
201971010142-王玉慧 实验三 结对项目—《{0-1}KP 实例数据集算法实验平台》项目报告
| 项目 | 内容 |
|---|---|
| 课程班级博客链接 | 班级博客 |
| 这个作业要求链接 | 作业要求 |
| 我的课程学习目标 | 1.体验软件项目开发中的两人合作,练习结对编程 2. 掌握Github协作开发程序的操作方法。 3.阅读《现代软件工程—构建之法》学习代码规范等知识 4. 学习遗传算法并进行问题求解。 |
| 这个作业在哪些方面帮助我实现学习目标 | 1.熟悉了软件工程结对编程 2.掌握Github克隆结对方项目 3.学习了代码风格规范、代码设计规范、代码复审等知识 |
| 结对方学号-姓名 | 201971010138-汤可意 |
| 结对方本次博客作业链接 | https://www.cnblogs.com/keyi21/p/16093881.html |
| 结对方的仓库链接地址 | https://github.com/keyi21 |
| 本项目Github的仓库链接地址 | https://github.com/keyi21/D-0-1-bag |
1、实验目的与要求
(1)体验软件项目开发中的两人合作,练习结对编程(Pair programming)。
(2)掌握Github协作开发程序的操作方法。
2、实验内容和步骤
任务1:阅读《现代软件工程—构建之法》第3-4章内容,理解并掌握代码风格规范、代码设计规范、代码复审、结对编程概念;
1.代码风格规范:
代码风格规范包括命名规范,代码展示风格的规范(缩进、空格、换行),控制语句的规范以及代码注释的规范,好的代码风格规范可以让其他人更好的理解。它的原则是:简明,易读,无二义性。
- 四个空格的缩进
- 每个{}独占一行
- 不要把多个变量定义在一行上
- 一个类型的成员变量用同一类型命名
- 所有的类型/类/函数名
- 注释是为了解释程序做什么(What),为什么这么做(Why),以及要特别注意的地方,只用ASCII字符,不要用中文
2.代码设计规范:
- 函数:只做一件事,并且要做好
- 单一出口
- 不要在构造函数中做复杂的操作,简单初始化所有的数据成员即可
3.代码复审:
- 看代码是否在代码规范的框架内正确地解决了问题、长远的问题;
