
1、定义
文件数据
文件数据包括元信息与实际数据
文件存储在硬盘上,硬盘最小的存储单位是“扇区”,每个扇区存储512字节
一个文件必须占有一个inode,但至少占用一个block
block(块)
连续的八个扇区组成一个block(4k)
是文件存取的最小单位
操作系统读取硬盘的时候,是一次性连续读取多个扇区,即一个块一个快读取的
inode(索引节点)
中文译名“索引节点”,也叫i节点
用于存储文件元信息
inode不包含文件名,每一个inode都有一个号码,操作系统用inode号码来识别不同的文件。Linux系统内部不使用文件名,而使用inode号码来识别文件,对于系统来说,文件名只是inode号码便于识别的别称,文件名和inode号码是一一对应关系,每个inode号码对应一个文件名,所以,当用户在Linux系统中试图访问一个文件时,系统会先根据文件名去查找它对应的inode号码,通过inode号码,获取inode信息,根据inode信息,看该用户是否具有访问这个文件的权限,如果有,就指向相对应的数据block,并读取数据
inode包含文件的元信息
(1)、文件的字节数
(2)、文件拥有者的User ID
(3)、文件的Group ID
(4)、文件的读、写、执行权限
(5)、文件的时间戳
2、Linux系统文件三个主要的时间属性
atime(accesstime)
当使用这个文件的时候就会更新这个时间。
mtime(modifcation time)
当修改文件内容数据的时候,就会更新这个时间,而更改权限或者属性,mtime不会改变,这就是和ctime的区别。
ctime(status time)
