
集合知识点整理分析
开门见山:
Collection的实现类有set和List,List的实现类有ArrayList、LinkedList、Victory
ArrayList
List<String> list = new ArrayList<String>(); // 往 尾部添加 指定元素 list.add("图图"); list.add("小美"); list.add("不高兴"); System.out.println(list); // add(int index,String s) 往指定位置添加 list.add(1,"没头脑"); System.out.println(list); // String remove(int index) 删除指定位置元素 返回被删除元素 // 删除索引位置为2的元素 System.out.println("删除索引位置为2的元素"); System.out.println(list.remove(2)); System.out.println(list); // String set(int index,String s) // 在指定位置 进行 元素替代(改) // 修改指定位置元素 list.set(0, "三毛"); System.out.println(list); // String get(int index) 获取指定位置元素 // 跟size() 方法一起用 来 遍历的 for(int i = 0;i<list.size();i++){ System.out.println(list.get(i)); } //还可以使用增强for for (String string : list) { System.out.println(string); } System.out.println("--------------------"); Iterator it = list.iterator(); while(it.hasNext()) { System.out.println(it.next()); }
LinkedList集合数据存储的结构是链表结构。方便元素添加、删除的集合,但相对于数组而言,遍历较慢。
因为它的底层是双向链表,所以他有链表的一些性质。又因为他是List的实现类,所以他也有List的性质:有序和可以重复
LinkedList<String> list = new LinkedList<String>(); list.add("懒"); list.add("得"); list.add("跑"); System.out.println(list.getFirst()); System.out.println(list.getLast()); // 删除元素 System.out.println(list.removeFirst()); System.out.println(list.removeLast()); while (!list.isEmpty()) { //判断集合是否为空 System.out.println(list.pop()); //弹出集合中的栈顶元素 }
Victory底层数据结构是数组,查询快,增删慢;线程安全,效率低,几乎已经淘汰了这个集合
--------------------------------------------------------------------------------------------------------------------------------------------------------------------
Set:无序、不可重复;
HashSet:具有set的性质,直接来说HashSet,不可重复指的是存取的不可重复,当我们从它的底层研究就能清晰知道了,它的底层实现是哈希表,哈希表的底层是数组+链表/二叉树实现,如图: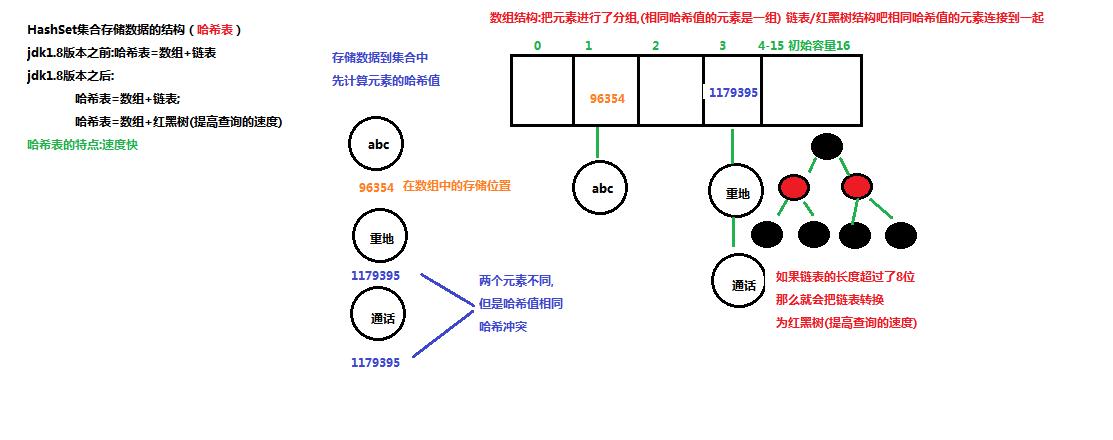
是先将元素的哈希值放入到数组中(如果在之后不对其的存储顺序作记录的话,这一步就决定它是无序的了),然后再用链表或者二叉树将元素与哈希值绑定起来。如果哈希值相同的,进行判断(所以要对Boolean的equals和hashcode方法进行重写),不重写的话,可能有存入预期之外“相同”的对象。
package collectionAndmore; import java.util.HashSet; import java.util.Iterator; public class hashset { public static void main(String[] args) { HashSet<Person> hashSet = new HashSet<Person>(); Person p1 = new Person("小猪",17); Person p2 = new Person("小猫", 20); Person p3 = new Person("小猫", 20); hashSet.add(p2); hashSet.add(p1); hashSet.add(p3); Iterator<Person> it = hashSet.iterator(); while (it.hasNext()) { Object o = it.next(); System.out.println(o.toString()); } for(Person p :hashSet) { System.out.println(p); } System.out.println(hashSet); } } Person [name=小猪, age=17] Person [name=小猫, age=20] Person [name=小猪, age=17] Person [name=小猫, age=20] [Person [name=小猪, age=17], Person [name=小猫, age=20]]
LinkedHashSet :其他功能和HashSet相同,但它的底层多了个链表,这保证了它的存取有序。
public class LinkedHashSetDemo { public static void main(String[] args) { Set<String> set = new LinkedHashSet<String>(); set.add("bbb"); set.add("aaa"); set.add("abc"); set.add("bbc"); Iterator<String> it = set.iterator(); while (it.hasNext()) { System.out.println(it.next()); } } } 结果: bbb aaa abc bbc
Collections
-
-
public static void shuffle(List<?> list) 打乱顺序:打乱集合顺序。 -
public static <T> void sort(List<T> list):将集合中元素按照默认规则排序。
package collectionAndmore; import java.util.Collection; import java.util.Collections; import java.util.LinkedList; public class ColletionTest { public static void main(String[] args) { LinkedList<String> link = new LinkedList<String>(); Collections.addAll(link, "我","爱","中","国");//一次性增加多个元素 System.out.println(link); Collections.shuffle(link);//打乱元素顺序 System.out.println(link); Collections.sort(link); // 将元素顺序按照默认方式排列 System.out.println(link); } } [我, 爱, 中, 国] [我, 爱, 中, 国] [中, 国, 我, 爱]
重点分析下Collections的sort方法里面的
Collections.sort(link); 可以自然升序,但是link容器中是自定义的对象呢?
