线段树进阶应用学习笔记(四):单侧递归问题
线段树最重要的操作就是 pushup 和 pushdown,对于一类问题,光凭当前节点的信息无法合并,需要用到它的子节点的信息才能合并,这就是线段树单侧递归问题,时间复杂度一般是 \(O(n \log^2 n)\)。
打个比方,比如一条河流被污染了,但是仅在这条河岸找不到污染源,于是只能看这条河是由哪几条河汇流而成,找到那条被污染的河流继续看它是由哪几条河汇流而成,最终会找到污染的源头。
区间前缀最大值问题
线段树单侧递归解决的一类问题就是区间前缀最大值的信息统计,来看两道例题:
区间前缀最大值个数
首先可以发现只有当后面的楼房与原点连线所形成的角的 \(\tan\) 值比前面的大,才能被看到,于是我们把每个楼房与原点连线所形成的角的 \(\tan\) 值算出来,那么问题就变成了:
-
单点修改;
-
询问全局前缀最大值个数。
由于需要对序列进行修改,于是考虑线段树。让线段树上每个节点维护两个信息:
-
这个区间的答案
t[id].ans; -
这个区间的最大值
t[id].maxn。
那么答案就是 t[1].ans,区间最大值是好维护的,考虑如何维护区间前缀最大值个数。考虑线段树 pushup 的过程,我们现在要将 \(id\) 的左儿子与 \(id\) 的右儿子这两个区间的信息合并到 \(id\)。首先,如果 \(id\) 的左儿子的区间最大值已经比 \(id\) 的右儿子的大,这时 \(id\) 的右儿子的所有前缀最大值都对答案造不成贡献,\(id\) 的信息直接从 \(id\) 的左儿子继承即可。
考虑 \(id\) 的左儿子的区间最大值比 \(id\) 的右儿子的小的情况,这时我们会发现由于我们不知道 \(id\) 的右儿子有多少个前缀最大值会被保留,因此无法直接合并。于是我们考虑找到 \(id\) 的右儿子的两个子区间 \(ls\) 和 \(rs\),如果 \(ls\) 的区间最大值小于 \(id\) 的左儿子的区间最大值,那么这个区间内所有前缀最大值均不会被保留,直接往 \(id\) 的右儿子递归判断:
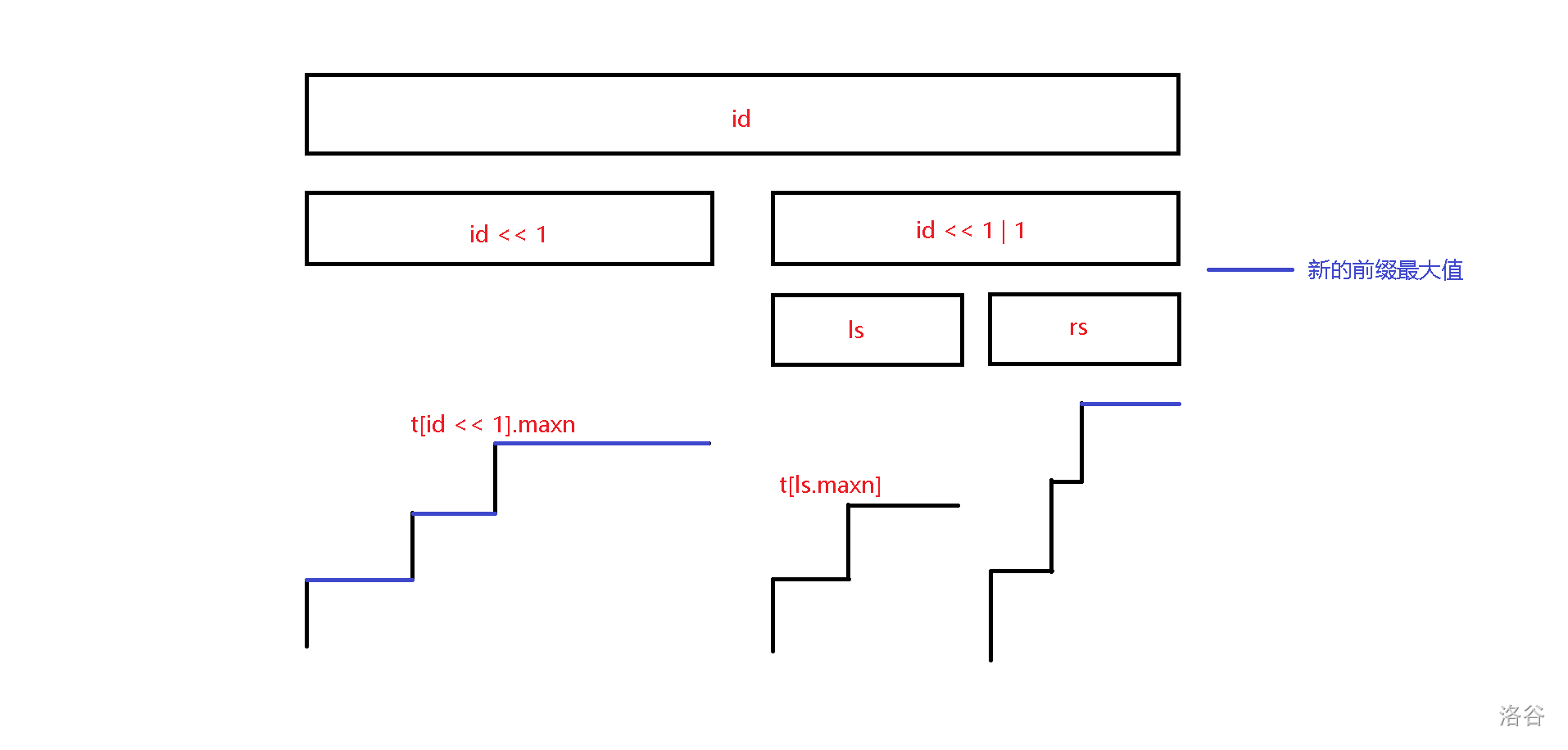
现在再来考虑 \(ls\) 的区间最大值大于 \(id\) 的左儿子的情况,我们先统计 \(rs\) 对答案造成的贡献。考虑到如果一个 \(rs\) 的前缀最大值比区间 \(ls\) 的区间最大值还要大,那么这个值一定会被保留下来。于是我们现在就要求的就是在 \(ls\) 的遮挡下,\(rs\) 有多少个前缀最大值被保留了下来,考虑到 \(id\) 的右儿子的答案就等于 \(ls\) 的答案加上在 \(ls\) 的遮挡下,\(rs\) 有多少个前缀最大值被保留了下来,于是我们对答案加上 t[id << 1 | 1].ans - t[ls].ans,然后往 \(ls\) 递归即可:
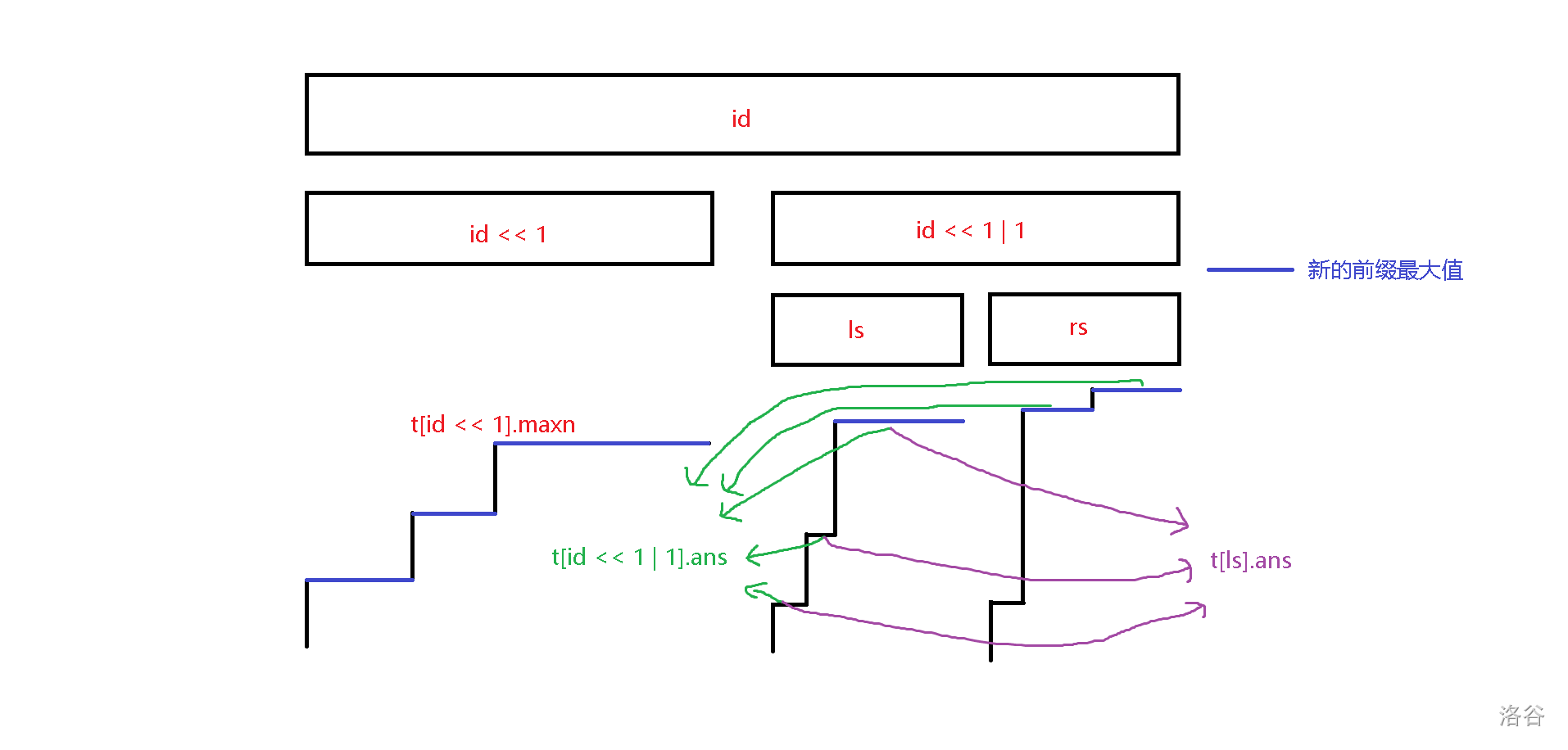
那么这道题就在 \(O(n \log^2 n)\) 的时间复杂度内解决了。
点击查看代码
#include <bits/stdc++.h>
using namespace std;
const int N = 1e5 + 9;
struct Node{
int ans;
double maxn;
} t[N << 2];
int n, m;
void pushup(int id, int l, int r){
t[id].maxn = max(t[id << 1].maxn, t[id << 1 | 1].maxn);
t[id].ans = t[id << 1].ans;
int now = id << 1 | 1;
