1.18总结——RDD算子
第四天。
RDD算子
算子:分布式集合对象上的API称之为算子。
方法\函数:本地对象的API,叫做方法\函数
算子:分布式对象的API,叫做算子。
算子分类
- Transformation:转换算子
- 定义:RDD的算子,返回值仍然师一个RDD的。
- 特性:lazy懒加载,如果没有action算子,Transformation算子是不工作的
- Action:动作(行动)算子
- 返回值不是RDD的算子。
常用转换算子
转换算子——map
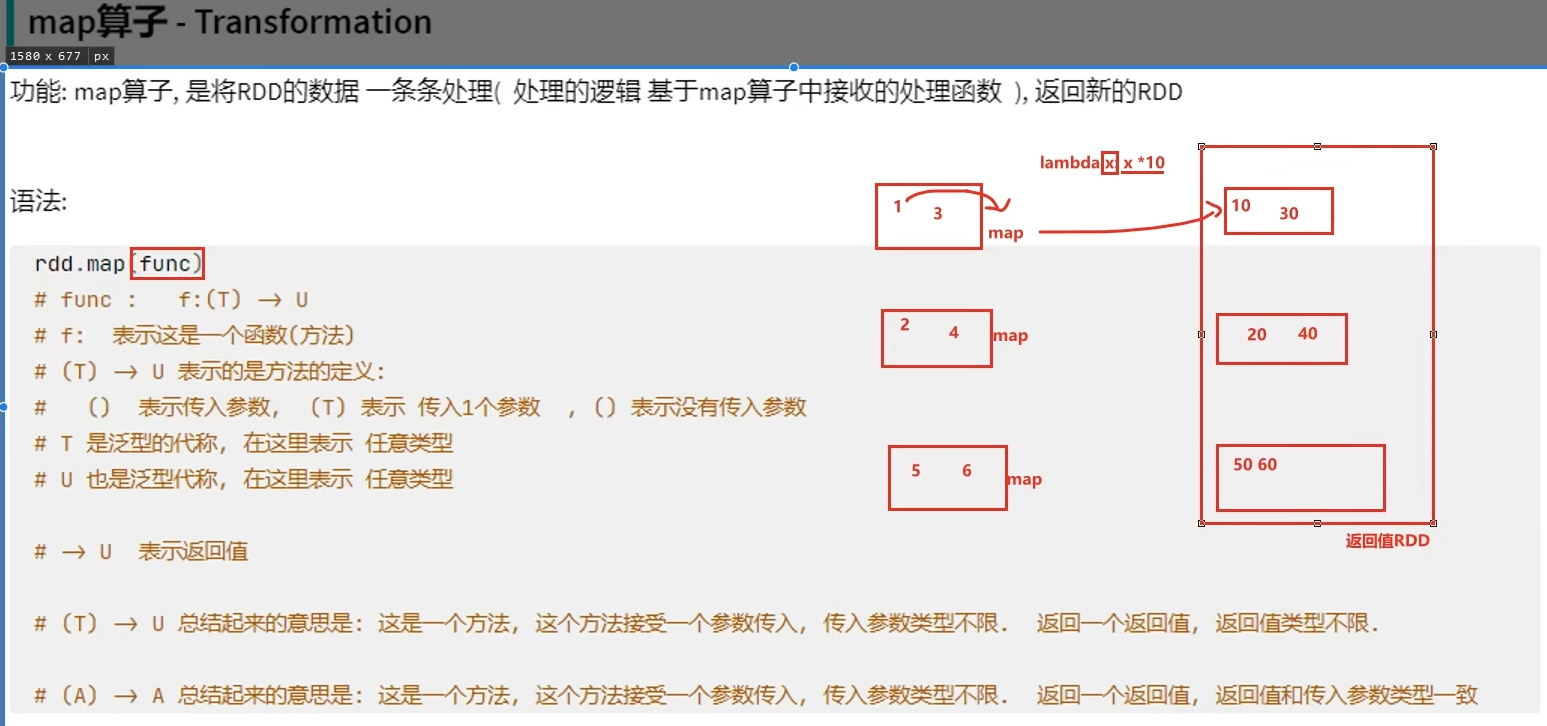
例子:

# coding:utf8 from pyspark import SparkConf, SparkContext if __name__ == '__main__': conf = SparkConf().setAppName("text").setMaster("local[*]") sc = SparkContext(conf=conf) rdd = sc.parallelize([1, 2, 3, 4, 5, 6], 3) def add(data): return data * 10 print(rdd.map(add).collect()) # 或 # print(rdd.map(lambda data: data * 10).collect())
转换算子——flatMap
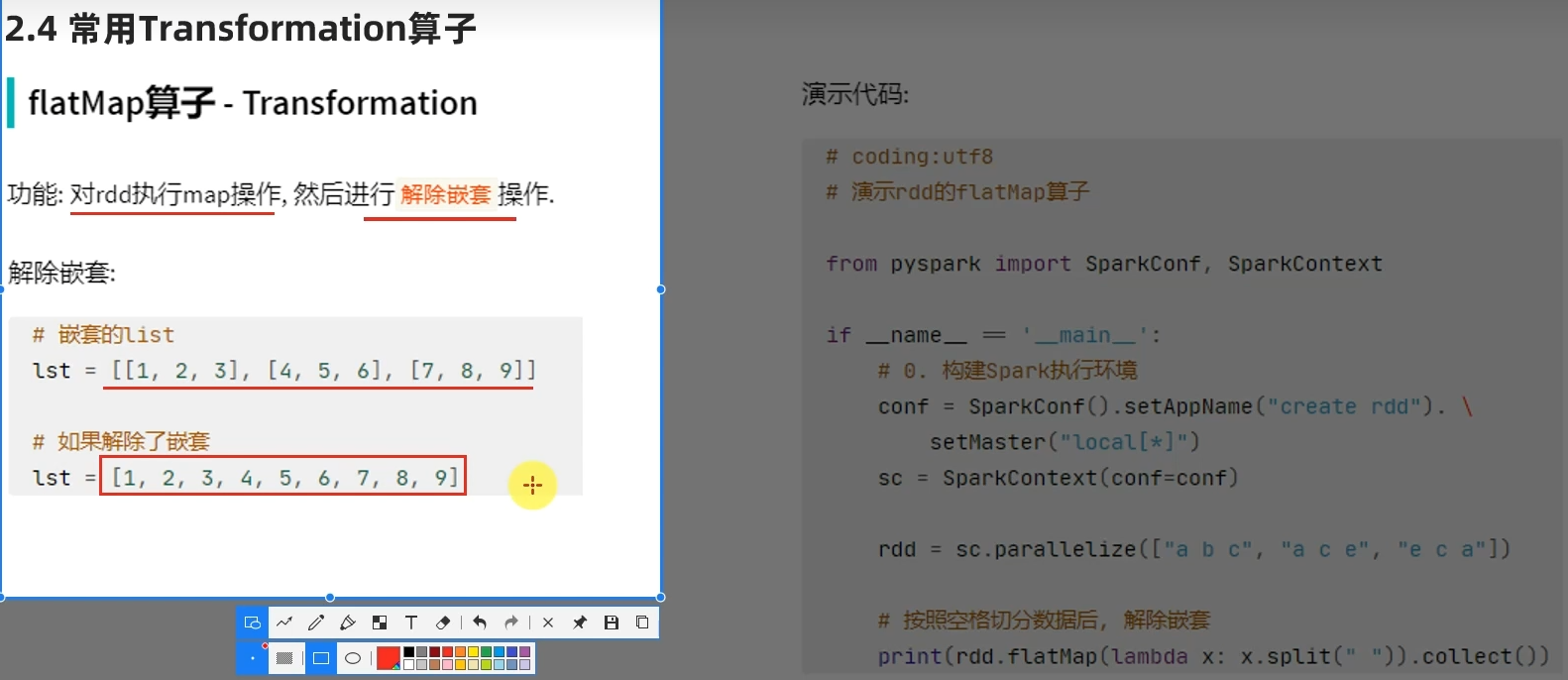
例子:
# coding:utf8 from pyspark import SparkConf, SparkContext if __name__ == '__main__': conf = SparkConf().setAppName("test").setMaster("local[*]") sc = SparkContext(conf=conf) rdd = sc.parallelize(["operators hadoop hadoop", "spark spark ment", "pychart heard"]) rdd2 = rdd.flatMap(lambda line: line.split(" ")) print(rdd2.collect())
转换算子——reduceByKey

例子:
# coding:utf8 from pyspark import SparkConf, SparkContext if __name__ == '__main__': conf = SparkConf().setAppName("test").setMaster("local[*]") sc = SparkContext(conf=conf) rdd = sc.parallelize([('a', 1), ('a', 1), ('b', 1), ('b', 1), ('b', 1)]) print(rdd.reduceByKey(lambda a, b: a + b).collect())
转换算子——mapValues
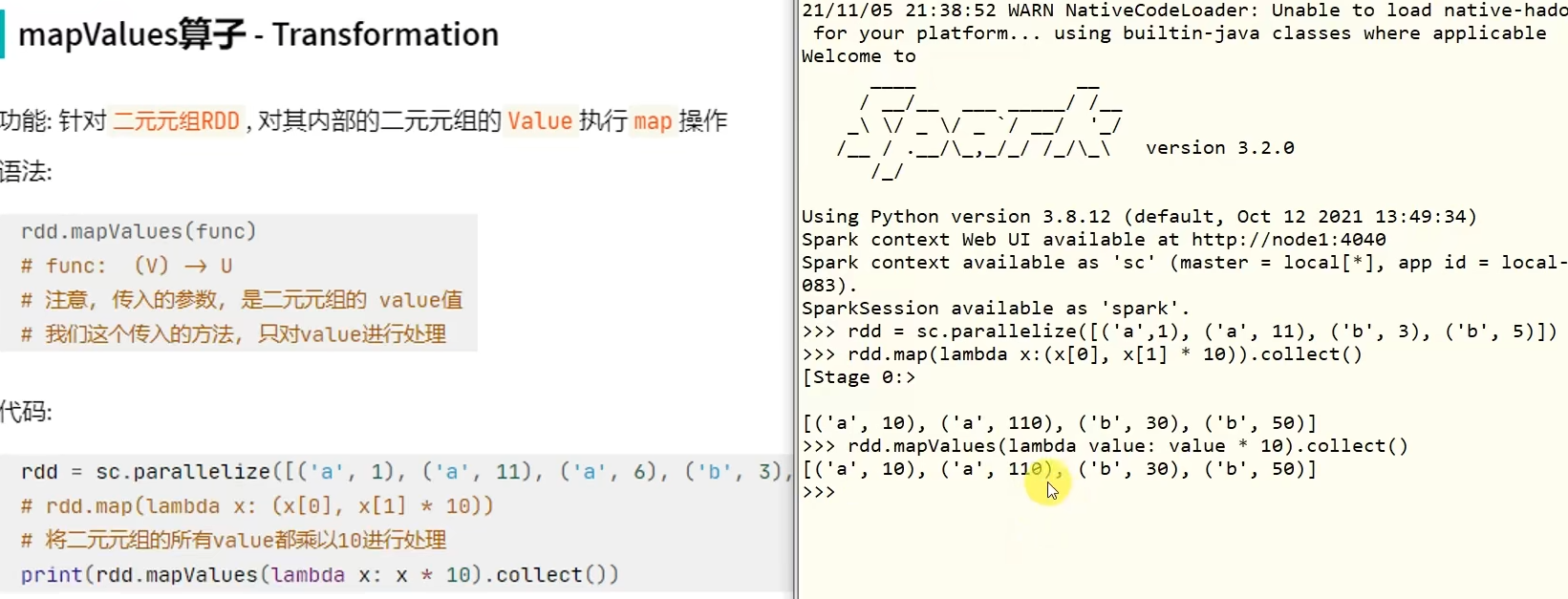
WordCount案例回顾
