WEEK12:Mysql and ORM
- 关系数据库管理系统(RDBMS)
- 特点
- 数据以表格的形式出现
- 每行为各种记录名称
- 每列为记录名称所对应的数据域
- 许多的行和列组成一张表单
- 若干的表单组成database
- 术语
- 数据库: 数据库是一些关联表的集合
- 数据表: 表是数据的矩阵。在一个数据库中的表看起来像一个简单的电子表格
- 列: 一列(数据元素) 包含了相同的数据, 例如邮政编码的数据
- 行:一行(=元组,或记录)是一组相关的数据,例如一条用户订阅的数据
- 冗余:存储两倍数据,冗余可以使系统速度更快
- 主键:主键是唯一的。一个数据表中只能包含一个主键。你可以使用主键来查询数据
- 外键:外键用于关联两个表
- 复合键:复合键(组合键)将多个列作为一个索引键,一般用于复合索引
- 索引:使用索引可快速访问数据库表中的特定信息。索引是对数据库表中一列或多列的值进行排序的一种结构。类似于书籍的目录
- 参照完整性: 参照的完整性要求关系中不允许引用不存在的实体。与实体完整性是关系模型必须满足的完整性约束条件,目的是保证数据的一致性。
- Mysql数据库(MariaDB)
最流行的关系型数据库管理系统- 特点:
- Mysql是开源的,所以你不需要支付额外的费用
- Mysql支持大型的数据库。可以处理拥有上千万条记录的大型数据库
- Mysql使用标准的SQL数据语言形式
- Mysql可以允许于多个系统上,并且支持多种语言。这些编程语言包括C、C++、Python、Java、Perl、PHP、Eiffel、Ruby和Tcl等
- Mysql对PHP有很好的支持,PHP是目前最流行的Web开发语言
- MySQL支持大型数据库,支持5000万条记录的数据仓库,32位系统表文件最大可支持4GB,64位系统支持最大的表文件为8TB
- Mysql是可以定制的,采用了GPL协议,你可以修改源码来开发自己的Mysql系统
- 管理命令
- USE 数据库名:选择要操作的Mysql数据库,使用该命令后所有Mysql命令都只针对该数据库
- SHOW DATABASES:列出 MySQL 数据库管理系统的数据库列表
- SHOW TABLES:显示指定数据库的所有表,使用该命令前需要使用 use命令来选择要操作的数据库
- SHOW COLUMNS FROM 数据表: 显示数据表的属性,属性类型,主键信息 ,是否为 NULL,默认值等其他信息
- CREATE DATABASE testdb CHARSET "utf8":创建一个叫testdb的数据库,且让其支持中文
- DROP DATABASE testdb:删除数据库
- SHOW INDEX FROM 数据表:显示数据表的详细索引信息,包括PRIMARY KEY(主键)
- 常用命令
- 创建数据表
- 语法
CREATETABLEtable_name (column_name column_type); - 实例
create table student(
stu_id INT NOT NULL AUTO_INCREMENT,
name CHAR(32) NOT NULL,
age INT NOT NULL,
register_date DATE,
PRIMARY KEY ( stu_id ));
- 解析
- 如果你不想字段为 NULL 可以设置字段的属性为 NOT NULL, 在操作数据库时如果输入该字段的数据为NULL ,就会报错
- AUTO_INCREMENT定义列为自增的属性,一般用于主键,数值会自动加1
- PRIMARY KEY关键字用于定义列为主键。 您可以使用多列来定义主键,列间以逗号分隔
- 解析
- 语法
- 插入数据
- 语法
INSERT INTO table_name ( field1, field2,...fieldN ) VALUES ( value1, value2,...valueN ); - 实例
insert into student (name,age,register_date) values ("alex li",22,"2016-03-4");
- 语法
- 格式化输出
select * from student\G
加\G之后不再需要加分号 - 查看数据表属性
desc student; - 查询数据
- 语法
SELECT column_name,column_name
FROM table_name
[WHERE Clause]
[OFFSET M ][LIMIT N]- 解析
- 查询语句中你可以使用一个或者多个表,表之间使用逗号(,)分割,并使用WHERE语句来设定查询条件
- SELECT 命令可以读取一条或者多条记录
- 可以使用星号(*)来代替其他字段,SELECT语句会返回表的所有字段数据
- 可以使用 WHERE 语句来包含任何条件
- 可以通过OFFSET指定SELECT语句开始查询的数据偏移量。默认情况下偏移量为0
- 可以使用 LIMIT 属性来设定返回的记录数
- 解析
- 实例
limit后面跟的是3条数据,offset后面是从第3条开始读取select * from student limit 3 offset 2;limit后面是从第3条开始读,读取1条信息
select * from student limit 3 ,1;
- 语法
- WHERE 子句
- 语法
SELECTfield1, field2,...fieldNFROMtable_name1, table_name2...[WHEREcondition1 [AND[OR]] condition2..... - 实例
使用主键来作为 WHERE 子句的条件查询是非常快速的
select*fromstudentwhereregister_date >'2016-03-04';
- 语法
- UPDATE 更新
- 语法
UPDATEtable_nameSETfield1=new-value1, field2=new-value2[WHEREClause] - 实例
updatestudentsetage=22 ,name="Alex Li"wherestu_id>3;
- 语法
- DELETE 语句
- 语法
DELETEFROMtable_name [WHEREClause]deletefromstudentwherestu_id=5;
- 语法
- LIKE 子句
- 语法
SELECTfield1, field2,...fieldN table_name1, table_name2...WHEREfield1LIKEcondition1 [AND[OR]] filed2 ='somevalue' - 实例
select*fromstudentwherenamebinarylike"%Li"; #binary则是将内容强制转换成二进制的字符串select*fromstudentwherenamebinarylikebinary"%Li"; #只匹配大写,like binary 用来区分大小写
- 语法
- 排序
- 语法
SELECTfield1, field2,...fieldN table_name1, table_name2...ORDERBYfield1, [field2...] [ASC[DESC]]
使用ASC或DESC关键字来设置查询结果是按升序或降序排列。 默认情况下,它是按升序排列。 - 实例
select*fromstudentwherenamelikebinary"%Li"orderbystu_iddesc;
- 语法
- GROUP BY语句
- 语法
SELECTcolumn_name,function(column_name)FROMtable_nameWHEREcolumn_name operator valueGROUPBYcolumn_name; - 实例
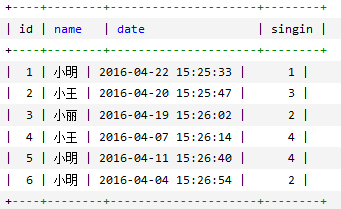
![]()
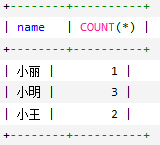
使用GROUPBY语句 将数据表按名字进行分组,并统计每个人有多少条记录SELECTname,COUNT(*)FROMemployee_tblGROUPBYname;![]()
-
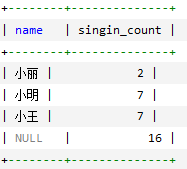
使用WITHROLLUPSELECTname,SUM(singin)assingin_countFROMemployee_tblGROUPBYnameWITHROLLUP;![]()
NULL表示所有人的登录次数;可以使用coalesce来设置一个可以取代NUll的名称,coalesce语法:SELECTcoalesce(name,'总数'),SUM(singin)assingin_countFROMemployee_tblGROUPBYnameWITHROLLUP;
- 语法
- ALTER 命令
修改数据表名或者修改数据表字段
- 删除,添加或修改表字段
- 语法
altertablestudentdropregister_date; #从student表删除register_date字段altertablestudentaddphoneint(11)notnull; #添加phone字段
- 语法
- 修改字段类型及名称
如果需要修改字段类型及名称, 你可以在ALTER命令中使用 MODIFY 或 CHANGE 子句
- 语法
- 把字段 c 的类型从 CHAR(1) 改为 CHAR(10)
ALTERTABLEtestalter_tblMODIFYcCHAR(10) - 使用 CHANGE 子句, 语法有很大的不同。 在 CHANGE 关键字之后,紧跟着的是你要修改的字段名,然后指定新字段名及类型
ALTERTABLEtestalter_tbl CHANGE i jBIGINT;ALTERTABLEtestalter_tbl CHANGE j jINT;
- 把字段 c 的类型从 CHAR(1) 改为 CHAR(10)
- 语法
- ALTER TABLE 对 NULL值和默认值的影响
修改字段时,可以指定是否包含或者是否设置默认值
指定字段 j 为 NOT NULL 且默认值为100ALTERTABLEtestalter_tblMODIFYjBIGINTNOTNULLDEFAULT100; - 修改表名
ALTERTABLEtestalter_tbl RENAMETOalter_tbl;
- 删除,添加或修改表字段
- 关于主键
外键,一个特殊的索引,用于关连2个表,只能是指定内容
- 创建第一张表 class
createtableclass(idintnotnullprimarykey,namechar(16)); - 创建第二张表 student2 并关联
CREATE TABLE "student2" ("id" int(11) NOT NULL,"name" char(16) NOT NULL,"class_id" int(11) NOT NULL,PRIMARY KEY ("id"),
#主要是用来加快查询速度的。Key是索引约束,对表中字段进行约束索引的,都是通过primary foreign unique等创建的
KEY "fk_class_key" ("class_id"),
#本表中的class_id关联表class表中id,关联后的名字为fk_class_key
CONSTRAINT "fk_class_key" FOREIGN KEY ("class_id") REFERENCES "class" ("id") )此时如果class 表中不存在id 1,student表也插入不了,这就叫外键约束insertintostudent2(id,name,class_id)values(1,'alex', 1);
#ERROR 1452 (23000): Cannotaddorupdatea child row: aforeignkeyconstraintfails (`testdb`.`student2`,CONSTRAINT`fk_class_key`FOREIGNKEY(`class_id`)REFERENCES`class` (`id`))如果有student表中跟这个class表有关联的数据,你是不能删除class表中与其关联的纪录的deletefromclasswhereid =1;#ERROR 1451 (23000): Cannotdeleteorupdatea parent row: aforeignkeyconstraintfails (`testdb`.`student2`,CONSTRAINT`fk_class_key`FOREIGNKEY(`class_id`)REFERENCES`class` (`id`))
- 创建第一张表 class
- NULL值的处理
MySQL使用 SQL SELECT 命令及 WHERE 子句来读取数据表中的数据,但是当提供的查询条件字段为 NULL 时,该命令可能就无法正常工作
- IS NULL: 当列的值是NULL,此运算符返回true
- IS NOT NULL: 当列的值不为NULL, 运算符返回true
- 连接
- INNER JOIN 内连接(等值连接):获取两个表中字段匹配关系的记录【其实就是只显示2个表的交集】
#将A表中的a列和B表中的b列内连接select*fromAINNERJOINBonA.a = B.b; (等于selectA.*,B.*fromA,BwhereA.a = B.b;) - LEFT JOIN 左连接:获取左表所有记录,即使右表没有对应匹配的记录【其实就是求差集】
#A表中存在但是B表中不存在的值则显示NULL,即非差集的值显示为NULLselect*fromaRIGHTJOINbonA.a = B.b; - RIGHT JOIN 右连接:与 LEFT JOIN 相反,用于获取右表所有记录,即使左表没有对应匹配的记录
- FULL JOIN【求并集】
mysql 并不直接支持full join,但是可以使用以下方法实现
select*fromAleftjoinBonA.a = B.bUNIONselect*fromArightjoinBonA.a = B.b;
#使用UNION语法联合两条命令
- INNER JOIN 内连接(等值连接):获取两个表中字段匹配关系的记录【其实就是只显示2个表的交集】
- 创建数据表
- 事务
用于处理操作量大,复杂度高的数据
- 特点
- 在MySQL中只有使用了Innodb数据库引擎的数据库或表才支持事务
- 事务处理可以用来维护数据库的完整性,保证成批的SQL语句要么全部执行,要么全部不执行
- 事务用来管理insert,update,delete语句
- 四个条件
- 事务的原子性:一组事务,要么成功;要么撤回
- 稳定性 : 有非法数据(外键约束之类),事务撤回
- 隔离性:事务独立运行。一个事务处理后的结果,影响了其他事务,那么其他事务会撤回。事务的100%隔离,需要牺牲速度
- 可靠性:软、硬件崩溃后,InnoDB数据表驱动会利用日志文件重构修改。可靠性和高速度不可兼得, innodb_flush_log_at_trx_commit选项 决定什么时候吧事务保存到日志里。
- 实例
1 mysql> begin; #开始一个事务 2 mysql> insert into a (a) values(555); 3 mysql> rollback; 回滚 , 这样数据是不会写入的,如果想提交直接使用commit进行提交
- 特点
- 索引
索引的建立对于MySQL的高效运行是很重要的,索引可以大大提高MySQL的检索速度
- 普通索引
- 查看索引
show index from student; - 创建方式
- 普通创建
最基本的索引,它没有任何限制。它有以下几种创建方式:CREATEINDEXindex_NameONmytable(username(length));
如果是CHAR,VARCHAR类型,length可以小于字段实际长度;如果是BLOB和TEXT类型,必须指定 length - 修改表结构
ALTERmytableADDINDEX[indexName]ON(username(length)) - 创建表的时候直接指定
CREATETABLEmytable(IDINTNOTNULL,usernameVARCHAR(16)NOTNULL,INDEX[indexName] (username(length)));
- 普通创建
- 删除索引
DROPINDEX[indexName]ONmytable;
- 查看索引
- 唯一索引
索引列的值必须唯一,但允许有空值。如果是组合索引,则列值的组合必须唯一- 创建索引
- 创建索引
CREATEUNIQUEINDEXindexNameONmytable(username(length)) - 修改表结构
ALTERmytableADDUNIQUE[indexName]ON(username(length)) - 创建表的时候直接指定
CREATE TABLE mytable(ID INT NOT NULL,username VARCHAR(16) NOT NULL,UNIQUE [indexName] (username(length)));
- 创建索引
- 使用ALTER添加和删除索引
有四种方式来添加数据表的索引-
ALTERTABLEtbl_nameADDPRIMARYKEY(column_list): 该语句添加一个主键,这意味着索引值必须是唯一的,且不能为NULL。 -
ALTERTABLEtbl_nameADDUNIQUEindex_name (column_list): 这条语句创建索引的值必须是唯一的(除了NULL外,NULL可能会出现多次)。 -
ALTERTABLEtbl_nameADDINDEXindex_name (column_list): 添加普通索引,索引值可出现多次。 -
ALTERTABLEtbl_nameADDFULLTEXT index_name (column_list):该语句指定了索引为 FULLTEXT ,用于全文索引。
-
-
实例
ALTERTABLEtestalter_tblADDINDEX(c);在ALTER命令中使用DROP子句来删除索引ALTERTABLEtestalter_tblDROPINDEX(c);
使用ALTER添加和删除主键
主键只能作用于一个列上,添加主键索引时,你需要确保该主键默认不为空(NOTNULL)ALTERTABLEtestalter_tblMODIFYiINTNOTNULL;ALTERTABLEtestalter_tblADDPRIMARYKEY(i);使用ALTER命令删除主键(删除指定时只需指定PRIMARYKEY,但在删除索引时,你必须知道索引名)ALTERTABLEtestalter_tblDROPPRIMARYKEY;- 显示索引信息
SHOWINDEXFROMtable_name\G
- 创建索引
- 普通索引
- 特点:
- pymysql
- 使用操作
- 执行sql
1 import pymysql 2 3 # 创建连接 4 conn = pymysql.connect(host='127.0.0.1', port=3306, user='root', passwd='123', db='t1') 5 6 # 创建游标(就是鼠标的位置或者就是begin;) 7 cursor = conn.cursor() 8 9 # 执行SQL,并返回受影响行数,插入数据 10 effect_row = cursor.executemany("insert into hosts(host,color_id)values(%s,%s)", [("1.1.1.11",1),("1.1.1.11",2)]) 11 16 # 提交,不然无法保存新建或者修改的数据 17 conn.commit() 18 19 # 关闭游标 20 cursor.close() 21 22 # 关闭连接 23 conn.close()
- 获取查询数据
1 import pymysql 2 3 conn = pymysql.connect(host='127.0.0.1', port=3306, user='root', passwd='123', db='t1') 4 cursor = conn.cursor() 5 cursor.execute("select * from hosts") 6 7 # 获取第一行数据 8 row_1 = cursor.fetchone() 9 10 # 获取前n行数据 11 row_2 = cursor.fetchmany(3) 12 13 # 获取所有数据 14 row_3 = cursor.fetchall() 15 16 conn.commit() 17 cursor.close() 18 conn.close() 19 20 #注:在fetch数据时按照顺序进行,可以使用cursor.scroll(num,mode)来移动游标位置,如: 21 # 1、cursor.scroll(1,mode='relative') # 相对当前位置移动 22 # 2、cursor.scroll(2,mode='absolute') # 相对绝对位置移动
- fetch数据类型
关于默认获取的数据是元组类型,如果想要或者字典类型的数据
1 import pymysql 2 3 conn = pymysql.connect(host='127.0.0.1', port=3306, user='root', passwd='123', db='t1') 4 5 # 游标设置为字典类型 6 cursor = conn.cursor(cursor=pymysql.cursors.DictCursor) 7 r = cursor.execute("call p1()") 8 9 result = cursor.fetchone() 10 11 conn.commit() 12 cursor.close() 13 conn.close()
- 执行sql
- SQLAlchemy
SQLAlchemy是Python编程语言下的一款ORM框架,该框架建立在数据库API之上,使用关系对象映射进行数据库操作,简言之便是:将对象转换成SQL,然后使用数据API执行SQL并获取执行结果
- 优点
- 隐藏了数据访问细节,“封闭”的通用数据库交互,ORM的核心。他使得我们的通用数据库交互变得简单易行,并且完全不用考虑该死的SQL语句
- ORM使我们构造固化数据结构变得简单易行
- 缺点
- 无可避免的,自动化意味着映射和关联管理,代价是牺牲性能(早期,这是所有不喜欢ORM人的共同点)。现在的各种ORM框架都在尝试使用各种方法来减轻这块(LazyLoad,Cache),效果还是很显著的
- 基本使用
1 import sqlalchemy 2 from sqlalchemy import create_engine 3 from sqlalchemy.ext.declarative import declarative_base 4 from sqlalchemy import Column, Integer, String 5 from sqlalchemy.orm import sessionmaker 6 7 #连接数据库 8 engine = create_engine("mysql+pymysql://root:alex3714@192.168.16.86/oldboydb",encoding='utf-8', echo=True) 9 10 #生成orm基类 11 Base = declarative_base() 12 13 class User(Base): 14 __tablename__ = 'user' #表名 15 id = Column(Integer, primary_key=True) #创建列 16 name = Column(String(32)) 17 password = Column(String(64)) 18 19 #读取全部数据库的数据的时候能够格式化输出,对下面的print(my_user)有效 20 def __repr__(self): 21 return "< %s name:%s >" %(self.id,self.name) 22 # class