double cmp = t[id << 1].maxn;
while(true){
if(l == r){
t[id].ans += (t[id].maxn > cmp);
break;
}
if(t[now].maxn <= cmp)
break;
int mid = (l + r) >> 1;
if(cmp >= t[now << 1].maxn){
now = now << 1 | 1;
l = mid + 1;
} else {
t[id].ans += t[now].ans - t[now << 1].ans;
now = now << 1;
r = mid;
}
}
}
void modify(int id, int l, int r, int q, double qx){
if(l == r){
t[id].maxn = qx;
t[id].ans = 1;
return;
}
int mid = (l + r) >> 1;
if(q <= mid)
modify(id << 1, l, mid, q, qx);
else
modify(id << 1 | 1, mid + 1, r, q, qx);
pushup(id, mid + 1, r);
}
int main(){
scanf("%d%d", &n, &m);
while(m--){
int x, y;
scanf("%d%d", &x, &y);
modify(1, 1, n, x, y * 1.0 / x);
printf("%d\n", t[1].ans);
}
return 0;
}
区间前缀最大值的和
AT_jsc2019_final_h Distinct Integers
第一届日本最强程序员学生锦标赛决赛
首先,这道题目要求的是区间有多少个子区间没有重复数字,如果我们记录一下每个数字 \(i\) 前一次出现的位置 \(pre_i\),那么问题就变成了有多少个子区间包括 \(i\) 但不包括 \(pre_i\),由于区间内每个数字都不能重复出现,于是固定住 \(r\),\(l\) 最左就只能到 \(\max_{i = L}^r pre_i + 1\),此时对于答案的贡献就是 \(r - l + 1\),于是答案就变成了 \(\displaystyle\sum_{i = L}^R (i - \max_{j = L}^i pre_j) = \frac{(L + R)(R - L + 1)}{2} - \sum_{i = L}^R \max_{j = L}^i pre_j\),于是问题就变成了求区间 \([l, r]\) 中前缀 \(pre\) 的最大值的和。
现在我们将问题转化成了区间前缀最大值问题,依然考虑使用线段树单侧递归的写法。考虑 \(id\) 的两个儿子以及 \(id\) 的右儿子的两个儿子 \(ls\) 和 \(rs\),如果 \(id\) 的左儿子的区间最大值比 \(id\) 的右儿子的大,那么 \(id\) 的右儿子的所有前缀最大值都无法对答案造成贡献,于是 \(id\) 的答案就是 \(id\) 的左儿子的答案加上 \(id\) 的右儿子的长度乘以 \(id\) 的左儿子的区间最大值。
考虑 \(ls\) 的区间最大值小于 \(id\) 的左儿子的这种情况,此时 \(ls\) 的所有前缀最大值都无法保留,于是答案加上 \(ls\) 的长度乘上 \(id\) 的左儿子的区间最大值,往 rs 递归即可。
最后考虑 \(ls\) 的区间最大值大于 \(id\) 的左儿子的这种情况,由于如果 \(rs\) 的一个前缀最大值大于 \(ls\) 的区间最大值,那么一定会在 \(id\) 的前缀最大值中被保留下来,而且 \(id\) 的左儿子的答案等于 \(ls\) 的答案加上在 \(ls\) 遮挡下 \(rs\) 的答案,因此将答案加上 t[id << 1 | 1].ans - t[ls].ans,往 \(ls\) 递归即可。