- 修改之后,有没有别的功能会受影响;
- 项目中还有别的地方需要类似的修改吗;
- 有没有留下足够的说明,让将来维护代码时不会出现问题;
- 对于修改,是否需要告知成员;
- 导致问题的根本原因是什么?以后如何能自动避免这样的情况再次出现;
结对编程
结对编程是一种敏捷软件开发的方法,两个程序员在一个计算机上共同工作。一个人输入代码,而另一个人审查他输入的每一行代码。输入代码的人称作驾驶员,审查代码的人称作观察员。两个程序员经常互换角色。
在结对编程中,观察员同时考虑工作的战略性方向,提出改进的意见,或将来可能出现的问题以便处理。这样使得驾驶者可以集中全部注意力在完成当前任务的“战术”方面。观察员当作安全网和指南。结对编程对开发程序有很多好处。比如增加纪律性,写出更好的代码等。
结对编程是极端编程的组成部分。
任务2:两两自由结对,对结对方《实验二 软件工程个人项目》的项目成果进行评价,具体要求如下:
(1)对项目博文作业进行阅读并进行评论,评论要点包括:博文结构、博文内容、博文结构与PSP中“任务内容”列的关系、PSP中“计划共完成需要的时间”与“实际完成需要的时间”两列数据的差异化分析与原因探究,将以上评论内容发布到博客评论区。
结对方博客链接:汤可意的博客
结对方Github项目仓库链接:汤可意Github项目仓库链接
博客评论:

(2)克隆结对方项目源码到本地机器,阅读并测试运行代码,参照《现代软件工程—构建之法》4.4.3节核查表复审同伴项目代码并记录。
克隆结对方代码到本地机器:
代码核查表
| 内容 | 完成效果 |
|---|---|
| ----------概要部分---------- | |
| 代码是否符合需求和规范说明 | 符合 |
| 代码设计是否考虑周全 | 周全 |
| 代码可读性如何 | 清晰易读 |
| 代码容易维护吗 | 容易 |
| 代码的每一行都执行并检查过了吗 | 否 |
| ----------设计规范部分---------- | |
| 设计是否遵循从已知的设计模式或项目中常用的设计模式 | 是 |
| 有没有硬编码或字符串/数字等存在 | 有 |
| 代码是否依赖于某一平台,是否会影响将来的移植 | 代码由C#编写,可能会影响移植 |