# coding:utf8 from pyspark import SparkConf, SparkContext if __name__ == '__main__': conf = SparkConf().setAppName("test").setMaster("local[*]") sc = SparkContext(conf=conf) # 1. 读取文件获取数据 构建RDD file_rdd = sc.textFile("../data/input/words.txt") # 2. 通过flatMap API 取出所有的单词 word_rdd = file_rdd.flatMap(lambda x: x.split(" ")) # 3. 将单词转换成元组, key是单词, value是1 word_with_one_rdd = word_rdd.map(lambda word: (word, 1)) # 4. 用reduceByKey 对单词进行分组并进行value的聚合 result_rdd = word_with_one_rdd.reduceByKey(lambda a, b: a + b) # 5. 通过collect算子, 将rdd的数据收集到Driver中, 打印输出 print(result_rdd.collect())
转换算子——groupBy
# coding:utf8 from pyspark import SparkConf, SparkContext if __name__ == '__main__': conf = SparkConf().setAppName("test").setMaster("local[*]") sc = SparkContext(conf=conf) rdd = sc.parallelize([('a', 1), ('a', 1), ('b', 1), ('b', 2), ('b', 3)]) # 通过groupBy对数据进行分组 # groupBy传入的函数的 意思是: 通过这个函数, 确定按照谁来分组(返回谁即可) # 分组规则 和SQL是一致的, 也就是相同的在一个组(Hash分组) result = rdd.groupBy(lambda t: t[0]) print(result.map(lambda t:(t[0], list(t[1]))).collect())
转换算子——filter
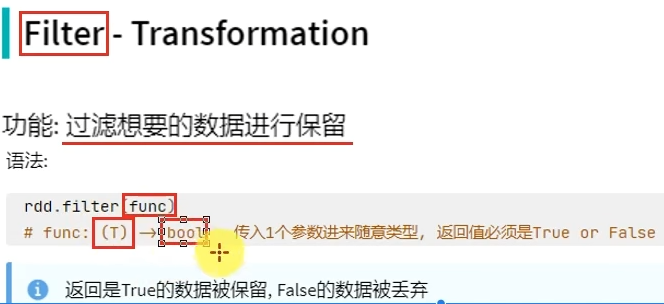
# coding:utf8 from pyspark import SparkConf, SparkContext if __name__ == '__main__': conf = SparkConf().setAppName("test").setMaster("local[*]") sc = SparkContext(conf=conf) rdd = sc.parallelize([1, 2, 3, 4, 5, 6]) # 通过Filter算子, 过滤奇数 result = rdd.filter(lambda x: x % 2 == 1) print(result.collect())
转换算子——distinct

# coding:utf8 from pyspark import SparkConf, SparkContext if __name__ == '__main__': conf = SparkConf().setAppName("test").setMaster("local[*]") sc = SparkContext(conf=conf) rdd = sc.parallelize([1, 1, 1, 2, 2, 2, 3, 3, 3]) # distinct 进行RDD数据去重操作 print(rdd.distinct().collect()) rdd2 = sc.parallelize([('a', 1), ('a', 1), ('a', 3)]) print(rdd2.distinct().collect())
转换算子——union