修改操作可以给每种值开一个集合,记录这种值出现的下标。将 \(a_x\) 修改为 \(y\) 时,只用将 \(x\) 在 \(a_x\) 集合中的后继的 \(pre\) 修改为 \(x\) 的前驱,并将 \(x\) 的 \(pre\) 修改为它在 \(y\) 集合中的前驱,将 \(x\) 后继的 \(pre\) 修改为 \(x\) 即可。
注意一下,如果最大的 \(pre_i\) 都小于 \(L\),那么 \(l\) 只能取到 \(L\),不能更小,因此需要特判一下。那么这道题就在 \(O(n \log^2 n)\) 的时间复杂度内解决。
点击查看代码
#include <bits/stdc++.h>
using namespace std;
#define int long long
const int N = 5e5 + 9;
struct Node{
int ans, maxn;
} t[N << 2];
int a[N], pre[N], n, q;
int prequery(int id, int l, int r, int ql, int qr){
if(ql <= l && r <= qr)
return t[id].maxn;
int mid = (l + r) >> 1, ans = 0;
if(ql <= mid)
ans = prequery(id << 1, l, mid, ql, qr);
if(qr > mid)
ans = max(ans, prequery(id << 1 | 1, mid + 1, r, ql, qr));
return ans;
}
int pushup(int now, int l, int r, int cmp){
int res = 0;
while(true){
if(l == r){
res += max(t[now].maxn, cmp);
break;
}
int mid = (l + r) >> 1;
if(cmp > t[now << 1].maxn){
res += (mid - l + 1) * cmp;
now = now << 1 | 1;
l = mid + 1;
} else {
res += t[now].ans - t[now << 1].ans;
now = now << 1;
r = mid;
}
}
return res;
}
void build(int id, int l, int r){
if(l == r){
t[id].maxn = t[id].ans = pre[l];
return;
}
int mid = (l + r) >> 1;
build(id << 1, l, mid);
build(id << 1 | 1, mid + 1, r);
t[id].maxn = max(t[id << 1].maxn, t[id << 1 | 1].maxn);
t[id].ans = t[id << 1].ans + pushup(id << 1 | 1, mid + 1, r, t[id << 1].maxn);
}
void modify(int id, int l, int r, int q, int qx){
if(l == r){
t[id].ans = t[id].maxn = qx;
return;
}
int mid = (l + r) >> 1;
if(q <= mid)
modify(id << 1, l, mid, q, qx);