| 开发者新写的代码是否用已有的Library/SDK/Framework中的功能实现?在本项目中是否存在类似的功能可以通过调用而不用全部重新实现? | 是,用已有的Library/SDK/Framework中的功能实现 |
| 有没有无用的代码可以清除 | 有 |
| ----------代码规范部分---------- | |
| 修改的部分符合代码标准和风格么 | 符合 |
| ----------具体代码部分---------- | |
| 是否可正确读入实验数据文件的有效D{0-1}KP数据 | 代码实现了从本地读取数据,符合需求且比较容易维护 |
| 是否能够绘制任意一组D{0-1}KP数据以重量为横轴、价值为纵轴的数据散点图 | 可根据读入的不同数据准确绘制以重量为横轴、价值为纵轴的数据散点图,符合实验要求。 |
| 是否对一组D{0-1}KP数据按项集第三项的价值:重量比进行非递增排序; | 对不同的数据可以进行选择并对其进行能够对一组D{0-1}KP数据按项集第三项的价值:重量比进行非递增排序;但相关部分代码可读性较差,存在较多问题。 |
| 是否自主选择动态规划算法、回溯算法求解指定D{0-1} KP数据的最优解和求解时间 | 代码中选择动态规划算法任意选择一组数据并求解了这组数据的最优解和求解时间,求解时间也是按照以秒为单位,符合实验要求 |
| 是否将任意一组D{0-1} KP数据的最优解、求解时间和解向量可保存为txt文件或导出EXCEL文件。 | 完成了任意一组D{0-1} KP数据的最优解、求解时间和解向量可保存为txt文件或导出EXCEL文件保存在本地。 |
| 有没有对错误进行处理?对于调用的外部函数,是否检查了返回值或处理了异常? | 已处理 |
| 参数传递有无错误,字符串的长度是字节的长度还是字符的长度,是从0开始计数还是从1开始计数 | 无错误,字符的长度,从0开始计数 |
| 边界条件是如何处理的?switch语句和default分支是如何处理的?循环有没有可能出现死循环? | 通过前提分析推导边界条件 |
| 有没有使用断言(Assert)来保证我们认为不变的条件真的得到满足? | 否 |
| 对资源的利用,是在哪里申请,在哪里释放的?有无可能存在资源泄露?有没有优化的空间? | 自动申请释放,不会存在资源泄露,有优化的空间 |
