
个人项目:论文查重
| 这个作业属于哪个课程 | https://edu.cnblogs.com/campus/gdgy/CSGrade22-34 |
|---|---|
| 这个作业要求在哪里 | https://edu.cnblogs.com/campus/gdgy/CSGrade22-34/homework/13229 |
| 这个作业的目标 | 独立完成一个论文查重的个人项目;在项目开发中学习PSP表格的使用;学习使用Github仓库进行代码管理;学习使用Code Quality Analysis工具分析代码,修改有警告的代码;学习使用性能分析工具Studio Profiling Tools对代码进行性能分析,对算法进行改进优化;学习对代码进行单元测试。 |
一、项目仓库地址
https://github.com/J-Developer-backend/J-Developer-backend项目的具体内容存放在3122004739文件夹中
二、使用PSP表格预估各模块用时
- PSP(Personal Software Process)表格是卡内基梅隆大学软件工程研究所(Software Engineering Institute, SEI)开发的一套个人软件过程改进方法。PSP是一套旨在帮助软件开发人员提高个人生产率和产品质量的工具和方法。它包括一系列的表格、指南和练习,用于帮助开发者跟踪和改进他们的工作过程。在开发该项目时,也使用了PSP表格辅助项目开发,该表格估计了在程序的各个模块的开发上耗费的时间以及实际开发的耗时。
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) |
|---|---|---|
| Planning | 计划 | 60 |
| ·Estimate | ·估计这个任务需要多少时间 | 60 |
| Development | 开发 | 1440 |
| ·Analysis | ·需求分析(包括学习新技能) | 120 |
| ·Design Spec | ·生成设计文档 | 60 |
| ·Design Review | ·设计复审 | 60 |
| ·CodingStandard | ·代码规范(为目前的开发制定合适的规范) | 60 |
| ·Design | ·具体设计 | 600 |
| ·Coding | ·具体编码 | 300 |
| ·Code Review | ·代码复审 | 120 |
| ·Test | ·测试(自我测试,修改代码,提交修改) | 120 |
| reporting | 报告 | 300 |
| ·Test Repor | ·测试报告 | 120 |
| ·Size Measurement | ·计算工作量 | 120 |
| ·Postmortem & Process Improvement Plan | ·事后总结,并提出过程改进计划 | 60 |
| 合计 | 1800 |
三、需求分析
1、具体需求
- 该项目要求设计一个论文查重算法,可以根据一个原文文件和一个抄袭版文件给出它们的重复率,并输出到答案文件中,要求答案文件中输出的答案为浮点型,精确到小数点后两位。该需求涉及文件的读写操作以及算法的设计。
2、输入输出要求
- 由于该项目主要是文件操作,所以输入输出采用文件输入输出,规范如下:
- 从命令行参数给出:论文原文的文件的绝对路径。
- 从命令行参数给出:抄袭版论文的文件的绝对路径。
- 从命令行参数给出:输出的答案文件的绝对路径。
以Java为例,运行项目时,应在项目打包的jar包的目录下打开控制台窗口,输入下面的命令:
java -jar main.jar [原文文件] [抄袭版论文的文件] [答案文件]
3、代码规范
- 需要使用代码分析工具将项目的代码消除所有的警告以及规范代码变量、函数的命名。
4、功能测试与性能分析
- 项目应该通过样例的测试,至少能输出结果。
- 需要使用性能分析工具对程序进行性能分析,改进程序性能。
四、开发环境
- IntelliJ IDEA——集成开发环境
- Java17
- Maven——依赖管理工具
- HanLP——Java中文分词工具
- JUnit——测试工具
- IntelliJ Profiler——性能分析工具
五、模块接口的设计与实现