Student(Base): 23 # __tablename__ = 'student' #表名 24 # id = Column(Integer, primary_key=True) #创建列 25 # name = Column(String(32),nullable=False) 26 # register_date=Column(DATE,,nullable=False) 27 # password = Column(String(32),nullable=False) 28 29 30 #创建表结构 31 Base.metadata.create_all(engine) 32 33 #创建与数据库的会话session class ,注意,这里返回给session的是个class,不是实例 34 Session_class = sessionmaker(bind=engine) 35 36 #生成session实例 37 Session = Session_class() 38 39 #生成你要创建的数据对象 40 user_obj = User(name="alex",password="alex3714") 41 42 #此时还没创建对象呢,不信你打印一下id发现还是None 43 print(user_obj.name,user_obj.id) 44 45 #把要创建的数据对象添加到这个session里, 一会再统一创建 46 Session.add(user_obj) 47 48 #此时也依然还没创建 49 print(user_obj.name,user_obj.id) 50 51 #现此才统一提交,创建数据 52 Session.commit() 53 54 #获取所有数据 55 print(Session.query(User.name,User.id).all() ) 56 57 #查询 58 my_user = Session.query(User).filter_by(name="alex").all() 59 print(my_user[0].name,data[0].password) 60 print(my_user) 61 my_user = Session.query(User).filter(User.id>1).all() #判断相等则使用双等号== 62 print(my_user) 63 objs = Session.query(User).filter(User.id>0).filter(User.id<7).all() #多条件查询,2个filter的关系相当于 user.id >1 AND user.id <7 的效果 64 print(Session.query(User,Student).filter(User.id==Student.id).all()) #多表查询 65 #相等 :query.filter(User.name == 'ed') 66 #不相等 :query.filter(User.name != 'ed') 67 #LIKE :query.filter(User.name.like('%ed%')) 68 #in :query.filter(User.name.in_(['ed', 'wendy', 'jack'])) 69 #not in :query.filter(~User.name.in_(['ed', 'wendy', 'jack'])) 70 71 #修改 72 my_user = Session.query(User).filter_by(name="alex").first() 73 my_user.name = "Alex Li" 74 Session.commit() 75 76 #回滚 77 my_user = Session.query(User).filter_by(id=1).first() 78 my_user.name = "Jack" 79 fake_user = User(name='Rain', password='12345') 80 Session.add(fake_user) 81 print(Session.query(User).filter(User.name.in_(['Jack','rain'])).all() ) #这时看session里有你刚添加和修改的数据 82 Session.rollback() #此时你rollback一下 83 print(Session.query(User).filter(User.name.in_(['Jack','rain'])).all() ) #再查就发现刚才添加的数据没有了 84 # Session.commit() 85 86 #统计和分组 87 Session.query(User).filter(User.name.like("Ra%")).count() #统计 88 from sqlalchemy import func 89 print(Session.query(func.count(User.name),User.name).group_by(User.name).all() )#分组,相当于SELECT count(user.name) AS count_1, user.name AS user_name FROM user GROUP BY user.name 90 91 #外键关联 92 from sqlalchemy import ForeignKey 93 from sqlalchemy.orm import relationship 94 class Address(Base): #我们创建一个addresses表,跟user表关联 95 __tablename__ = 'addresses' 96 id = Column(Integer, primary_key=True) 97 email_address = Column(String(32), nullable=False) 98 user_id = Column(Integer, ForeignKey('user.id')) 