| 数据结构中有没有用不到的元素? | 有 |
| ----------效能---------- | |
| 代码的效能(Performance)如何?最坏的情况是怎么样的? | 效能一般,数据量过大可能会需要很长的运行时间而得不到结果 |
| 代码中,特别是循环中是否有明显可优化的部分? | 无 |
| 对于系统和网络的调用是否会超时?如何处理? | 如果超时,重新调用 |
| 代码可读性如何?有没有足够的注释? | 结构清晰,但注释较少 |
| ----------可测试性---------- | |
| 代码是否需要更新或创建新的单元测试 | 否 |
博客作业中针对任务2的评分要点:
- 结对方博客链接(1分);
- 结对方Github项目仓库链接(1分);
- 符合(1)要求的博客评论(18分);
- 符合(2)要求的代码核查表(15分);
- 结对方项目仓库中的Fork、Clone、Push、Pull request、Merge pull request日志数据(5分)
(3)依据复审结果尝试利用github的Fork、Clone、Push、Pull request、Merge pull request等操作对同伴个人项目仓库的源码进行合作修改。
fork:从别人发布的项目上复制一个过来,相当于一个分支,项目复制到自己的个github中,于是本地就有了一个仓库;
clone: 从自己的github上把fork过来的复制到本地,这样本地就有了一个项目;
push:当你在本地项目中进行修改进行开发后,最后同步到你的github上的仓库中;
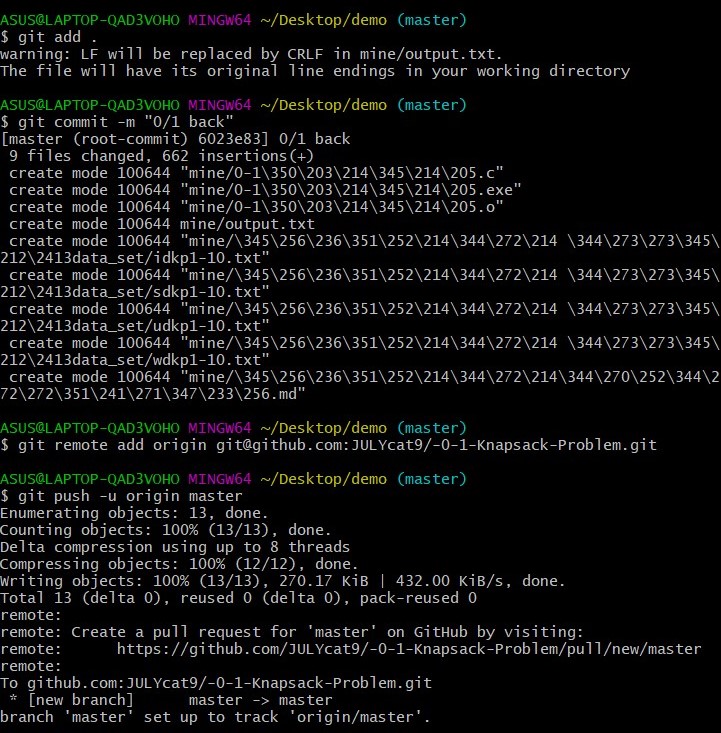
pull request:你把自己github中的已经修改的内容申请同步到最初那个开发者的项目中;
任务3:两两采用两人结对编程方式,设计开发一款D{0-1}KP 实例数据集算法实验平台,使之具有以下功能:
(1)平台基础功能:实验二 任务3;
(2)D{0-1}KP 实例数据集需存储在数据库;
(3)平台可动态嵌入任何一个有效的D{0-1}KP 实例求解算法,并保存算法实验日志数据;
(4)人机交互界面要求为GUI界面(WEB页面、APP页面都可);
