Faster-Rcnn的loss曲线可视化
http://blog.csdn.net/wxplol/article/details/73694657
http://www.cnblogs.com/ymjyqsx/p/7059280.html
由于要写论文需要画loss曲线,查找网上的loss曲线可视化的方法发现大多数是基于Imagenat的一些方法,在运用到Faster-Rcnn上时没法用,本人不怎么会编写代码,所以想到能否用python直接写一个代码,读取txt然后画出来,参考大神们的博客,然后总和总算一下午时间,搞出来了,大牛们不要见笑。
首先,在训练Faster-Rcnn时会自己生成log文件,大概在/py-faster-rcnn/experiments/logs文件下,把他直接拿出来,放在任意位置即可,因为是txt格式,可以直接用,如果嫌麻烦重命名1.txt.接下来就是编写程序了
一下为log基本的格式
I0530 08:54:19.183091 10143 solver.cpp:229] Iteration 22000, loss = 0.173712
I0530 08:54:19.183137 10143 solver.cpp:245] Train net output #0: rpn_cls_loss = 0.101713 (* 1 = 0.101713 loss)
I0530 08:54:19.183145 10143 solver.cpp:245] Train net output #1: rpn_loss_bbox = 0.071999 (* 1 = 0.071999 loss)
I0530 08:54:19.183148 10143 sgd_solver.cpp:106] Iteration 22000, lr = 0.001
通过发现,我们只需获得 Iteration 和loss就行
- #!/usr/bin/env python
- import os
- import sys
- import numpy as np
- import matplotlib.pyplot as plt
- import math
- import re
- import pylab
- from pylab import figure, show, legend
- from mpl_toolkits.axes_grid1 import host_subplot
- # read the log file
- fp = open('2.txt', 'r')
- train_iterations = []
- train_loss = []
- test_iterations = []
- #test_accuracy = []
- for ln in fp:
- # get train_iterations and train_loss
- if '] Iteration ' in ln and 'loss = ' in ln:
- arr = re.findall(r'ion \b\d+\b,',ln)
- train_iterations.append(int(arr[0].strip(',')[4:]))
- train_loss.append(float(ln.strip().split(' = ')[-1]))
- fp.close()
- host = host_subplot(111)
- plt.subplots_adjust(right=0.8) # ajust the right boundary of the plot window
- #par1 = host.twinx()
- # set labels
- host.set_xlabel("iterations")
- host.set_ylabel("RPN loss")
- #par1.set_ylabel("validation accuracy")
- # plot curves
- p1, = host.plot(train_iterations, train_loss, label="train RPN loss")
- #p2, = par1.plot(test_iterations, test_accuracy, label="validation accuracy")
- # set location of the legend,
- # 1->rightup corner, 2->leftup corner, 3->leftdown corner
- # 4->rightdown corner, 5->rightmid ...
- host.legend(loc=1)
- # set label color
- host.axis["left"].label.set_color(p1.get_color())
- #par1.axis["right"].label.set_color(p2.get_color())
- # set the range of x axis of host and y axis of par1
- host.set_xlim([-1500,60000])
- host.set_ylim([0., 1.6])
- plt.draw()
- plt.show()
参考博客地址:
http://blog.csdn.net/YhL_Leo/article/details/51774966
解决caffe绘制训练过程的loss和accuracy曲线时候报错:paste: aux4.txt: 没有那个文件或目录 rm: 无法删除"aux4.txt": 没有那个文件或目录https://www.yuanmas.com/info/okzVl6WGyv.html
我用的是faster-rcnn,在绘制训练过程的loss和accuracy曲线时候,抛出如下错误,在网上查找无数大牛博客后无果,自己稍微看了下代码,发现,extract_seconds.py文件的
get_start_time()函数在获取时间时候获取失败,因为if line.find(‘Solving‘) != -1:这个语句判断错误导致,具体解决办法:
将该函数改造成:
def get_start_time(line_iterable, year):
"""Find start time from group of lines
"""
start_datetime = None
for line in line_iterable:
line = line.strip()
#if line.find(‘Solving‘) != -1:
start_datetime = extract_datetime_from_line(line, year)
break
return start_datetime
没错,就是把这个判断注释掉就ok了!
但是还有一个问题:解析出来的两个文件,分别是:mylog.train和mylog.test,其中mylog.test是个空文件,很是无语,暂时不想去深探原因,求各位看客帮
=======================================================================================================================================================
绘制loss曲线
第一步保存日志文件,用重定向即可:
$TOOLS/caffe train --solver=$SOLVERFILE 2>&1 |tee out.log
第二步直接绘制:
python plot_training_log.py 2 testloss.png out.log
这个plot_training_log.py在这个目录下caffe-fast-rcnn/tools/extra
2是选择画哪种类型的图片,具体数字是代表哪个类型可以查看帮助信息看到:
0: Test accuracy vs. Iters
1: Test accuracy vs. Seconds
2: Test loss vs. Iters
3: Test loss vs. Seconds
4: Train learning rate vs. Iters
5: Train learning rate vs. Seconds
6: Train loss vs. Iters
7: Train loss vs. Seconds
testloss.png是生成图片的名字,要求必须是png类型的文件
out.log是之前生成的日志文件
有个教程让你先生成解析日志文件:用:./parse_log.sh xxxxxxx.log
python parse_log.py out.log ./
注意最后一个是./,是保存的路径,最后会生成.train和.test两个文件。
实际上我觉得没有必要执行这一步,直接绘制曲线就好,绘制曲线中间也会生成这两个文件,因为plot_training_log.py本身要调用parse_log.py的shell脚本。并且生成的文件第一行是自带'#',但是用这个解析生成的反而是不带的。
跑项目代码时,生成的日志文件有一点问题,一个正常的日志文件应该是这样:

