2021-面向对象设计与构造-第二单元总结
第五次作业
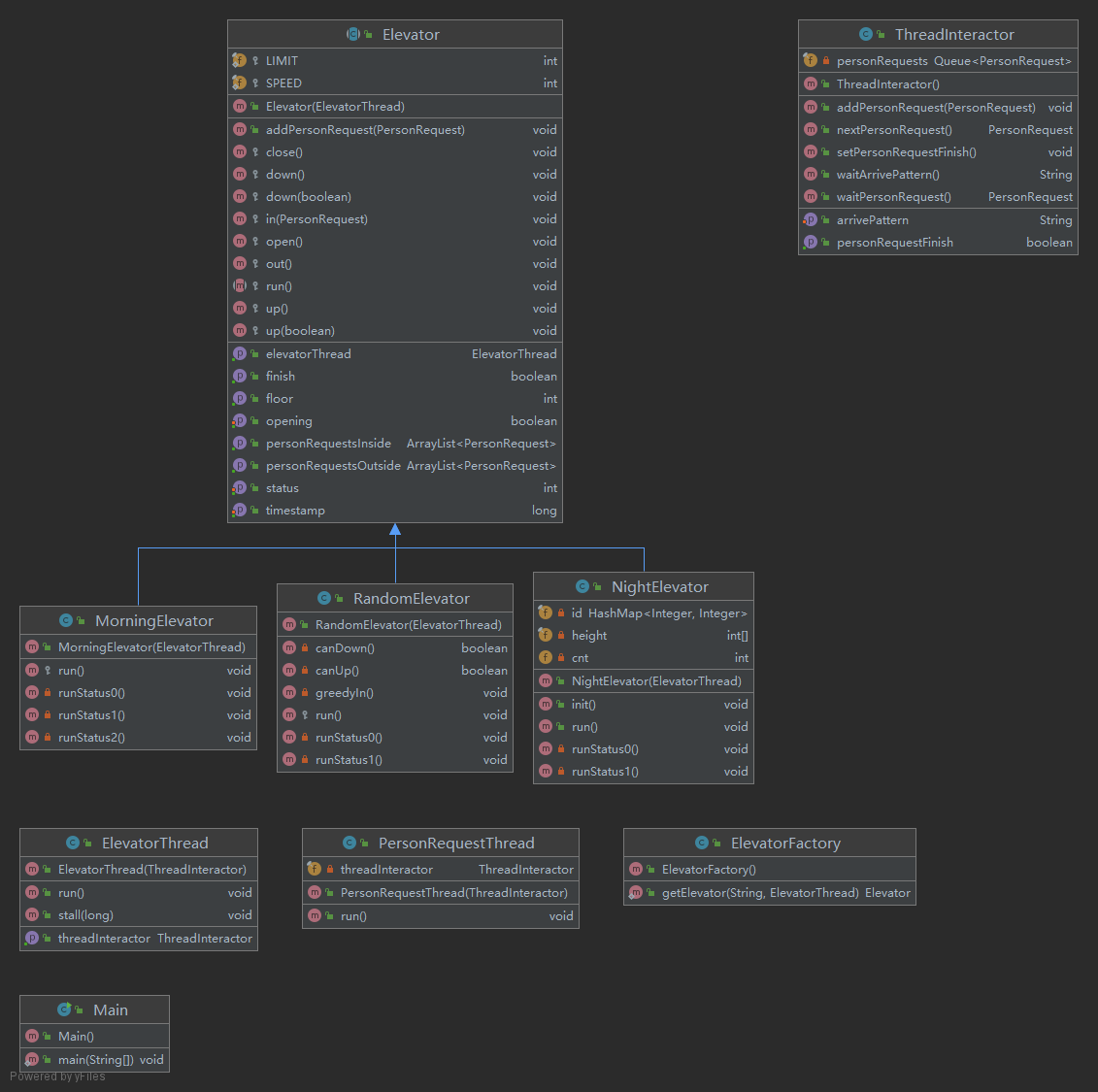
UML 类图
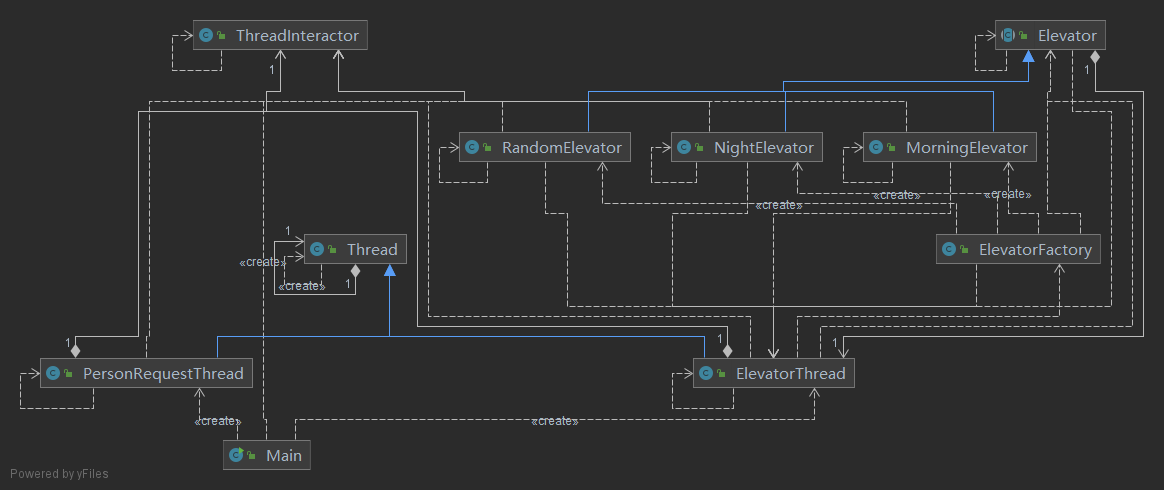
协作图
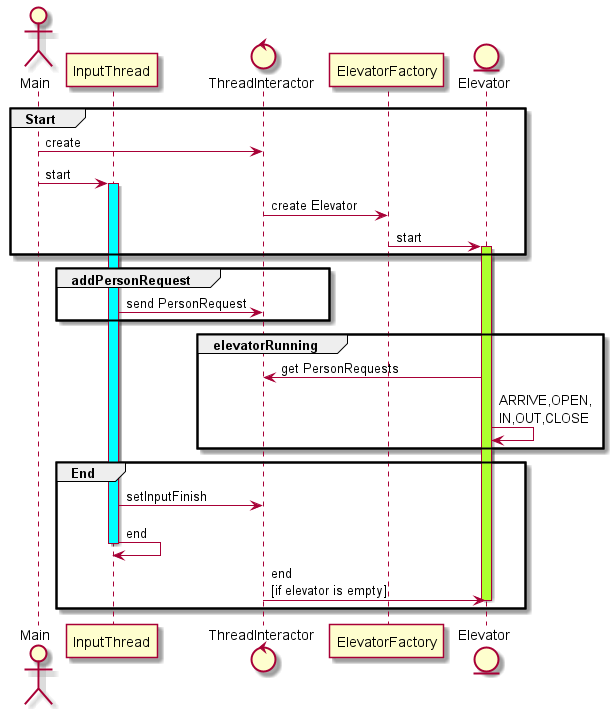
架构与实现
同步块与锁
第一次接触多线程,主要时间花在理解 生产者-消费者模式 和 sychornized 关键字。
参考讨论区的月饼教程,我建立了一个线程安全类 ThreadInteractor,将其中所有的方法都加上 sychornized 关键字,同时保证每个方法的原子性,这样就保证了安全性,同时其它类不需要考虑安全的问题。
本次作业除主线程外存在两个线程,分别为输入线程 InputThread 以及电梯线程 ElevatorThread,两者通过交互器 ThreadInteractor 进行交互。输入线程在接受到乘客请求时使用 addPersonRequest 方法将乘客请求送入到交互器中;电梯线程通过 nextPersonRequests 和 waitPersonRequests 两个方法从交互器中获取乘客请求,两者都会将当前所有的乘客请求返回,并将它们从交互器中移除,区别在于如果交互器中此时没有乘客请求,后者会进行等待直到输入结束或下一个乘客请求到来,前者则直接返回 null。
这里的等待如果直接 while(true) 就轮询了,可以使用 wait 和 notifyAll 的方法避免这个问题,当新乘客请求到来或者输入结束时进行 notifyAll。
为什么需要两个获取乘客的方法呢?因为当电梯还在运作时,只需每次到达楼层时或关门时将所有乘客请求获取进行判断;而当电梯不在运作时,即之前所有乘客请求都处理完时,需要等待下一个关键时刻再进行运作,这里的关键时刻就是新乘客请求到来或是输入结束。
另外,ElevatorThread 是一个线程,其内部创建了一个 Elevator,含有电梯的状态以及运行策略,其实没有必要这样,直接让 Elevator 作为一个线程就可以,这在后面的作业中有所改善。ThreadInteractor 其实可以使用单例模式,而我将它分别传入了两个线程中,实现并不优雅。
调度器
本次作业因为只有一个电梯,所以不需要调度器。但是,从程序的拓展性上进行考虑,一些同学可能选择提前设置一个调度器。我并没有这样做,因为调度器的结构可能会依托于作业的具体内容,在不知道第二次作业内容的情况下,提前设置极大可能会是一个不合适的架构,反而会浪费时间,降低效率。因此,我仅保证了电梯内部的运作是独立的,使得在添加调度器时不需要进行过多改动。
电梯运行算法
