
Springboot快速整合JPA实现增删查改
简单看看JPA依赖包的主要成分,可以看到里面有个熟悉的框架 hibernate:
不多说,直接开始整合。
这次快速整合示例的目录结构:

先创建一个springboot项目,在pom.xml中加入依赖:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<!--mysql连接-->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>
<!--JPA-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
<!--lombok-->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.16.10</version>
<scope>provided</scope>
</dependency>接着是application.yml文件:
#服务端口
server:
port: 8055
spring:
datasource:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/testdemo?useSSL=false&useUnicode=true&characterEncoding=UTF-8&serverTimezone=GMT%2B8&zeroDateTimeBehavior=convertToNull
hikari: # springboot 2.0 整合了hikari ,据说这是目前性能最好的java数据库连接池
username: root
password: root
minimum-idle: 5 # 最小空闲连接数量
idle-timeout: 180000 # 空闲连接存活最大时间,默认600000(10分钟)
maximum-pool-size: 10 # 连接池最大连接数,默认是10
auto-commit: true # 此属性控制从池返回的连接的默认自动提交行为,默认值:true
pool-name: MyHikariCP # 连接池名称
max-lifetime: 1800000 # 此属性控制池中连接的最长生命周期,值0表示无限生命周期,默认1800000即30分钟
connection-timeout: 30000 # 数据库连接超时时间,默认30秒,即30000
connection-test-query: SELECT 1 #连接池每分配一条连接前执行的查询语句(如:SELECT 1),以验证该连接是否是有效的。如果你的驱动程序支持 JDBC4,HikariCP 强烈建议我们不要设置此属性
jpa:
hibernate:
ddl-auto: create # 第一次建表create 后面用update,要不然每次重启都会新建表
show-sql: true #打印执行的sql语句
database-platform: org.hibernate.dialect.MySQL5InnoDBDialect #设置数据库方言 记住必须要使用 MySQL5InnoDBDialect 指定数据库类型对应InnoDB ;如果使用MySQLDialect 则对应的是MyISAM
上面的配置项,需要注意的是,
①数据库连接池,这次例子里面采用的是springboot2.0版本后默认整合的hikari连接池,想多了解的可以去网上额外了解下这个数据库连接池的优劣。
②ddl-auto,
create:每次运行程序时,都会重新创建表,故而数据会丢失create-drop:每次运行程序时会先创建表结构,然后待程序结束时清空表upadte:每次运行程序,没有表时会创建表,如果对象发生改变会更新表结构,原有数据不会清空,只会更新(推荐使用)validate:运行程序会校验数据与数据库的字段类型是否相同,字段不同会报错none: 禁用DDL处理
③database-platform,这项是配置对应连接数据库的方言,也就是语法、规则等等。 这里我们使用mysql数据库,方言项记得使用MySQL5InnoDBDialect,这样才能对应起InnoDB。
好,接下来创建User.java(需要注意的是主键自增的设置项,IDENTITY):
import javax.persistence.Entity;
import javax.persistence.GeneratedValue;
import javax.persistence.GenerationType;
import javax.persistence.Id;
/**
* @Author : JCccc
* @CreateTime : 2019/10/12
* @Description :
**/
@Data
@Entity // 该注解声明一个实体类,与数据库中的表对应
@ToString
public class User {
@Id // 表明id
@GeneratedValue(strategy = GenerationType.IDENTITY) // 自动生成
private Long id ;
private String name ;
}
- @Entity:标注在实体类上告诉JPA这是一个实体类
- @Table:可以给表命名,也可以使用默认的,即实体类名就是表名
- @Id:主键注解
- @GeneratedValue(strategy = GenerationType.IDENTITY) //自增主键
- @Column: 标注在字段上,可以指定字段名和长度 .
然后是mapper层,UserMapper.java:
import com.jc.gracedemo.pojo.User;