1、文件读写
- 该论文查重项目涉及到对3个文件的操作,分别是对原文件和抄袭文件的读取以及答案文件的写入。设计文件读写类FileInterface管理文件的读写,提供文件读写操作的方法。该模块可以使用Java的IO接口简单实现。
2、文件预处理
- 在文本内容进行查重前,因该对文本内容进行预处理,将不影响重复率的因素剔除掉。由于内容基本属于中文文本,所以要清除掉内容中的中式符号以及空格。设计文本处理工具类TextParserUtil对文本进行预处理,使用String类的自身API可以简单实现。
3、SimHash算法
- SimHash算法的核心思想是将文本的特征向量映射为一个固定长度的二进制哈希值,该项目设计该二进制哈希值的长度为64位,通过比较两个哈希值的海明距离来判断文本的相似度。SimHash算法的优点在于计算速度快、空间效率高,适合实时性和大规模数据处理,它通过将文本转换为固定长度的哈希值,大大降低了存储和计算成本,同时保持了较高的准确性和效率。但它也有局限性,如在处理短文本时准确性可能不足,且存在一定的碰撞概率。
- SimHash算法的步骤如下:
- (1)分词:将文本进行分词处理,移除停用词,并提取关键词。
- (2)计算TF-IDF:为每个关键词计算TF-IDF值,以确定其在文本中的重要性。
- (3)生成哈希向量:对每个关键词计算哈希值,通常是一个64位的二进制数。
- (4)加权合并:根据每个词的权重(如TF-IDF值),对哈希值的每一位进行加权,正权重对应位为1时累加,为0时累减;负权重则相反。
- (5)生成SimHash值:将加权后的哈希向量进行合并,如果某一位的累加和大于零,则该位为1,否则为0,从而得到最终的SimHash值。
- (6)计算相似度:通过比较两个SimHash值的汉明距离来估计文本的相似度,汉明距离越小,文本越相似。
- SimHash算法的实现:设计生成SimHash值的工具类SimHashUtil提供simHash方法获取文本的SimHash值。
- 使用hanPL的标准分词器StandardTokenizer对文本分词。
- 使用HashMap存储词性权重,key为词性,value为权重
- 设计getWordHash方法生成分词的哈希值
/**
* 对单个的分词进行hash计算;
* @param word 分词
* @return 分词的hash
*/
private static BigInteger getWordHash(String word) {
char[] wordCharArray = word.toCharArray();
BigInteger x = BigInteger.valueOf(((long) wordCharArray[0]) << 7);
BigInteger m = new BigInteger("1000003");
BigInteger mask = new BigInteger("2").pow(HASH_BITS).subtract(new BigInteger("1"));
for (char item : wordCharArray) {
BigInteger temp = BigInteger.valueOf(item);
x = x.multiply(m).xor(temp).and(mask);
}
x = x.xor(new BigInteger(String.valueOf(word.length())));
if (x.equals(new BigInteger(HASH_LMT))) {
x = new BigInteger("-2");
}
return x;
}
- 根据分词的哈希值加权合并到文本的哈希向量中
for (int i = 0; i < HASH_BITS; i++) {
BigInteger bitmask = new BigInteger("1").shiftLeft(i);
//添加权重
int weight = 1;
if (weightOfNature.containsKey(nature)) {
weight = weightOfNature.get(nature);
}
if (hash.and(bitmask).signum() != 0) {
// 这里是计算整个文档的所有特征的向量和