# coding:utf8 from pyspark import SparkConf, SparkContext if __name__ == '__main__': conf = SparkConf().setAppName("test").setMaster("local[*]") sc = SparkContext(conf=conf) rdd1 = sc.parallelize([1, 1, 3, 3]) rdd2 = sc.parallelize(["a", "b", "a"]) rdd3 = rdd1.union(rdd2) print(rdd3.collect()) """ 1. 可以看到 union算子是不会去重的 2. RDD的类型不同也是可以合并的. """
转换算子——join
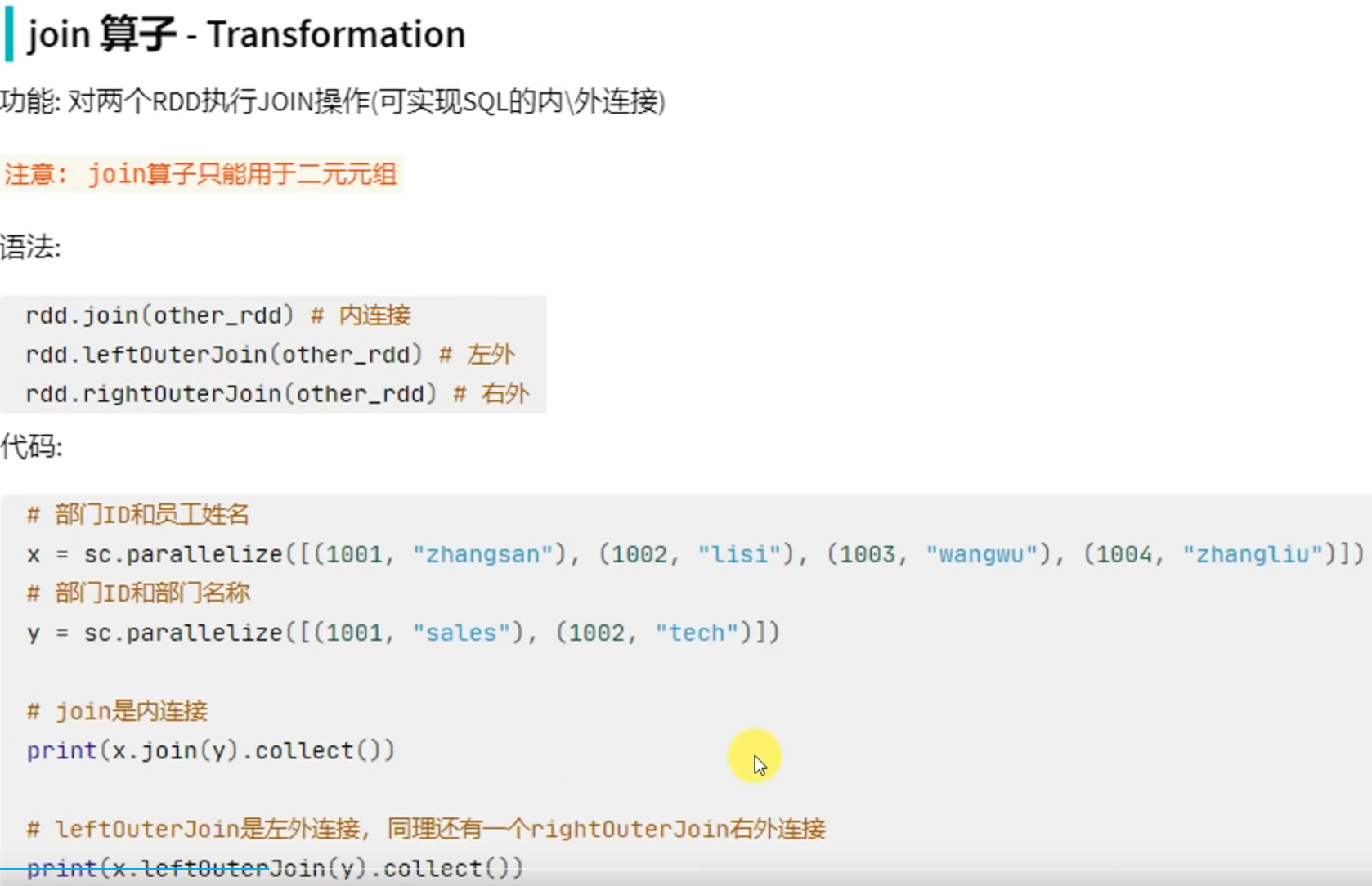
# coding:utf8 from pyspark import SparkConf, SparkContext if __name__ == '__main__': conf = SparkConf().setAppName("test").setMaster("local[*]") sc = SparkContext(conf=conf) rdd1 = sc.parallelize([ (1001, "zhangsan"), (1002, "lisi"), (1003, "wangwu"), (1004, "zhaoliu") ]) rdd2 = sc.parallelize([ (1001, "销售部"), (1002, "科技部")]) # 通过join算子来进行rdd之间的关联 # 对于join算子来说 关联条件 按照二元元组的key来进行关联 print(rdd1.join(rdd2).collect()) # 左外连接, 右外连接 可以更换一下rdd的顺序 或者调用rightOuterJoin即可 print(rdd1.leftOuterJoin(rdd2).collect())
转换算子——intersection
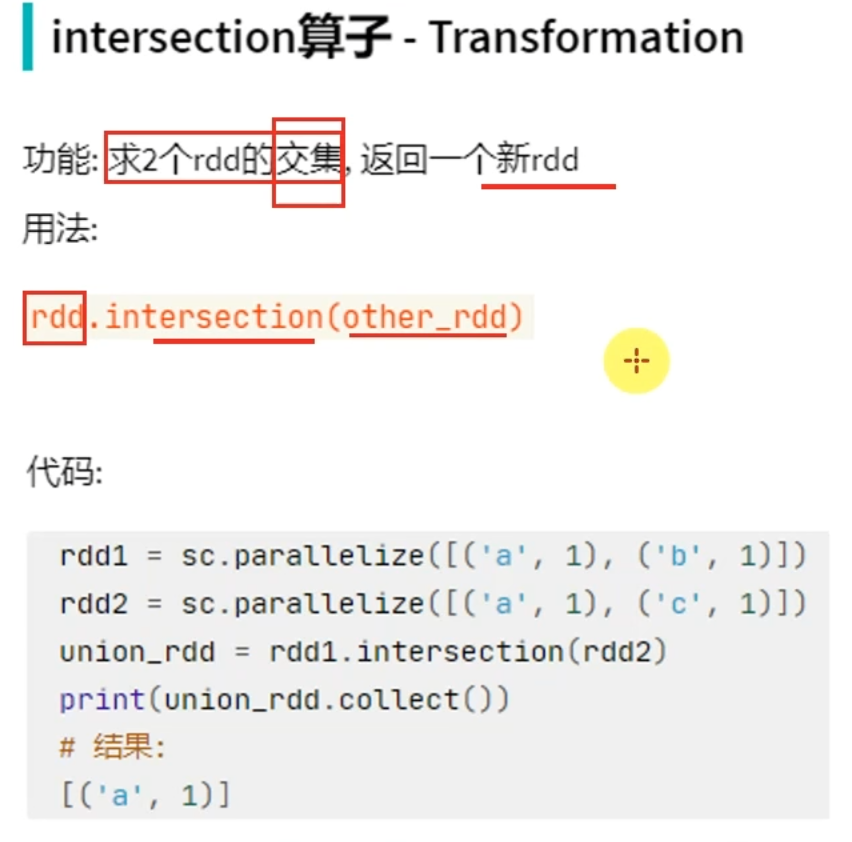
# coding:utf8 from pyspark import SparkConf, SparkContext if __name__ == '__main__': conf = SparkConf().setAppName("test").setMaster("local[*]") sc = SparkContext(conf=conf) rdd1 = sc.parallelize([('a', 1), ('a', 3)]) rdd2 = sc.parallelize([('a', 1), ('b', 3)]) # 通过intersection算子求RDD之间的交集, 将交集取出 返回新RDD rdd3 = rdd1.intersection(rdd2) print(rdd3.collect())
转换算子——glom
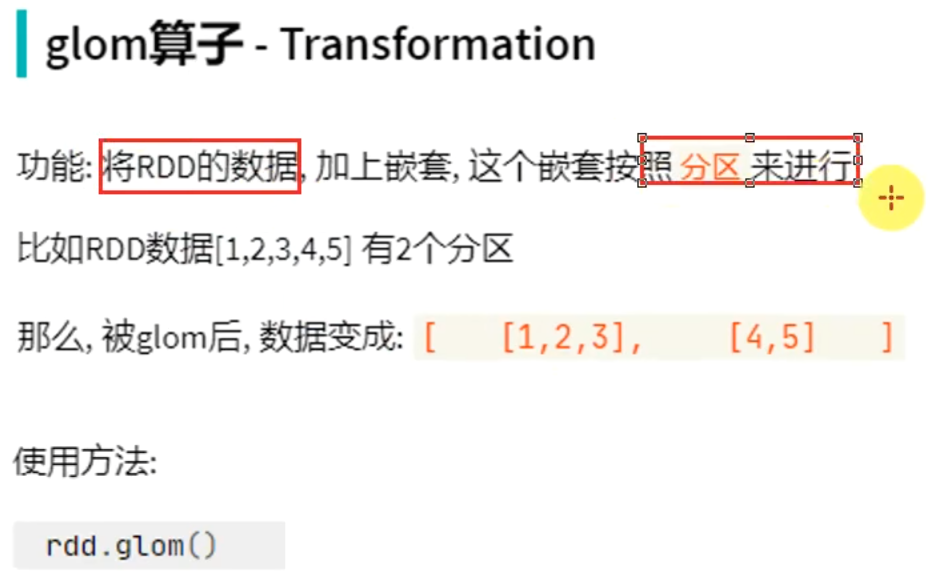