else
modify(id << 1 | 1, mid + 1, r, q, qx);
t[id].maxn = max(t[id << 1].maxn, t[id << 1 | 1].maxn);
t[id].ans = t[id << 1].ans + pushup(id << 1 | 1, mid + 1, r, t[id << 1].maxn);
}
int query(int id, int l, int r, int ql, int qr){
if(ql <= l && r <= qr)
return pushup(id, l, r, l - 1 ? prequery(1, 1, n, 1, l - 1) : 0);
int mid = (l + r) >> 1, ans = 0;
if(ql <= mid)
ans += query(id << 1, l, mid, ql, qr);
if(qr > mid)
ans += query(id << 1 | 1, mid + 1, r, ql, qr);
return ans;
}
vector <int> s[N];
signed main(){
scanf("%lld%lld", &n, &q);
for(int i = 1; i <= n; i++)
s[i].push_back(0);
for(int i = 1; i <= n; i++){
scanf("%lld", &a[i]);
a[i]++;
s[a[i]].insert(lower_bound(s[a[i]].begin(), s[a[i]].end(), i), i);
pre[i] = *--lower_bound(s[a[i]].begin(), s[a[i]].end(), i);
}
build(1, 1, n);
while(q--){
int opt, x, y;
scanf("%lld%lld%lld", &opt, &x, &y);
x += 1;
y += !opt;
if(opt == 0){
if(upper_bound(s[a[x]].begin(), s[a[x]].end(), x) != s[a[x]].end()){
modify(1, 1, n, *upper_bound(s[a[x]].begin(), s[a[x]].end(), x), *--lower_bound(s[a[x]].begin(), s[a[x]].end(), x));
pre[*upper_bound(s[a[x]].begin(), s[a[x]].end(), x)] = *--lower_bound(s[a[x]].begin(), s[a[x]].end(), x);
}
s[a[x]].erase(lower_bound(s[a[x]].begin(), s[a[x]].end(), x));
s[y].insert(lower_bound(s[y].begin(), s[y].end(), x), x);
pre[x] = *--lower_bound(s[y].begin(), s[y].end(), x);
modify(1, 1, n, x, *--lower_bound(s[y].begin(), s[y].end(), x));
if(upper_bound(s[y].begin(), s[y].end(), x) != s[y].end()){
modify(1, 1, n, *upper_bound(s[y].begin(), s[y].end(), x), x);
pre[*upper_bound(s[y].begin(), s[y].end(), x)] = x;