vector[i] += weight;
} else {
vector[i] -= weight;
}
}
}
- 利用文本向量生成SimHash值
BigInteger simHash = new BigInteger("0");
for (int i = 0; i < HASH_BITS; i++) {
if (vector[i] >= 0) {
simHash = simHash.add(new BigInteger("1").shiftLeft(i));
}
}
- 计算海明距离以及相似度(下模块实现)
4、计算海明距离和相似度
- 海明距离(Hamming Distance)是信息论中的一个重要概念,用于衡量两个等长字符串之间的差异。它定义为在相同长度的两个字串中,对应位置上不同字符的个数。换句话说,汉明距离就是在将一个字符串变换成另一个字符串时,需要进行的最小单字符替换次数。设计海明距离计算工具类HammingUtil实现海明距离以及相似度的计算。
/**
* 计算海明距离,海明距离越小说明越相似,等于0时证明完全相似
* @param simHash1 文本1的文本指纹
* @param simHash2 文本2的文本指纹
* @return 海明距离
*/
public static int hammingDistance(BigInteger simHash1, BigInteger simHash2) {
BigInteger m = new BigInteger("1")
.shiftLeft(SimHashUtil.HASH_BITS)
.subtract(new BigInteger("1"));
BigInteger x = simHash1.xor(simHash2).and(m);
int distance = 0;
while (x.signum() != 0) {
distance += 1;
x = x.and(x.subtract(new BigInteger("1")));
}
return distance;
}
/**
* 根据海明距离返回相似度
* @param distance 海明距离
* @return 相似度
**/
public static double getSimilarity(int distance) {
return 1 - (double) distance / SimHashUtil.HASH_BITS;
}
5、主函数
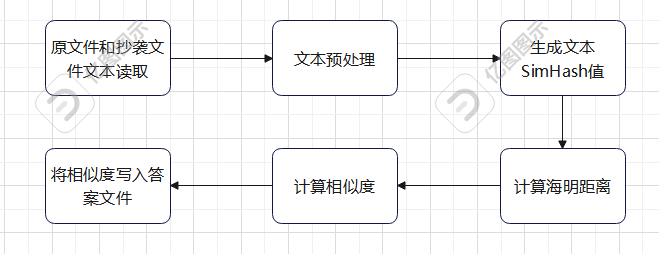
-
流程图
![]()
-
代码实现
public static void main(String[] args) {
//命令参数获取
String originFileName = args[0];
String copyFileName = args[1];
String answerFileName = args[2];
//文件读写对象
FileInterface fileInterface = new FileInterface(originFileName, copyFileName, answerFileName);
try {
// 原文件和抄袭文件文本读取
String originText = fileInterface.readOriginFile();
String copyText = fileInterface.readCopyFile();
// 文本预处理
String originContext = TextParserUtil.clean(originText);
String copyContext = TextParserUtil.clean(copyText);
// 生成文本指纹
BigInteger originSimHash = SimHashUtil.simHash(originContext);
BigInteger copySimHash = SimHashUtil.simHash(copyContext);
// 计算海明距离
int hammingDistance = HammingUtil.hammingDistance(originSimHash, copySimHash);