当修改文件的权限或者属性的时候,就会更新这个时间,ctime并不是create time,更像是change time。只有当更新文件的属性或者权限的时候才会更新这个时间,但是更改内容的话是不会更新这个时间。
3、inode的号码
用户通过文件名打开文件时,系统内部的过程
(1)、系统找到这个文件名对应的inode号码
(2)、根据inode号码,获取inode信息
(3)、根据inode信息,找到文件数据所在的block,读出数据
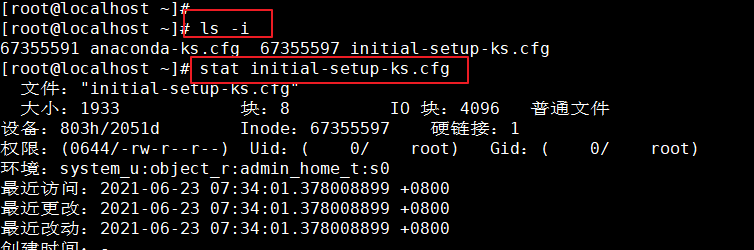
查看inode号码的方法
(1)、ls -i命令:查看文件名对应的inode号码
(2)、stat命令:查看文件inode信息中的inode号码
4、inode的大小
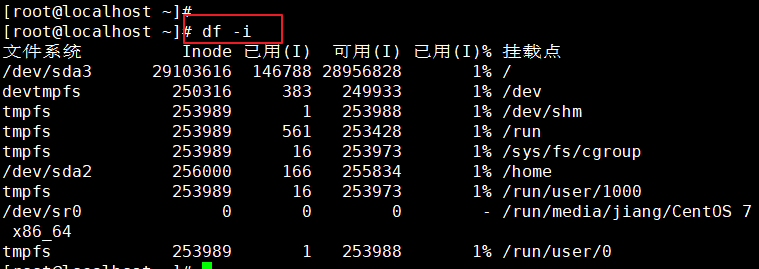
inode也会消耗硬盘空间,所以格式化的时候,操作系统自动将硬盘分为两个区域。一个是数据区,存放文件数据,另一个是inode区,存放inode所包含的信息。每个inode的大小一般是128字节或256字节。通常情况下不需要关注单个inode的大小,而是需要重点关注inode总数。inode的总数在格式化时就给定了,执行 df -i 命令即可查看每个硬盘分区对应的inode总数和已经使用的inode数量。
5、inode的特殊作用
由于inode号码与文件名分离,导致Linux系统具备以下几种特有现象:
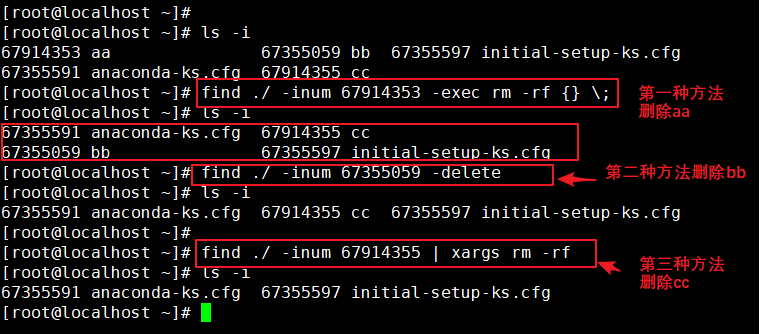
(1)、文件名包含特殊字符,可能无法正常删除,这时直接删除inode,能够起到删除文件的作用。
(2)、移动文件或重命名文件,只是改变文件名,不影响inode号码。
(3)、打开一个文件以后,系统就以inode号码来识别这个文件,不再考虑文件名。