(5)查阅资料,设计遗传算法求解D{0-1}KP,并利用此算法测试要求;
(6)附加功能:除(1)-(5)外的任意有效平台功能实现。
结对编程项目实施要求及代码部分评分细则(30分):
- 结对编程开发进度计划的要求:在项目正式之前,预估本次结对项目任务的PSP环节的消耗时间,并在PSP过程中统计实际耗时,填写PSP表格。
- 尝试采用汉堡包法实施项目结对中两个人的沟通,关于汉堡包法的阐述参见:http://www.cnblogs.com/xinz/archive/2011/08/22/2148776.html
- 理解领航员和驾驶员两种角色关系:两人都必须参与编码工作,在结对编程中两个人轮流做对方的角色。
- 将结对编程项目的源码以增量方式提交到指定同学Github账号的项目仓库中,Github结对项目仓库的代码提交日志要体现两人合作过程,项目仓库中要能看到项目多次commit的记录,和两人各自的commit记录。(5分)
- 项目必须包含src文件夹。
- 编撰两人合作开发遵守共同认可的编码规范,提交项目代码规范文档到Github项目仓库根目录下。(5分)
- 程序功能评测。( 20分)
1.需求分析陈述。(5分)
1.能够正确读入实验数据文件的有效D{0-1}KP数据,即从给定的txt文件中正确切割、正确读取数据,并将数据传送到服务器保存到数据库。
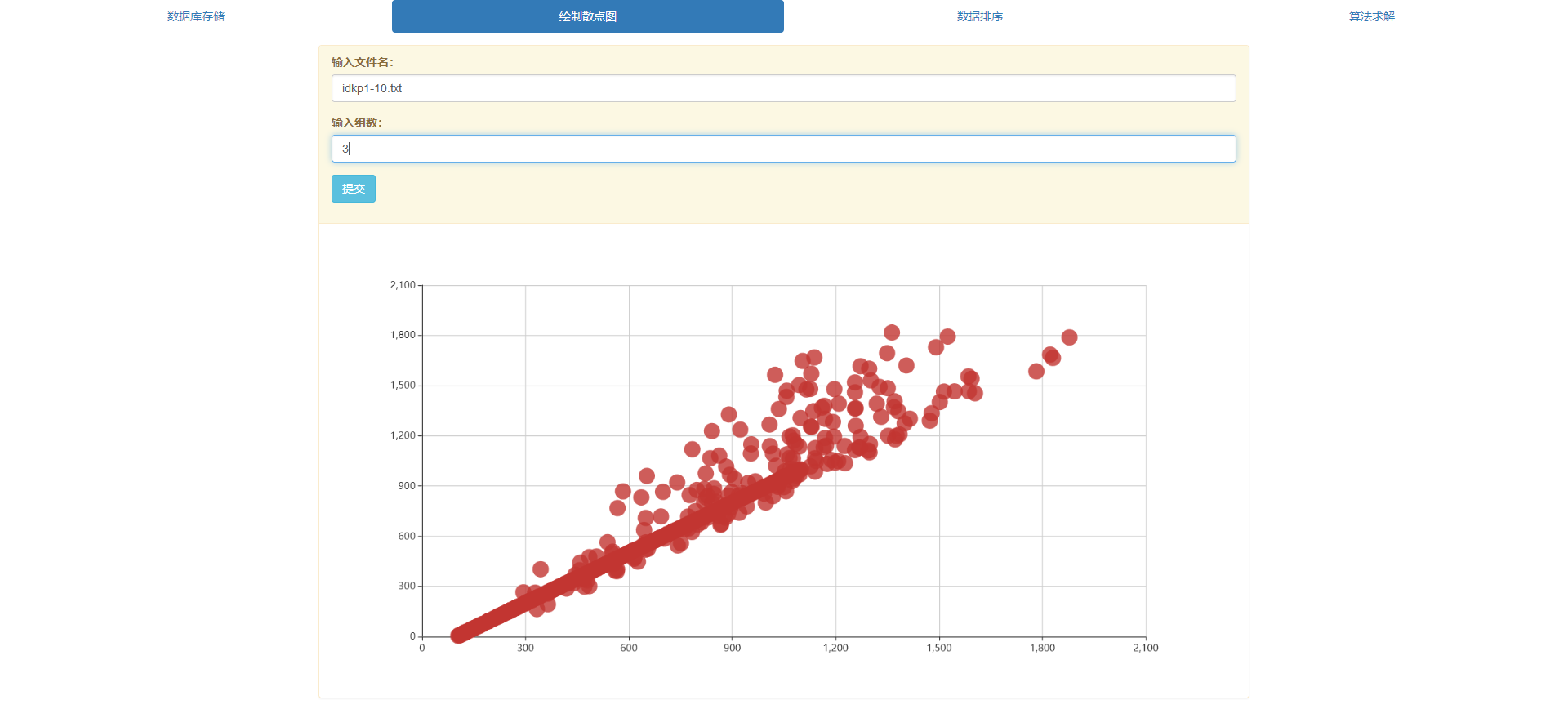
2.能够绘制任意一组D{0-1}KP数据以重量为横轴、价值为纵轴的数据散点图,将这一组数据直观的显示出来,并且需要新坐标系,重量设为x,价值设为y,来绘制新坐标轴。
3.能够对一组D{0-1}KP数据按项集第三项的价值:重量比进行非递增排序。产品的“价值重量比”高就是说重量很轻,价值很高。价值重量比越高,这个产品的销售半径就越大。
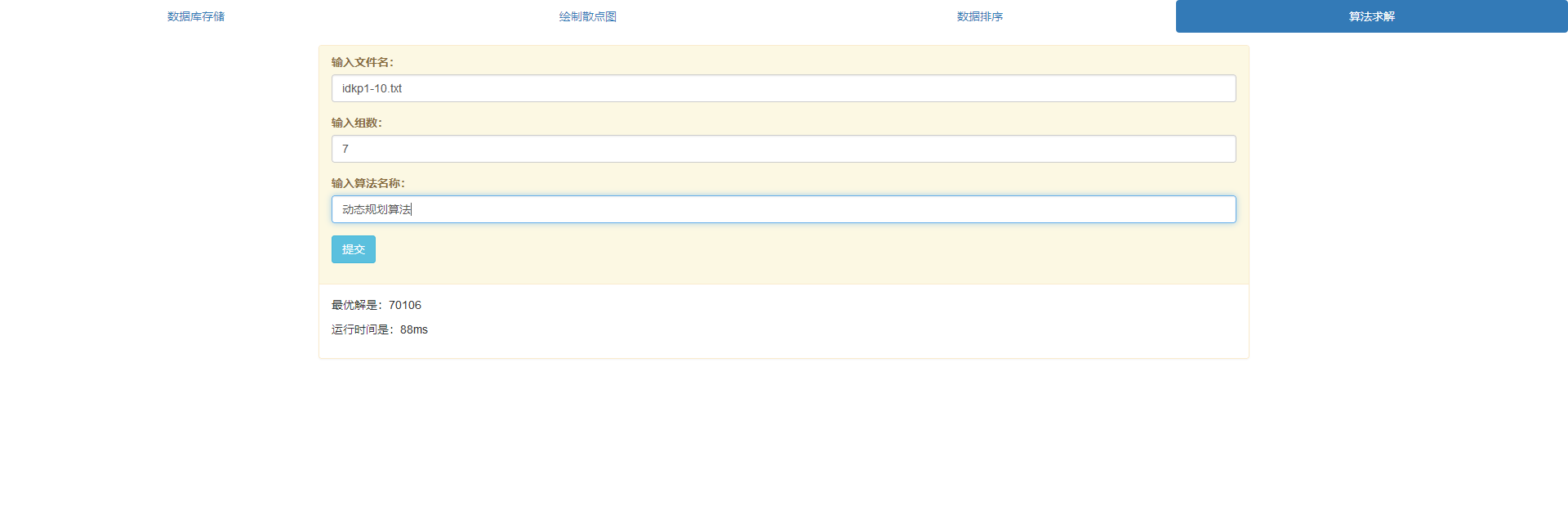
4.使用者能够自主选择动态规划算法、回溯算法求解指定D{0-1} KP数据的最优解和求解时间,即可以对同一组数据选择不同的算法进行计算最优解,求解向量,并可以将结果存储到服务器上的数据库中
