requests的使用
准备工作#
安装request库#
pip install request
实例引入#
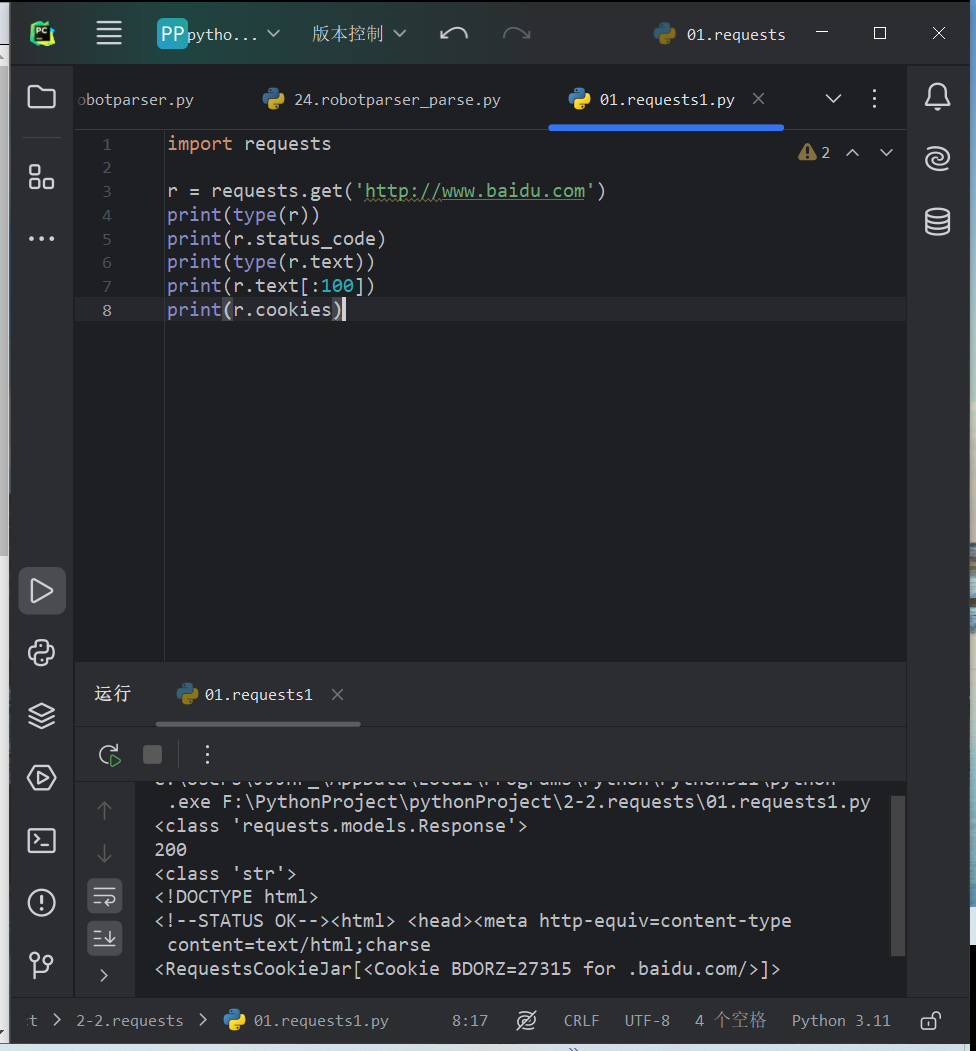
get方法实现GET请求,返回一个Response对象,存放在变量r中,分别输出响应的类型、状态码、响应体的类型、内容以及cookie
import requests r = requests.get('http://www.baidu.com') print(type(r)) print(r.status_code) print(type(r.text)) print(r.text[:100]) print(r.cookies)
也可以实现POST、PUT、DELETE等请求
import requests r1 = requests.get('https://www.httpbin.org/get') r2 = requests.post('https://www.httpbin.org/post') r3 = requests.put('https://www.httpbin.org/get/put') r4 = requests.delete('https://www.httpbin.org/get/delete') r5 = requests.patch('https://www.httpbin.org/get/patch')
GET请求#
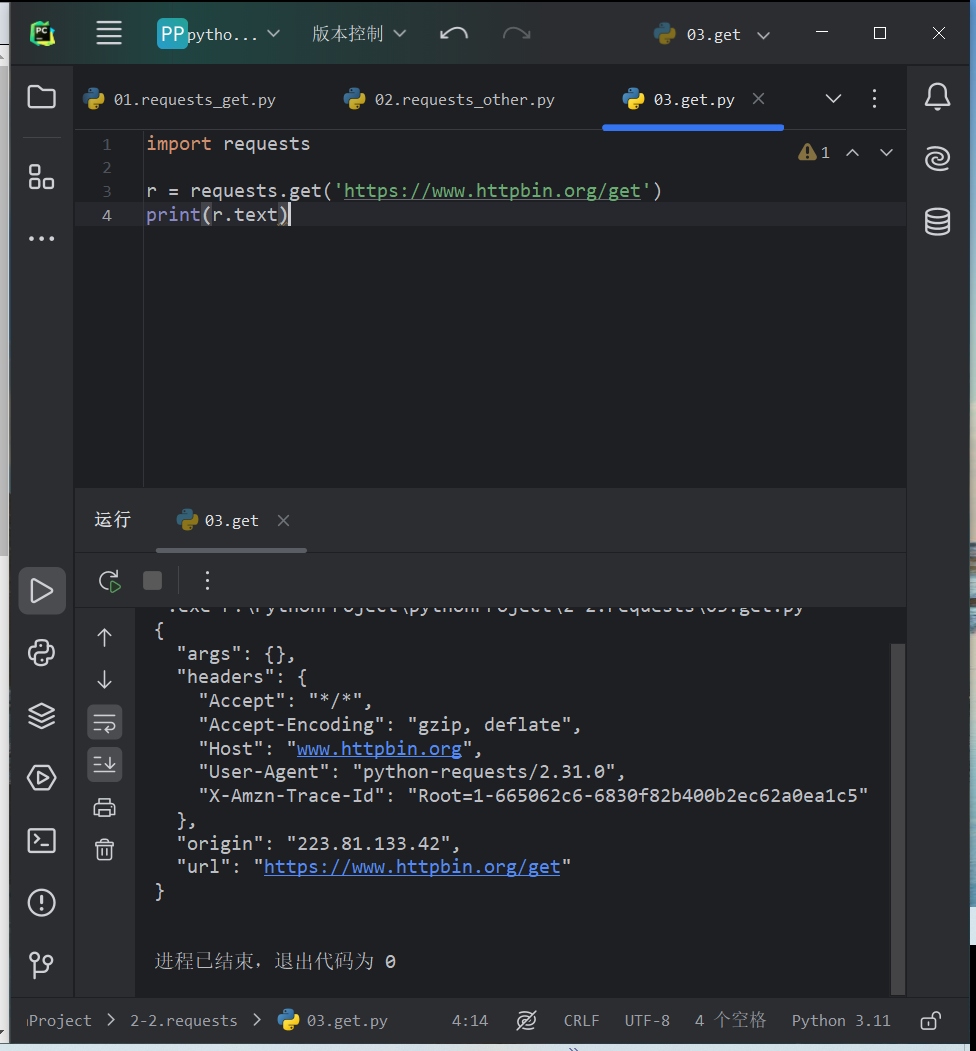
- 基本实例使用requests库构建一个GET请求
import requests r = requests.get('https://www.httpbin.org/get') print(r.text)
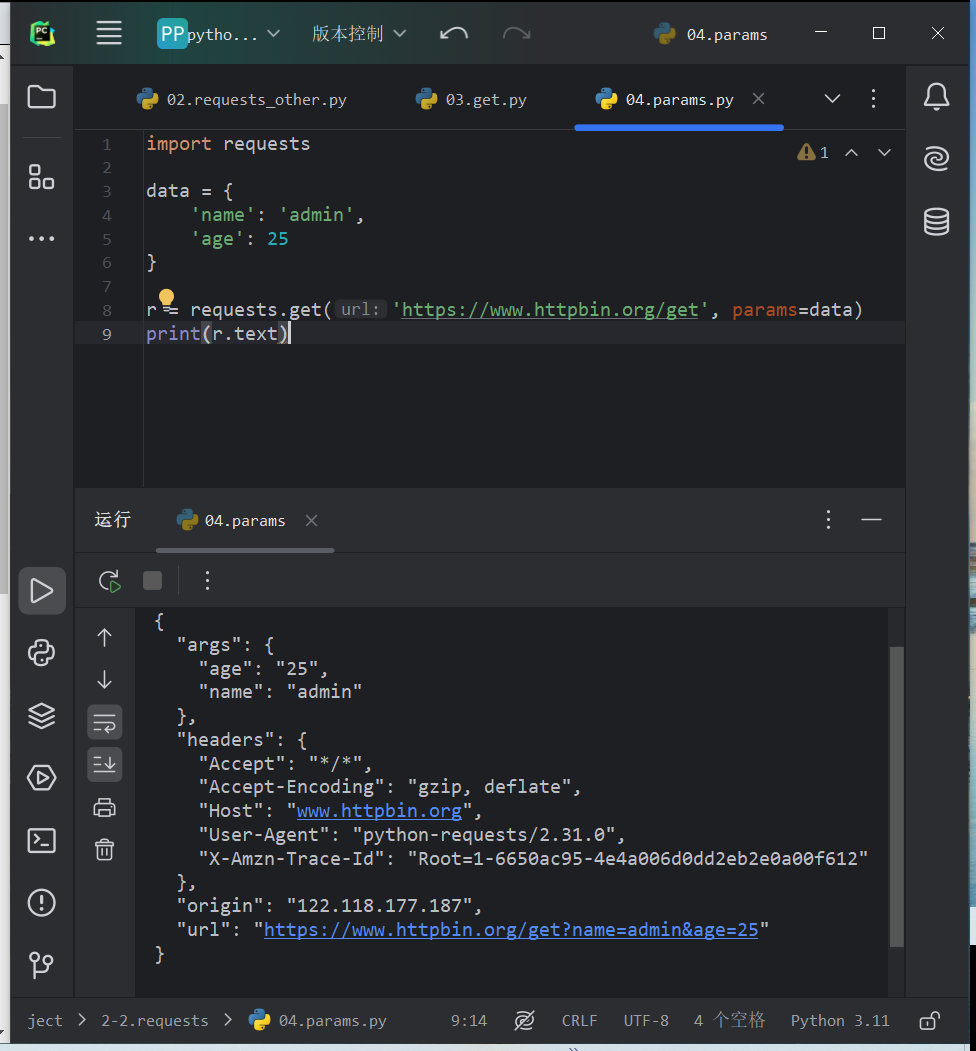
使用params参数给URL添加参数

import requests data = { 'name': 'admin', 'age': 25 } r = requests.get('https://www.httpbin.org/get', params=data) print(r.text)
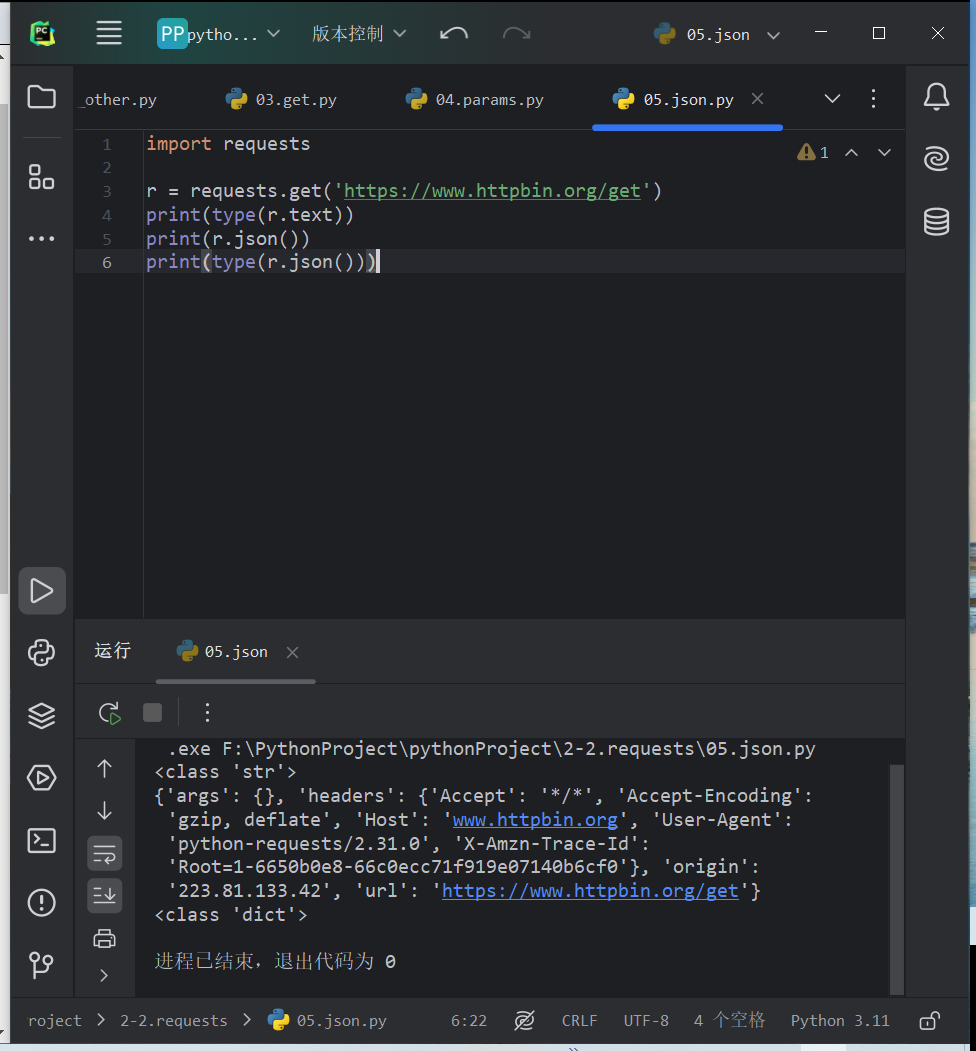
把URL参数以字典的形式传给get方法的params参数,请求的链接被自动构造成含参链接,网页的返回类型为str类型,但是是JSON格式的,若想直接解析返回结果,得到一个JSON格式的数据,可调用json方法将返回结果转换为字典。d
import requests r = requests.get('https://www.httpbin.org/get') print(type(r.text)) print(r.json()) print(type(r.json()))
- 抓取网页
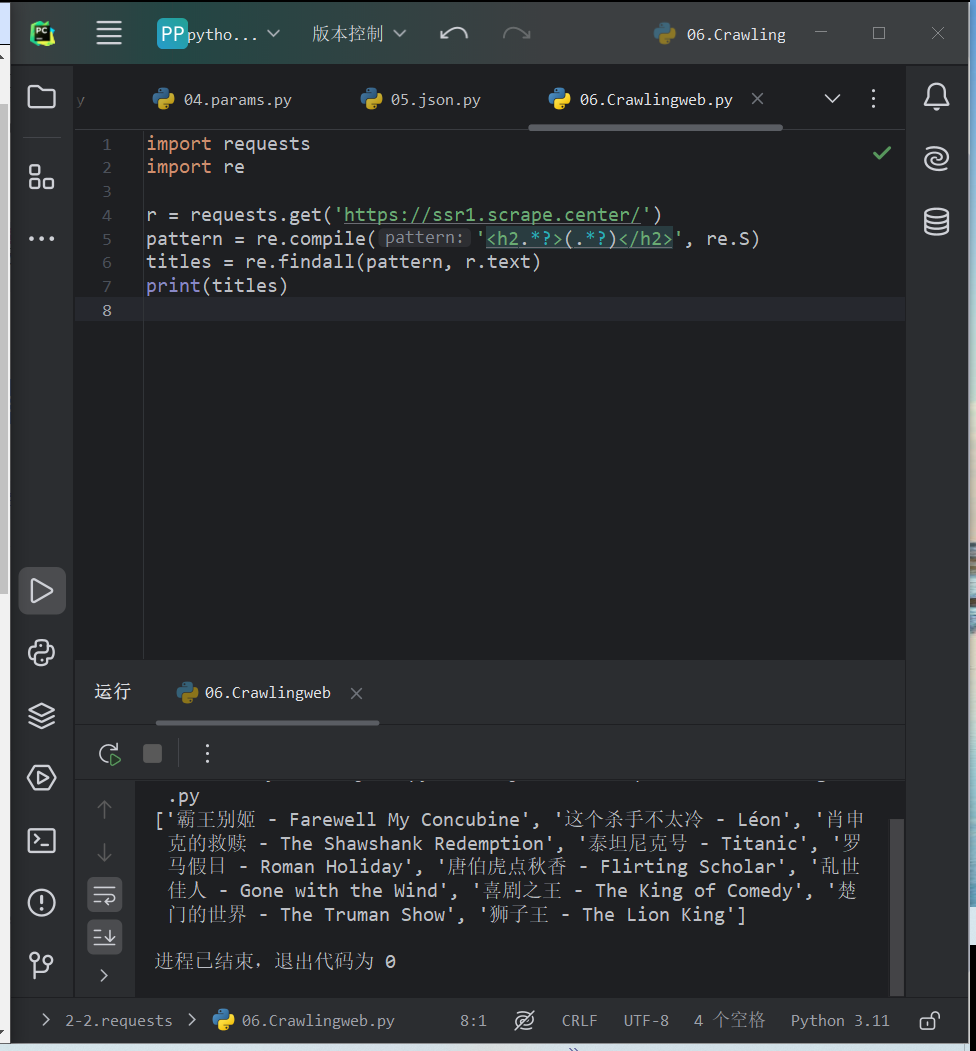
使用正则表达式提取网页标题
import requests import re r = requests.get('https://ssr1.scrape.center/') pattern = re.compile('<h2.*?>(.*?)</h2>', re.S) titles = re.findall(pattern, r.text) print(titles)
- 抓取二级制数据
上面例子为使用某些规则抓取网页的部分内容,若想抓取图片、音频、视频等文件时,这些文件本质上是由二进制编码组成,要抓取这些文件需要拿到他们的二进制数据。
import requests r = requests.get('https://scrape.center/favicon.ico')
print(type(r.text))
print(r.text)
print(type(r.content))
print(r.content)


r.content前面的b代表这是bytes类型的数据,r.tex在打印时会转换为str类型,也就是图片直接转换为字符串,所以会乱码。
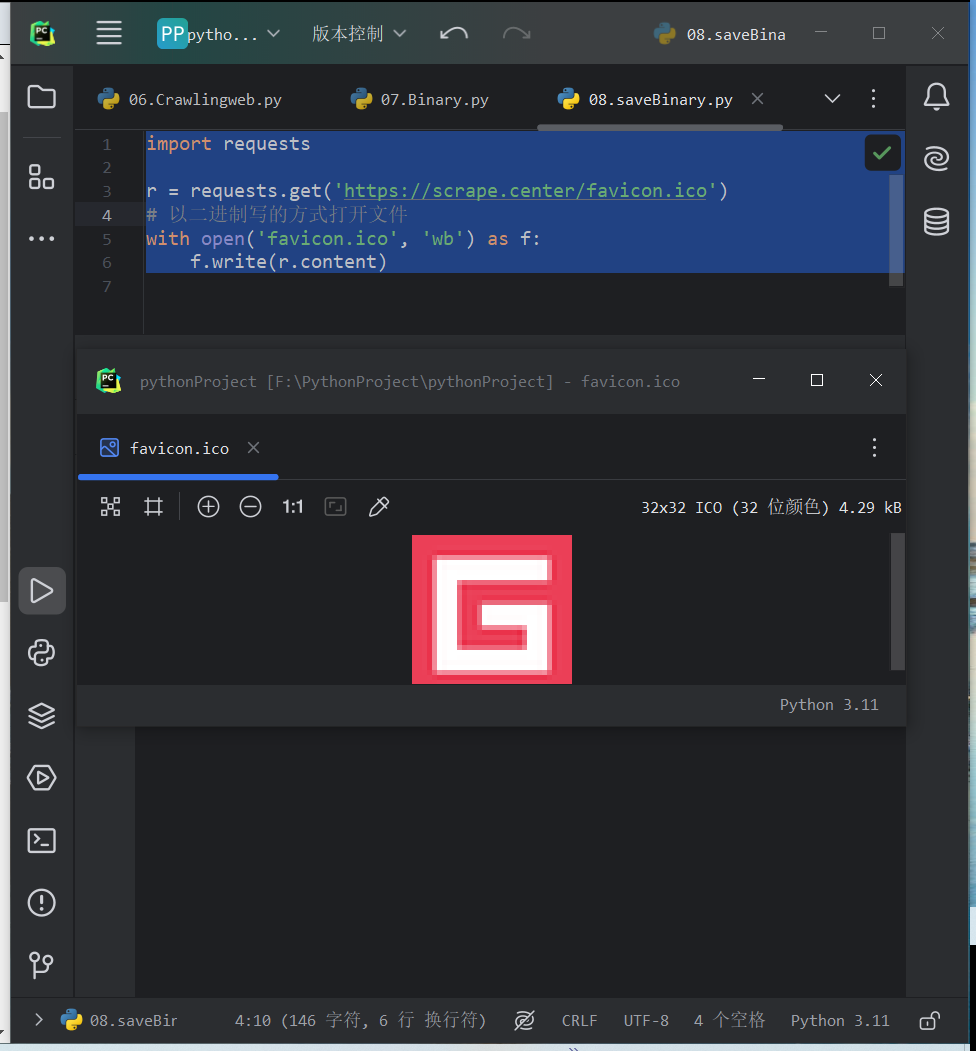
将提取的二进制数据保存