}
a[x] = y;
} else {
modify(1, 1, n, x, x - 1);
printf("%lld\n", (x + y) * (y - x + 1) / 2 - query(1, 1, n, x, y));
modify(1, 1, n, x, pre[x]);
}
}
return 0;
}
括号序列问题
sto %%%  %%% orz
%%% orz
不愧是数据结构大师 lxl,竟能把括号序列问题转化成前缀最大值问题,强。
我们把左括号看成 \(-1\),右括号看成 \(+1\),再将其变为前缀和数组,于是所有右括号所在位置都是某个前缀最大值,那么我们就可以用线段树单侧递归解决带修括号序列问题。
这么说有一点玄幻,来看一道题:
连毒瘤都觉得毒瘤的题,对于我这种凡人来说,真的是一坨超级大的,写加调一共花了 \(6\) 天 qwq。
依然考虑用线段树单侧递归解决这道题目,我们令线段树上一个节点 \([l, r]\) 维护这段括号序列未匹配的括号信息。如果一个节点出现了 \((]\) 这种情况,那么无论后面拼上什么括号序列,都无法将其消除,直接打上一个标记即可。同时,我们也知道了,如果一个节点维护的未匹配括号能在以后被匹配上,那么一定是一段右括号加一段左括号的形式:\()\}>)])] ((\{<[(<\)。
依然考虑单侧递归的形式,我们现在要将 \(id\) 的左儿子和 \(id\) 的右儿子的信息合并到 \(id\)。显然,如果一个节点被标记了,那么直接将 \(id\) 也打上标记即可。
现在我们考虑一般情况,我们希望 \(id\) 的左儿子的左括号能与 \(id\) 的右儿子的右括号相匹配,这不难想到哈希,于是我们在线段树一个节点要记录左括号个数、左括号哈希值、右括号个数、右括号哈希值这 \(4\) 个信息。
这里顺道讲一下我的哈希方法,由于传统模数 \(998244353\) 与 \(10^9 + 7\) 太容易被卡,且取模速度极慢,于是我们换一个模数 \(p = 2^{61} - 1\)(是个质数)。可以发现,\(2^{61} - 1\) 的所有 \(61\) 个二进制位都是 \(1\),那么对于被取模数 \(x\) 的后 \(61\) 位,取模后还是其本身,因此就是 \((2^{61} - 1) \operatorname{and} x\),而剩下的那些位可以写成 \(y \times 2^{61}\),我们考虑对其做带余除法:\(\displaystyle\frac{y \times 2^{61}}{2^{61} - 1} = \frac{y \times (2^{61} - 1) + y}{2^{61} - 1} = \frac{y}{2^{61} - 1}\)。于是直接右移 \(61\) 位,加上 \((2^{61} - 1) \operatorname{and} x\),再取模就行了(其实可以直接减)。
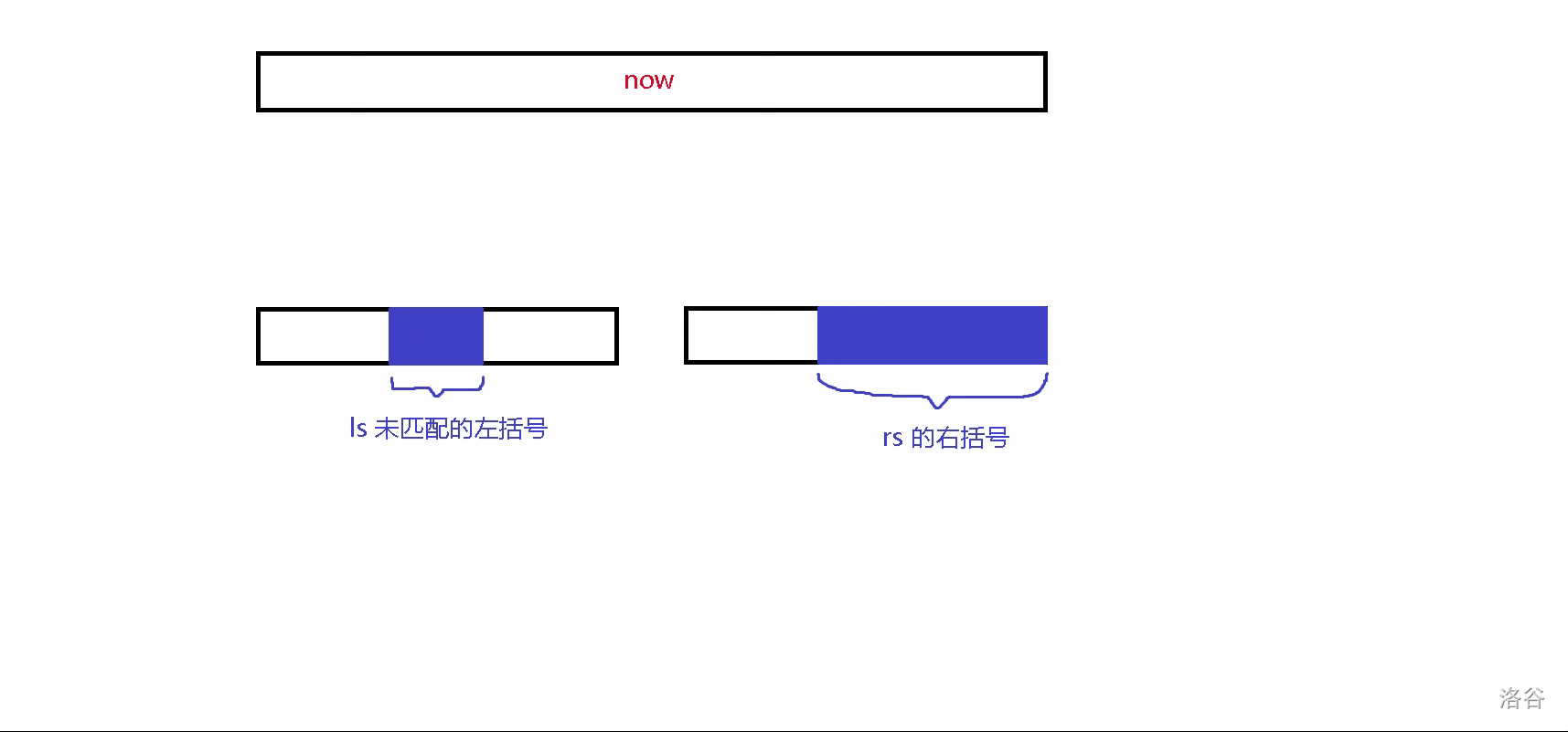
说回正题,假设现在 \(id\) 的左儿子的左括号数大于 \(id\) 的右儿子的右括号数(对称情况同理),那么我们现在需要找到 \(id\) 的左儿子的左括号的一段后缀与 \(id\) 的右儿子的右括号进行匹配,我们令 \(now\) 表示目前递归到节点 \(now\),\(ls\) 表示 \(now\) 的左儿子,\(rs\) 表示 \(now\) 的右儿子,\(sum\) 还需要匹配 \(sum\) 个右括号。初始时 \(now\) 为 \(id\) 的左儿子,\(sum\) 为 \(id\) 的右儿子的右括号数。
-
如果 \(rs\) 的左括号数等于 \(sum\),直接返回这段左括号的哈希值;
