2.17总结
寒假第二十天
urllib.openurl:返回对象的方法
# 设置一个url对象 url = "百度一下,你就知道" #发送请求,打开url up = urllib.request.urlopen(url) print(type(up)) #返回对象 >>> <class 'http.client.HTTPResponse'>
发送GET请求:
from urllib import request response = request.urlopen('百度一下,你就知道') print(response.read().decode())
发送post请求:
from urllib import reuqest response = request.urlopen('Method Not Allowed', data=b'word=hello') print(response.read().decode()) #decode()解码
urllib.request.Request
上面的urllib是可对网页发起请求,在我们实际的爬虫应用中,如果频繁的访问一个网页,网站就会识别我们是不是爬虫,这个时候我们就要利用Request来伪装我们的请求头。
urllib.request.Request(url, data=None, headers={}, origin_req_host=None, unverifiable=False, method=None)
推荐使用request()来进行访问的,因为使用request()来进行访问有两点好处:
- 可以直接进行post请求,不需要将 data参数转换成JSON格式
- 直接进行GET请求,不需要自己拼接url参数
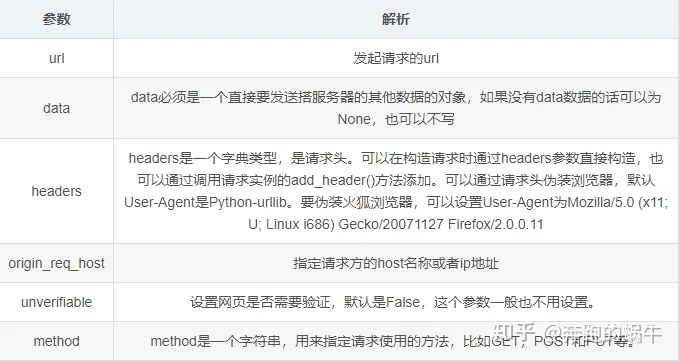
如果只进行基本的爬虫网页抓取,那么urllib足够用了。