电梯运行算法上,我分三种模式进行考虑,并建立了三个不同的电梯类,实现了各自的调度算法:
-
Night 模式,全部读入后按高度排序后进行分段 dp,本以为是真算法,后被 👴👴 hack 掉,即最优分组不一定是按高度连续的,例如下述数据:
[1.0]Night [1.0]1-FROM-2-TO-1 [1.0]2-FROM-2-TO-1 [1.0]3-FROM-3-TO-1 [1.0]4-FROM-3-TO-1 [1.0]5-FROM-3-TO-1 [1.0]6-FROM-3-TO-1 [1.0]7-FROM-3-TO-1 [1.0]8-FROM-4-TO-1 [1.0]9-FROM-4-TO-1最优解是将
1,2,8,9分为一组,4,5,6,7,8分为一组。目前还没想到多项式复杂度的算法,坐等 dalao 们赐教。
-
Morning 模式,直接贪心,每次满 \(6\) 个人或者输入结束就选到达层数最高的数个人拉走。
-
Random 模式,LOOK 算法,能上就上,不能上就下。
测试与 bug 分析
本次作业没有在强测与互测中出现 bug,但因为 LOOK 算法写假了,丧失了 \(0.11\) 的性能分。
LOOK 算法在向上的过程中不应该接下行的乘客,脑子想到但是没写上去,而且一直也没发现,寄。
本地测试中,因为清明节的原因,时间有限,而且就一个电梯可以规避多线程,因此写了个 C++ 对拍机。随机生成数据 + 定时投放,将全部输出和输入数据排序后离线进行 check。这个想法很好,但是因为 计时同步性误差,很容易就判成「预知未来」,评测时必须将输入数据的时间戳进行一下提前的偏移,这样做虽然很不严谨,但是一般也不会存在预知未来的程序,凑活能用。
互测中,一位同学发生了死锁,直接一发入魂。
度量分析
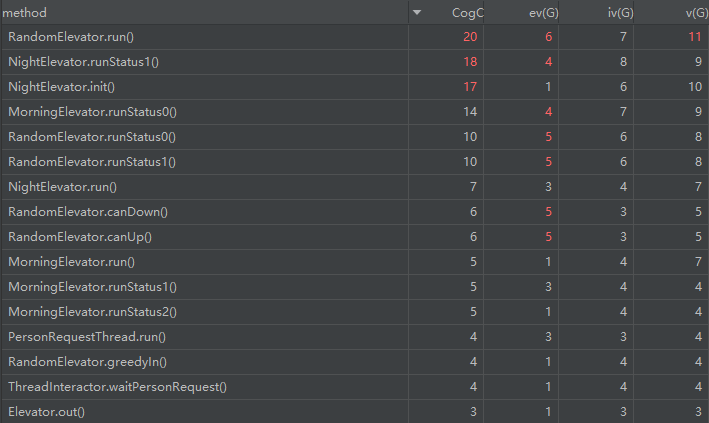
方法复杂度分析
因为方法过多,这里仅截取复杂度过高的部分方法进行分析。
类复杂度分析
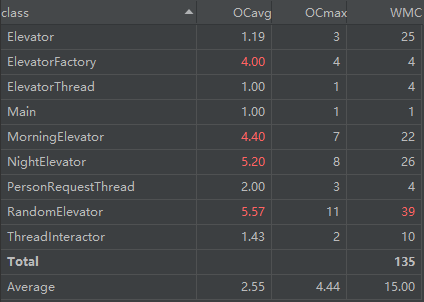
类代码行数分析
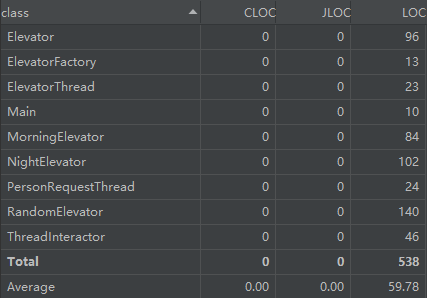
度量分析总结
RandomElevator.run() 这个方法过于复杂是因为刚接触多线程,逻辑写的太复杂且无意义,后面有所改善。
NightElevator.init() 则是上述提到的假 dp,故意牺牲拓展性换性能分,完全没有必要硬把 dp 拆成一个个小部分,毕竟这部分不会存在于下一次作业。
至于 ElevatorFactory,这是一个工厂类,里面就是根据模式串返回对应的电梯,用的是 switch,有三个分支,按定义来说确实应该标红,阿哲......
