

Facial Expression Recognition by De-expression Residue Learning
面部残余表情学习表情识别方法(略去了实验)
摘要:
一个人的人脸表情是由表情和中性脸组成。在这篇文章中,我们提出通过识别面部表情通过提取表情组成部分的信息通过表情元素滤除的残余表情识别算法(DERL)。首先,通过cGAN训练一个生成模型。这个模型对于任何输入的人脸图片生成大致相当的中性脸。我们把它叫做de-expression是因为这个表情被这个生成模型筛选;然而,表情信息依旧在中间层记录。给定中性脸,不像以前使用像素级或者特征级的不同去识别表情,我们的新方法学习生成模型的中间层残留的残余表情。这个样的残留表情是重要的,因为它包含任何输入表情图片沉淀在生成模型的表情成分。七种公开的面部表情数据集在我们的试验中使用。两个数据集作为预训练,在CK+, Oulu-CASIA, MMI, BU-3DFE, and BP4D+.五个数据集上进行了评估。实验结果阐述了我们提出方法的优越性。
引言:
人脸表情识别的研究进行在各种变化的图片条件下,包括各种各样的头部姿势,光照条件,分辨率和隐藏。尽管在提高表情分类上取得了重大意义的突破,当前的主要挑战来自个体差异的巨大变化,例如:年龄,性别,种族背景和个人差异。不同的人由于不同的风格和不同的表情表达方式会展现出不同的表情。只有最近的论文工作开始着手这个方面的工作,把个人性格种族年龄等考虑在人脸表情分析中。 研究表明,人类有能力去识别面部表情通过比较表情脸和中性脸。换句话说,一个人脸表情可以用表情和中性脸组成。到现在,许多现存的工作利用图片差异和特征差异对于识别图片和中性图片去识别面部表情。然而,这个假定是中性脸是获得的。事实是,中性脸可能不能经常获得。为了减缓这个问题,这是一个要求取获得一个中性表情生成器在给定的表情输入上。生成对抗模型有能力取解决这个问题。为了训练一个生成模型,一个生成对抗框架利用其他的深度模型去(辨别器)和生成模型对抗而不是为这个生成器定义一个常用的损失函数。这个辨别器被设计用来区分采样来自生成的的训练数据;而发生器学会输出最大程度混淆鉴别器的样本。一个基础的GAN扩展是条件GAN,它能够通过额外的条件变化来学习不同的上下文信息。现有的工作将CNN和cGAN结合起来用于许多应用,包括facegeneration [7],边缘地图的对象重建[11]和对象属性操作[24]。
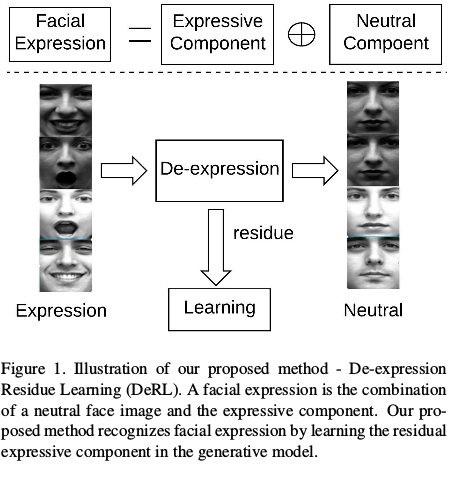
在这篇文章中,我们提出了一种新的方法叫做残余表情学习去学习面部表情通过提取表情残余手段。如图一所示,给定一个致力于面部表情的人脸,他的大致的中性表情被训练好的生成模型产生。经过这个步骤,当表达组件被移除时,主题的身份信息保持不变。我们把它叫做残余表情信息。尽管带有表达式的输入图像被“标准化”为中性表达式作为输出,但被过滤出来的表情成分仍然沉淀在生成模型中。换句话说,表情信息,在残余过程中表情信息被记录在生成器中。这样的沉淀是表情元素的残留。这是精确的表情成分我们想要在表情分类中使用。
相比于之前的对输入表情图片和中性图片用像素差异或特征水平差异的方法,我们提出的DERL框架学习残余在生成模型中的残余表情元素,试图去缓和个体特征的影响并提高面部表情识别能力。这项工作的贡献有两方面:
1、我们提出了一种新奇的方法去学习表情通过表情元素。我们首先训练一个生成模型去为查询的图片生成大致的中性脸;然后学习生成模型的的残留,这是为了减缓识别相关的变化因素。
2、我们提出的方法有能力处理无意识的表情、姿势表情、变化类型和种族背景等情形。他成功地提高了单数据集的识别能力,在交叉验证数据集上也比最先进的方法表现好。
2、相关工作
以前的工作表明使用中性脸对面部表情识别有益。从像素级或特征级别的相应面部表情图像中减去中性面部图像可以强调面部表情,同时减少类内变异。
Bazzo et al.[2]通过应用Gabor 小波在提取的中性脸上,获得了良好的识别率。Zafeiriou etal.[30]对于不同的图片应用稀疏面部表情表示,这是从表现中性图像中减去中性图像得出的,并证明使用中性图像往往强调移动的面部部分。Lee at al.[15]从训练集生成几个类内变异图像(包括中性),然后由待识别面部图像减去
获得不同的图像。 差异图像用于强调查询面部图像中的面部表情。
Kim et al.[13]在网络中采用对比表示来提取查询面部图像和中性面部图像之间的特征级别差异。
然而,这些先前的论文假设在给定相同主题的任何表达的情况下中性表达总是可用的,这是不现实的。根据需要从任何输入表情生成中性脸。最近的工具-GAN在展现出成功在这样的应用。Gauthier [7]试图用CGAN去生成特定属性的人脸,Radford et al. [24][24]尝试使用CNN来扩大GAN以模拟图像,并引入深度卷积生成对抗网络(DCGAN)的结构。这项工作展示了通过矢量算法操纵生成的面部样本的能力。Isola等。 [11]利用条件性逆向网络进行图像到图像的转换,并展示了许多有趣的应用,即从地图生成航空照片,从边缘地图重建物体,以及着色图像。此外,周等人[36] 应用cGAN来合成来自中性面部的面部表情图像。
到目前为止,已经使用查询图像和生成的中性图像的图像或特征差异,但是没有探索生成模型中记录的任何隐式表达信息。我们提出去探索表情信息,那些插入在生成器中,并且在中间层直接提取表情成分。事实上,这样的信息这种信息在去表达过程中由发生器“滤除”,而其表示(或残留)仍然存放在生成模型中,因此成为表示表达成分的关键信息。我们提出的方法不是同时使用查询图像和生成的中性人脸图像来训练具有对比度损失函数的深度模型(例如[13]),而是着重于学习生成模型的残差,从而有效地捕获表达成分和 对个体变化更加健壮。

