InnoDB的辅助索引叶子节点存储主键键值的原因整理
InnoDB的所有辅助(二级)索引都引用主键作为data域。例如,下图为定义在非主键上的一个辅助索引:
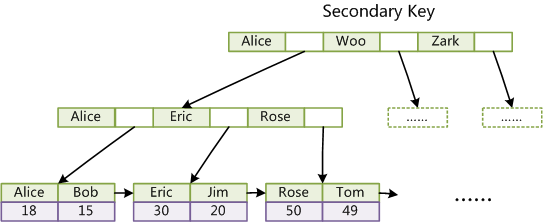
InnoDB表是基于聚簇索引建立的。因此InnoDB 的索引能提供一种非常快速的主键查找性能。不过,它的辅助索引(Secondary Index, 也就是非主键索引)也会包含主键列, 所以,如果主键定义的比较大,其他索引也将很大。如果想在表上定义很多索引,则争取尽量把主键定义得小一些。 InnoDB 不会压缩索引。
文字符的ASCII码作为比较准则。聚集索引这种实现方式使得按主键的搜索十分高效,但是辅助索引搜索需要检索两遍索引:首先检索辅助索引获得主键,然后用主键到主索引中检索获得记录。而InnoDB的辅助索引叶子节点存储主键键值的原因主要有以下两点:
1)减少了出现行移动或者数据页分裂时二级索引的维护工作(当数据需要更新的时候,二级索引不需要修改,只需要修改聚簇索引,一个表只能有一个聚簇索引,其他的都是二级索引,这样只需要修改聚簇索引就可以了,不需要重新构建二级索引)。
2)不同存储引擎的索引实现方式对于正确使用和优化索引都非常有帮助,例如知道了InnoDB的索引实现后,就很容易明白为什么不建议使用过长的字段作为主键,因为所有辅助索引都引用主索引,过长的主索引会令辅助索引变得过大。 再例如, 用非单调的字段作为主键在InnoDB中不是个好主意,因为InnoDB数据文件本身是一颗B+树,非单调的主键会造成在插入新记录时数据文件为了维持B+树的特性而频繁的分裂调整,十分低效,而使用自增字段作为主键则是一个很好的选择。
本文来自博客园,作者:Jcpeng_std,转载请注明原文链接:https://www.cnblogs.com/JCpeng/p/15272884.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号