Spark中的reduceByKey()和groupByKey()的区别
一、先看结论
1.从Shuffle的角度
reduceByKey 和 groupByKey都存在shuffle操作,但是reduceByKey可以在shuffle之前对分区内相同key的数据集进行预聚合(combine)功能,这样会较少落盘的数据量,而groupByKey只是进行分组,不存在数据量减少的问题,reduceByKey性能比较高
2.从功能的角度
reduceByKey其实包含分组和聚合的功能;groupByKey只能分组,不能聚合,所以在分组聚合的场合下,推荐使用reduceByKey,如果仅仅是分组而不需要聚合,那么还是只能使用groupByKey。
用WordCount程序来举例。
val words = Array("one", "two", "two", "three", "three", "three")
val wordPairsRDD = sc.parallelize(words).map(word => (word, 1))
val wordCountsWithReduce = wordPairsRDD
.reduceByKey(_ + _)
.collect()
val wordCountsWithGroup = wordPairsRDD
.groupByKey()
.map(t => (t._1, t._2.sum))
.collect()
这两种做法的结果都是正确的。
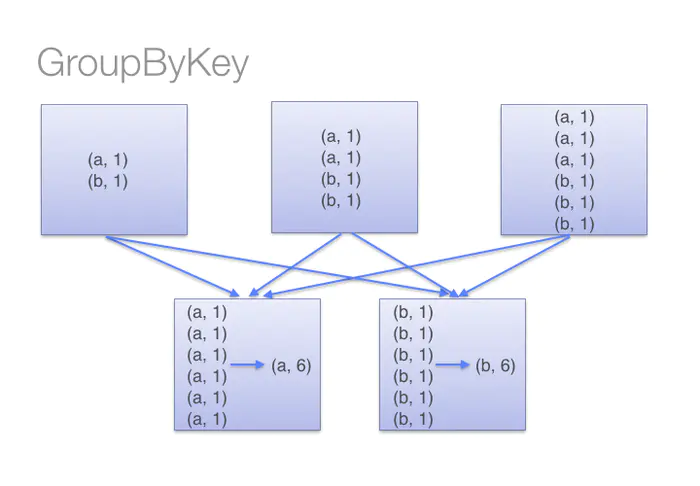
在大的数据集上,reduceByKey()的效果比groupByKey()的效果更好一些。因为reduceByKey()会在shuffle之前对数据进行合并。
如图所示:

而当我们调用groupByKey()的时候,所有的键值对都会被shuffle到下一个stage,传输的数据比较多,自然效率低一些。
故乡明

 浙公网安备 33010602011771号
浙公网安备 33010602011771号