import requests r = requests.get('https://scrape.center/favicon.ico') # 以二进制写的方式打开文件 with open('favicon.ico', 'wb') as f: f.write(r.content)
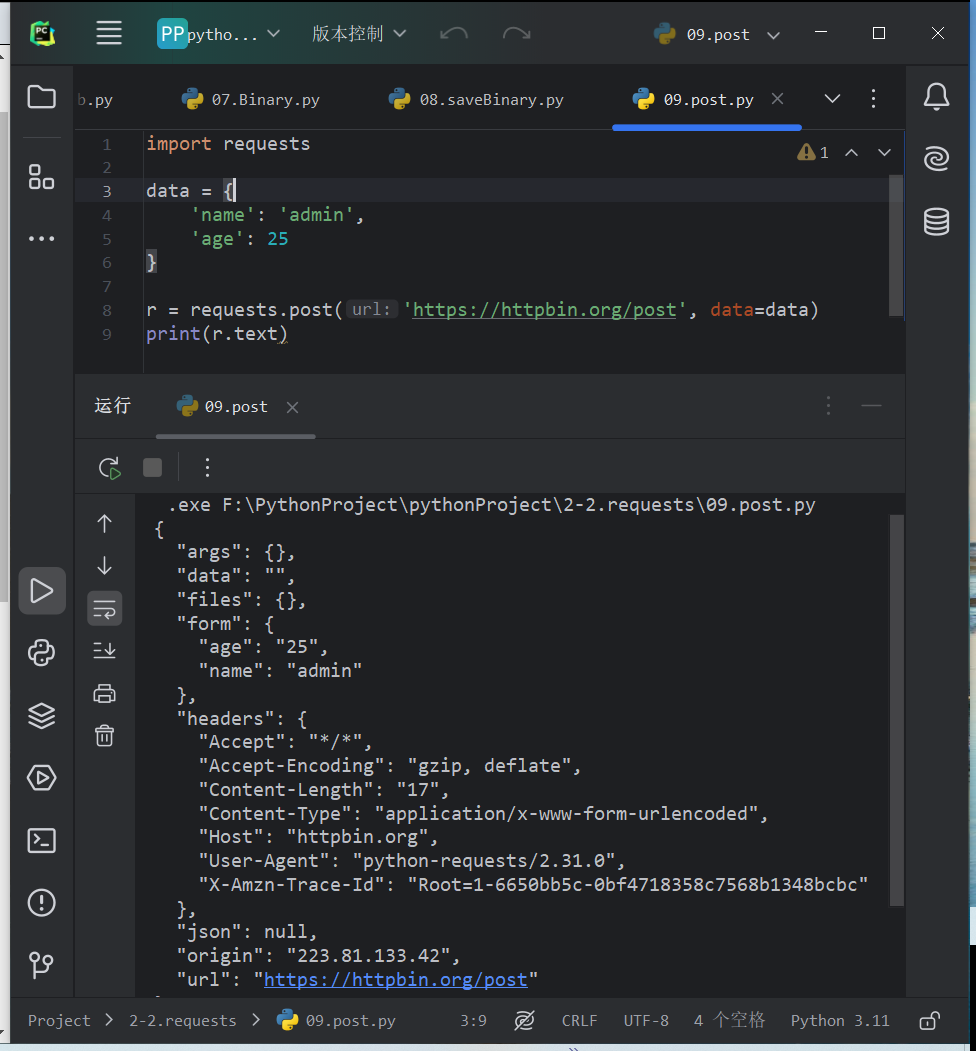
POST请求#
import requests data = { 'name': 'admin', 'age': 25 } r = requests.post('https://httpbin.org/post', data=data) print(r.text)
 #
#
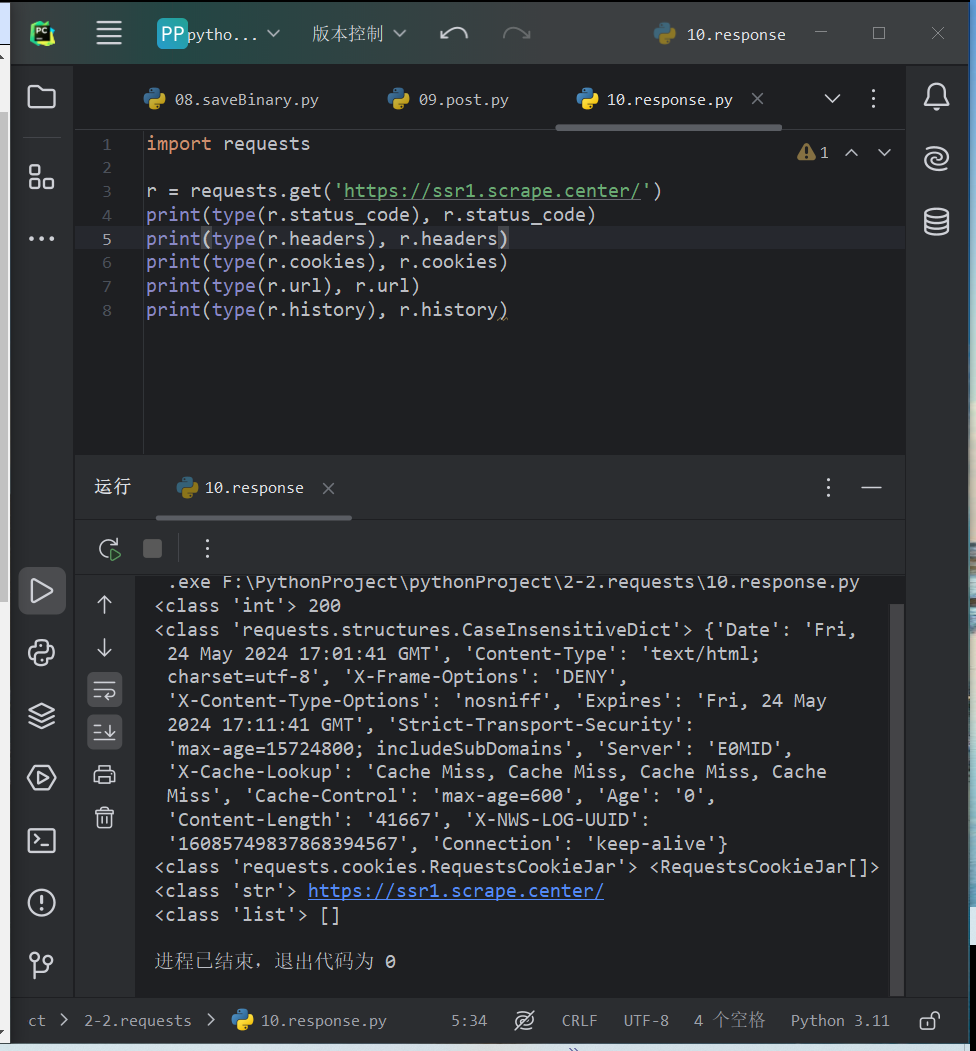
响应#
除了使用text和content获取响应内容外。还有许多属性和方法来获取信息,例如状态码、响应头、Cookie等
import requests r = requests.get('https://ssr1.scrape.center/') print(type(r.status_code), r.status_code) print(type(r.headers), r.headers) print(type(r.cookies), r.cookies) print(type(r.url), r.url) print(type(r.history), r.history)
requests库提功了内置的状态码查询对象requests.codes
import requests r = requests.get('https://ssr1.scrape.center/') exit() if not r.status_code == requests.codes.ok else print('请求成功')
常用返回码和相应的查询条件P53
当使用 requests 发送一个请求时,你可以通过 response.status_code 来获取状态码,并使用 response.text 或 response.json()(如果返回的是 JSON)来获取响应的内容。
高级用法#
- 文件上传
import requests files = {'file': open('favicon.ico', 'rb')} r = requests.post('http://httpbin.org/post', files=files) print(r.text)
- Cookie设置
ookies写法复杂,可使用requests获取和设置Cookie
import requests r = requests.get('http://www.baidu.com') # 调用cookies属性,成功得到Cookie,属于RequestCookieJar类型 print(r.cookies) # 调用items方法将Cookie转换为由元组组成的列表,遍历输出Cookie中的每一个条目的名称和值,实现遍历解析 for key, values in r.cookies.items(): print(key + '=' + values)
可以用cookie来维持登录状态。以github为例,登录自己的账号:
import requests headers = { 'Cookie': '_octo=GH1.1.229921746.1716358908; preferred_color_mode=light; tz=Asia%2FShanghai; color_mode=%7B%22color_mode%22%3A%22auto%22%2C%22light_theme%22%3A%7B%22name%22%3A%22light%22%2C%22color_mode%22%3A%22light%22%7D%2C%22dark_theme%22%3A%7B%22name%22%3A%22dark%22%2C%22color_mode%22%3A%22dark%22%7D%7D; logged_in=yes; dotcom_user=2811006977' } r = requests.get('https://github.com/', headers=headers) print(r.text)
也可以通过cookies参数来设置Cookie信息。构造一个RequestsCookieJar对象,将刚才的Cookie进行处理及赋值。
import requests cookies = '_octo=GH1.1.229921746.1716358908; preferred_color_mode=light; tz=Asia%2FShanghai; color_mode=%7B%22color_mode%22%3A%22auto%22%2C%22light_theme%22%3A%7B%22name%22%3A%22light%22%2C%22color_mode%22%3A%22light%22%7D%2C%22dark_theme%22%3A%7B%22name%22%3A%22dark%22%2C%22color_mode%22%3A%22dark%22%7D%7D; logged_in=yes; dotcom_user=2811006977' jar = requests.cookies.RequestsCookieJar() headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36' } for cookie in cookies.split(';'): key, value = cookie.split('=', 1) jar.set(key, value) r = requests.get('https://github.com/', cookies=jar, headers=headers) print(r.text)
- Session维持
利用Session可以做到模拟同一个会话而不用担心Cookie的问题,通常在模拟登陆成功之后进行下一步操作时用到。
案例:如果沿用之前写法并不会输出cookie
import requests requests.get('http://httpbin.org/cookies/set/number/123456789') r = requests.get('http://httpbin.org/cookies') print(r.text)

