

HashMap长度2次幂/扩容相关
HashMap这样做有两点原因
提升计算效率,更快算出元素的位置
减少哈希碰撞,使得元素分布均匀
提升计算效率
我们先看put方法的细节:
public V put(K key, V value) { return putVal(hash(key), key, value, false, true); }
其中hash(key)如下:
static final int hash(Object key) { int h; return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16); }
hash()方法返回二次运算后的哈希值即可。
putVal()方法:
可以看到,对于一个key,拿到hash(key)后,之后要确定这个key在数组中的位置,我们一般倾向于对数组长度length取余,余数是几,就在数组的第几个位置上,简单方便。
但对于机器而言,位运算永远比取余运算快得多,在length为2的整数次方的情况下(length-1得到的二进制为全1),hash(key)%length能被替换成高效的hash(key)&(length-1),两者的结果是相等的。
减少哈希碰撞
如果数组长度是2的整数次方时,也就是一个偶数,length-1就是一个奇数,奇数的二进制最后一位是1,因此不管hash(key)是多少,hash(key)&(length-1)的二进制最后一位可能是0,也可能是1,取决于hash(key)。即如果hash(key)是奇数的话,则映射到数组上第奇数个位置上。
如果length是一个奇数的话,length-1就是一个偶数,偶数的二进制最后一位是0,则不管hash(key)是奇数还是偶数,该元素都会被映射到数组上第偶数个位置上,奇数位置上没有任何元素!
因此,数组长度是一个2的整数次方时,哈希碰撞的概率起码能下降一半,而且所有元素也能均匀地分布在数组上。
JDK8的扩容机制
HashMap的容量变化通常存在以下几种情况:
- 空参数的构造函数:实例化的HashMap默认内部数组是null,即没有实例化。第一次调用put方法时,则会开始第一次初始化扩容,长度为16。
- 有参构造函数:用于指定容量。会根据指定的正整数找到不小于指定容量的2的幂数,将这个数设置赋值给阈值(threshold)。第一次调用put方法时,会将阈值赋值给容量,然后让
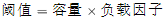 。(因此并不是我们手动指定了容量就一定不会触发扩容,超过阈值后一样会扩容!!)
。(因此并不是我们手动指定了容量就一定不会触发扩容,超过阈值后一样会扩容!!) - 之后超过阈值的扩容,容量变为原来的2倍,阈值也变为原来的2倍。(容量和阈值都变为原来的2倍时,负载因子还是不变)
JDK8的元素迁移
JDK8则因为巧妙的设计,性能有了大大的提升:由于数组的容量是以2的幂次方扩容的,那么一个Entity在扩容时,新的位置要么在原位置,要么在原长度+原位置的位置。原因如下图:
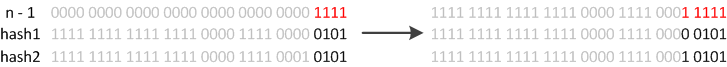
数组长度变为原来的2倍,表现在二进制上就是多了一个高位参与数组下标确定。此时,一个元素通过hash转换坐标的方法计算后,恰好出现一个现象:最高位是0则坐标不变,最高位是1则坐标变为“10000+原坐标”,即“原长度+原坐标”。如下图:
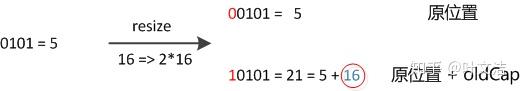
因此,在扩容时,不需要重新计算元素的hash了,只需要判断最高位是1还是0就好了。JDK8在迁移元素时是正序的,不会出现链表转置的发生。
其他
key.hashCode()^ (h >>> 16)
>>>的含义,即无符号右移,高位补0。例如:
0111 1110 0000 1111 1011 0001 0101 1010
右移16位得到
0000 0000 0000 0000 0111 1110 0000 1111
一般来说,任意一个对象的哈希值比较大,随便实例化一个对象,得到它的hash值
转换成2进制后,得到
0011 1001 1010 0000 0101 0100 1010 0101
而HashMap的长度一般就在[1,2^16]左右,取length=16为例,那么直接使用key的哈希值&(length-1)后,得到
0011 1001 1010 0000 0101 0100 1010 0101
&
0000 0000 0000 0000 0000 0000 0000 1111
---------------------------------------
0000 0000 0000 0000 0000 0000 0000 0101
可见,运算后的结果对哈希值的高位无效,即如果两个不同对象的哈希值仅仅在高位上不一样的话,依然会存在哈希冲突的情况。因此,我们现在打算让运算后的结果对哈希值的高位以及低位都有效。
而对哈希值再次运算后,即使用key.hashCode()^ (h >>> 16)运算后,将哈希值的低16位异或了高16位,让高位与低位都影响到了对之后位置的选择上。
为什么使用^异或^能保证两个数都能影响到最终的结果,而|中只要一个为1,不管对方是多少,结果都为1,&也是同样的道理,有0则0。
区别两个细微对象的不同,就要深挖其细微之处。因此要在最大程度上避免哈希冲突,就越要使用到所有已知的特征,不能认为细微就没用。

