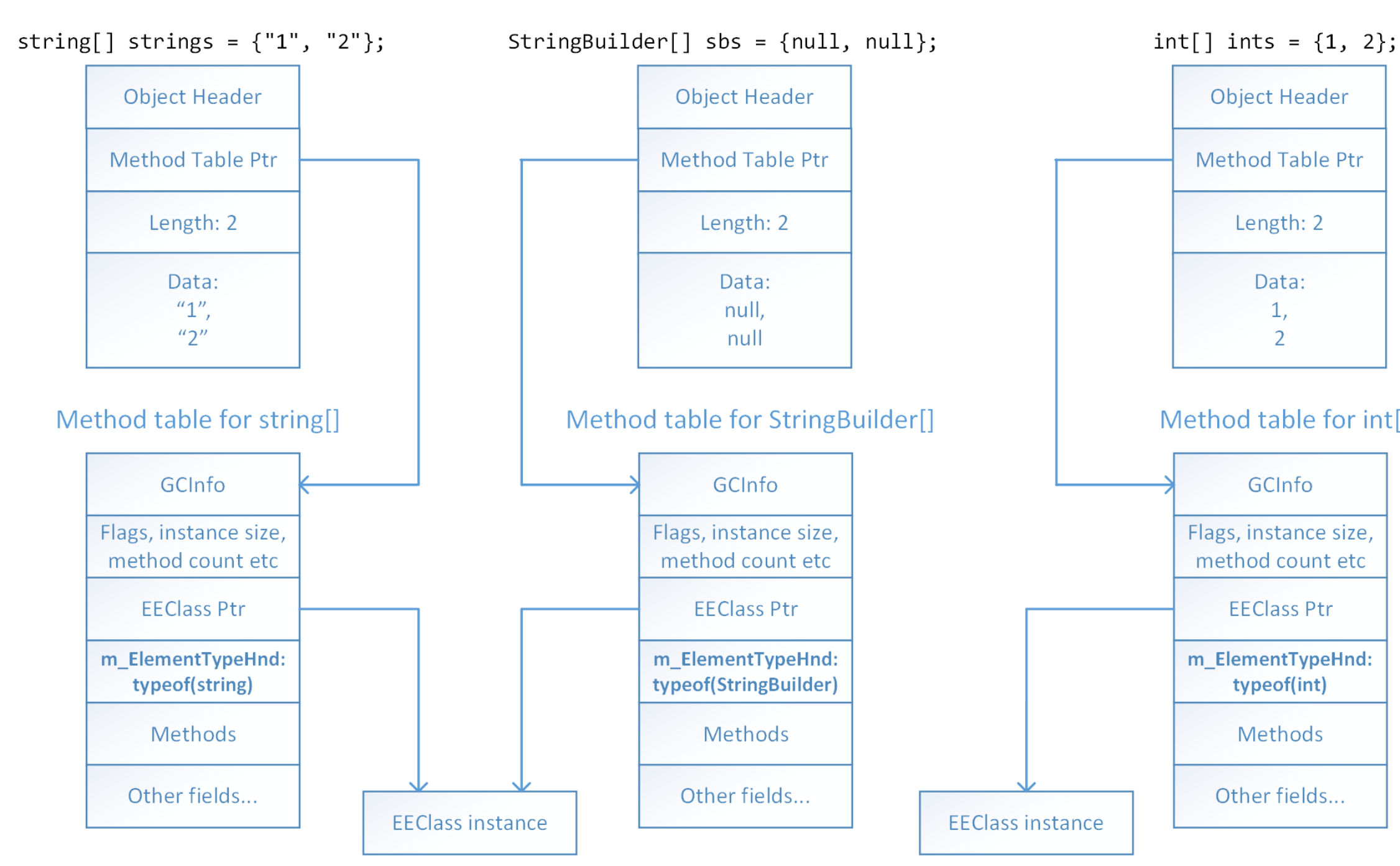
有关布局的详细信息,请参阅 CoreClr 代码库中的以下代码段:
// Get the element type for the array, this works whether the element
// type is stored in the array or not
inline TypeHandle GetArrayElementTypeHandle() const;
TypeHandle GetArrayElementTypeHandle()
{
LIMITED_METHOD_CONTRACT;
return GetMethodTable()->GetApproxArrayElementTypeHandle();
}
TypeHandle GetApproxArrayElementTypeHandle()
{
LIMITED_METHOD_DAC_CONTRACT;
_ASSERTE(IsArray());
return TypeHandle::FromTAddr(m_ElementTypeHnd);
}
union
{
PerInstInfo_t m_pPerInstInfo;
TADDR m_ElementTypeHnd;
TADDR m_pMultipurposeSlot1;
};
我不确定数组布局是什么时候改变的,但似乎在速度和(托管)内存之间有一个权衡。由于内存局部性,初始实现(当类型句柄存储在每个数组实例中时)访问应该更快,但肯定有不可忽略的内存开销。当时,所有引用类型的数组都有共享方法表。但现在情况不一样了:每个引用类型的数组都有自己的方法表,该表指向相同的 EEClass ,指针指向元素类型句柄的指针。
也许CLR团队的人可以解释一下.