-
如果 \(rs\) 的左括号数大于 \(sum\),直接往 \(rs\) 递归即可。
现在我们来考虑最复杂的 \(rs\) 的左括号数小于 \(sum\) 的情况,那么 \(now\) 的左括号的来源应该如图:
\(rs\) 的左括号的哈希值是好求的,我们考虑 \(ls\) 的左括号的哈希值。这个值等于 \(ls\) 所有左括号的哈希值减去发生匹配的左括号的哈希值,而发生匹配的左括号的哈希值正好等于 \(rs\) 的右括号的哈希值:
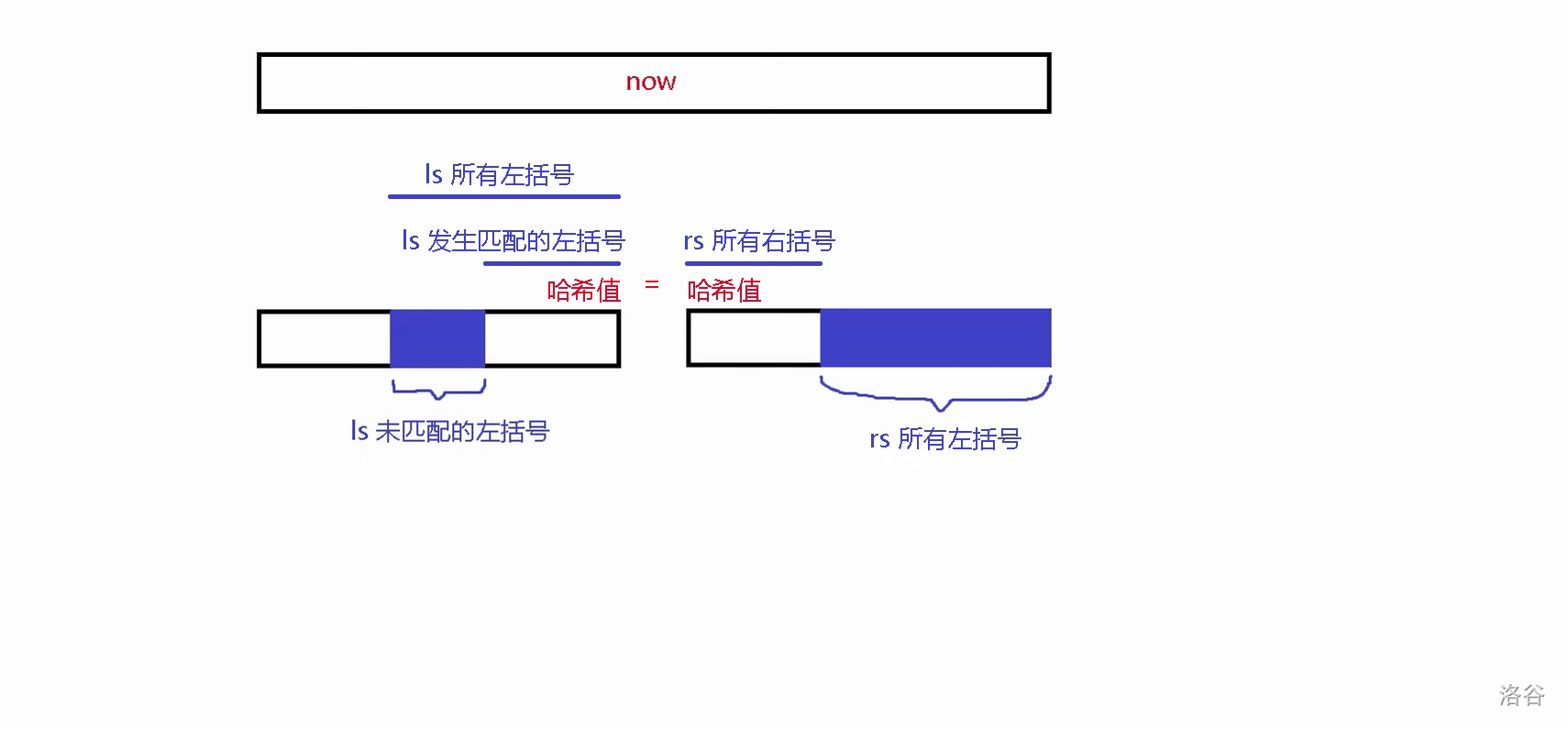
于是,我们将返回值加上 \(rs\) 左括号的哈希值,再减去 \(rs\) 右括号的哈希值,往 \(ls\) 递归即可。
注意此处的加减均为哈希值的加减,注意顺序和基数。
query 操作和合并操作类似,我们把找出来的 \(cnt = O(\log_2 n)\) 个节点重新建成一棵“左偏”的线段树(不需要正真建出来,从左往右扫一遍即可):
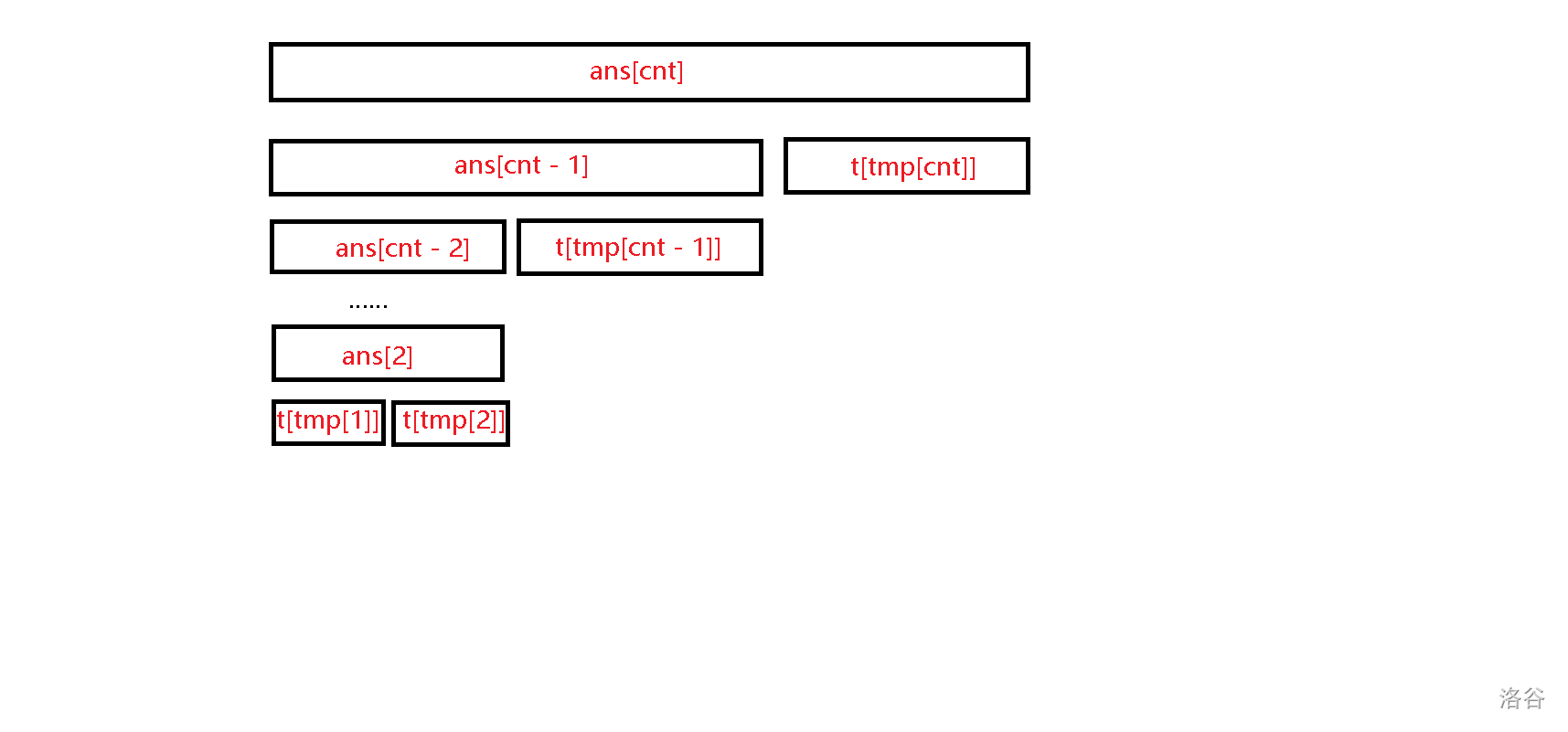
(ans[i] 记录前 \(i\) 个节点匹配后的括号序列,tmp[i] 记录第 \(i\) 个节点在原线段树上的编号)
单侧递归时,如果往左儿子走,那么与合并时往左儿子走类似,否则就是在原线段树上某个节点找其右儿子的一段后缀与需要的左括号相匹配,直接调用之前编好的函数即可,于是我们在 \(O(n \log^2 n)\) 的时间复杂度内解决了这个问题。
点击查看代码
#include <bits/stdc++.h>
using namespace std;
#define int long long
const int N = 1e5 + 9, base = 5201314, MOD = (1ll << 61) - 1;
int B[N], n, k, q;
int plu(int x, int y){
return x + y > MOD ? x + y - MOD : x + y;
}
int sub(int x, int y){
return x < y ? x - y + MOD : x - y;
}
int mod(__int128 x){
return sub((MOD & x) + (x >> 61), MOD);
}
int mul(__int128 x, int y){
return mod(x * y);
}
struct Hash{
int len, val;
Hash(){
len = val = 0;
}
Hash operator + (const Hash &b) const{//将 b 拼在 a 的右边 a + b = ab
Hash res;
res.val = plu(mul(b.val, B[len]), val);
res.len = len + b.len;
return res;
}
Hash operator - (const Hash &b) const{//将 a 开头 b 个字母去掉 ab - b = a
Hash res;
res.val = sub(val, mul(b.val, B[len - b.len]));
res.len = len - b.len;
return res;
}
};
struct Sgt{
Hash l, r;//右括号在左边,左括号在右边 )}>)])] (({<[(<
bool flag;
} t[N << 2];
Hash getval1(int now, int sum){//目前在节点 now,需要凑 sum 个左括号
if(sum == 0)
return Hash();