剩下的标红部分则是电梯运行过程中的必要逻辑,当时写的时候感觉很简洁,现在回顾感觉还是有那么一点冗余,可能再细分成几个方法会有利于维护与拓展。
代码行数方面,没有特别长的类,还可以接受。(互测中经常有人四五百行一个类,我直接害怕)
第六次作业
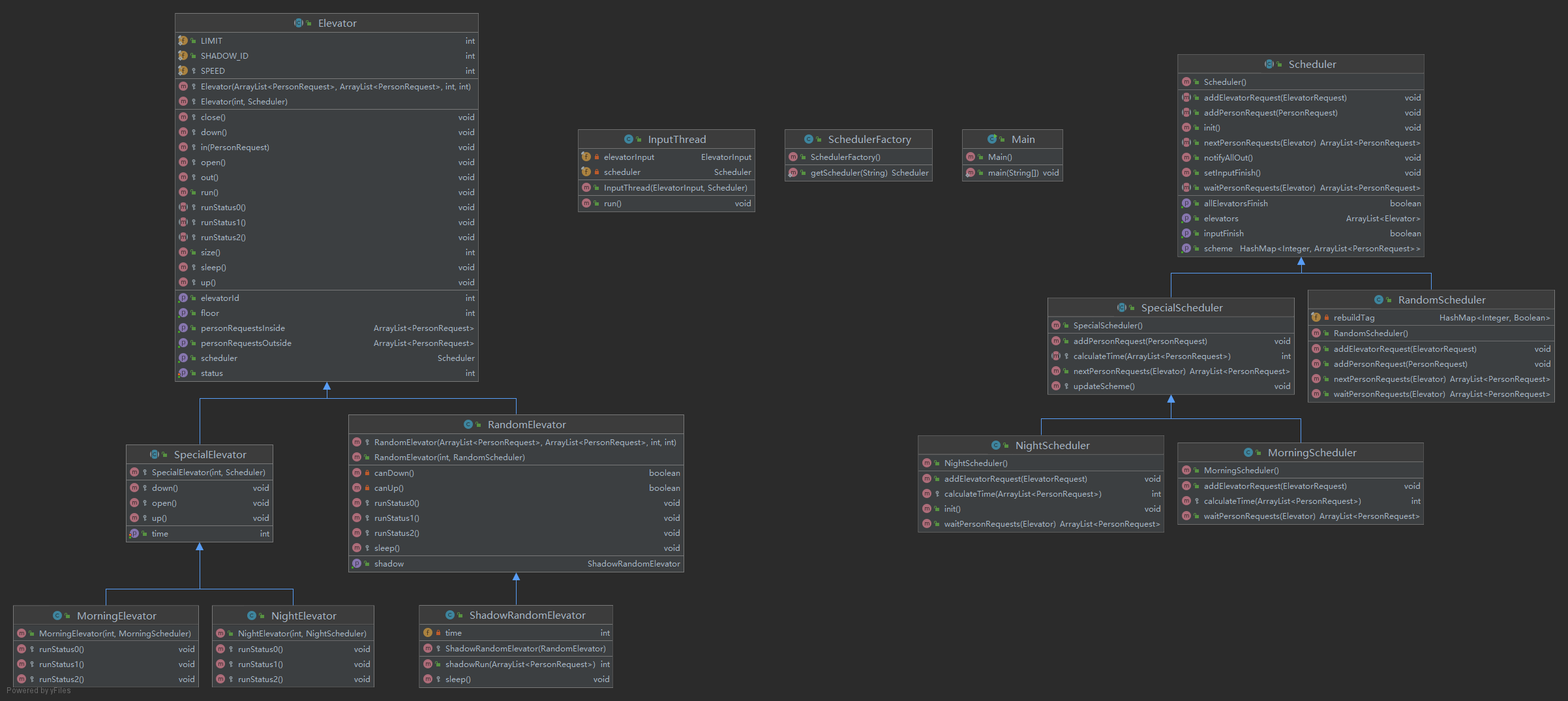
UML 类图
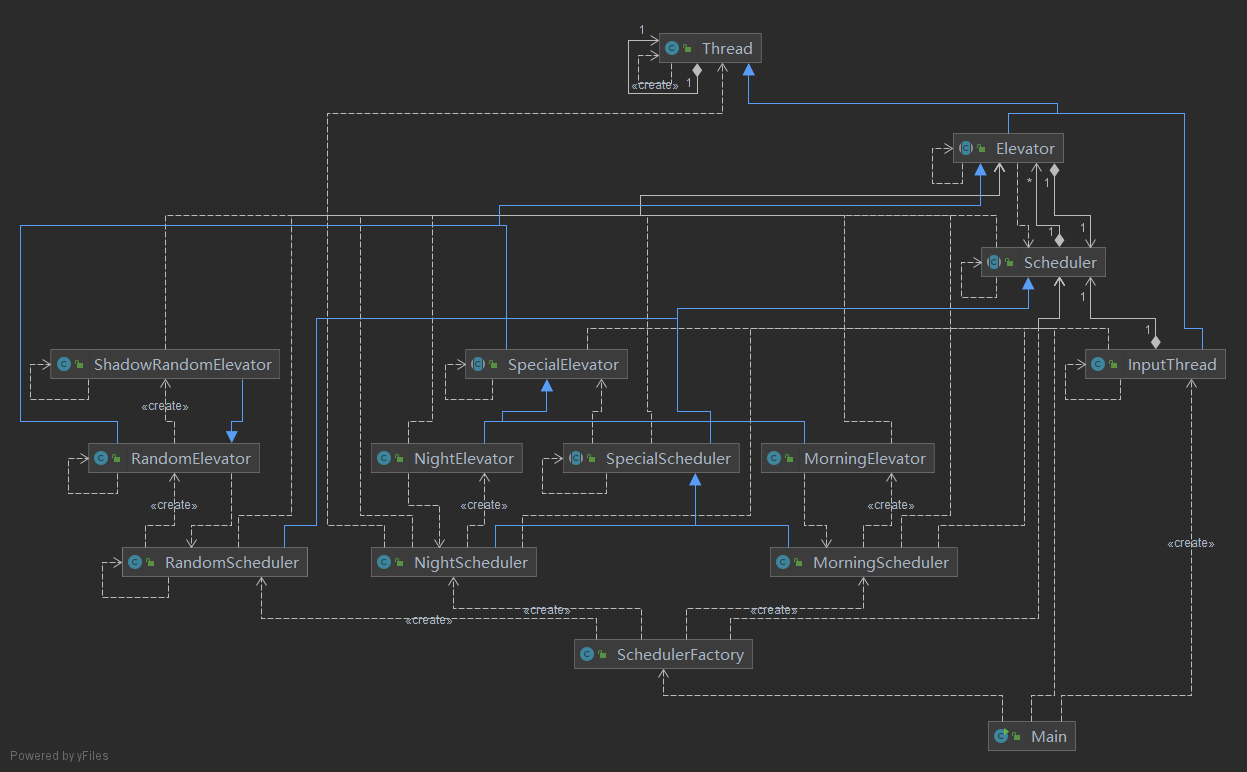
协作图
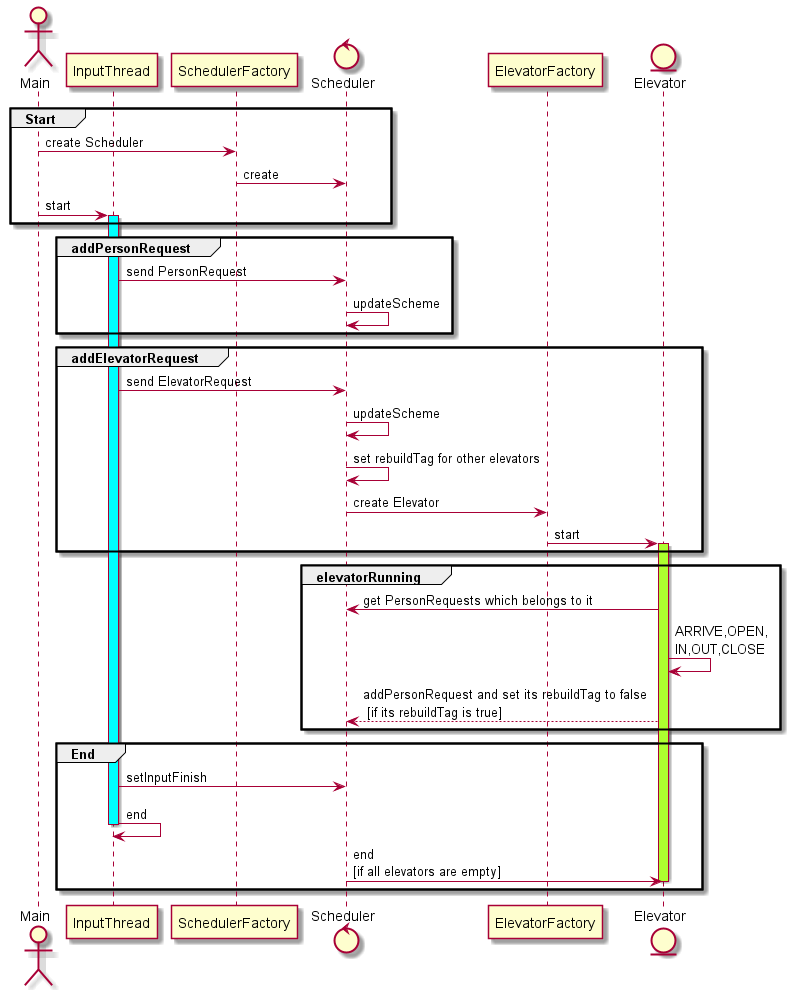
架构与实现
同步块与锁
本次作业直接将第五次作业中的交互器 ThreadInteractor 改为调度器 Scheduler,该类还是一个线程安全类,所有方法全部上 sychornized,且具有原子性。
输入线程 InputThread 还是老样子,只不过这回可以使用调度器中的 addElevatorRequest 来加电梯了。至于 nextPersonRequests 和 waitPersonRequests,它们和第五次作业实现的功能相同,但具体细节取决于模式,这会在下面提到。
吸取上次的教训,本次让 Elevator 直接成为一个线程,取代第五次作业中的 ElevatorThread。
除此之外,唯一和线程安全相关的地方,就是 RandomElevator.getShadow() 了,这是为了获取一个 RandomElevator 的「影子电梯」,以计算其用时,为了保证信息拷贝的原子性,对该方法进行上 sychornized。
调度器
调度器内含一个类型为 HashMap<Integer, ArrayList<PersonRequest>> 的分配方案 scheme,每个电梯在使用 nextPersonRequests 和 waitPersonRequests 时,只会获得分配给它的乘客请求。
根据三种模式,又细分为三种调度器:
-
Night 模式下,基于电梯算法(后续会讲),可以快速算出每个电梯送完人回到 \(1\) 层还需要多少时间,因此每次收到新乘客请求或是新电梯请求时,会将所有
scheme中所有还没有被电梯接受的乘客请求进行重新分配,按高度排序后贪心地分配给分配后所需时间最少的电梯。 -
Morning 模式下,和 Night 模式基本相同,只不过时间算法略微不同,且每次等满 \(6\) 个人或者输入结束