# coding:utf8 from pyspark import SparkConf, SparkContext if __name__ == '__main__': conf = SparkConf().setAppName("test").setMaster("local[*]") sc = SparkContext(conf=conf) rdd = sc.parallelize([1, 2, 3, 4, 5, 6, 7, 8, 9], 2) print(rdd.glom().flatMap(lambda x: x).collect())
转换算子-groupByKey

# coding:utf8 from pyspark import SparkConf, SparkContext if __name__ == '__main__': conf = SparkConf().setAppName("test").setMaster("local[*]") sc = SparkContext(conf=conf) rdd = sc.parallelize([('a', 1), ('a', 1), ('b', 1), ('b', 1), ('b', 1)]) rdd2 = rdd.groupByKey() print(rdd2.map(lambda x: (x[0], list(x[1]))).collect())
groupByKey只保留同组的值,而groupBy还保留key
转换算子——sortBy
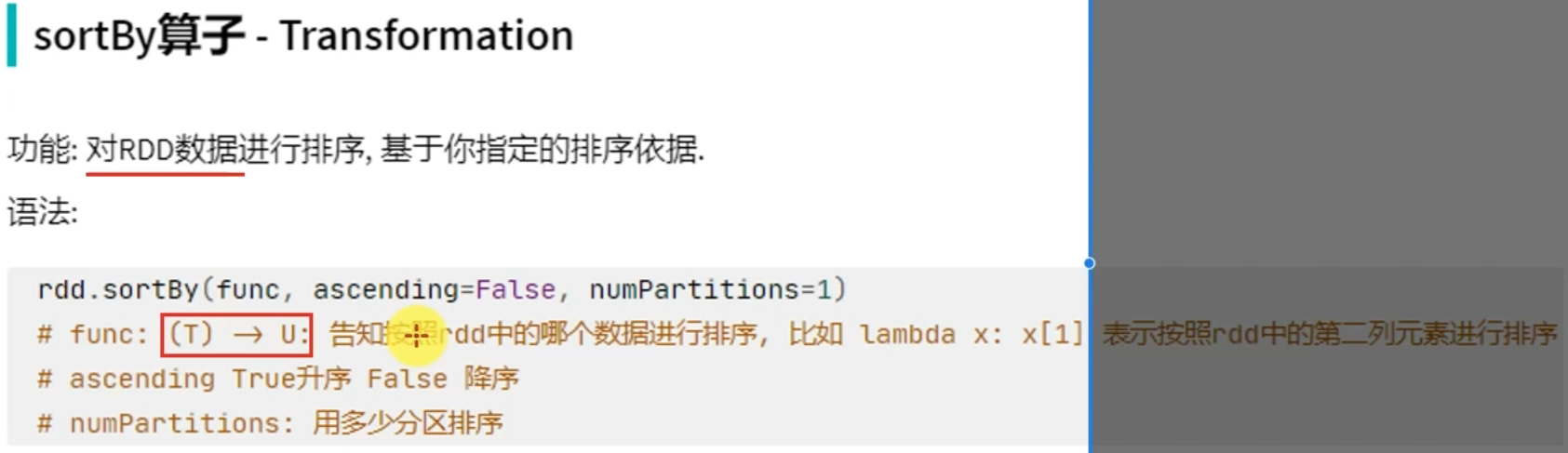
# coding:utf8 from pyspark import SparkConf, SparkContext if __name__ == '__main__': conf = SparkConf().setAppName("test").setMaster("local[*]") sc = SparkContext(conf=conf) rdd = sc.parallelize([('c', 3), ('f', 1), ('b', 11), ('c', 3), ('a', 1), ('c', 5), ('e', 1), ('n', 9), ('a', 1)], 3) # 使用sortBy对rdd执行排序 # 按照value 数字进行排序 # 参数1函数, 表示的是 , 告知Spark 按照数据的哪个列进行排序 # 参数2: True表示升序 False表示降序 # 参数3: 排序的分区数 """注意: 如果要全局有序, 排序分区数请设置为1""" print(rdd.sortBy(lambda x: x[1], ascending=True, numPartitions=1).collect()) # 按照key来进行排序 print(rdd.sortBy(lambda x: x[0], ascending=False, numPartitions=1).collect())
转换算子——sortByKey