package collectionAndmore; import java.util.Collection; import java.util.Collections; import java.util.LinkedList; public class ColletionTest { public static void main(String[] args) { LinkedList<Person> link = new LinkedList<Person>(); link.add(new Person("c张三",17)); link.add(new Person("李四", 18)); link.add(new Person("b王五", 17)); link.add(new Person("二赖子",20)); Collections.sort(link);//需要在元素对象类中重写Comparable接口的方法 System.out.println(link); } }
一定要在元素的对象类Person中实现Comparable接口和重写compareTo方法,compareTo方法可以加以拓展.....(在下面会提到)
public class Person implements Comparable<Person>{ .... @Override public int compareTo(Person o) { return this.age-o.age;//升序 } }
结果:
[Person [name=c张三, age=17], Person [name=b王五, age=17], Person [name=李四, age=18], Person [name=二赖子, age=20]]
Comparator:
具体的功能和上面提及的是一样的,也需要重写Comparator接口里面的compare方法
package collectionAndmore; import java.util.Collections; import java.util.Comparator; import java.util.LinkedList; public class CollectionsTest { public static void main(String[] args) { LinkedList<Student> link = new LinkedList<Student>(); link.add(new Student("c张三",17)); link.add(new Student("李四", 18)); link.add(new Student("b王五", 17)); link.add(new Student("二赖子",20)); Collections.sort(link,new Comparator<Student>() { @Override public int compare(Student o1, Student o2) { int result = o1.getAge()-o2.getAge(); if(result == 0) { result = o1.getName().charAt(0)-o2.getName().charAt(0); } return result; } }); System.out.println(link); } }
Map集合:
-
-
Map中的集合,元素是成对存在的(理解为夫妻)。每个元素由键与值两部分组成,通过键可以找对所对应的值。 -
Collection中的集合称为单列集合,Map中的集合称为双列集合。 -
需要注意的是,
Map中的集合不能包含重复的键,值可以重复;每个键只能对应一个值。
HashMap<K,V>:
数据的底层实现是哈希表(HshSet相同),元素的存取顺序无法保证(无序性)。由于要保证键的唯一性,所以要重写键equals方法和hashcode方法,一般自定义键的类型时.
Map接口中定义了很多方法,常用的如下:
-
public V put(K key, V value): 把指定的键与指定的值添加到Map集合中。 -
public V remove(Object key): 把指定的键 所对应的键值对元素 在Map集合中删除,返回被删除元素的值。 -
public V get(Object key)根据指定的键,在Map集合中获取对应的值。 -
boolean containsKey(Object key)判断集合中是否包含指定的键。 -
public Set<K> keySet(): 获取Map集合中所有的键,存储到Set集合中。 -
public Set<Map.Entry<K,V>> entrySet(): 获取到Map集合中所有的键值对对象的集合(Set集合)。
package MapTest; import java.util.HashMap; import java.util.Iterator; import java.util.Map.Entry; import java.util.Set; public class MapDemo { public static void main(String[] args) { HashMapTest(); } public static void HashMapTest() { HashMap<String, String> hashMap = new HashMap<>(); hashMap.put("confidence", "success"); hashMap.put("success", "confidenc"); hashMap.put("de", "di"); /*HashMap能存入null值 * */ /* * HashMap的遍历 */ Set<String> set1 = hashMap.keySet(); for(String key : set1) { System.out.println(key + "="+ hashMap.get(key)); } Set<String> set2 = hashMap.keySet(); Iterator<String> iterator = set2.iterator(); while (iterator.hasNext()) { String e = iterator.next(); System.out.println(e+"="+hashMap.get(e)); } System.out.println("entry -----------------"); Set<Entry<String, String>> entrySet = hashMap.entrySet(); for(Entry<String, String> e : entrySet) { System.out.println(e.getKey()+"="+e.getValue()); } } }
confidence=success de=di success=confidenc confidence=success entry ----------------- de=di success=confidenc confidence=success
LinkedHashMap extends HashMap<K,V> implements Map<K,V>继承了HashMap,功能大体上一样,在底层实现上多了条链表,让存取有序。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号