waitPersonRequests才会返回乘客请求。基于上述两种调度模式的相似性,使用一个
SpecialScheduler作为它们的父类,提高代码的复用率。 -
Random 模式下,当新乘客请求到来时,将乘客请求分给「接收该乘客后运送完所有乘客所需时间最少」的电梯。实现方法即创造一个
ShadowRandomElevator,就是上述说的「影子电梯」,它将原电梯的信息全部克隆,新增一个记录时间的变量time,并将sleep全部改为令time增加等量的时间,同时在运作时删去了输出的部分,例如ARRIVE,IN等。这样就可以快速得到一个电梯的运行时间,而不必再去一步步真实模拟。而当新电梯请求到来时,为了防止所有乘客请求都被分出去了,我给每个电梯设置了一个标志位
rebuildTag,新电梯到来时会将其它所有电梯的该标志位置true,从而其它电梯在下一次调用nextPersonRequests时会将所有还没进电梯的乘客请求回退到调度器进行重新分配,并将标志位置false。相比 Night 和 Morning,没有选择每次新乘客请求到来后全部进行重分配,一方面是因为这样做可能导致耗费大量 CPU 时间,另一方面是如果进行重排,那么要么不能将全部乘客请求分配给每个电梯,要么需要频繁将已分配的电梯送回调度器,不管是那一种都会降低 LOOK 算法的效率,因此我没有选择这么做。
电梯运行算法
电梯运行算法上,类似于第五次作业,分三种模式进行考虑,并建立了三个不同的电梯类,实现了各自的调度算法:
- Night 模式,既然 dp 假了,和贪心差的也不多,干脆直接乱搞,每次选出楼层最高的数个人拉走,可以发现这样是可以算出具体时间的。
- Morning 模式,和第五次作业一样,每次满 \(6\) 个人或者输入结束就选到达层数最高的数个人拉走,也可以发现这样是可以算出具体时间的。
- Random 模式,和第五次作业一样,LOOK 算法,能上就上,不能上就下,这回总算写真了。
测试与 bug 分析
本次作业没有在强测与互测中出现 bug,但是 Night 模式的处理出现了严重失误,因此性能分惨痛地损失了 \(1.5\) 分。
一方面,Night 模式并不保证电梯请求也会同时到达,因此不能等所有数据都读入再进行处理。我的处理方法是让调度器线程