# coding:utf8 from pyspark import SparkConf, SparkContext if __name__ == '__main__': conf = SparkConf().setAppName("test").setMaster("local[*]") sc = SparkContext(conf=conf) rdd = sc.parallelize([('a', 1), ('E', 1), ('C', 1), ('D', 1), ('b', 1), ('g', 1), ('f', 1), ('y', 1), ('u', 1), ('i', 1), ('o', 1), ('p', 1), ('m', 1), ('n', 1), ('j', 1), ('k', 1), ('l', 1)], 3) print(rdd.sortByKey(ascending=True, numPartitions=1, keyfunc=lambda key: str(key).lower()).collect())
RDD算子——案例
# coding:utf8 from pyspark import SparkConf, SparkContext import json if __name__ == '__main__': conf = SparkConf().setAppName("test").setMaster("local[*]") sc = SparkContext(conf=conf) # 读取数据文件 file_rdd = sc.textFile("../data/order.text") # 进行rdd数据的split 按照|符号进行, 得到一个个的json数据 jsons_rdd = file_rdd.flatMap(lambda line: line.split("|")) # 通过Python 内置的json库, 完成json字符串到字典对象的转换 dict_rdd = jsons_rdd.map(lambda json_str: json.loads(json_str)) # 过滤数据, 只保留北京的数据 beijing_rdd = dict_rdd.filter(lambda d: d['areaName'] == "北京") # 组合北京 和 商品类型形成新的字符串 category_rdd = beijing_rdd.map(lambda x: x['areaName'] + "_" + x['category']) # 对结果集进行去重操作 result_rdd = category_rdd.distinct() # 输出 print(result_rdd.collect())
对于demo中的测试时,出现报错
Failed to submit application_1708255218009_0009 to YARN : root is not a leaf queue
解决方案:
在hadoop/etc/hadoop中找到yarn-site配置文件
添加
<!-- 选择调度器,默认容量 -->
<property>
<description>The class to use as the resource scheduler.</description>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler</value>
</property>
整体上传yarn案例:
# coding:utf8 from pyspark import SparkConf, SparkContext from defs_19 import city_with_category import json import os os.environ['HADOOP_CONF_DIR'] = "/export/server/hadoop/etc/hadoop" if __name__ == '__main__': # 提交 到yarn集群, master 设置为yarn