// 计算相似度
double similarity = HammingUtil.getSimilarity(hammingDistance);
// 将相似度写入答案文件
fileInterface.writeAnswerFile(similarity, false);
} catch (IOException e) {
System.err.println("文件路径错误");
}
}
六、模块接口的性能测试
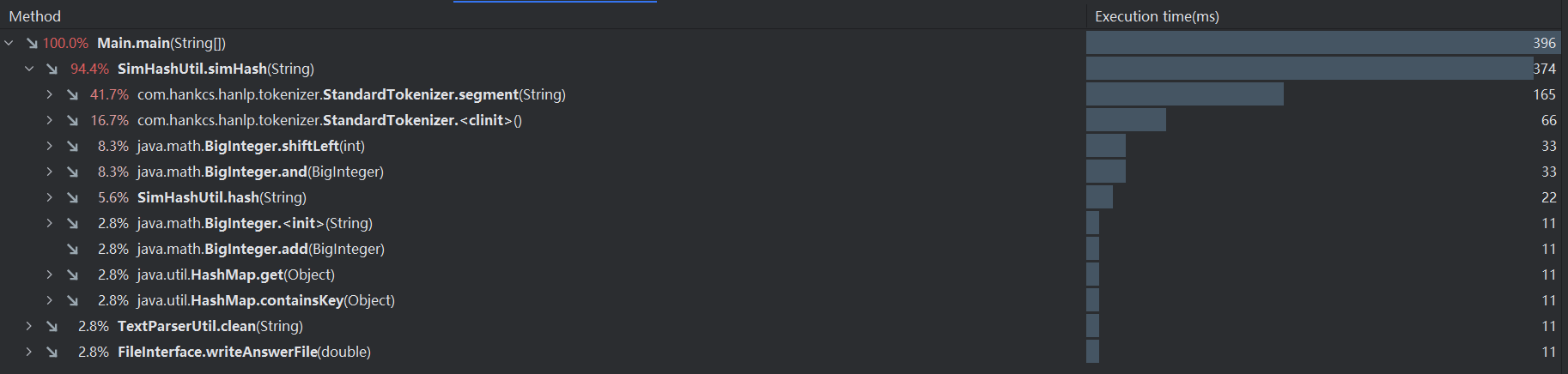
-
使用性能分析工具IntelliJ Profiler对项目程序进行分析,得到以下结果:
-
各函数调用占据CPU的比例以及时间
![]()
![]()
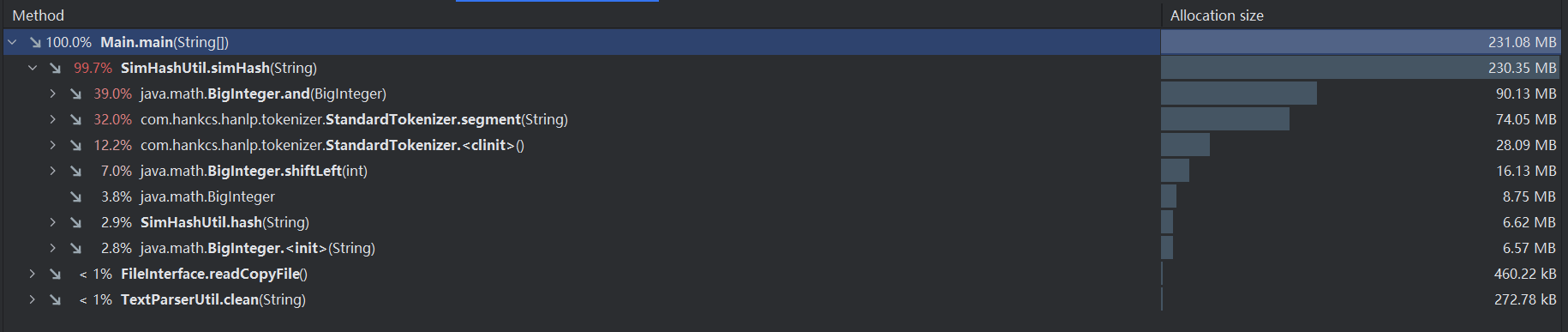
-
各函数调用占据内存的比例以及空间
![]()
![]()
-
-
由上面的性能分析图可知,方法SimHashUtil.simHash占据的CPU时间和内存空间都是最大的,是消耗最大的方法,该方法是获取文本的SimHash值。而在方法SimHashUtil.simHash中,方法com.hankcs.hanlp.tokenizer.StandardTokenizer.segment是分词操作,是方法SimHashUtil.simHash主要操作,占据了较大的CPU时间和内存空间。因此,若要对项目的性能进行优化,则需要对分词操作做出优化,使用效率更高的分词器。


七、计算模块部分单元测试展示
- 使用JUnit工具进行单元测试。
- 单元测试的设计
- 测试样例中包含原文件和抄袭文件,方便测试。
- 首先通过通过测试样例的路径获取到原文件和抄袭文件的路径,读取文件。
- 对每个抄袭文件执行与主函数相同逻辑的测试。
- 输出每个抄袭文件的答案到文件中,并打印到控制台。
- 单元测试代码
- 单元测试的设计
/**
* 此单元测试仅适用当前项目测试样例中的文件命名方式,即原文件:orig.txt,抄袭文件:xx_xx_xx.txt
* 答案文件中的重复率数据的顺序与抄袭文件按名称排序相同
* @throws Exception yc异常
*/
@org.junit.Test
public void test() throws Exception {
File parentFile = new File("D:\\GDUTLearning\\大三上\\软件工程\\作业\\个人项目\\3122004739\\测试文本");
//选出原文件和抄袭文件
File[] originFiles = parentFile.listFiles((fileName) -> fileName.getName().contains("orig.txt"));
File[] copyFiles = parentFile.listFiles((fileName) -> fileName.getName().contains("_"));
assert originFiles != null;
assert copyFiles != null;
Arrays.sort(copyFiles);
//取出原文件地址
String originFileName = originFiles[0].getAbsolutePath();
//设置答案文件地址
String answerFileName = parentFile.getAbsolutePath() + "\\ans.txt";
File ansFile = new File(answerFileName);
if (ansFile.exists()) {
if (ansFile.delete()) {
System.out.println("已清除上次测试答案数据");
}
}
//对每个抄袭文件测试
for (File copyFileName : copyFiles) {
FileInterface fileInterface = new FileInterface(originFileName, copyFileName.getAbsolutePath(), answerFileName);
// 原文件和抄袭文件文本读取
String originText = fileInterface.readOriginFile();