(4)、文件数据被修改保存后,会生成一个新的inode号码。
通过删除inode,起到删除文件的作用有以下三种方法
为文件或目录建立链接文件
链接文件分类
硬链接: ln 源文件 目标位置
软链接: ln 【-s】源文件或目录...链接文件或目录位置
| 软连接 | 硬链接 | |
| 删除原始文件后 | 失效 | 仍旧可用 |
| 使用范围 | 适用于文件或目录 | 只可用于文件 |
| 保存位置 | 与原始文件可以位于不同的文件系统中 |
必须与原始文件在同一个文件系统 (如一个Linux分区)内 |
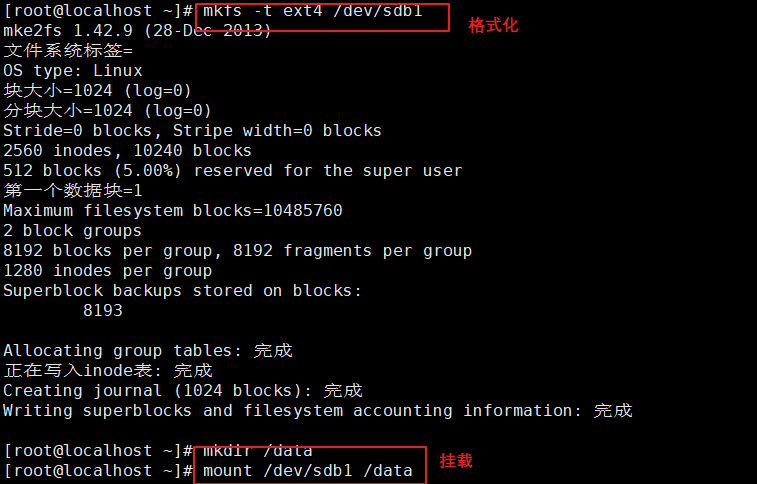
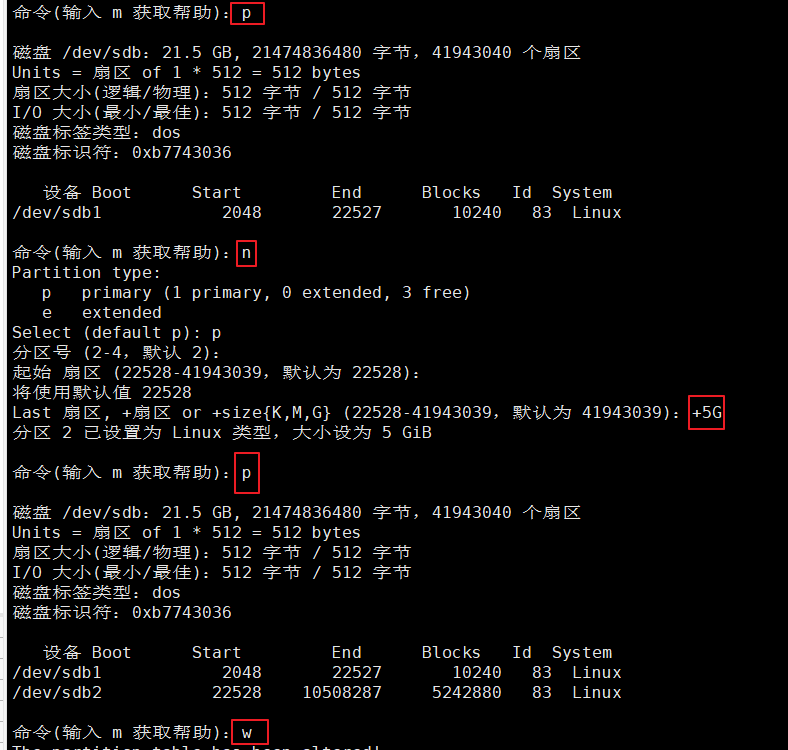
#使用fdisk创建分区/dev/sdb1,分区大小30M即可
fdisk /dev/sdb
mkfs -t ext4 /dev/sdb1
mkdir /data
mount /dev/sdb1 /data
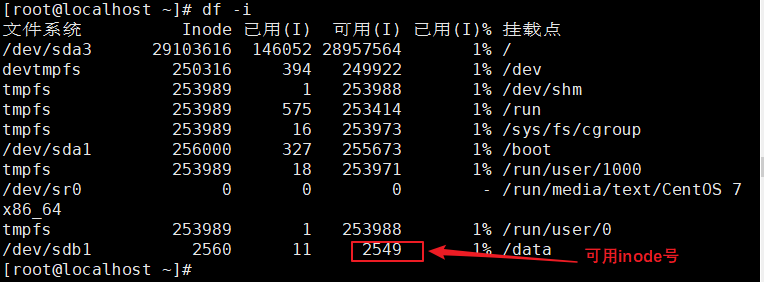
df -i
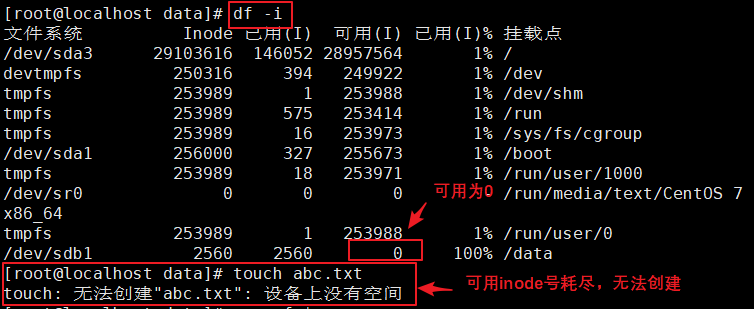
#模拟inode节点耗尽故障
for ((i=1; i<=7680; i++));do touch /data /file$i;done
df -i
df -hT
#删除文件恢复
rm -rf /data/*
df -i
df -hT
操作如下
添加一块硬盘,将硬盘分为一个10M的主分区
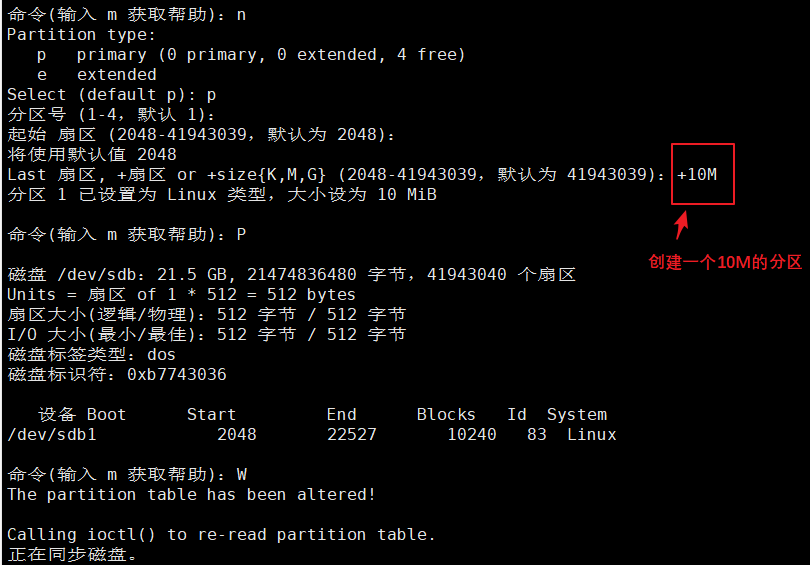
格式化,并挂载
查看可用inode号
用for循环模拟inode节点耗尽故障