conf = SparkConf().setAppName("test-yarn-1").setMaster("yarn") # 如果提交到集群运行, 除了主代码以外, 还依赖了其它的代码文件 # 需要设置一个参数, 来告知spark ,还有依赖文件要同步上传到集群中 # 参数叫做: spark.submit.pyFiles # 参数的值可以是 单个.py文件, 也可以是.zip压缩包(有多个依赖文件的时候可以用zip压缩后上传) conf.set("spark.submit.pyFiles", "defs_19.py") sc = SparkContext(conf=conf) # 在集群中运行, 我们需要用HDFS路径了. 不能用本地路径 file_rdd = sc.textFile("hdfs://node1:8020/input/order.text") # 进行rdd数据的split 按照|符号进行, 得到一个个的json数据 jsons_rdd = file_rdd.flatMap(lambda line: line.split("|")) # 通过Python 内置的json库, 完成json字符串到字典对象的转换 dict_rdd = jsons_rdd.map(lambda json_str: json.loads(json_str)) # 过滤数据, 只保留北京的数据 beijing_rdd = dict_rdd.filter(lambda d: d['areaName'] == "北京") # 组合北京 和 商品类型形成新的字符串 category_rdd = beijing_rdd.map(city_with_category) # 对结果集进行去重操作 result_rdd = category_rdd.distinct() # 输出 print(result_rdd.collect())
在服务器上通过spark-submit提交到集群运行
# --py-files 可以帮你指定 你依赖的其他python代码,支持.zip(一堆),也可以单个.py文件 都行 /export/server/spark/bin/spark-submit --master yarn --py-files ./defs.py /home/hadoop/main.py # /export/server/spark/bin/spark-submit --master yarn --py-files 依赖文件路径 提交文件路径
代码
# coding:utf8 from pyspark import SparkConf, SparkContext from defs import city_with_category import json # import os # os.environ['HADOOP_CONF_DIR'] = "/export/server/hadoop/etc/hadoop" if __name__ == '__main__': # 提交 到yarn集群, master 设置为yarn conf = SparkConf().setAppName("test-yarn-form-linux") # 如果提交到集群运行, 除了主代码以外, 还依赖了其它的代码文件 # 需要设置一个参数, 来告知spark ,还有依赖文件要同步上传到集群中 # 参数叫做: spark.submit.pyFiles # 参数的值可以是 单个.py文件, 也可以是.zip压缩包(有多个依赖文件的时候可以用zip压缩后上传) conf.set("spark.submit.pyFiles", "defs_19.py") sc = SparkContext(conf=conf) # 在集群中运行, 我们需要用HDFS路径了. 