

本次学习学习了共享变量的相关知识内容以及文件系统的读写
本地文件系统的数据读写
读
scala> val textFile = sc.textFile("file:///usr/local/spark/mycode/wordcount/word.txt")
因为Spark采用了惰性机制,在执行转换操作的时候,即使输入了错误的语句,spark-shell也不会马上报错
只有进行action操作时才会进行报错,可以通过以下的进行判断
scala>textFile.first()
写
scala> textFile.saveAsTextFile("file:///usr/local/spark/mycode/wordcount/writeback")
分布式文件系统HDFS的数据读写
读:

scala> val textFile = sc.textFile("hdfs://hadoop102:8020/user/hadoop/test/a.txt") textFile: org.apache.spark.rdd.RDD[String] = hdfs://hadoop102:8020/user/hadoop/test/a.txt MapPartitionsRDD[3] at textFile at <console>:23 scala> textFile.first() res1: String = 1213123131231232suashu scala> val textFile = sc.textFile("/user/hadoop/test/a.txt") textFile: org.apache.spark.rdd.RDD[String] = /user/hadoop/test/a.txt MapPartitionsRDD[10] at textFile at <console>:23 scala> textFile.first() res4: String = 1213123131231232suashu
还有一种直接读的形式
写
scala> textFile.saveAsTextFile("hdfs://hadoop102:8020/user/hadoop/test/writeback.txt") scala> textFile.saveAsTextFile("/user/hadoop/test/writeback.txt")
我默认写入的路径:/user/atguigu/writeback.txt
Json文件的读写
加载
把本地文件系统中的people.json文件加载到RDD中:
val jsonStr = sc.textFile("file:///usr/local/spark/examples/src/main/resources/people.json") scala> jsonStr.foreach(println) {"name":"Justin", "age":19} {"name":"Michael"} {"name":"Andy", "age":30}
解析
Scala中有一个自带的JSON库——scala.util.parsing.json.JSON,可以实现对JSON数据的解析JSON.parseFull(jsonString:String)函数,以一个JSON字符串作为输入并进行解析,如果解析成功则返回一个Some(map: Map[String, Any]),如果解析失败则返回None
示例:
[atguigu@hadoop102 ~]$ mkdir -p ./testjsonapp/src/main/scala [atguigu@hadoop102 ~]$ cd testjsonapp/ [atguigu@hadoop102 testjsonapp]$ cd src/ [atguigu@hadoop102 src]$ cd main/ [atguigu@hadoop102 main]$ cd scala/ [atguigu@hadoop102 scala]$ vim SimpleApp.scala
编写SimpleApp程序
import org.apache.spark.SparkContext import org.apache.spark.SparkContext._ import org.apache.spark.SparkConf import scala.util.parsing.json.JSON object JSONRead { def main(args: Array[String]) { val inputFile = "file:///usr/local/spark/examples/src/main/resources/people.json" val conf = new SparkConf().setAppName("JSONRead") val sc = new SparkContext(conf) val jsonStrs = sc.textFile(inputFile) val result = jsonStrs.map(s => JSON.parseFull(s)) result.foreach( {r => r match { case Some(map: Map[String, Any]) => println(map) case None => println("Parsing failed") case other => println("Unknown data structure: " + other) } } ) } }
[atguigu@hadoop102 scala]$ cd ..
[atguigu@hadoop102 main]$ cd ..
[atguigu@hadoop102 src]$ cd ..
[atguigu@hadoop102 testjsonapp]$ vim simple.sbt
编写simple.sbt
name := "Simple Project" version := "1.0" scalaVersion := "2.12.15" libraryDependencies += "org.apache.spark" %% "spark-core" % "3.2.0" libraryDependencies += "org.scala-lang.modules" %% "scala-parser-combinators" % "1.0.4"
目录结构、打包
[atguigu@hadoop102 testjsonapp]$ find . . ./src ./src/main ./src/main/scala ./src/main/scala/SimpleApp.scala ./simple.sbt [atguigu@hadoop102 testjsonapp]$ /usr/local/sbt/sbt package
Spark运行
[atguigu@hadoop102 testjsonapp]$ /usr/local/spark/bin/spark-submit --class "JSONRead" /home/atguigu/testjsonapp/target/scala-2.12/simple-project_2.12-1.0.jar
结果:
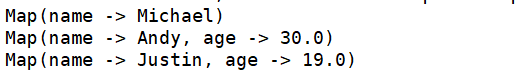
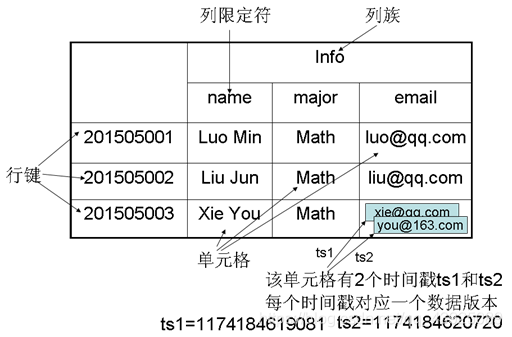
读写Hbase数据
Hbase是一个稀疏、多维度、排序的映射表,这张表的索引是行键,列族、列限定符和时间戳
Hbase需要根据行键,列族、列限定符和时间戳来确定一个单元格,可以视为一个四维坐标,Hbase基于HDFS,由于HDFS不能进行修改,所以使用时间戳生成最新版本来进行修改单元格的数据
[atguigu@hadoop102 bin]$ start-hbase.sh
启动shell
[atguigu@hadoop102 bin]$ hbase shell
停止Hbase
stop-hbase.sh


· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 使用C#创建一个MCP客户端
· ollama系列1:轻松3步本地部署deepseek,普通电脑可用
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· 按钮权限的设计及实现