sleep一个微小的时间,以便所有数据都读入,但是我图方便写主线程里面了,而此时输入线程并没有启动,因此相当于白sleep了,这导致一开始每个电梯可能就接收了一个乘客,白白损失了很多时间。另一方面,仔细思考 Night 模式的调度算法,三个电梯均为空时,高度最高的三个乘客请求分别分给了三个不同的电梯,这显然是非常劣的。
本地测试中,写了一个 Java 评测机,支持数据生成 + 实时评测,最后会详细叙述。
互测中,一位同学出现死锁,一发入魂。另有两位同学的程序也存在问题,但是我没拍出来,最终它们被其他人 hack 的数据也并非边界数据,因此对应 bug 应该是属于个例问题,除非去阅读代码,否则能不能拍出来纯看脸。
度量分析
方法复杂度分析
因为方法过多,这里仅截取复杂度过高的部分方法进行分析。
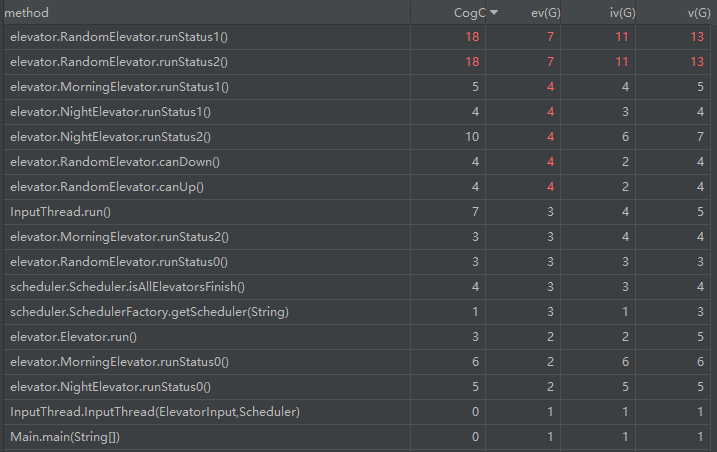
类复杂度分析
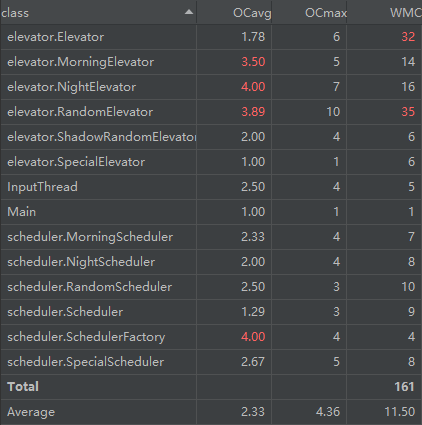
类代码行数分析
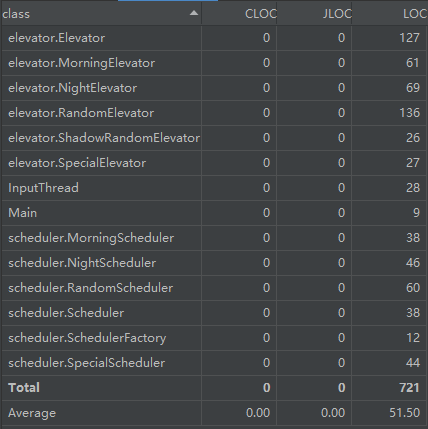
度量分析总结
复杂度方面,相比第五次作业好很多,红色的地方还是因为电梯运行逻辑没有进行拆分。
代码行数方面,仅增加了 \(200\) 行,且没有出现行数过多的类。
第七次作业
UML 类图
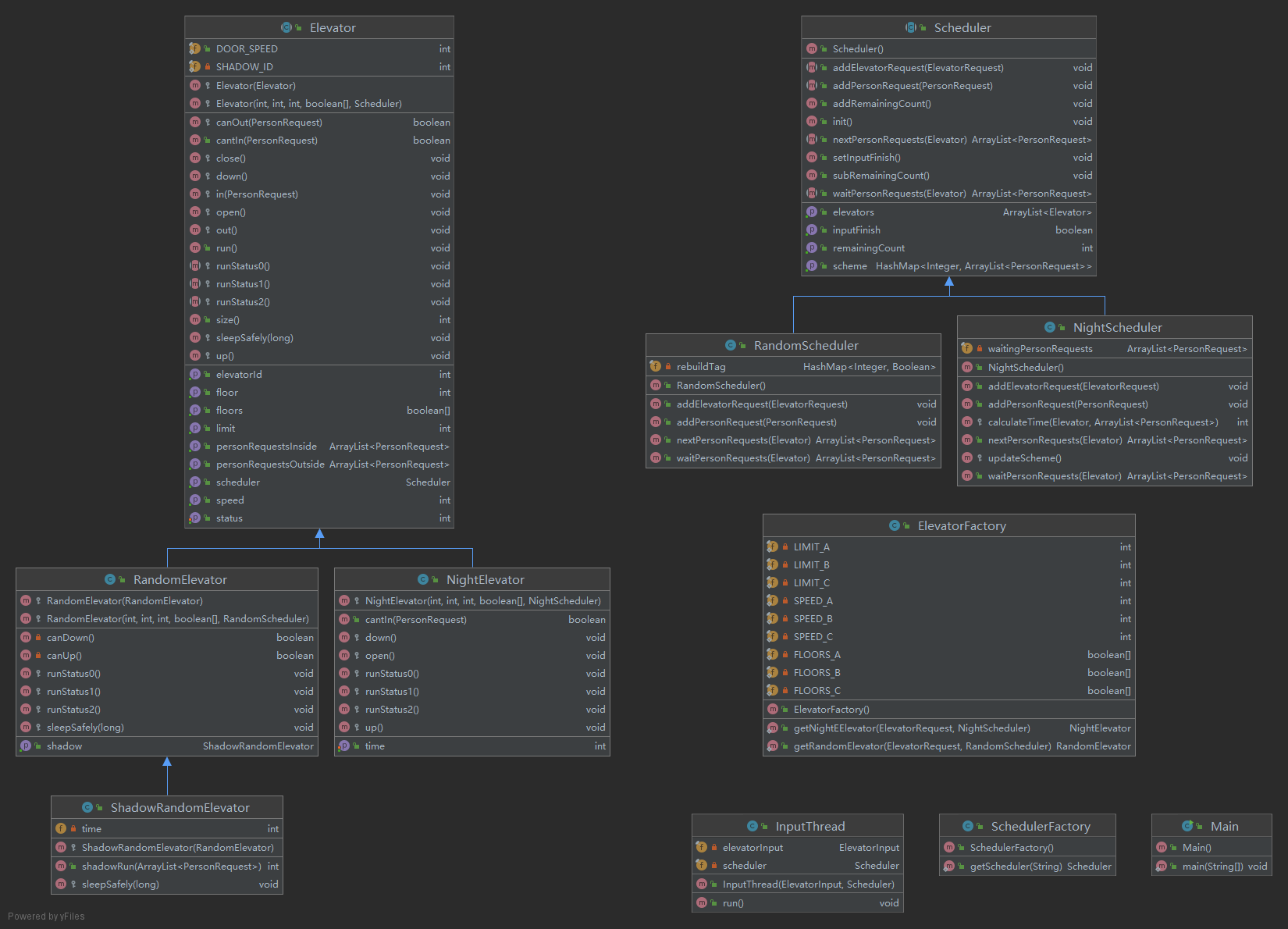
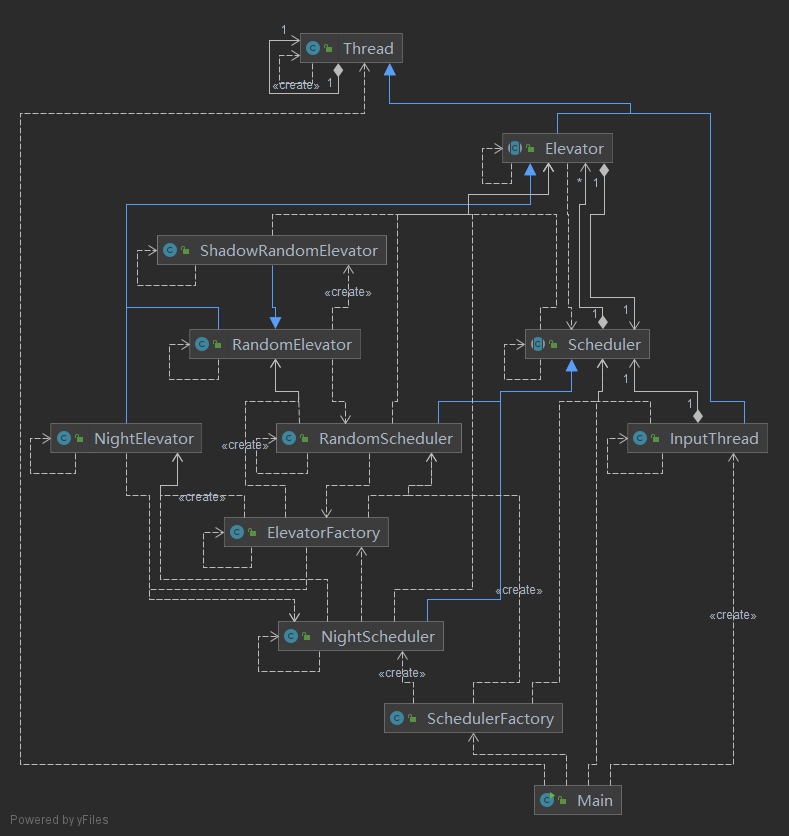
协作图
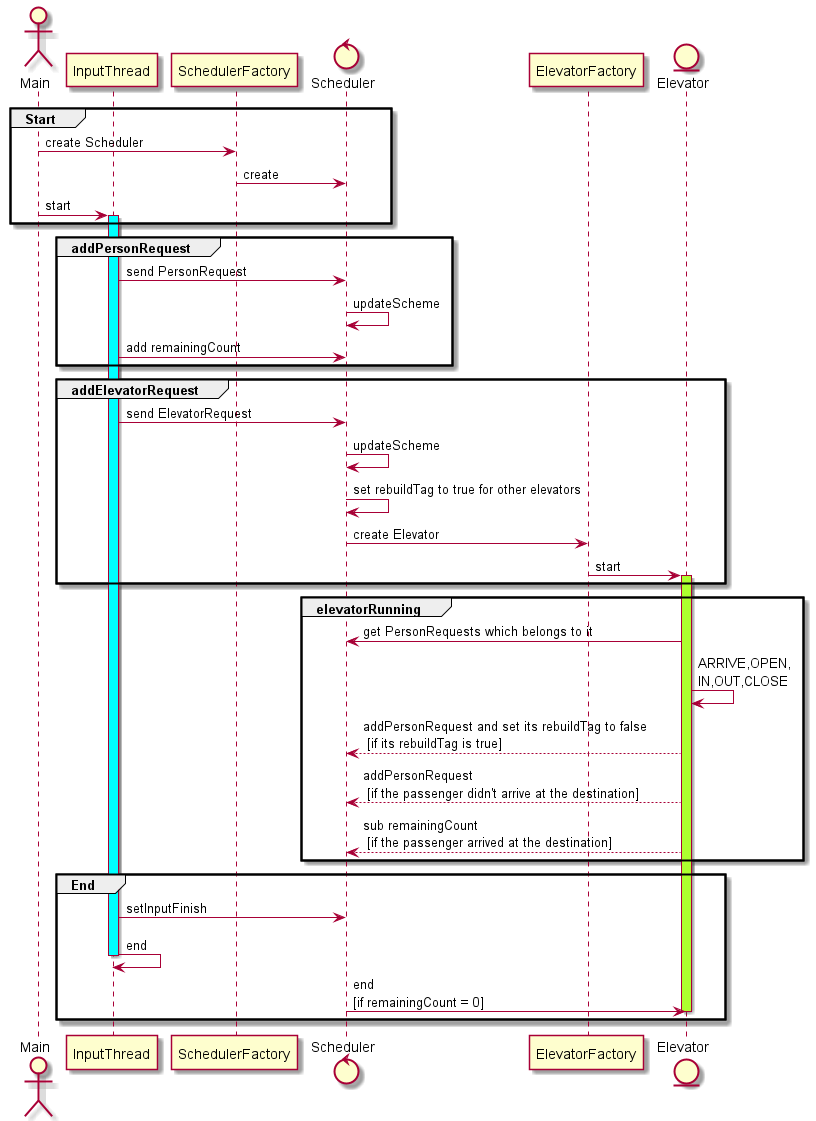
架构与实现
同步块与锁
直接沿用了第六次作业的架构,因此同步块与锁方面和第六次作业完全相同。
调度器
电梯种类出现了变化,停靠楼层越多,速度越慢,容量越大。
同时本次性能分计算方式也发生了变化,额外添加了每个人的等待时间之和。思考了一些算法,一个比一个假,还不好写,索性怎么简单怎么来。
因为每个人等待时间之和的加入,Morning 模式中乘客的等待不一定更优,因此直接将 Random 和 Morning 合并,并沿用第六次作业中的 Random 调度器。唯一发生变化的是,为了让速度更快但停靠楼层有限制的两种电梯也发挥作用,每种电梯会在可以接受该乘客的前提下,将他们送到距离目的地最近的可停靠楼层。具体实现方法为添加一些简单的判断函数,并在乘客离开电梯时判断如果乘客没到达目的地,则将一个新的请求加入调度器。