不能用本地路径 file_rdd = sc.textFile("hdfs://node1:8020/input/order.text") # 进行rdd数据的split 按照|符号进行, 得到一个个的json数据 jsons_rdd = file_rdd.flatMap(lambda line: line.split("|")) # 通过Python 内置的json库, 完成json字符串到字典对象的转换 dict_rdd = jsons_rdd.map(lambda json_str: json.loads(json_str)) # 过滤数据, 只保留北京的数据 beijing_rdd = dict_rdd.filter(lambda d: d['areaName'] == "北京") # 组合北京 和 商品类型形成新的字符串 category_rdd = beijing_rdd.map(city_with_category) # 对结果集进行去重操作 result_rdd = category_rdd.distinct() # 输出 print(result_rdd.collect())
常用Action算子
action算子——countByKey

# coding:utf8 from pyspark import SparkConf, SparkContext if __name__ == '__main__': conf = SparkConf().setAppName("test").setMaster("local[*]") sc = SparkContext(conf=conf) rdd = sc.textFile("../data/input/words.txt") rdd2 = rdd.flatMap(lambda x: x.split(" ")).map(lambda x: (x, 1)) # 通过countByKey来对key进行计数, 这是一个Action算子 result = rdd2.countByKey() print(result) print(type(result))
action算子——collect

action算子——reduce
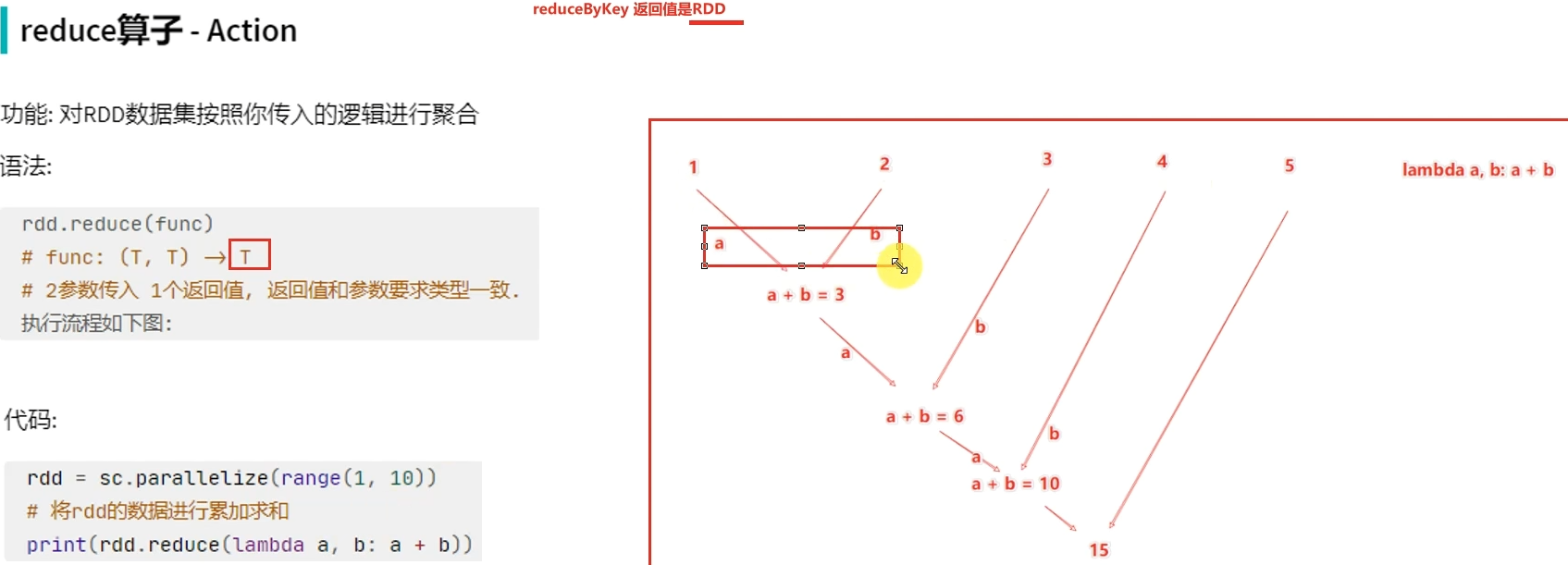
# coding:utf8 from pyspark import SparkConf, SparkContext if __name__ == '__main__': conf = SparkConf().setAppName("test").setMaster("local[*]") sc = SparkContext(conf=conf) rdd = sc.parallelize([1, 2, 3, 4, 5]) print(rdd.reduce(lambda a, b: a + b))
action算子——fold-了解

# coding:utf8 from pyspark import SparkConf, SparkContext if __name__ == '__main__': conf = SparkConf().setAppName("test").setMaster("local[*]") sc = SparkContext(conf=conf) rdd = sc.parallelize([1, 2, 3, 4, 5, 6, 7, 8, 9], 3) print(rdd.fold(10, lambda a, b: a + b))
action算子——first

