
一致性哈希算法
一致哈希算法 Consistent Hashing
标签(空格分隔): Java基础
1.场景描述(分布式缓存问题)
有三台缓存服务器sever1,server2,server3,如何读写呢?有如下方法
- 随机访问
- 哈希计算(取模法)
- 一致性哈希
随机访问
每次请求随机发送到一台缓存服务器,策略简单但是会导致问题:
- 同一份数据可能被存在不同的机器上造成数据冗余
- 数据已有缓存,但是没有命中
所以,随机策略在时间效率、空间效率上都不是很好。
哈希计算(取模法)
解决相同key访问发送到同一服务器的常用方法->计算哈希。如下
server=Hash(key)%3
这样会解决随机访问导致的问题。但是有产生了新的问题:
-
容错性:系统中有服务器不可用时,整个系统是否可正确高效运行
-
扩展性:加入新的服务器,整个系统是否可正确高效运行
假设现在有一台机器宕机了,那么之前的算法就要改为server=Hash(key)%(N-1)
增加一台服务器,则变为server=Hash(key)%(N+1)
这会导致无论是增加还是减少服务器都会从新计算Hash。从而导致缓存不命中问题。
一致性哈希
分布式系统每个节点都可能失效,在节点失效或者加入新节点后,如何把对数据的影响降到最低?在分布式缓存中,如果没有好的算法,某个节点失效或者加入新节点后,会对当前缓存的命中率产生巨大的影响。
传统Hash也不是最优解,更好的算法呼之欲出。
2.一致性哈希
定义:一致性哈希将整个哈希值空间组织成一个虚拟的圆环,如假设某哈希函数H的值空间为0~\(2^{32}\)-1(即哈希值是一个32位无符号整形),如何将一个key,映射到一个节点, 这里分为两步.
- 将服务的key按该hash算法计算,得到在服务在一致性hash环上的位置.
- 将缓存的key,用同样的方法计算出hash环上的位置,按顺时针方向,找到第一个大于等于该hash环位置的服务key,从而得到该key需要分配的服务器。
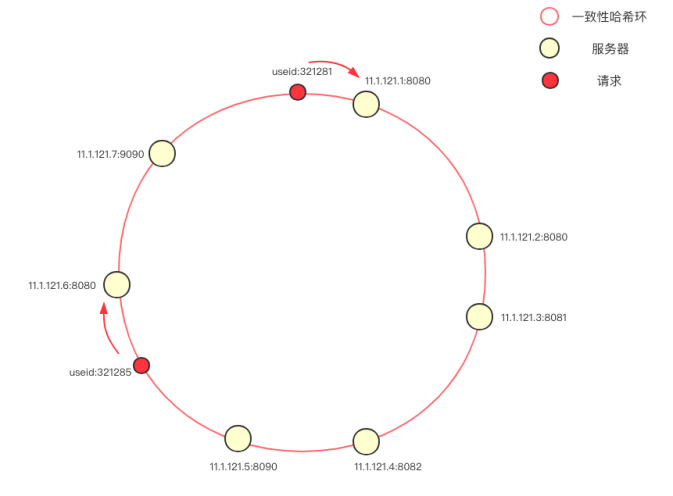
上图摘自语雀
当减少或者增加一个节点时,只对顺时针方向第一个原有节点的数据有影响,其他节点不变
3.hash环的偏斜
当节点比较少时,这个算法还是存在数据分布不均匀的情况,这时候可以引入虚拟节点。在原有的基础上多一步由虚拟节点映射到实际节点的步骤即可让少量节点也能满足均匀性。
4.如何虚拟节点
"虚拟节点"的 hash 计算可以采用对应节点的 IP 地址加数字后缀的方式。例如假设 cache A 的 IP 地址为202.168.14.241 。
引入“虚拟节点”前,计算 cache A 的 hash 值:
Hash(“202.168.14.241”);
引入“虚拟节点”后,计算“虚拟节”点 cache A1 和 cache A2 的 hash 值:
Hash(“202.168.14.241#1”); // cache A1
Hash(“202.168.14.241#2”); // cache A2
5.为什么Hash环对(\(2^{32}\))取模,而不是其他的数
没有搞懂为何选这个数字,有人说是一个无符号int,此问题待定...
总结
参考文章:
这几篇文章都写得特别好,通俗易懂
语雀
朱双印的博客-白话解析一致性哈希
oilbeater 的自习室-一致性哈希
掘金-五分钟看懂一致性哈希算法(附带java代码)
google文章

 浙公网安备 33010602011771号
浙公网安备 33010602011771号