Night 模式吸取上次失败的教训,保持按最短时间分配的策略,但不再一个个分,而是一次分 \(4/6/8\) 个(取决于电梯容量),这样就可以大幅提高效率。
电梯算法
继续沿用之前的算法。
Night 模式,每次选出楼层最高的数个人拉走。
Morning 和 Random 模式,LOOK 算法,能上就上,不能上就下。
拓展性
可以发现,本次作业的架构其实就是在第六次作业进行拓展的结果,这从侧面验证了该架构的强大可拓展性。
输入 / 调度 / 电梯运作 / 换乘 等部分均 解耦,一旦需求发生变化,并不需要大费周折,只需找到对应的模块进行一定的修改即可。
bug 与测试分析
本次作业没有在强测与互测中出现 bug,性能分丧失了 \(0.25\) 分,原因是有两个 Morning 被卡到了 \(97\) 分。
本地测试中,在第六次作业的评测机基础上进行迭代开发,最后会详细叙述。
值得一提的是,刚写完进行提交时,弱测第三个点老强了,交了两次全死锁了。因为前两次作业中完全没有出现任何多线程的 bug,导致我缺乏处理 bug 的经验,最终经过各种复现操作,终于发现是
waitPersonRequests中判断是否全部乘客都被送完的部分因为太复杂而出现了离谱 bug,我直接将这部分改为「当前还有多少人没有到达目的地」,每次输入一个乘客请求就令人数 \(+1\),每次一个乘客到达目的地就令人数 \(-1\),这样就避免了冗余的判断,轻松解决一切隐患。
互测中,一位同学出现死锁,但很难复现,刀了无数刀都没中,很遗憾。
度量分析
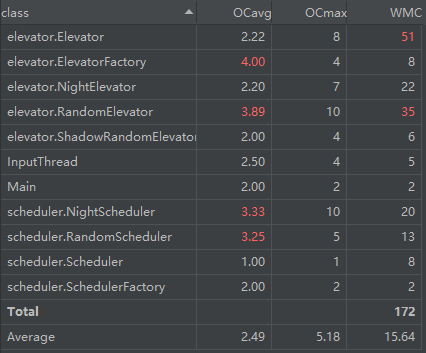
方法复杂度分析
因为方法过多,这里仅截取复杂度过高的部分方法进行分析。
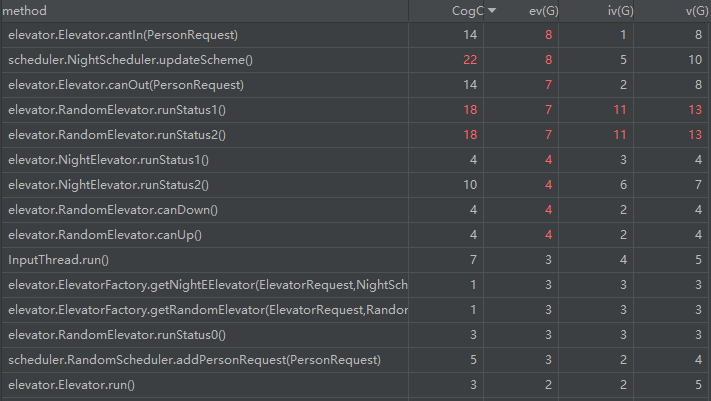
类复杂度分析
类代码行数分析
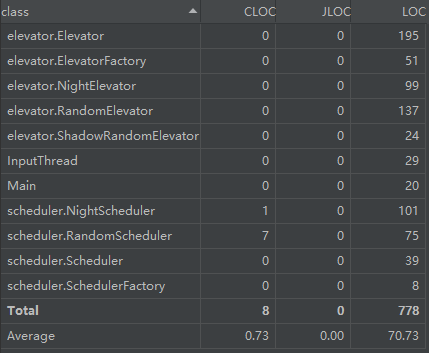
度量分析总结
复杂度方面,因为延续第六次作业的架构,一些该红的地方还是红着,scheduler.NightScheduler.updateScheme 这个方法是上述所说的 Night 模式的分配方法,比较面向过程,说实话这一部分很难进行拆分,毕竟 Night 模式是一个极其特殊且具体的过程,此时一味追求 OO 思想反而会适得其反。