action算子——take

action算子——top
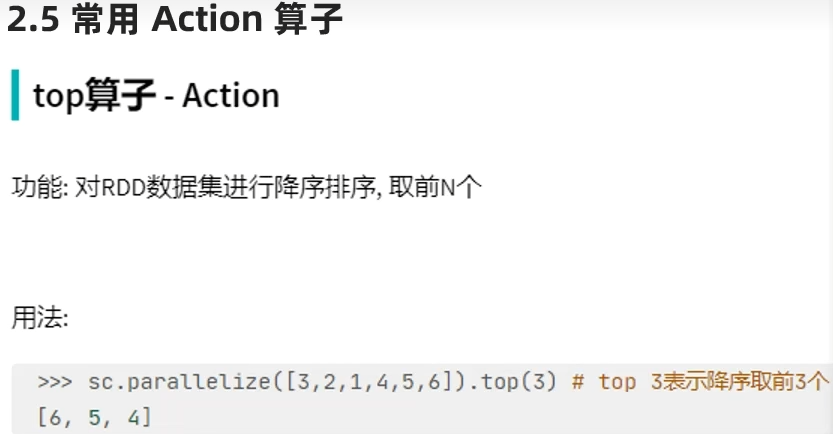
action算子——count

action算子——takeSample
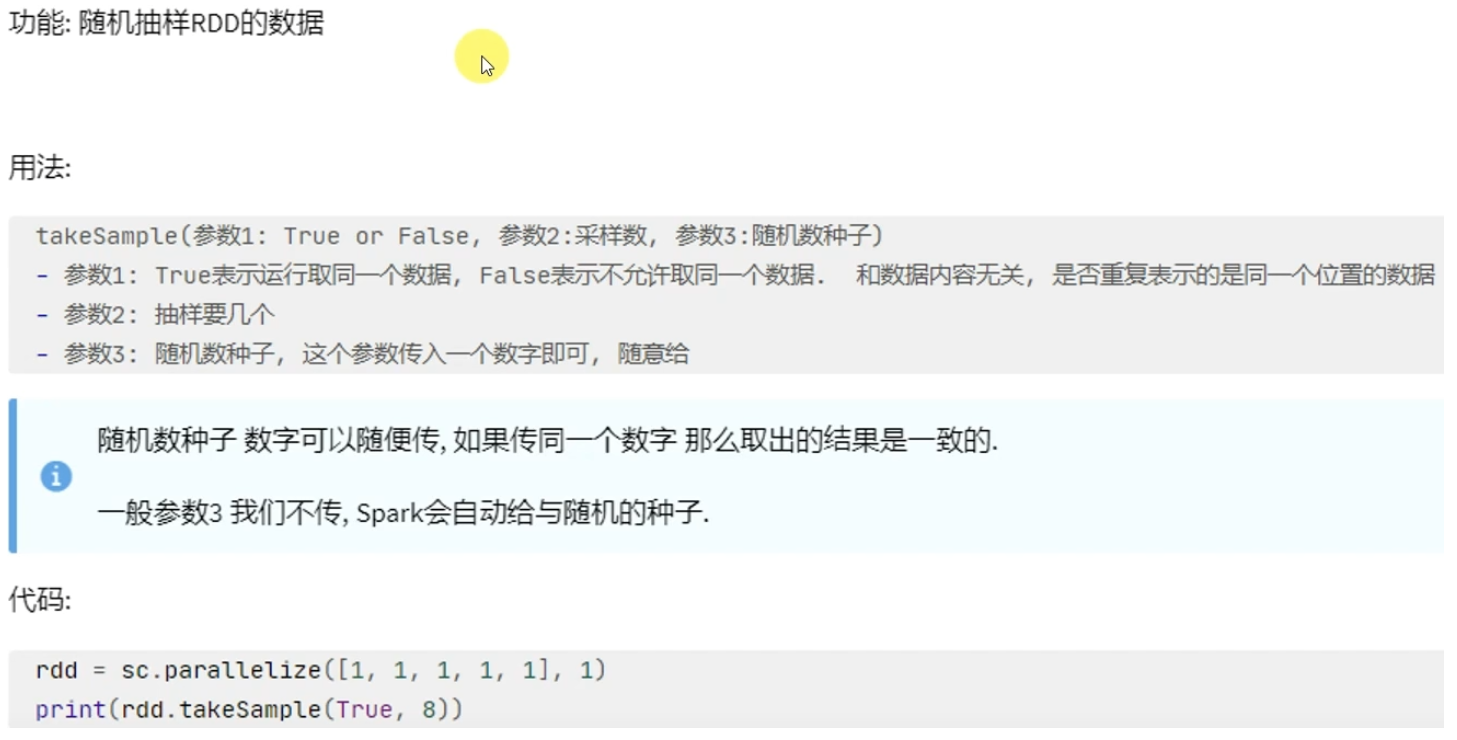
# coding:utf8 from pyspark import SparkConf, SparkContext if __name__ == '__main__': conf = SparkConf().setAppName("test").setMaster("local[*]") sc = SparkContext(conf=conf) rdd = sc.parallelize([1, 3, 5, 3, 1, 3, 2, 6, 7, 8, 6], 1) print(rdd.takeSample(False, 5, 1))
action算子——takeOrdered

# coding:utf8 from pyspark import SparkConf, SparkContext if __name__ == '__main__': conf = SparkConf().setAppName("test").setMaster("local[*]") sc = SparkContext(conf=conf) rdd = sc.parallelize([1, 3, 2, 4, 7, 9, 6], 1) print(rdd.takeOrdered(3)) print(rdd.takeOrdered(3, lambda x: -x))
action算子——foreach
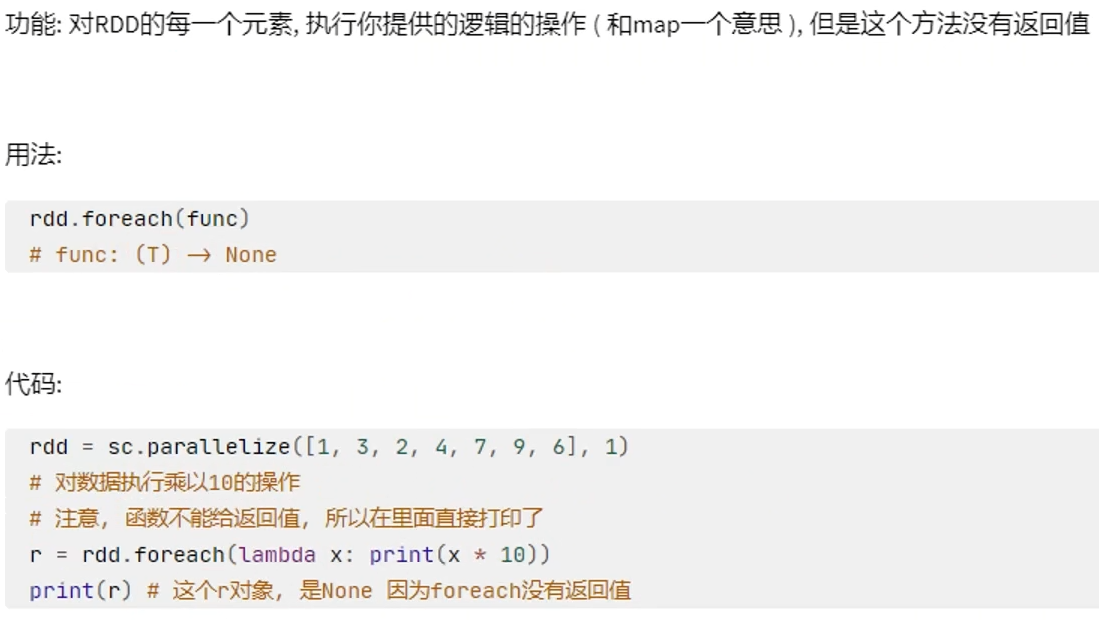
# coding:utf8 from pyspark import SparkConf, SparkContext if __name__ == '__main__': conf = SparkConf().setAppName("test").setMaster("local[*]") sc = SparkContext(conf=conf) rdd = sc.parallelize([1, 3, 2, 4, 7, 9, 6], 1) result = rdd.foreach(lambda x: print(x * 10))
action算子——saveAsTextFile
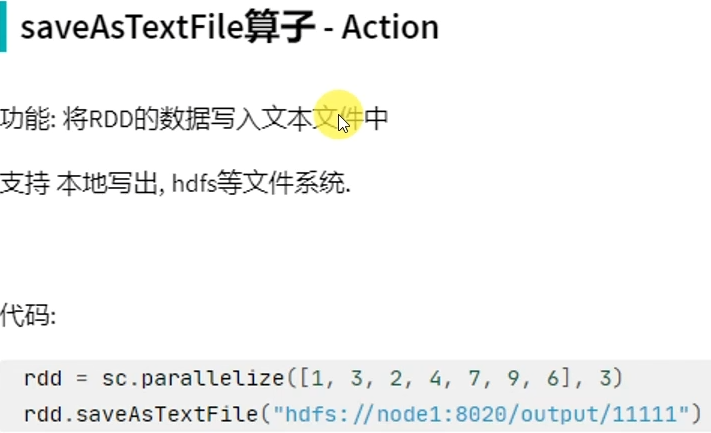

# coding:utf8 from pyspark import SparkConf, SparkContext if __name__ == '__main__': conf = SparkConf().setAppName("test").setMaster("local[*]") sc = SparkContext(conf=conf) rdd = sc.parallelize([1, 3, 2, 4, 7, 9, 6], 3) rdd.saveAsTextFile("hdfs://node1:8020/output/out1")