99 user = relationship("User", backref="addresses") #这个允许你在user表里通过backref字段反向查出所有它在addresses表里的关联项 100 def __repr__(self): 101 return "<Address(email_address='%s')>" % self.email_address 102 obj = Session.query(User).first() 103 for i in obj.addresses: #通过user对象反查关联的addresses记录 104 print(i) 105 addr_obj = Session.query(Address).first() 106 print(addr_obj.user.name) #在addr_obj里直接查关联的user表 107 108 #创建关联对象 109 obj = Session.query(User).filter(User.name=='rain').all()[0] 110 print(obj.addresses) 111 obj.addresses = [Address(email_address="r1@126.com"), #添加关联对象 112 Address(email_address="r2@126.com")] 113 Session.commit()
- 多外键关联
1 #>>>>>>>>>>>orm_many_fk.py 2 from sqlalchemy import Integer, ForeignKey, String, Column 3 from sqlalchemy.ext.declarative import declarative_base 4 from sqlalchemy.orm import relationship 5 from sqlalchemy import creat_engine 6 7 Base = declarative_base() 8 9 class Customer(Base): 10 __tablename__ = 'customer' 11 id = Column(Integer, primary_key=True) 12 name = Column(String(64)) 13 14 billing_address_id = Column(Integer, ForeignKey("address.id")) #外键一 15 shipping_address_id = Column(Integer, ForeignKey("address.id")) #外键二 16 17 billing_address = relationship("Address", foreign_keys=[billing_address_id]) 18 shipping_address = relationship("Address", foreign_keys=[shipping_address_id]) 19 20 class Address(Base): 21 __tablename__ = 'address' 22 id = Column(Integer, primary_key=True) 23 street = Column(String(64)) 24 city = Column(String(64)) 25 state = Column(String(64)) 26 27 engine = create_engine("mysql+pymysql://root:alex3714@localhost/testdb",encoding='utf-8', echo=True) 28 #Base.metadata.create_all(engine) #创建表结构
1 #>>>>>>>>>>>orm_api.py 2 import orm_many_fk 3 from sqlalchemy.orm import sessionmaker 4 5 #>>>>>创建数据 6 Session_class=sessionmaker(bind=orm_many_fk.engine)#创建与数据库的会话session class ,注意,这里返回给session的是个class,不是实例 7 Session = Session_class() #生成session实例 8 9 addr1=orm_many_fk.Address(street="tiantongyuan",city="changping",state="beijing") 10 addr2=orm_many_fk.Address(street="wudaokou",city="haidian",state="beijing") 11 addr3=orm_many_fk.Address(street="yanjiao",city="langfang",state="hebei") 12 session.add_all([addr1,addr2,addr3]) 13 14 c1=orm_many_fk.Customer(name="alex",billing_address=addr1,shipping_address=addr2) 15 c2=orm_many_fk.Customer(name="jack",billing_address=addr3,shipping_address=addr3) 16 session.add_all([c1,c2]) 17 18 session.commit() 19 20 #>>>>>查询数据 21 obj=session.query(orm_many_fk.Customer).filter(orm_many_fk.Customer.name=="alex").first() 22 print(obj.name,obj.billing_address,obj.shipping_address)
- 多对多关系
一本书多个作者,一个作者多本书