5.对于任意一组D{0-1} KP数据的最优解、求解时间和解向量可保存为txt文件或导出EXCEL文件,可以一次求解,永久使用。
6.需要保存日志,服务器端和客户端都需要留有日志。
2.软件设计说明。(5分)
1、D{0-1}KP 实例数据集需存储在数据库;
2、平台可动态嵌入任何一个有效的D{0-1}KP 实例求解算法,并保存算法实验日志数据;
3、人机交互界面要求为GUI界面;
4、查阅资料,设计遗传算法求解D{0-1}KP,并利用此算法测试要求。
3.软件实现及核心功能代码展示:软件包括哪些类,这些类分别负责什么功能,他们之间的关系怎样?类内有哪些重要的方法,关键的方法是否需要画出流程图?(5分)
1. 软件的类:
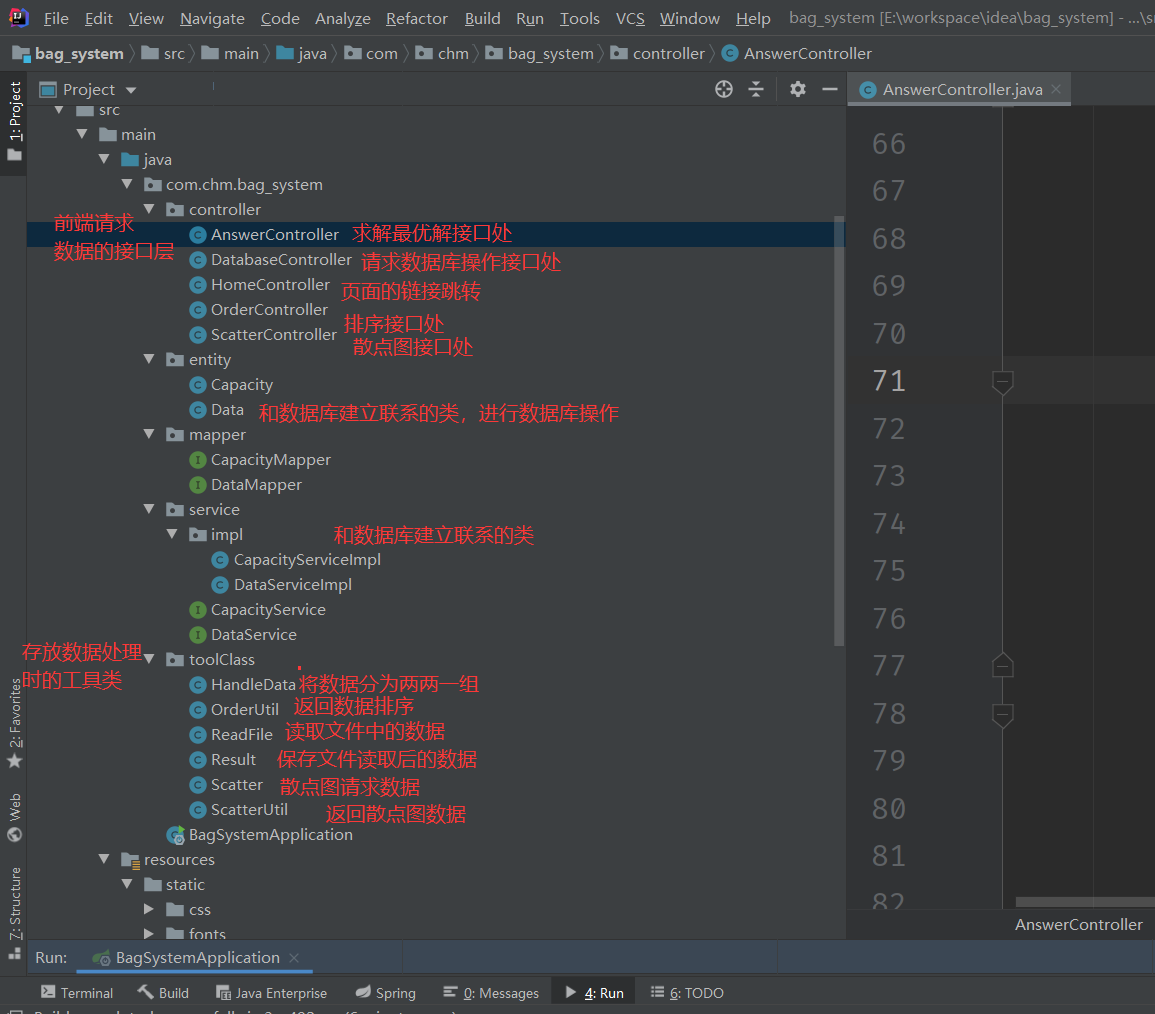
2. 程序运行:
- 向数据库存储数据
- 对选定文件夹里面的具体对象绘制散点图
- 选择将要排序的数组
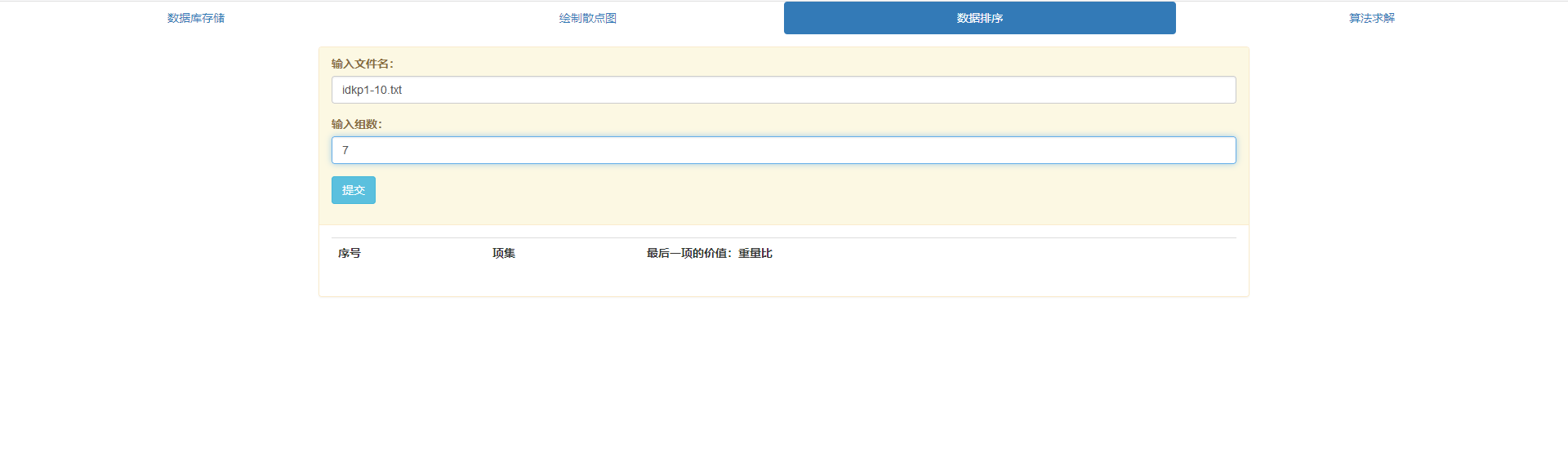
- 对某一组组数据项集按第三项性价比进行排序
- 用回溯算法求最优解
- 用动态规划算法求最优解
- 数据库中每一项数据的价值与重量
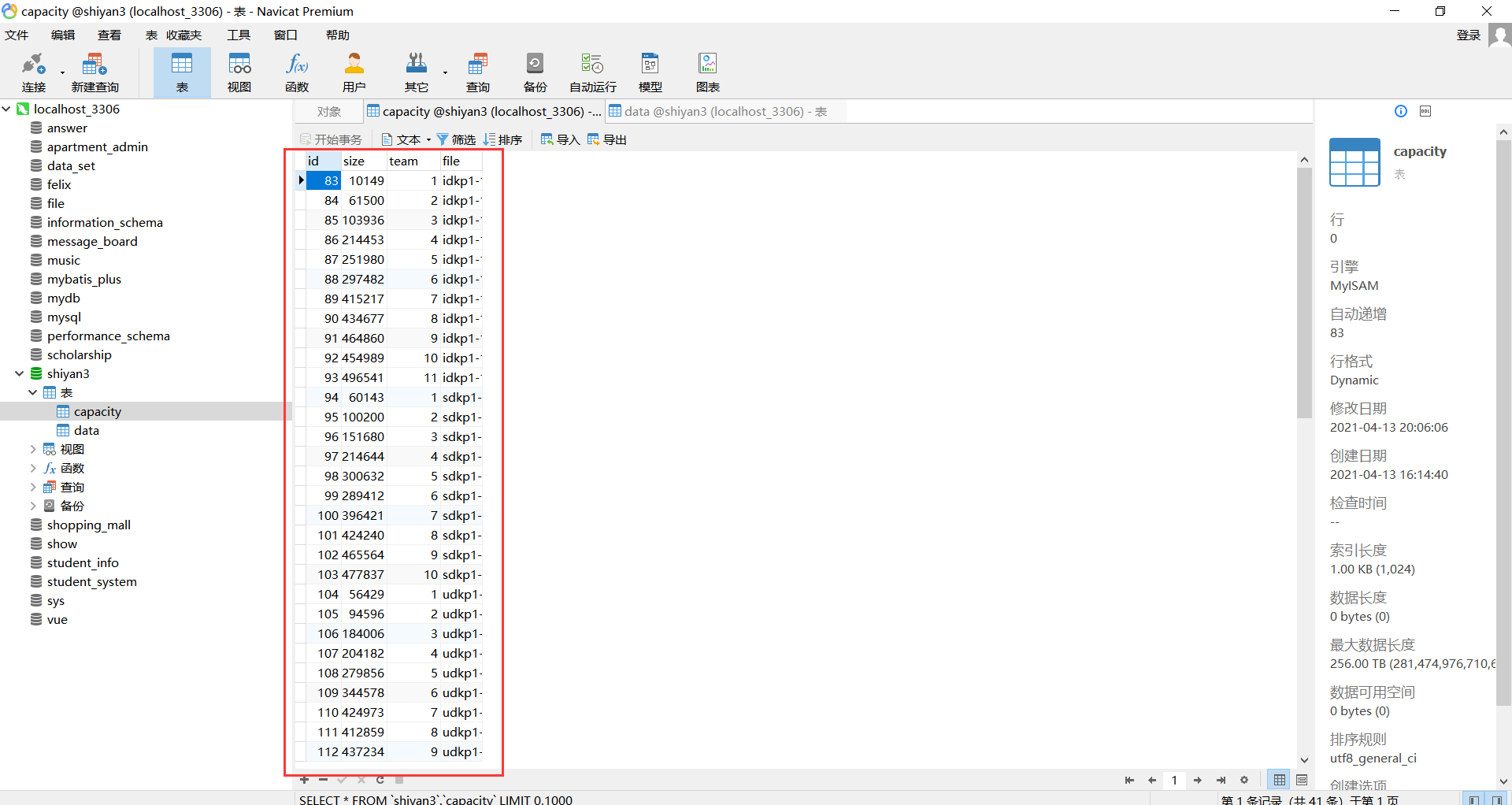
- 数据库中按组数存储的数据
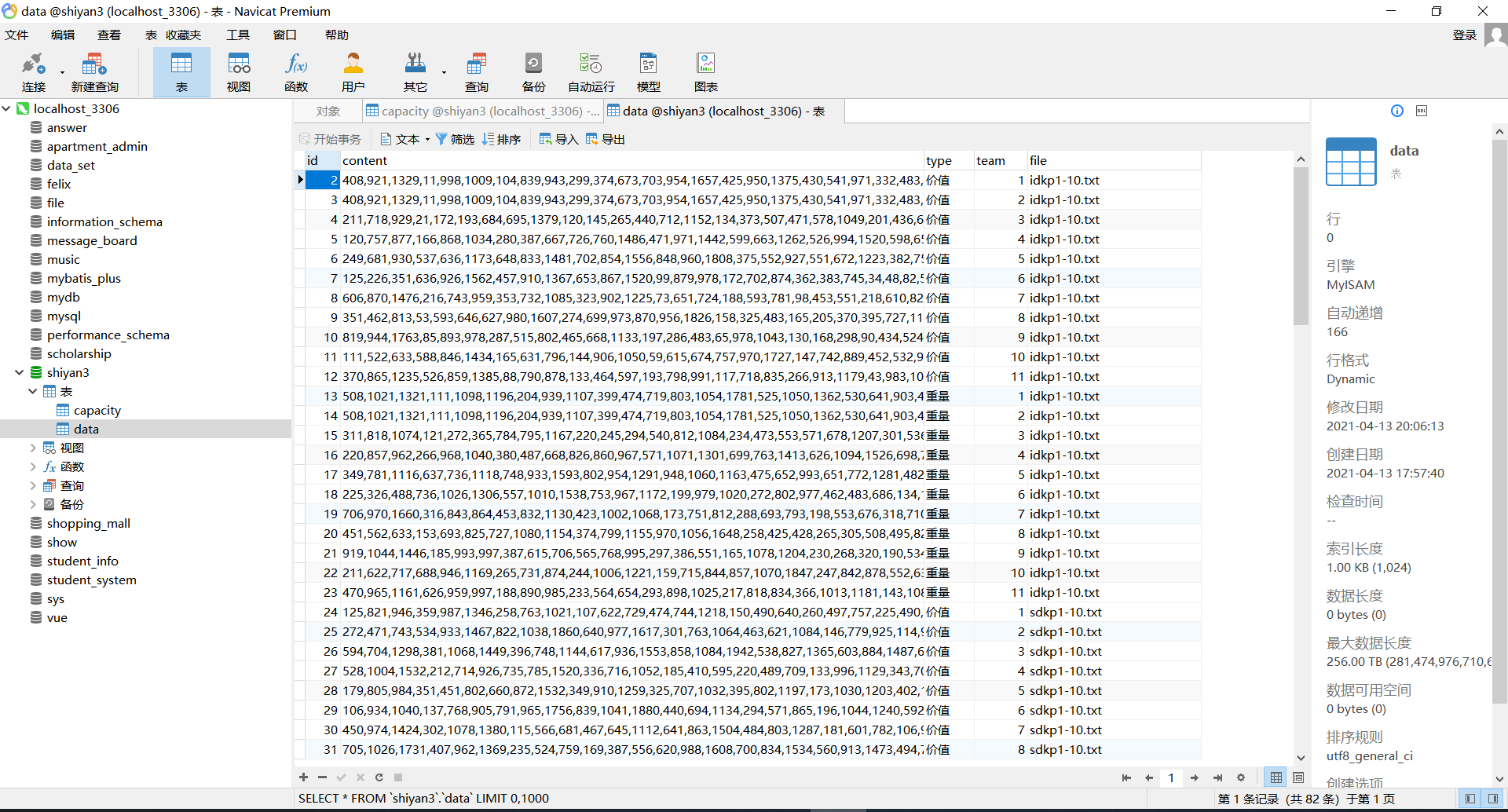
3. 遗传算法概述:
遗传算法(Genetic Algorithm,GA)是进化计算的一部分,是模拟达尔文的遗传选择和自然淘汰的生物进化过程的计算模型,是一种通过模拟自然进化过程搜索最优解的方法。该算法简单、通用,鲁棒性强,适于并行处理。
遗传算法的基本流程
- 通过随机方式产生若干由确定长度(长度与待求解问题的精度有关)编码的初始群体;
- 通过适应度函数对每个个体进行评价,选择适应度值高的个体参与遗传操作,适应度低的个体被淘汰;
- 经遗传操作(复制、交叉、变异)的个体集合形成新一代种群,直到满足停止准则(进化代数GEN>=?);
- 将后代中变现最好的个体作为遗传算法的执行结果。
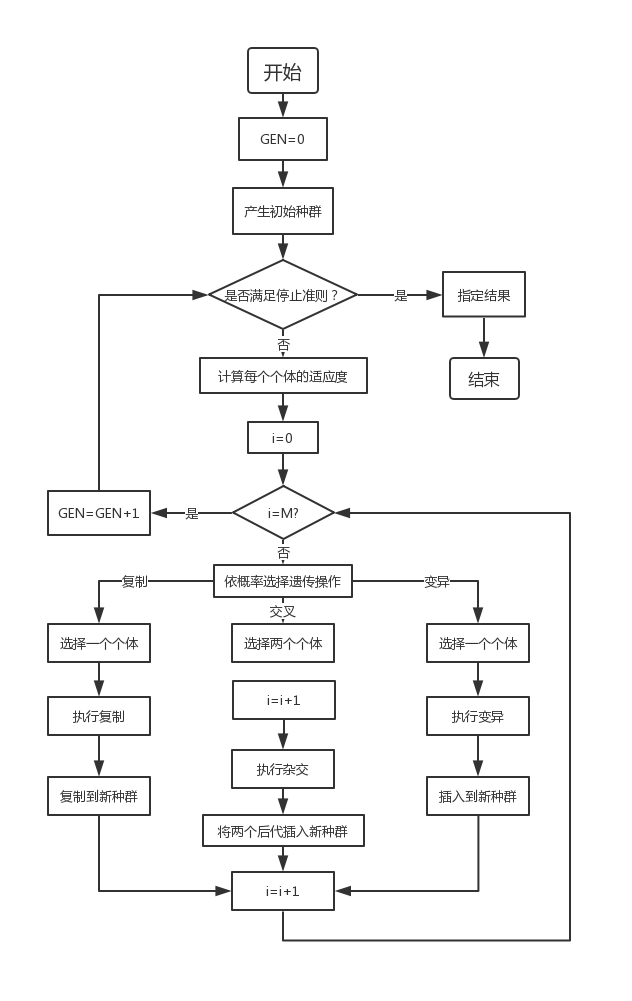
(其中,GEN是当前代数;M是种群规模,i代表种群数量。)
/*
计算种群适应度
*/