String copyText = fileInterface.readCopyFile();
// 文本预处理
String originContext = TextParserUtil.clean(originText);
String copyContext = TextParserUtil.clean(copyText);
// 生成文本指纹
BigInteger originSimHash = SimHashUtil.simHash(originContext);
BigInteger copySimHash = SimHashUtil.simHash(copyContext);
// 计算海明距离
int hammingDistance = HammingUtil.hammingDistance(originSimHash, copySimHash);
// 计算相似度
double similarity = HammingUtil.getSimilarity(hammingDistance);
// 将相似度输出
fileInterface.writeAnswerFile(similarity, true);
System.out.println("原文件:" + originFileName);
System.out.println("抄袭文件:" + copyFileName.getAbsolutePath());
System.out.println("重复率:" + similarity);
}
}
- 测试覆盖率
![]()
- 测试结果

| 原文件 | 抄袭文件 | 重复率 |
|---|---|---|
| orig.txt | orig_0.8_add.txt | 0.91 |
| orig.txt | orig_0.8_del.txt | 0.92 |
| orig.txt | orig_0.8_dis_1.txt | 0.95 |
| orig.txt | orig_0.8_dis_10.txt | 0.89 |
| orig.txt | orig_0.8_dis_15.txt | 0.84 |
八、计算模块部分异常处理说明
- 该项目只有在文件路径错误时,才会发生文件读写异常,如果文件路径错误,该异常无法避免,所以处理方式为终止程序并给出提示。
九、使用PSP表格记录各模块实际用时
| PSP2.1 | Personal Software Process Stages | 实际耗时(分钟) |
|---|---|---|
| Planning | 计划 | 50 |
| ·Estimate | ·估计这个任务需要多少时间 | 50 |
| Development | 开发 | 1440 |
| ·Analysis | ·需求分析(包括学习新技能) | 180 |
| ·Design Spec | ·生成设计文档 | 30 |
| ·Design Review | ·设计复审 | 30 |
| ·CodingStandard | ·代码规范(为目前的开发制定合适的规范) | 60 |
| ·Design | ·具体设计 | 660 |
| ·Coding | ·具体编码 | 360 |
| ·Code Review | ·代码复审 | 120 |
| ·Test | ·测试(自我测试,修改代码,提交修改) | 180 |
| reporting | 报告 | 360 |
| ·Test Repor | ·测试报告 | 120 |
| ·Size Measurement | ·计算工作量 | 120 |
| ·Postmortem & Process Improvement Plan | ·事后总结,并提出过程改进计划 | 120 |
| 合计 | 2030 |
附:代码规范

项目发行版地址
https://github.com/J-Developer-backend/J-Developer-backend/releases/tag/3122004739-paper-check-1.0可以再次地址下载release.zip以及完整项目的代码。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号