校园网站地图绘制
校园网站地图绘制
问题描述
集美大学内部有多个网站,有的网站之间互有链接,有的网站没有指向其他站点的链接,有的网站只有没有被任何其他站点所指向,或者各种情况都有。
设计一个爬虫算法从一个节点出发,尝试绘制整个集美大学所有网站的链接拓扑图。
问题分析
根据题目的需求,我们需要设计一个爬虫算法来实现对集美大学内部网站的爬取,并且获取这些网站之间的关系,根据关系生成对应的图。
因此,我使用Python来实现爬虫算法,并且实现图的生成。
1、标签类型
由于需要对节点进行分类,所以我们总共划分了四个类型,根据每个网站出度的多少来划分
类型一:连接网站小于等于5
类型二:连接网站在5-10之间
类型三:连接网站在10-15之间
类型四:连接网站在15以上
而不同的类型将会以不同的颜色表示,颜色由pyecharts库自行生成。
2、节点
我们将根据网站的出度来确立节点的大小,即对于点集的参数symbolSize,我们将通过节点的出度来赋值,网站所连接的节点越多,该网站的节点就越大。
3、边
根据网站之间的联系,我们生成不同的边,边的信息表明了某个网站到另一个网站的指向。一个节点所连接的线越多,说明它与校内其他网站间的关系越密切。
4、算法构思
类似于BFS,我们以集美大学教务处的网站为起点,然后爬取页面内的校内链接,将其放入列表中,根据迭代达到类似BFS的效果。
流程图
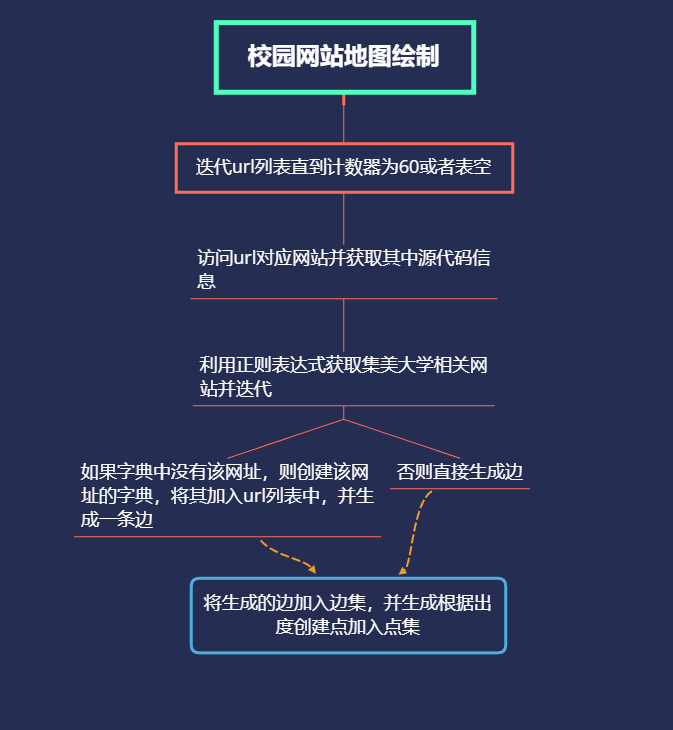
代码
import re,requests
from bs4 import BeautifulSoup
from pyecharts import options as opts
from pyecharts.charts import Graph
idnum = 0#记录点的id信息
linknum = -1#记录边的id信息
ulist = ['http://jwc.jmu.edu.cn']
iddic = {"http://jwc.jmu.edu.cn":"0"}
categories = [
{
"name": "类型一"#<=5
},
{
"name": "类型二"#5-10
},
{
"name": "类型三"#10-15
},
{
"name": "类型四"#>=15
}
]
nodes = []
links = []
#根据url访问网站并爬取
def GetUrl(url,ulist,nodes,links,iddic):
global idnum,linknum
try:
head = {
'User-Agent': 'Mozilla/5.0 '
}
r = requests.get(url,headers = head,timeout = 20)
r.encoding = 'utf-8'
soup = BeautifulSoup(r.text,'html.parser')
name = soup.find('title').text
mes = re.compile(r'http://.{1,8}?jmu.edu.cn')
mo = set(mes.findall(r.text))
cnt = 0
for chush in mo:
cnt = cnt+1
if chush not in iddic:
idnum += 1
iddic[chush] = str(idnum)
linknum += 1
link = {
"id": str(linknum),
"source": iddic[url],
"target": iddic[chush]
}
links.append(link)
ulist.append(chush)
else:
linknum += 1
link = {
"id": str(linknum),
"source": iddic[url],
"target": iddic[chush]
}
links.append(link)
cat = 0
if cnt <= 5:
cat = 0
elif cnt<=10:
cat = 1
elif cnt<=15:
cat = 2
else:
cat = 3
node = {
"id": iddic[url],
"name": name+'\n '+url,
"symbolSize": (cnt+1)*2,
"label": {
"normal": {
"show": True
}
},
"category": cat
}
nodes.append(node)
except:
pass
def main(ulist,nodes,links,iddic):
idx = 0
while True:
try:
url = ulist[idx]
GetUrl(url,ulist,nodes,links,iddic)
idx = idx + 1
except:
break
if idx == 60:
break
print(idx)
main(ulist,nodes,links,iddic)
c = (
Graph(init_opts=opts.InitOpts(width="1500px", height="1000px"))
.add(
"",
nodes=nodes,
links=links,
categories=categories,
layout="circular",
is_rotate_label=True,
linestyle_opts=opts.LineStyleOpts(color="source", curve=0.3),
label_opts=opts.LabelOpts(position="right"),
)
.set_global_opts(
title_opts=opts.TitleOpts(title="Graph-jmu"),
legend_opts=opts.LegendOpts(orient="vertical", pos_left="2%", pos_top="20%"),
)
.render("jmu.html")
)
这段代码是用Python来实现的,鉴于目前我们以C和C++为主,就不作详细的解释,而是简单说一下实现的功能,首先我们调用一下所需要的库,然后设置全局变量。
1、
def表示定义函数,其中GetUrl(url,ulist,nodes,links,iddic)函数是这个算法的主体,它传入的参数主要是
url:即所要爬取的网站的网址
ulist:存放所要url的列表,我们需要将爬取到的网址存入这个列表中
nodes:点集,我们通过函数生成节点信息加入点集中
links:边集,我们将爬取到的网址与url生成对应边的关系,并加入边集中
iddic:字典,存放url的id信息,用来检查爬取到的url是否曾经爬取过,保证生成点时该url的id唯一。
2、
def main(ulist,nodes,links,iddic)
主函数,其中参数与Geturl相同,目的是为了迭代ulist列表。
3、总体简介
GetUrl函数将传入的url参数作为requests库的访问对象,然后获取网页的源代码信息,利用正则表达式来获取相关的网址并返回,返回的网址以列表的形式存储,然后我们迭代这个列表,判断这个网址是否在字典中如果不在其中则创建字典,键值为idnum的str形式,然后根据字典中两个网址(爬取的网址和目前迭代的网址)来生成边的关系,完成后将边加入边集,最后再生成点集,其中标签的类型通过出度(利用计数器记录爬取的网址数)来计算。最后当main函数中调用出错或者idx的值到60时,跳出循环,然后将边集的点集的参数传入Graph中,生成我们需要的图。
另外:事实上集美大学校内的各网站有上百个甚至可能更多(包含诚毅学院),但是因为电脑的能力有限,要爬取如此多的网站实在困难,而且生成的图也很难展现,所以我们只展示最前面的60个节点。
该算法是否一定能得到包含所有网站的拓扑图?
不能,该算法是根据正则表达式进行爬取的,我设置的Regex只针对以jmu.edu.cn为后缀的域名,所以网站中的一些外站链接或者超文本并没有爬取下来。
时间复杂度是多少?