if(t[now].l.len == sum)//当前节点恰好有 sum 个左括号
return t[now].l;
else if(t[now << 1 | 1].l.len > sum)//当前节点右儿子有 >sum 个左括号
return getval1(now << 1 | 1, sum);//往右儿子递归
else
return getval1(now << 1, sum - t[now << 1 | 1].l.len + t[now << 1 | 1].r.len) - t[now << 1 | 1].r + t[now << 1 | 1].l;
}
Hash getval2(int now, int sum){//目前在节点 now,需要凑 sum 个右括号,与 getval1 同理
if(sum == 0)
return Hash();
if(t[now].r.len == sum)
return t[now].r;
else if(t[now << 1].r.len > sum)
return getval2(now << 1, sum);
else {
return getval2(now << 1 | 1, sum - t[now << 1].r.len + t[now << 1].l.len) - t[now << 1].l + t[now << 1].r;
}
}
void pushup(int id){
if(t[id << 1].flag || t[id << 1 | 1].flag)
return t[id].flag = 1, void();
t[id].flag = 0;
if(t[id << 1].l.len > t[id << 1 | 1].r.len){//在左儿子找与右儿子匹配的括号
if(getval1(id << 1, t[id << 1 | 1].r.len).val == t[id << 1 | 1].r.val){
t[id].r = t[id << 1].r;
t[id].l = t[id << 1].l - t[id << 1 | 1].r + t[id << 1 | 1].l;
} else
t[id].flag = true;
} else {//同理
if(getval2(id << 1 | 1, t[id << 1].l.len).val == t[id << 1].l.val){
t[id].l = t[id << 1 | 1].l;
t[id].r = t[id << 1 | 1].r - t[id << 1].l + t[id << 1].r;
} else
t[id].flag = true;
}
}
void build(int id, int l, int r){
if(l == r){
int tmp;
scanf("%lld", &tmp);
if(tmp > 0){
t[id].l.val = tmp;
t[id].l.len = 1;
} else {
t[id].r.val = -tmp;
t[id].r.len = 1;
}
return;
}
int mid = (l + r) >> 1;
build(id << 1, l, mid);
build(id << 1 | 1, mid + 1, r);
pushup(id);
}
void modify(int id, int l, int r, int q, int qx){
if(l == r){
if(qx > 0){
t[id].l.val = qx;
t[id].r.val = 0;
t[id].l.len = 1;
t[id].r.len = 0;
} else {
t[id].r.val = -qx;