查询inode号,并创建文件验证是否可以
1、创建分区
2、分区格式化,并挂载

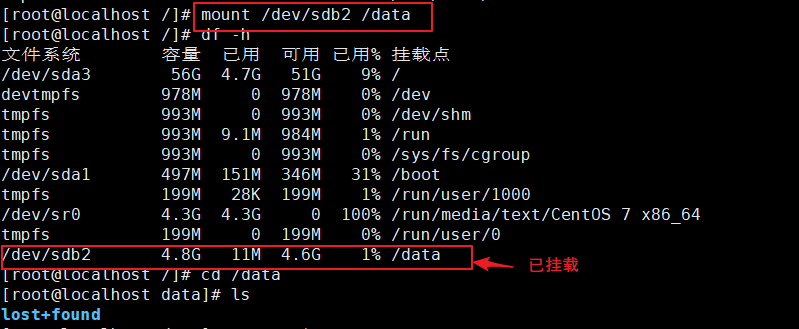
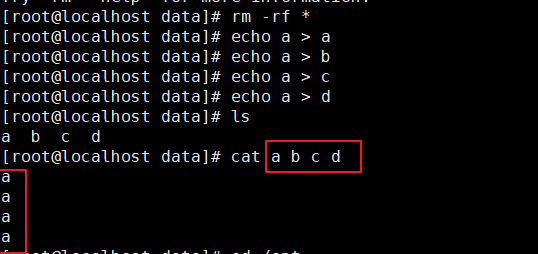
3、在data目录中穿件文件
4安装软件到opt目录中,并解压