代码行数方面,仅增加了 \(50\) 行,Elevator 类的行数略多,原因是加入了乘客能否进出电梯的判断函数,个人认为放在这个这个类中是比较合适的,不能单纯通过行数较多而将其否定,实在不行可以压行。
评测机
以第七次作业所用评测机为例。
UML 类图
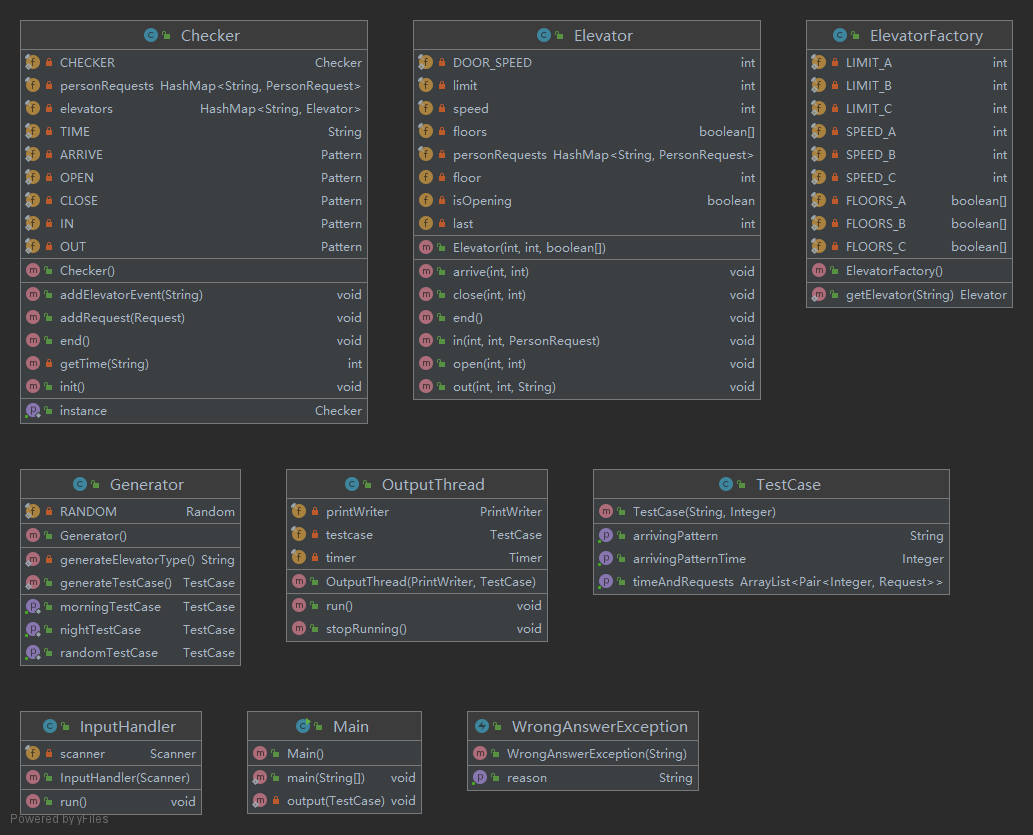
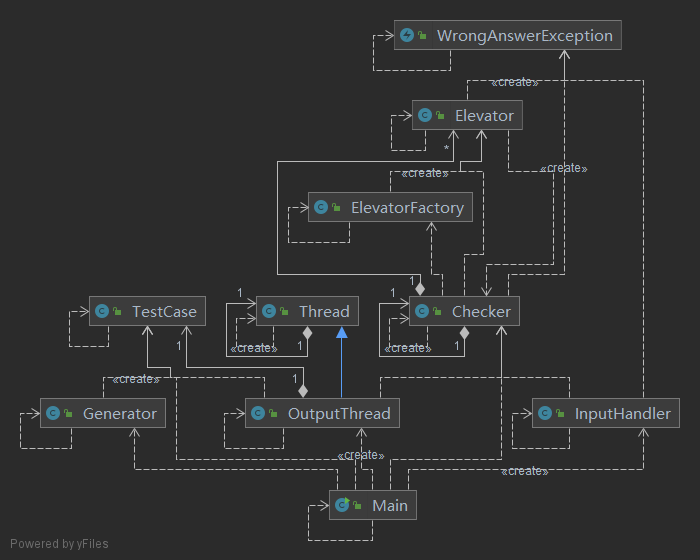
架构与实现
首先使用 Generator 类生成一组数据。
接着用 Process 类创建一个进程,运行打包好的电梯程序。
然后兵分两路:
- 一方面,新建一个线程
OutputThread用于定时投放输入信息给电梯程序,使用的是PrintWriter类,同时也将这些信息传给评测器Checker。 - 另一方面,主线程实例化一个
InputHandler,不断接收电梯程序的输出,使用的是Scanner类,并将输出传给Checker。
Checker 根据输入新建数个电梯线程,并根据输出操纵对应的电梯,一旦发现不合法情况,或是程序出现异常,均直接抛出包含错误原因的 WrongAnswerException。
另外,主线程也会创建一个定时任务,如果 \(210\) 秒还没完事,直接终止程序,并输出 Time Limit Exceeded!。
所有非通过的样例都会将样例和电梯程序输出一并给出。
评测机的编写尽量秉持 OO 的风格,并使用课程组提供的 CheckStyle 进行代码风格的检查,第六次作业评测机到第七次作业评测机的高效迭代,让我又一次体会到了面向对象的好处。
比较遗憾的是没法测 CPU 使用时间,而且因为没有搞明白 Java 的内存分配机制,导致做不到 超多 进程并发,开多了就说内存不够,Java 运行指令加上参数限制也不行,因为时间原因没有再去深究,有时间一定要搞明白。
度量分析
按照惯例,评测机也分析一波。
方法复杂度分析
因为方法过多,这里仅截取复杂度过高的部分方法进行分析。
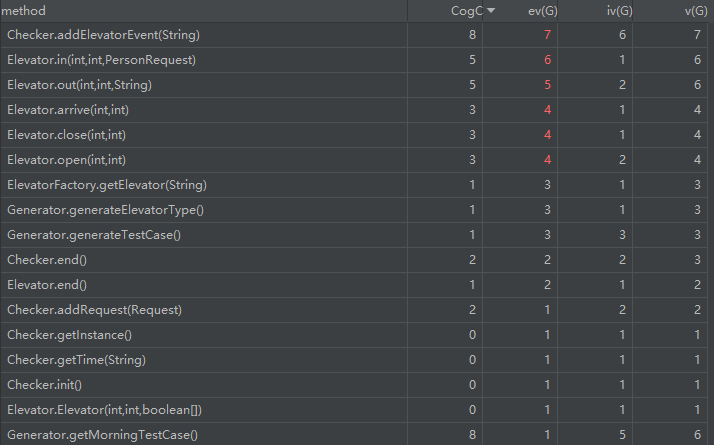
类复杂度分析
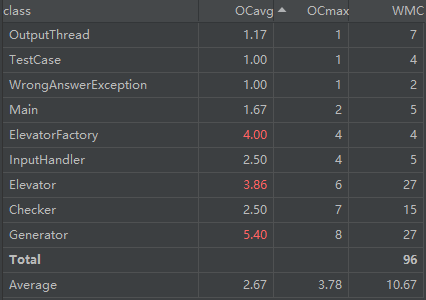
类代码行数分析
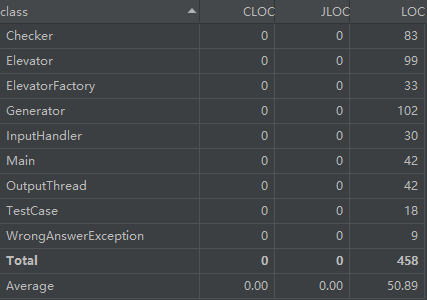
度量分析总结
有一说一,比三次电梯作业的数据好看多了,仅有一些确实需要逻辑判断的地方被标红了,代码长度上也很平均。