3、提出方法 - DeRL
我们提出的DERL方法结构框架如图2。包含两个学习过程:第一步是通过cGANs学习中性脸生成器。第二步是从生成器中间层学习。输入图像对e.g. < I input , I target >,被用来训练cGANs.我输入的是显示任何表情的脸部图像,而我的目标是同一主题的中性脸部图像。在训练之后,生成器为任何输入重建相应的中性面部图像,同时保持身份信息不变。 从表情面部图像到中性面部图像,表达相关信息被记录为中间层中的表达成分。 对于第二学习过程,生成器的参数是固定的,并且中间层的输出被组合并输入到用于面部表情分类的深度模型中。
3.1中性脸生成器
cGAN被利用去通过给定的表情图片生成中性面部表示。一个GAN框架经常包含两个不同的部分,一个生成器(G),和一个判别器(d)训练发生器通过用鉴别器进行所谓的minmax游戏来恢复训练数据的分布。提供图像对<I input,I target>用于训练cGAN.我输入首先输入到生成器中以重新构造I输出,然后<I input,I target,yes>和<I input,I output,no>被赋予鉴别器。 鉴别器试图在生成器尝试时将<I input,I target>与<I input,I
output>区分开来.不仅最大限度地混淆鉴别器,而且还产生尽可能接近目标图像的图像。
鉴别器的目标表示为:
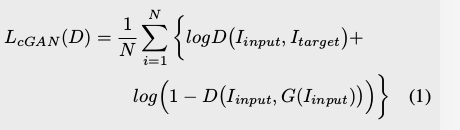
其中N是训练图相对的总数
生成器的目标形容如下:

在这里,我们使用L1损失来获得图像相似度而不是L2,因为L2损失倾向于过度模糊输出图像[11]。 最终目标是:


3.2面部表情识别组成
经过中性脸生成,可以在像素级或者特征级通过比较中性脸和待识别表情来分析表情信息。然而,由于图像之间的变化,即旋转,平移和照明条件变化,像素级差异是不可靠的。即使没有表达式更改,这也会导致较大的像素级差异。 此外,特征级别差异是不稳定的,因为表达信息可能根据身份信息而变化。 由于查询图像和中性图像的差异记录在中间层中,我们利用表达式 直接从中间层中分解成分,以缓解上述问题,
我们用面部表情表示一个图像:I
在输入生成模型后,生成中性表达图像:
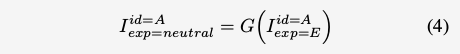
其中,G是生成器,E属于六种基本原型面部表情中的任何一种。 从等式(4),我们可以看到具有主题(A)和表达(E)的图像变为同一主题(A)的中性面部。可以合理地得出结论,每个人的独特表达信息(a.k.a.表达成分)必须记录在发生器的中间层中。 因此,我们提出了第二种学习策略,即直接从发生器的中间层学习表达式。 该独特信息也称为去表达残基(例如,参见图3)。
如图2所示,为了从发生器的中间层学习去表达残差,这些层的所有滤波器都是固定的,并且具有相同大小的所有层被连接并输入到本地CNN中。 面部表情分类模型。 对于每个本地CNN模型,代价函数被标记为损失i,i∈[1,2,3,4]。 每个本地CNN模型的最后完全连接的层被进一步连接并与用于面部表情分类的最后编码层组合。 因此,总损失函数定义为:

