

本次学习学习了Dataframe方面的知识
DataFrame
DataFrame概念
Spark SQL增加了DataFrame(即带有Schema信息的RDD),使用户可以在Spark SQL中执行SQL语句,数据既可以来自RDD,也可以是Hive、HDFS、Cassandra等外部数据源,还可以是JSON格式的数据Spark SQL目前支持Scala、Java、Python三种语言,支持SQL-2003规范
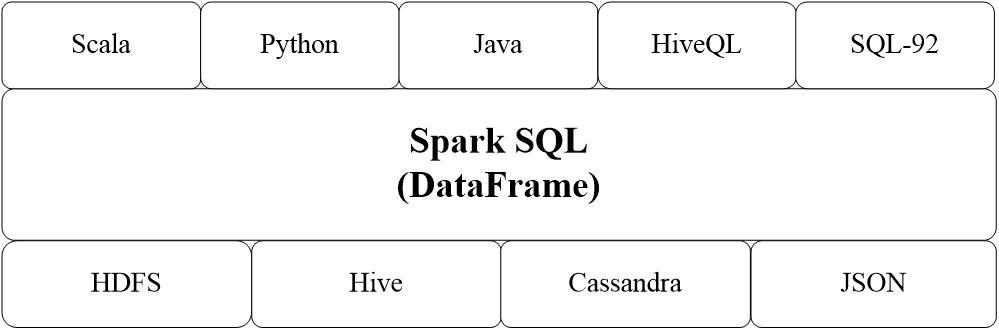
DataFrame的推出,让Spark具备了处理大规模结构化数据的能力,不仅比原有的RDD转化方式更加简单易用,而且获得了更高的计算性能Spark能够轻松实现从MySQL到DataFrame的转化,并且支持SQL查询
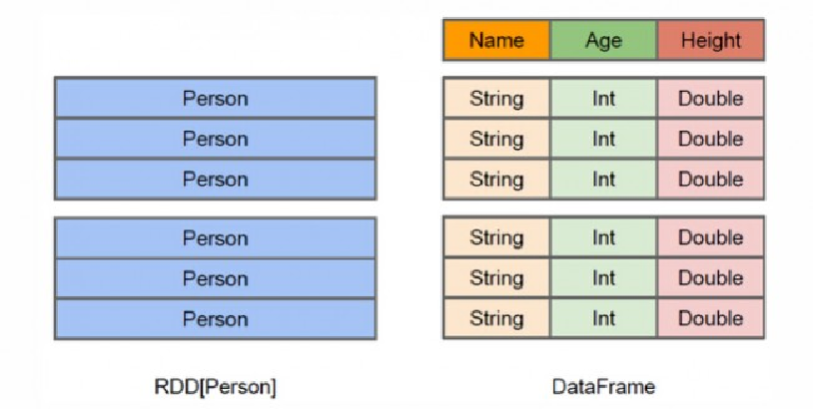
RDD是分布式的 Java对象的集合,但是,对象内部结构对于RDD而言却是不可知的
DataFrame是一种以RDD为基础的分布式数据集,提供了详细的结构信息,可以快速去找相关信息
DataFrame创建
scala> import org.apache.spark.sql.SparkSession import org.apache.spark.sql.SparkSession scala> val spark = SparkSession.builder().getOrCreate() spark: org.apache.spark.sql.SparkSession = org.apache.spark.sql.SparkSession@1cc00f56 // 支持RDDs转换为DataFrames以及后面的操作 scala> import spark.implicits._ import spark.implicits._ scala> val df = spark.read.json("file:///usr/local/spark/examples/src/main/resources/people.json") df: org.apache.spark.sql.DataFrame = [age: bigint, name: string] // 展示 scala> df.show() +----+-------+ | age| name| +----+-------+ |null|Michael| | 30| Andy| | 19| Justin| +----+-------+ //查看结构 scala> df.printSchema() root |-- age: long (nullable = true) |-- name: string (nullable = true) // 查询 scala> df.select(df("name"),df("age") + 1).show() +-------+---------+ | name|(age + 1)| +-------+---------+ |Michael| null| | Andy| 31| | Justin| 20| +-------+---------+ // 过滤 scala> df.filter(df("age") > 20).show() +---+----+ |age|name| +---+----+ | 30|Andy| +---+----+ // 分组 scala> df.groupBy("age").count().show() +----+-----+ | age|count| +----+-----+ | 19| 1| | 30| 1| |null| 1| +----+-----+ // 排序 scala> df.sort(df("age").desc).show() +----+-------+ | age| name| +----+-------+ | 30| Andy| | 19| Justin| |null|Michael| +----+-------+ // 进行多列排序 scala> df.sort(df("age").desc,df("name").asc).show() +----+-------+ | age| name| +----+-------+ | 30| Andy| | 19| Justin| |null|Michael| +----+-------+ // 进行重命名 scala> df.select(df("name").as("username"),df("age")).show() +--------+----+ |username| age| +--------+----+ | Michael|null| | Andy| 30| | Justin| 19| +--------+----+
利用反射机制推断RDD模式
在利用反射机制推断RDD模式时,需要首先定义一个case class,因为,只有case class才能被Spark隐式地转换为DataFrame
scala> case class Person(name: String, age: Long) //定义一个case class defined class Person scala> val peopleDF = spark.sparkContext. | textFile("file:///usr/local/spark/examples/src/main/resources/people.txt"). | map(_.split(",")). | map(attributes => Person(attributes(0), attributes(1).trim.toInt)).toDF() peopleDF: org.apache.spark.sql.DataFrame = [name: string, age: bigint] scala> peopleDF.createOrReplaceTempView("people") //必须注册为临时表才能供下面的查询使用 scala> val personsRDD = spark.sql("select name,age from people where age > 20") //最终生成一个DataFrame,下面是系统执行返回的信息 personsRDD: org.apache.spark.sql.DataFrame = [name: string, age: bigint] scala> personsRDD.map(t => "Name: "+t(0)+ ","+"Age: "+t(1)).show() //DataFrame中的每个元素都是一行记录,包含name和age两个字段,分别用t(0)和t(1)来获取值 //下面是系统执行返回的信息 +------------------+ | value| +------------------+ |Name:Michael,Age:29| | Name:Andy,Age:30| +------------------+
使用编程方式定义RDD模式
当无法提前定义case class时,就需要采用编程方式定义RDD模式。
scala> import org.apache.spark.sql.types._ import org.apache.spark.sql.types._ scala> import org.apache.spark.sql.Row import org.apache.spark.sql.Row //下面加载文件生成RDD scala> val peopleRDD = spark.sparkContext. | textFile("file:///usr/local/spark/examples/src/main/resources/people.txt") peopleRDD: org.apache.spark.rdd.RDD[String] = file:///usr/local/spark/examples/src/main/resources/people.txt MapPartitionsRDD[1] at textFile at <console>:26 //定义一个模式字符串 scala> val schemaString = "name age" schemaString: String = name age // 进行 scala> val fields = schemaString.split(" ").map(fieldName => StructField(fieldName,StringType,nullable = true)) fields: Array[org.apache.spark.sql.types.StructField] = Array(StructField(name,StringType,true), StructField(age,StringType,true)) //进行关联,schema描述了模式信息,模式中包含name和age两个字段 //shcema就是“表头” scala> val schema = StructType(fields) schema: org.apache.spark.sql.types.StructType = StructType(StructField(name,StringType,true), StructField(age,StringType,true)) //下面加载文件生成RDD scala> val peopleRDD = spark.sparkContext. | textFile("file:///usr/local/spark/examples/src/main/resources/people.txt") peopleRDD: org.apache.spark.rdd.RDD[String] = file:///usr/local/spark/examples/src/main/resources/people.txt MapPartitionsRDD[1] at textFile at <console>:26 //对peopleRDD 这个RDD中的每一行元素都进行解析 scala> val rowRDD = peopleRDD.map(_.split(",")). | map(attributes => Row(attributes(0), attributes(1).trim.toInt)) rowRDD: org.apache.spark.rdd.RDD[org.apache.spark.sql.Row] = MapPartitionsRDD[3] at map at <console>:29 //上面得到的rowRDD就是“表中的记录” //下面把“表头”和“表中的记录”拼装起来 scala> val peopleDF = spark.createDataFrame(rowRDD, schema) peopleDF: org.apache.spark.sql.DataFrame = [name: string, age: int] //必须注册为临时表才能供下面查询使用 scala> peopleDF.createOrReplaceTempView("people") scala> val results = spark.sql("SELECT name,age FROM people") results: org.apache.spark.sql.DataFrame = [name: string, age: int] scala> results. | map(attributes => "name: " + attributes(0)+","+"age:"+attributes(1)). | show() +--------------------+ | value| +--------------------+ |name: Michael,age:29| | name: Andy,age:30| | name: Justin,age:19|
把RDD保存为文件
scala> val peopleDF = spark.read.format("json").load("file:///usr/local/spark/examples/src/main/resources/people.json") peopleDF: org.apache.spark.sql.DataFrame = [age: bigint, name: string] scala> peopleDF.select("name","age").write.format("csv").save("file:///usr/local/spark/mycode/newpeople.csv")
write.format()可以指定输出json,parquet,jdbc,orc,csv,text等类型的文件
scala> df.rdd.saveAsTextFile("file:///usr/local/spark/mycode/newpeople.txt")
生成的均为一个目录
[atguigu@hadoop102 mycode]$ ll 总用量 0 drwxrwxr-x. 2 atguigu atguigu 6 1月 22 17:56 examples drwxrwxr-x. 5 atguigu atguigu 64 1月 22 21:58 filesort drwxrwxr-x. 3 atguigu atguigu 23 1月 22 21:27 MaxAndMin drwxr-xr-x. 2 atguigu atguigu 176 1月 23 11:48 newpeople.csv drwxr-xr-x. 2 atguigu atguigu 84 1月 23 11:53 newpeople.txt drwxrwxr-x. 3 atguigu atguigu 52 1月 22 21:53 rdd drwxrwxr-x. 2 atguigu atguigu 40 1月 22 21:22 rdd2 drwxrwxr-x. 5 atguigu atguigu 64 1月 22 18:31 topscala drwxrwxr-x. 6 atguigu atguigu 97 1月 21 21:09 wordcount

 浙公网安备 33010602011771号
浙公网安备 33010602011771号