或许没有了性能分的约束,才能写出更 OO 的代码吧。
总结与收获
这一单元完整地体会了一遍多线程开发,学习了如何维护线程安全,如何用 wait-notify 取代轮询,以及如何避免死锁。
同时,从第六次作业到第七次作业的改动,以及第六次评测机到第七次评测机的迭代,相比上一单元那次大重构,让我再次体会到了架构的重要性所在。
不过,我认为本单元有一些内容还有改进空间,仅代表个人看法:
-
除了第五次作业的 Night 外,其它情况均不存在所有数据情况下均为最优解的算法,而且大部分情况算法效果很依赖于数据。评判一个调度算法是否足够好,要看这种算法面对足够多足够全面的数据样本的平均表现如何,而不是仅靠 \(20\) 组强测数据,况且这 \(20\) 组数据也没有实现给定其数据生成器或是生成方案。
这个问题在第一单元也有所体现,财富密码就是拆括号和不拆括号取最短,但其实存在很多样例需要别的优化方法,只是没有放在强测中而已。然而指导书中并没有明确指出样例的类型,因此某种意义上也是在「猜样例」,并不能充分体现出化简算法的优劣。
一句题外话,大一的数据结构大作业相比之下更是离谱,亘古不变的一组数据,最后演变成枚举哈希模数,完全是本末倒置。
与其让大家写着虚假的贪心算法,调着不明所以的参数,靠「抽奖」来获取性能分,不如弱化调度优化,仅设置一个最差性能阈值,并用「更多复杂有趣的机制与事件」将其取代。
当然,还有一种需要耗费大量资源的改进方案,即扩大性能测试样例,甚至允许每位同学提交一个
generator,更加全面、真实地评判每一种算法。这样必然耗费大量的运算资源,而且在 bug 修复进行回归测试时也不方便进行,可以考虑额外准备少量的判定正确性的强测样例,不通过将不进行上述大规模性能测试,回归测试时也仅考虑这些样例。 -
前两次作业中,性能分的判定竟然是以程序输出的时间戳为准,而不是以程序真实运行时间为准,这给了同学们改变时间戳初始化的位置来「偷时间」的机会,而对此进行追查也需要耗费一定的人力。不如将程序真实运行时间作为判定标准,而时间戳仅仅用于判断正确性,这样就只会用到时间戳的相对差值,不需要考虑时间戳初始化问题了。
-
第六次作业中,hack 时经常出现输入数据非法的情况,如果可以将
validator中数据非法的原因反馈给 hack 者可能会更加人性化一些。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号