网易Python后台开发面经
社招。总共3轮技术面+1轮HR面,难度中等。问的问题基本都比较务实,纯技术和八股,没有算法。
一面(40min)
这一面比较水,主要是摸底。
-
自我介绍。
-
简历项目和个人工作介绍。
-
介绍一下数据平台上的数据生命周期。
数据平台生命周期都比较相似,都是数据上报+数据清洗+数据计算+数据存储+数据可视化(或被其他地方消费)
-
数据平台模型评估功能是怎么实现的?
给定数据集,抽样作为验证集(一般都是pandas dataframe)。给定评估算法。评估算法加载模型与数据后启动评估流程,评估结果入库。
-
介绍下权限系统设计方案。
DAC/MAC/RBAC/ABAC,自己参与建设的平台用的是RBAC,区别见文章权限系统设计模型分析
-
权限系统鉴权接口做了哪些优化?
- 鉴权流程优化。
- 缓存优化。
- db优化。反范式设计,增加冗余字段,防止查询多表。
-
django/flask对比。为什么之前会用django开发?
-
对面试岗位的疑问。
二面 (45min)
问了一些比较基础的问题。
-
自我介绍。
-
python源码有读过吗?解释一下deepcopy怎么实现。
递归+变量记录,看这篇文章python deepcopy src analysis
-
解释下闭包和装饰器,装饰器有什么常见用法?
闭包看上去是嵌套函数,其实是延伸了作用域的函数,可以访问不在函数体定义的非全局变量(一般都是在嵌套函数中出现)。而装饰器借助闭包实现,参数一般是另一个函数,可以以某种方式增强被装饰函数的行为,然后返回被装饰的函数或将其替换为一个新的函数。装饰器也可以装饰类(返回一个新类)。装饰器一个很重要的特性是,它是导入模块时运行的。常见用法:flask路由、数据库事务、鉴权等。
-
敏感词匹配算法有了解过吗?
利用敏感词库构建DFA。
三面 (50min)
-
自我介绍。
-
介绍一下数据平台业务,数据生命周期。
-
怎么实现日志采集?
两个方法:1. 写日志文件。2. 写socket报文。
-
从日志文件中收集日志。设计模式:日志->采集器->kafka。按块获取日志,每批次获取1Mb或512kb。当触发发送条件后(时间或文件大小达标),从记录的文件offset开始读取(如果没有,从0开始读取),发送日志时,记录下每次的offset,设定offset为最后一个回车换行,记录redo信息,过滤不采集的日志。获取历史日志文件信息时,不走redo,根据输入的日期收集。当程序重启时,读取上次记录的offset。如果跨天则从当天最新的开始读取。
-
从socket获取报文信息。设计模式:日志->接口->持久化并处理后入库。通过制定端口传输日志,为实现对底层数据库的保护,将接收到的数据持久化(类似kafka)。
-
-
业务什么时候会用到重定向(301/302)?
以前没用过,学习一下。比如商城业务的购物车:如果使用转发,当顾客刷新页面的时候,相当于又重新访问了一次购物车,导致数据出错。所以在购物车业务的时候最好使用重定向。
由于转发在服务器端完成的,重定向是在客户端完成的。所以他俩会有几点区别:- 转发的速度稍微快一些,而重定向速度慢一点
- 转发的是同一次请求;重定向是两次不同请求
- 因为区别2的原因,导致转发地址栏没有变化,而重定向地址栏有变化
- 还是因为区别2的原因,转发必须是在同一台服务器下完成,重定向可以在不同的服务器下完成
HTTP状态码301、302区别:
- 301是永久重定向,在获取新内容的同时也将url替换为重定向后的url。
- 302是临时重定向,只获取新内容,不替换url。
-
常用http动作解释,get和head的区别?
get方法是从服务器获取资源。head和get类似,也是请求从服务器获取资源,服务器的处理机制也是一样的,但服务器不会返回请求的实体数据,只会传回响应头,也就是资源的元信息。HEAD 方法可以看做是 GET 方法的简化版,因为它的响应头与 GET 完全相同,所以可以用在很多并不真正需要资源的场合,避免传输 body 数据的浪费。比如,想要检查一个文件是否存在,只要发个 HEAD 请求就可以了,没有必要用 GET 把整个文件都取下来。再比如,要检查文件是否有最新版本,同样也应该用 HEAD,服务器会在响应头里把文件的修改时间传回来。
-
解释一下deepcopy的实现原理。(见上)
-
介绍下python垃圾回收机制。
《Fluent Python》第8章内容,介绍引用计数、标记清除(解决循环引用)、分代回收(避免不必要的内存回收)。
-
阐述一下mysql聚簇索引和非聚簇索引的区别。
太经典了。
聚簇索引与非聚簇索引区别 -
为什么用B+树而不是B树?
-
遇到最大的表有多大?怎么处理大表?
分库分表。(查询和事务会有什么问题?)
-
怎么实现乐观锁/悲观锁?
-
cursor有用过吗?
-
redis用过吗?str和hash结构有什么不同?
str类型是最简单的类型。str类型的值可以通过
append key value往原来的值追加一段字符串。hash类型是一个str类型的key-value映射表,简单来说就是一个key下面存储了多个key-value。
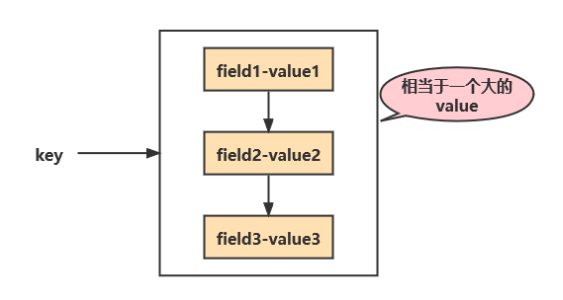
常用命令:
hmset key field1 value1 [field2 value2...],此命令设置一个hash类型值,可以将hmset理解为hash multi-set。hgetall key,获取指定哈希表所有key和value。hkeys key,获取哈希表所有key。hvals key,获取哈希表所有value。hget key field,获取哈希表指定字段值。hdel key field1 [field2...],删除哈希表一个或多个字段。hlen key,获取哈希表中字段数量。
-
阐述redis 主从模式/哨兵模式/cluster模式不同之处。
-
redis cluster集群怎么动态扩容?阐述步骤。
-
redis扩容后,服务端有没有感知?为什么?
-
缓存和db数据不一致,怎么解决?
-
redis内存监控。
-
k8s pod怎么保活?阐述pod存活探针如何配置。
-
怎么保证自己设计的接口高性能且高可用?
-
实习的时候是怎么快速适应工作的?怎么学习不熟悉的知识?
HR面 (35min)
-
个人发展规划。
-
怎么看待网易的岗位和之前的岗位?
-
辞职在家时间分配如何?拿了几个offer?给了多少?
-
预期薪酬。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号