
【数据预处理】TIMIT语料库WAV文件转换
1 问题描述
这两天复现代码。先构造数据集,纯净语音、不同噪声、不同SNR的混合语音。其中纯净语音由两部分组成,IEEE corpus和TIMIT。
一开始我用MATLAB中的audioread读取音频文件,合成后用audiowrite保存下来。没有任何问题。
后来,师姐让我换成python处理,不管是wave还是scipy.io中的wavfile,在读取TIMIT的原始WAV时都会报错。
2 原因定位
通过上述问答以及TIMIT语料库的官方说明文件,我们可以发现TIMIT中的WAV文件是:
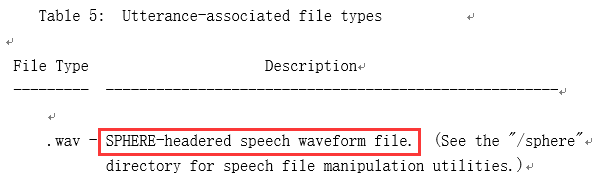
我们用notepad++打开任意一个数据集中的wav文件,可以看到以下内容作为开头:
而以同样方式打开普通的wav文件,则开头内容为:

3 解决思路
将SPHERE文件转换成WAV文件。
网上可以找到许多方法,在此我采用了Dystopia在基于各种分类算法的说话人识别(年龄段识别)一文中的方法。
Kaldi中tools下有SPHERE文件转换工具sph2pipe.exe
1.下载编译sph2pipe
转换工具:sph2pipe_v2.5,如果安装过Kaldi的话,可以直接使用 $KALDI_ROOT/tools/sph2pipe_v2.5/sph2pipe,如果没有安装的话,可以单独下载:http://sourceforge.net/projects/kaldi/files/sph2pipe_v2.5.tar.gz
如果是在Windows环境下的话直接使用sph2pipe.exe即可,如果是在linux环境下的话,则需要进行GCC编码:gcc -o sph2pipe *.c -lm
2.用re_sph2pipe.py脚本生成sph2pipe转换文件
1 #encoding="utf-8" 2 import os 3 import os.path 4 rootdir = "/data/Datasets/yuanpp/TIMIT" 5 timitpath = "/data/Datasets/yuanpp/TIMIT" 6 targetpath = "/data/Datasets/yuanpp/TIMIT_convert" 7 sph2pipepath = "/home/yuanpeipei/sph2pipe_v2.5/sph2pipe" 8 f = open('./make_sph2pipe_file.txt','w') 9 for root,dirs,files in os.walk(rootdir): 10 for fn in files: 11 if fn[len(fn)-3:len(fn)]=='wav': 12 sourcefile = timitpath+root[len(rootdir):]+"/"+fn 13 targetfile = targetpath + "/" + fn 14 s = sph2pipepath + " -f wav " + sourcefile+" "+targetfile+"\n" 15 f.write(s) 16 f.close()
生成make_sph2pipe_file.txt文件,内容为命令行。
1 /home/yuanpeipei/sph2pipe_v2.5/sph2pipe -f wav /data/Datasets/yuanpp/TIMIT/pure_utterance/validation/S_125_06.wav /data/Datasets/yuanpp/TIMIT_convert/S_125_06.wav 2 /home/yuanpeipei/sph2pipe_v2.5/sph2pipe -f wav /data/Datasets/yuanpp/TIMIT/pure_utterance/validation/S_130_03.wav /data/Datasets/yuanpp/TIMIT_convert/S_130_03.wav 3 /home/yuanpeipei/sph2pipe_v2.5/sph2pipe -f wav /data/Datasets/yuanpp/TIMIT/pure_utterance/validation/S_60_10.wav /data/Datasets/yuanpp/TIMIT_convert/S_60_10.wav 4 /home/yuanpeipei/sph2pipe_v2.5/sph2pipe -f wav /data/Datasets/yuanpp/TIMIT/pure_utterance/validation/S_130_06.wav /data/Datasets/yuanpp/TIMIT_convert/S_130_06.wav 5 ... ...
3.在linux下执行shell命令
1 #!/bin/sh 2 while read line 3 do 4 $line 5 done < make_sph2pipe_file.txt
即可。
参考资料:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号