而我的日志文件是这样;
 即在Iteration前我的日志文件没有I0619 10:29:45.757735 8944 solver.cpp:280] Solving deeplab_largeFOV 这句话,在parse_log.sh里有这样一句:grep '] Solving ' $1 > aux3.txt,要寻找 '] Solving ',如果没有,生成的aux3.txt就为空,
即在Iteration前我的日志文件没有I0619 10:29:45.757735 8944 solver.cpp:280] Solving deeplab_largeFOV 这句话,在parse_log.sh里有这样一句:grep '] Solving ' $1 > aux3.txt,要寻找 '] Solving ',如果没有,生成的aux3.txt就为空,
因为aux4.txt是由aux3.txt来的,这样就无法生成aux4.txt,也就报错说不能paste和rm aux4.txt。在extract_seconds.py中也是通过寻找sovling来确定开始时间的。如果单独用parse_log.py生成日志文件,不会报aux4.txt的错误,但会报extract_seconds.py
的错误。所以在Iteration 0前面一行加上没有这句话,就能解决问题。
在parse_log.sh中两行代码:
grep '] Solving ' $1 > aux3.txt # grep 'Testing net' $1 >> aux3.txt grep 'Train net' $1 >> aux3.txt
这两行代码都是搜索含有字符串的行然后写入aux3.txt。因为我的日志中没有] Solving,并且我的是训练日志,也没有Testing net,所以在没有添加] Solving的时候去运行脚本就报了:无法paste,rm aux4.txt的错误。实际上是因为没有任何东西写进aux3.txt,
aux3.txt是空的,所以运行$DIR/extract_seconds.py aux3.txt aux4.txt就不会生成aux4.txt。当然也就没办法paste,rm。修改的方法可以把Testing net改成Train net,这样可以在日志文件中找到行写入aux3.txt。或者在日志中添加] Solving让能有东西写进
aux3.txt。其实两种改法都可以,反正这个脚本之后要删除这些临时文件,然后再取生成.train的东西,这样改只是为了让程序不报错,能正常运行。
plot_training_log.py.example里的load_data函数也需要改一下,原本的代码是:

def load_data(data_file, field_idx0, field_idx1):
data = [[], []]
with open(data_file, 'r') as f:
for line in f:
line = line.strip()
if line[0] != '#':
fields = line.split()
data[0].append(float(fields[field_idx0].strip()))
data[1].append(float(fields[field_idx1].strip()))
return data
这段代码是从中间生成的日志文件读取你需要项的数据,!= '#'其实就是不读取第一行的项信息,这是中间文件:
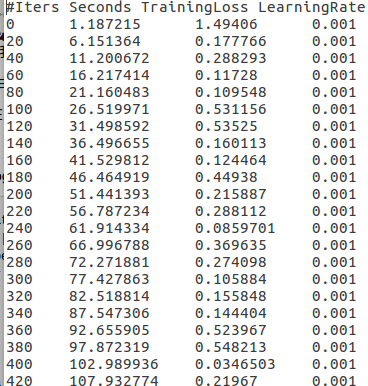
直接用会报字符串无法转换成float的错误,原代码里对每一行split空格后生成的list,不是只含这4个数字的list,而是含有许多空格的list,所以当然float无法转换空格字符。需要做的就是split掉所有的空格,生成一个大小为4只包含4个数字的list。
这里需要注意个问题,日志文件中两个数字间的间隔的空格数是不一样的,有的是4个,有的是5个,代码需要实现无论多少个空格,都split掉。
修改代码:
def load_data(data_file, field_idx0, field_idx1):
data = [[], []]
with open(data_file, 'r') as f:
for line in f:
line = line.strip()
if line[0] != '#':
line=','.join(filter(lambda x: x, line.split(' ')))
print line
fields = line.split(',')
print fields
data[0].append(float(fields[field_idx0].strip()))
data[1].append(float(fields[field_idx1].strip()))
return data
这个的filter实现了功能。filter先split生成了一个每个空格占一个位置的list。
以下这张图大概模拟了一下过程:

可以看到split之后一个空格占一个位置。实际上我发现,这个filter函数,要想完成我需要的功能,只能处理list中任何带空格的位置都只能有一个空格,如果包含两个或其他多个,就不能实现过滤掉空格的功能,下图做了演示:

实际上,这样做很麻烦,split函数里面什么都不加,就会处理掉所有空格,无论空格多少个,即split(),如下图:

我最初绘制的loss曲线是将日志中每个loss都显示,但曲线误差大,不平滑,不便于分析:

造成这种原因是,在项目中,batch_size大小是2,即每次处理两张图片,在终端每20个迭代期显示一次loss,也就是每个loss是40张图片的,有可能某几张图片的loss比较大,就造成这一段迭代期的误差大。基于此,我将图像显示换成连续10个loss的平均,相当于200个迭代期的平均loss,这样下来波动就小了很多,方便分析:

生成的日志文件,无论是40000迭代期,还是80000,在20000时都要进入ipython,造成日志的格式不对,导致画不出图像,在后面的迭代期也会显示一些奇怪的东西,反正都需要删除掉,之后就能正常显示图像:


1 tools/extra/parse_log.sh中
第17行第48列
源程序:sed -n '/Iteration .* Testing net/,/Iteration *. loss/p' $1 > aux.txt
修正为:sed -n '/Iteration .* Testing net/,/Iteration .* loss/p' $1 > aux.txt
2 由于自己想在同一个窗口画多个log文件形成对比,所以希望每条曲线的label不同,本代码所有曲线上label都是‘x’,我修正成了随机,源代码已经写了随机的部分,但是最后用的时候却有点匪夷所思,个人觉得可能是作者的疏忽,而且之前也没见人提出这个问题。个人愚见,有不同意的还请勿喷。
tools/extra/plot_training_log.py.example
第95行第20列
源程序:return markers.values()[idx]
修改为:return markers.keys()[idx]
修改完毕后,达到了我自己想要的效果。大家可以借鉴。
注意1:如果有Invalid DISPLAY variable的报错,就在plot_training_log.py.example中修改。我按照下图该就ok了。
注意2:如果生成train loss相关图像时报错,可能是日志解析有问题,查看caffe.log.train是否正确,如果错误,需要更改parse_log.sh。我按照以下这样改就ok了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号