public void caculteFitness(){
bestFitness=population.get(0).getFitness();
worstFitness=population.get(0).getFitness();
totalFitness=0;
for (Chromosome g:population) {
//changeGene(g);
setNowGenome(g);
if(g.getFitness()>bestFitness){
setBestFitness(g.getFitness());
if(y<bestFitness){
y=g.getFitness();
}
setIterBestFit(g);
}
if(g.getFitness()<worstFitness){
worstFitness=g.getFitness();
}
totalFitness+=g.getFitness();
}
averageFitness = totalFitness / popSize;
//因为精度问题导致的平均值大于最好值,将平均值设置成最好值
averageFitness = averageFitness > bestFitness ? bestFitness : averageFitness;
}
/*
/*
轮盘赌选择算法
*/
public Chromosome getChromoRoulette(){
double db=random.nextDouble();
double randomFitness=db*totalFitness;
Chromosome choseOne=null;
double sum=0.0;
for(int i=0;i<population.size();i++){
choseOne=population.get(i);
sum+=choseOne.getFitness();
if(sum>=randomFitness){
break;
}
}
return choseOne;
}
4. 结对过程描述:
本次项目PSP
| 任务内容 | 计划共完成需要的时间/分钟 | 实际完成需要的时间/分钟 |
|---|---|---|
| 计划总时长 | 1180 | 2050 |