1 #orm_m2m.py 2 from sqlalchemy import Table, Column, Integer,String,DATE, ForeignKey 3 from sqlalchemy.orm import relationship 4 from sqlalchemy.ext.declarative import declarative_base 5 from sqlalchemy import create_engine 6 from sqlalchemy.orm import sessionmaker 7 8 #>>>>>>>>>>创建 9 Base = declarative_base() 10 11 book_m2m_author = Table('book_m2m_author', Base.metadata, 12 Column('book_id',Integer,ForeignKey('books.id')), 13 Column('author_id',Integer,ForeignKey('authors.id'))) 14 15 class Book(Base): 16 __tablename__ = 'books' 17 id = Column(Integer,primary_key=True) 18 name = Column(String(64)) 19 pub_date = Column(DATE) 20 authors = relationship('Author',secondary=book_m2m_author,backref='books') 21 22 def __repr__(self): 23 return self.name 24 25 class Author(Base): 26 __tablename__ = 'authors' 27 id = Column(Integer, primary_key=True) 28 name = Column(String(32)) 29 30 def __repr__(self): 31 return self.name 32 33 engine = create_engine("mysql+pymysql://root:alex3714@localhost/testdb?charset=utf8",encoding='utf-8')#?charset=utf8能够使连接支持中文 34 Base.metadata.create_all(engine) #创建表结构
1 #orm_fk.py 2 import orm_m2m 3 from sqlalchemy.orm import sessionmaker 4 5 #>>>>>>>创建 6 Session_class=sessionmaker(bind=orm_many_fk.engine)#创建与数据库的会话session class ,注意,这里返回给session的是个class,不是实例 7 Session = Session_class() #生成session实例 8 9 b1=orm_m2m.Book(name="learn python with alen",pub_date="2019-07-14") 10 b2=orm_m2m.Book(name="learn zhuangbility with alen",pub_date="2019-07-14") 11 b3=orm_m2m.Book(name="learn hook up girls with alex",pub_date="2019-07-14") 12 13 a1=orm_m2m.Author(name="alex") 14 a2=orm_m2m.Author(name="jack") 15 a3=orm_m2m.Author(name="rain") 16 17 b1.authors=[a1,a3] 18 b3.authors=[a1,a2,a3] 19 20 session.add_all([b1,b2,b3,a1,a2,a3]) 21 session.commit() 22 23 #>>>>>>查询 24 author_obj=session.query(orm_m2m.Author).filter(orm_m2m.Author.name=="alex").first() 25 print(author_obj.books[1].pub_date) 26 book_obj=session.query(orm_m2m.Book).filter(orm_m2m.Book.id==2).first() 27 print(book_obj.authors) 28 29 #>>>>>>>删除 30 #通过书删除作者 31 #author_obj =session.query(Author).filter_by(name="jack").first() 32 #book_obj =session.query(Book).filter_by(name="learn hook up girls with alex").first() 33 book_obj.authors.remove(author_obj)#删除id=2的这本书 34 session.commit() 35 #直接删除作者 36 author_obj =session.query(Author).filter_by(name="alex").first() 37 s.delete(author_obj) 38 s.commit() 39 40 #处理中文 41 #sqlalchemy设置编码字符集一定要在数据库访问的URL上增加charset=utf8,否则数据库的连接就不是utf8的编码格式 42 b4=orm_m2m.Book(name="跟alex去泰国",pub_date="2019-07-14") 43 session.add_all([b4,])
- 优点
- 使用操作
- 特点

 浙公网安备 33010602011771号
浙公网安备 33010602011771号