改用session继续尝试
import requests s = requests.Session() s.get('http://httpbin.org/cookies/set/number/123456789') r = s.get('http://httpbin.org/cookies') print(r.text)
- SSL证书验证
很多网站要求使HTTPS协议,但是有的网站可能没有设置好HTTPS证书,或者证书没有被CA机构认可,所以网站可能出现SSL证书错误的提示。

可以在浏览器汇总通过一些设置来说忽略证书的验证
import requests response = requests.get('https://ssr2.scrape.center/', verify=False) print(response.status_code)
此处的警告可以通过设置忽略警告的方式以来屏蔽:
import urllib3 urllib3.disable_warnings()
或者通过捕获警告到日志的方式忽略警告
import logging logging.captureWarnings(True)
- ·超时设置
import requests r = requests.get('http://www.httpbin.org/get', timeout=1) print(r.status_code)
请求分为两个部分:连接(connect)和读取(read)
timeout是连接和读取的总和,若想分别制定作用,可以传入一个元组
r = requests.get('http://www.httpbin.org/get', timeout=(2, 30))
- 身份认证
urllib库进行身份验证较为繁琐,可以直接使用requests库
import requests from requests.auth import HTTPBasicAuth r = requests.get('https://ssr3.scrape.center/',auth=HTTPBasicAuth('user','password')) print(r.status_code)