t[id].l.val = 0;
t[id].r.len = 1;
t[id].l.len = 0;
}
return;
}
int mid = (l + r) >> 1;
if(q <= mid)
modify(id << 1, l, mid, q, qx);
else
modify(id << 1 | 1, mid + 1, r, q, qx);
pushup(id);
}
int sta[N], cnt;
void query(int id, int l, int r, int ql, int qr){
if(ql <= l && r <= qr)
return sta[++cnt] = id, void();
int mid = (l + r) >> 1;
if(ql <= mid)
query(id << 1, l, mid, ql, qr);
if(qr > mid)
query(id << 1 | 1, mid + 1, r, ql, qr);
}
Sgt ans[N];
Hash getval3(int now, int sum){
if(sum == 0)
return Hash();
if(ans[now].l.len == sum)
return ans[now].l;
else if(t[sta[now]].l.len > sum)
return getval1(sta[now], sum);
else
return getval3(now - 1, sum - t[sta[now]].l.len + t[sta[now]].r.len) - t[sta[now]].r + t[sta[now]].l;
}
signed main(){
scanf("%lld%lld", &n, &k);
B[0] = 1;
for(int i = 1; i <= n; i++)
B[i] = mul(B[i - 1], base);
build(1, 1, n);
scanf("%lld", &q);
while(q--){
int opt, x, y, l, r;
scanf("%lld", &opt);
if(opt == 1){
scanf("%lld%lld", &x, &y);
modify(1, 1, n, x, y);
} else {
scanf("%lld%lld", &l, &r);
cnt = 0;
query(1, 1, n, l, r);
bool flg = false;
for(int i = 1; i <= cnt; i++){
if(t[sta[i]].flag){
flg = true;
break;
}
if(ans[i - 1].l.len < t[sta[i]].r.len){
flg = true;
break;
}
if(getval3(i - 1, t[sta[i]].r.len).val == t[sta[i]].r.val){
ans[i].r = Hash();
ans[i].l = ans[i - 1].l - t[sta[i]].r + t[sta[i]].l;
} else {
flg = true;
break;
}
}
if(ans[cnt].l.len || ans[cnt].r.len || flg)
printf("No\n");
else
printf("Yes\n");
}
}
return 0;
}
本文来自博客园,作者:Orange_new,转载请注明原文链接:https://www.cnblogs.com/JPGOJCZX/p/18716186

 浙公网安备 33010602011771号
浙公网安备 33010602011771号