正则表达式时间复杂度不明,但是迭代url列表的时间复杂度为o(n),n是设定的idx的最大值,每一次迭代url列表还要匹配正则表达式并迭代。所以时间复杂度大概是o(n*m),m是返回的Regex列表
在这样的一个拓扑图中,必然有一些节点和其他节点不一样, 这些节点的特征是怎样的?你觉得哪些节点比较重要(从分析问题的角度来看)。
我根据网站的出度来设定大小,所以不一样的节点主要就是出度多的节点,也就是连接的集美大学相关网站多的网站。
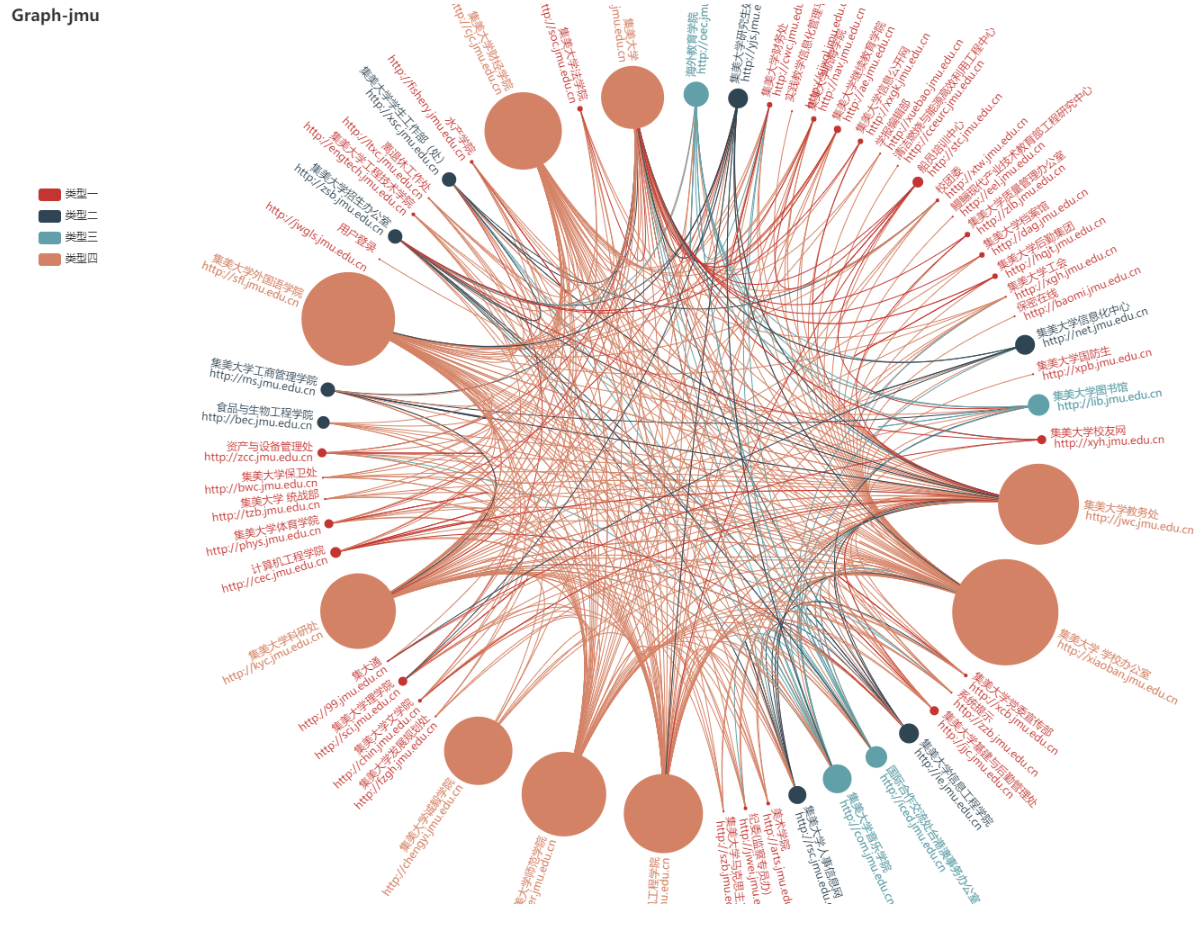
进阶:校园网络地图绘制实现即代码运行结果
因为生成的是本地的html文件,所以我们以截图的形式展示,该图总共有60个节点,根据出度的多少,节点的大小也不一样,所以我们可以很明显的看出比如集美大学教务处,集美大学等网站连接了许多的校内网站,从图的概念来说,集美大学教务处,集美大学这两个结点的出度明显比较大。
而依照这些节点的大小不同,我设置了四种类型的节点,我们可以通过左边的按钮切换显示不同类型节点之间的关系。同时,这是一个有向图,即每一条边,都是有向的,它表示一个节点到另一个节点的关系,即每一个网站到另一个网站的连接关系。边数越少的节点,则表明它在整个网络结构里越独立,我们可能需要通过域名才能之间访问这个网站,或者说从这个网站出发可以跳转到的校内网站很少。
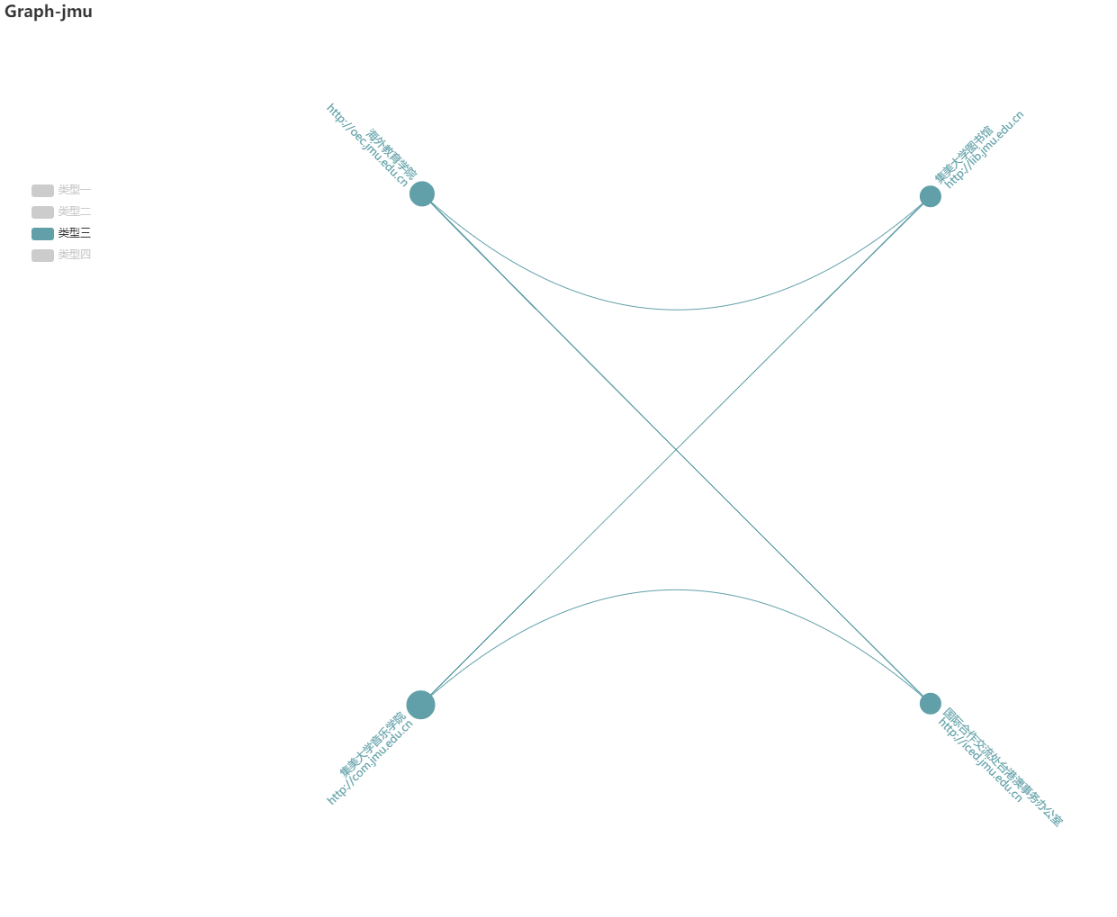