如果参数都传一个HTTPBasicAuth类很繁琐,可以直接传一个元组,会默认使用HTTPBasicAuth这个类来验证
import requests r = requests.get('https://ssr3.scrape.center/', auth=('user', 'password')) print(r.status_code)
requests库还提供了其他认证方式,如OAuth认证
pip install requests_oauthlib
import requests from requests_oauthlib import OAuth1 url = 'https://api.twitter.com/1.1/account/verify_credentials.json' auth = OAuth1('YOUR_API_KEY', 'YOUR_API_SECRET', 'YOUR_ACCESS_TOKEN', 'YOUR_ACCESS_TOKEN_SECRET') requests.get(url, auth=auth)
- 代理设置
大规模爬取,频繁请求可能会导致封禁ip,可以使用proxies设置代理来解决(代理替换为有效代理)
import requests proxies = { 'http': 'http://117.42.94.192:20720', 'https': 'http://117.42.94.192:20720', } requests.get('https://www.httpbin.org/get', proxies=proxies)
若代理需要身份认证,可使用类似http://user://password@host:post这样的语句来设置代理
import requests proxies = {'https://user://password@127.0.0.1:8080/', } requests.get('https://www.httpbin.org/get', proxies=proxies)
除基本的HTTP代理,requests库还支持SOCKS协议的代理
pip install “request[socks]”
import requests proxies = { 'http': 'socks5://127.0.0.1:1080', 'https': 'socks5://127.0.0.1:1080' } response = requests.get('http://www.baidu.com', proxies=proxies)
- Prepared Request
使用requests库的get和post请求的时,在内部构造一个Request对象发送出去,请求成功后会再得到一个Response对象,解析这个对象即可。Request对象实际上就是Prepared Request
不用get方法,直接构造Prepared Request:引入Request类,用url、data和headers参数构造一个Request对象,再调用Session类的prepare_request方法将其转换为一个Prepared Request对象,在调用一个send发送
from requests import Session,Request url = 'http://www.httpbin.org/post' data = {'name': 'data'} headers = { 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/16.0 Safari/605.1.15' } session = Session() req = Request('POST', url, data=data, headers=headers) prepped = session.prepare_request(req) r = session.send(prepped) print(r.text)




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· ollama系列01:轻松3步本地部署deepseek,普通电脑可用
· 25岁的心里话
· 按钮权限的设计及实现