import org.springframework.data.jpa.repository.JpaRepository;
import org.springframework.stereotype.Component;
/**
* @Author : JCccc
* @CreateTime : 2019/10/12
* @Description :
**/
@Component
public interface UserMapper extends JpaRepository<User,Long> {
/*
* 我们在这里直接继承 JpaRepository
* 这里面已经有很多现场的方法了,可以直接通过UserMapper.xxx()直接使用
* 这也是JPA的一大优点
*
* */
}在mapper层,因为我们使用的是jpa,继承了JpaRepository,里面基本的增删查改方法都是已经提供的,所以除了我们自己额外需要扩展的业务方法,基本不用写:
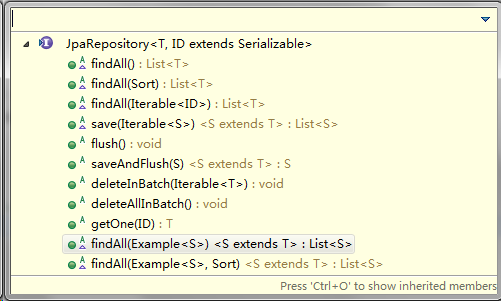
而且JpaRepository继承的分页PagingAndSortingRepository:
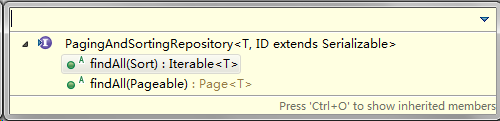
而PagingAndSortingRepository继承了CrudRepository:
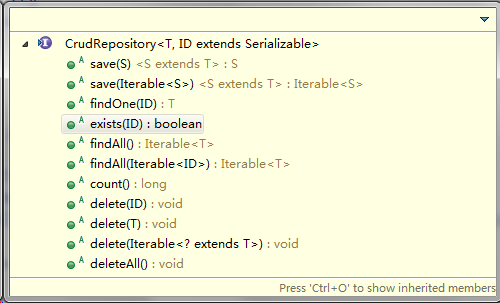
所以非常多的方法都是可以直接使用,非常方便。
接下来是service层,UserService.java:
/**
* @Author : JCccc
* @CreateTime : 2019/10/12
* @Description :
**/
public interface UserService {
List<User> findAll();
User getOne(Long id);
}
对应的impl:
/**
* @Author : JCccc
* @CreateTime : 2019/10/12
* @Description :
**/
@Service
public class UserServiceImpl implements UserService {
@Autowired
private UserMapper userMapper;
@Override
public List<User> findAll() {
// 这里我们就可以直接使用 findAll 方法 这个findAll方法来自JpaRepository
return userMapper.findAll();
}
@Override
public User getOne(Long id) {
return userMapper.getOne(id);
}
}然后是接口测试,UserController.java:
/**
* @Author : JCccc
* @CreateTime : 2019/10/12
* @Description :
**/
@RestController
public class UserController {
@Autowired
private UserService userService;
@GetMapping("/list")
public List<User> findAll() {
return userService.findAll();
}
@GetMapping("/getOne/{id}")
public String getOne(@PathVariable("id") Long id) {
return userService.getOne(id).toString();
}
}
好,到这里,SpringBoot整合JPA已经完成,接下来测试下看看效果:
把项目运行起来,可以看到控制台里输出了关于自动创建数据库表的相关操作日志:

看下数据库:

PS:相关的实体类表都建完后,记得修改yml里面的配置项,使用update。
我们往这个表里面手动添加一些数据用于测试, 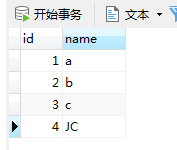
调用接口 /list:

调用接口 /getOne/{id}:

另外,插入使用的save方法,如:
save也是JpaRepository提供,所以直接在service层调用即可。
@Override
public User save(User user) {
return userMapper.save(user);
}更新的话,可以使用@Query ,@Modifying ,@Transactional ,如 :
@Transactional
@Modifying
@Query(value="update user set name=(:name) where id=(:id)",nativeQuery = true)
int updateById(@Param("name") String name,@Param("id") Long id);其实JpaRepository,细心看,会发现,里面提供了基本的查询、插入、删除,但是好像没有update字样。实际上也囊括在save这个方法里面了,如果数据库已经存在,则会根据主键进行更新数据。那么也就是说可以通过传递对象,通过set方法修改字段值,再调用save达到更新的效果。
OK,Springboot 整合JPA简单的使用就到此。
想了解多表联合查询、分页查询等可以看我其他的相关JPA文章。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号