我们知道 CLR 如何存储数组的元素类型,现在我们可以探索 CoreClr 代码库,看看实现类型检查。
首先,我们需要找到检查发生的位置。数组是 CLR 的一种非常特殊的类型,IDE 中没有"转到声明"按钮来"反编译"数组并显示源代码。但是我们知道,检查发生在索引器setter中,它与一组IL指令StElem*相对应:
* StElem.i4 用于整型数组
* StElem 用于任意值类型数组
* StElem.ref 用于引用类型数组
了解指令后,我们可以轻松地在代码库中找到实现。据我所知,实现在了jithelpers.cpp中。下面是方法JIT_Stelem_Ref_Portable稍微简化的版本:
/****************************************************************************/
/* assigns 'val to 'array[idx], after doing all the proper checks */
HCIMPL3(void, JIT_Stelem_Ref_Portable, PtrArray* array, unsigned idx, Object *val)
{
FCALL_CONTRACT;
if (!array)
{
// ST: explicit check that the array is not null
FCThrowVoid(kNullReferenceException);
}
if (idx >= array->GetNumComponents())
{
// ST: bounds check
FCThrowVoid(kIndexOutOfRangeException);
}
if (val)
{
MethodTable *valMT = val->GetMethodTable();
// ST: getting type of an array element
TypeHandle arrayElemTH = array->GetArrayElementTypeHandle();
// ST: g_pObjectClass is a pointer to EEClass instance of the System.Object
// ST: if the element is object than the operation is successful.
if (arrayElemTH != TypeHandle(valMT) && arrayElemTH != TypeHandle(g_pObjectClass))
{
// ST: need to check that the value is compatible with the element type
TypeHandle::CastResult result = ObjIsInstanceOfNoGC(val, arrayElemTH);
if (result != TypeHandle::CanCast)
{
// ST: ArrayStoreCheck throws ArrayTypeMismatchException if the types are incompatible
if (HCCALL2(ArrayStoreCheck, (Object**)&val, (PtrArray**)&array) != NULL)
{
return;
}
}
}
HCCALL2(JIT_WriteBarrier, (Object **)&array->m_Array[idx], val);
}
else
{
// no need to go through write-barrier for NULL
ClearObjectReference(&array->m_Array[idx]);
}
}
通过删除类型检查来提高性能
现在我们知道,CLR 确实在底层确保引用类型数组的类型安全。对数组实例的每个"写入"都有一个附加检查,如果数组在热路径上中使用,则该检查不可忽略。但在得出错误的结论之前,让我们先看看这个检查的性能消耗程度。
译者补充:热路径指的是那些会被频繁调用的代码块。
为了避免检查,我们可以更改 CLR,或者使用一个众所周知的技巧:将对象包装到结构中
public struct ObjectWrapper
{
public readonly object Instance;
public ObjectWrapper(object instance)
{
Instance = instance;
}
}
比较 object[] 和 ObjectWrapper[]的时间
private const int ArraySize = 100_000;
private object[] _objects = new object[ArraySize];
private ObjectWrapper[] _wrappers = new ObjectWrapper[ArraySize];
private object _objectInstance = new object();
private ObjectWrapper _wrapperInstanace = new ObjectWrapper(new object());
[Benchmark]
public void WithCheck()
{
for (int i = 0; i < _objects.Length; i++)
{
_objects[i] = _objectInstance;
}
}
[Benchmark]
public void WithoutCheck()
{
for (int i = 0; i < _objects.Length; i++)
{
_wrappers[i] = _wrapperInstanace;
}
}
结果如下:
| Method | 平均值 | 错误 | 标准差 |
|---|---|---|---|
| WithCheck | 807.7 us | 15.871 us | 27.797 us |
| WithoutCheck | 442.7 us | 9.371 us | 8.765 us |
不要被"几乎 2 倍"的性能差异所迷惑。即使在最坏的情况下,分配 100K 元素也不到一毫秒。性能表现非常好。但在现实世界中,这种差异是显而易见的。
许多性能关键的 .NET 应用程序使用对象池。池允许重用托管实例,而无需每次都创建新实例。此方法降低了内存压力,并可能对应用程序性能产生非常合理的影响。
可以基于并发数据结构(如ConcurrentQueue)或基于简单数组实现对象池。下面是 Roslyn 代码库中对象池实现的代码段:
internal class ObjectPool<T> where T : class
{
[DebuggerDisplay("{Value,nq}")]
private struct Element
{
internal T Value;
}
// Storage for the pool objects. The first item is stored in a dedicated field because we
// expect to be able to satisfy most requests from it.
private T _firstItem;
private readonly Element[] _items;
// other members ommitted for brievity
}
该实现管理一个缓存项数组,但池化并不是直接使用 T[],而是将 T 包装到结构元素中,以避免在运行时进行检查。
前段时间,我在应用程序中修复了一个对象池,使得解析阶段的性能提升了的 30%。这不是由于我在这里描述的技巧,是与池的并发访问相关。但关键是,对象池可能位于应用程序的热路径上,甚至像上面提到的小性能改进也可能对整体性能产生明显影响。
微信扫一扫二维码关注订阅号杰哥技术分享
出处:https://www.cnblogs.com/Jack-Blog/p/12266538.html
作者:杰哥很忙
本文使用「CC BY 4.0」创作共享协议。欢迎转载,请在明显位置给出出处及链接。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号