以下只显示类型一的节点,由于爬取的页面有些网址会重复,所以有的边是节点的自我连接,从这个图我们可以看出,除了类型一的节点,即出度最小的这些节点,它们互相之间几乎是没有联系的,也就是说我们很难根据以下的某个网站跳转到其他的网站中。

类型二的节点

类型三的节点
类型四的节点从大小看非常明显,并且边数也明显密集,我们可以看出类型四的这些网站之间都是可以相互访问的,显然这些网站是集美大学校内比较常用的网站。

拓展
根据这次实验,我们可以发现爬虫的作用以及图的意义,校园网站地图很好的表现出了集美大学校内各个网站之间的关系,我们可以根据这个图,尝试利用学习过的最小生成树等算法,寻找访问到某个网站的跳转方式的最短路径(当然直接通过网址访问是最快的)。
或者我们可以在程序中加一个字典,记录下每个网站的出度,然后将字典转化为列表进行排序,以递减的顺序生成集美大学内部网站间的排列,甚至可以利用Python的库直接生成Excel,让大家更好的浏览。
同时我们发现,校园内部的网站有非常多,爬取过后我才了解到一些网站,或许学校可以在官网下建立一个索引简单介绍一下这些网站以及提供链接跳转。
结论
爬虫算法的实现需要对html、js、Python等有一定了解,还要学习正则表达式以及一些相关的库的文档,在对校园网站地图的绘制中。我们需要利用图的基本概念,也就是出度来设置点的大小,并且利用BFS的思想来对网页进行爬取。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号