| --------------------任务一-------------------- | 50 | 55 |
| 阅读《现代软件工程—构建之法》第3-4章 | 50 | 55 |
| --------------------任务二-------------------- | 320 | 400 |
| 对项目博文作业进行阅读并进行评论 | 20 | 20 |
| 克隆结对方项目源码到本地机器,阅读并测试运行代码 | 100 | 120 |
| 依据复审结果用github的Fork、Clone、Push等操作对同伴个人项目仓库的源码进行合作修改 | 200 | 260 |
| --------------------任务3-------------------- | 810 | 1595 |
| D{0-1}KP 实例数据集存储在数据库 | 40 | 60 |
| 将数据库数据读取出来 | 40 | 70 |
| 用读出来的数据绘制散点图并显示在人机交互页面 | 60 | 270 |
| 动态规划算法结果显示在前端 | 60 | 120 |
| 回溯算法结果显示 | 40 | 75 |
| 将数据项显示在前端,按其第三项进行排序并显示 | 80 | 100 |
| 平台可动态嵌入任何一个有效的D{0-1}KP 实例求解算法,并保存算法实验日志数据 | 250 | 400 |
| 人机交互界面要求为GUI界面 | 40 | 50 |
| 查阅资料,设计遗传算法求解D{0-1}KP,并利用此算法测试要求 | 200 | 450 |
结对项目小结:
通过本次软件项目结对编程学习了遗传算法,并通过阅读《现代软件工程—构建之法》第3-4章内容,学习了代码风格规范、代码设计规范、代码复审、结对编程概念;发现结对编程可以提高项目完成的速率,但在结对编程的过程中也遇到了对方函数、变量等命名的不同一等问题。结对编程是一个对双方要求较高的实验方法,但也相对减轻了一部分工作量。在项目完成的过程中也提高了两个人的合作默契度,切实体会到1+1>2的实验效果。掌握了Github的fork、 clone、push、pull request 、merge pull request等的相关操作。对于代码规范有了进一步的了解与提升。