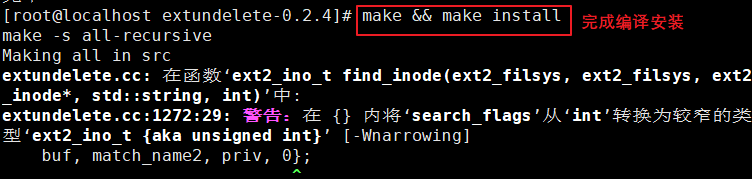
5、安装依赖包

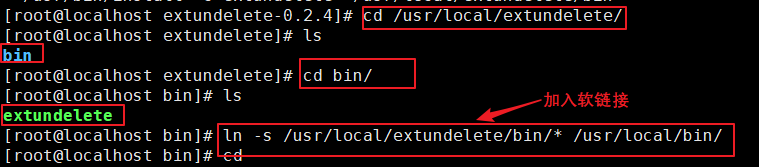
6.编译安装

7、加入软链接,并查看



8、模拟删除并执行恢复操作

9、恢复

CentOS 7系统默认采用xfs类型文件,xfs类型的文件可用xfsdump与xfsrestore工具进行备份恢复。xfsdump的备份级别有两种:0表示完全备份;1-9表示增量备份。xfsdump的备份级别默认为0。
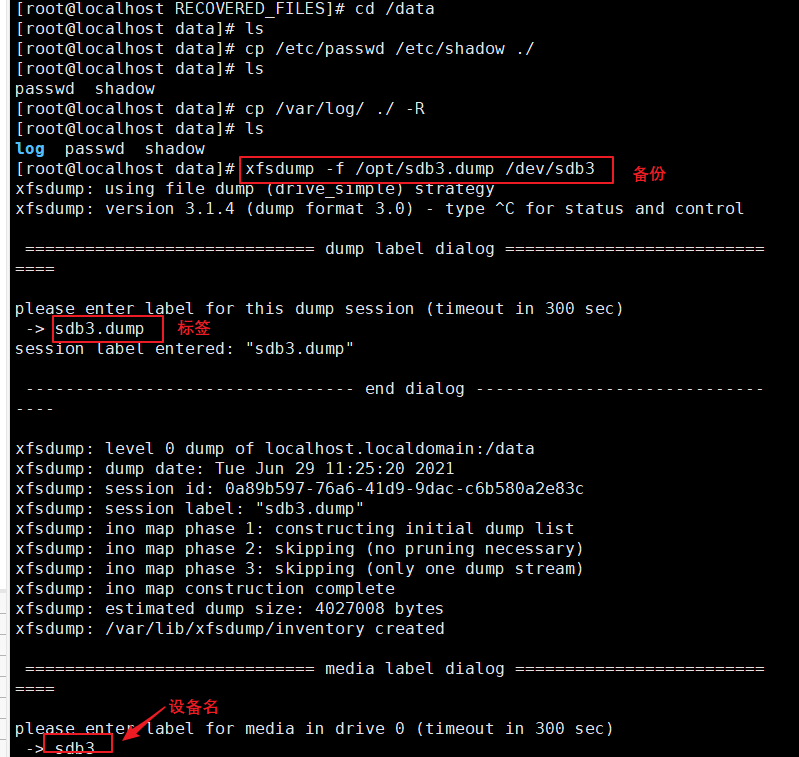
xfsdump的命令格式为:xfsdump -f 备份存放位置 要备份的路径或设备文件
xfsdump命令的常用选项
-f:指定备份文件目录
-L:指定标签session label
-M:指定设备标签media label
-s:备份单个文件,-s后面不能直接跟路径
xfsdump使用限制
1、只能备份已挂载的文件系统
2、必须使用root的权限才能操作
3、只能备份XFS文件系统
4、备份后的数据只能让xfsrestore解析
5、不能备份两个具有相同UUID的文件系统(可用blkid命令查看)
实验操作如下:
1、查看是否安装xfsdump

2、进行分区,格式化,并挂载
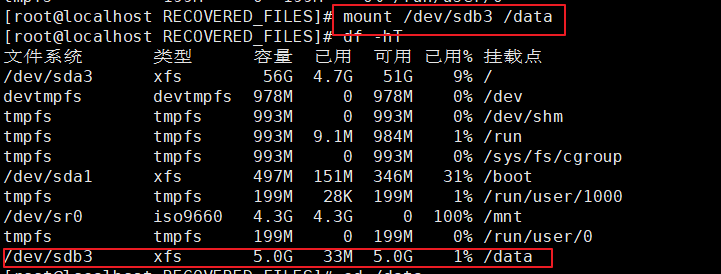
3、复制文件,并进行备份
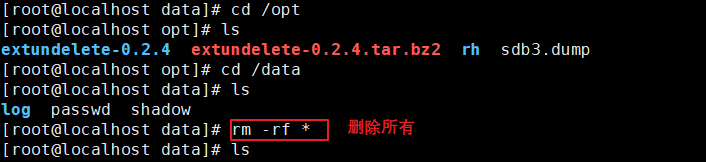
4、模拟数据丢失
5、数据恢复



1、日志文件的功能
用于记录系统,程序运行中发生的各种事件
通过阅读日志,有助于诊断和解决系统故障
2、日志文件的分类
(1)、内核及系统日志
由系统服务reyslog统一进行管理,日志格式基本相似
主配置文件/etc/reysiog.conf
(2)、用户日志
记录系统用户登录及退出系统的相关信息
(3)、程序日志
由各种应用程序独立管理的日志文件,记录格式不统一
3、日志文件默认位置: /var/log目录下
常见的一些日志文件
内核及公共消息日志
/var/log/messages:记录Linux内核消息及各种应用程序的公共日志信息,包括启动、IO错误、网络错误、程序故障等。对于为使用独立日志文件的应用程序过服务,一般都可以从该日志文件中获得相关的事件记录信息。
计划任务日志
/var/log/cron:记录crond计划任务产生的事件信息
系统引导日志
/var/log/dmesg:记录Linux系统在引导过程中的各种事件信息
邮件系统日志
/var/log/maillog:记录进入或发出系统的电子邮件活动
用户登录日志
/var/log/secure:记录用户认证相关的安全事件信息
/var/log/lastlog:记录每个用户最近的登录事件。二进制格式
/var/log/wtmp:记录每个用户登录、注销及系统启动和停机事件。二进制格式
/var/run/utmp:记录失败的、错误的登录尝试及验证事件。二进制格式
4、日志消息的级别
| 级号 | 消息 | 级别 | 说明 |
| 0 | EMERG | 紧急 | 会导致主机系统不可用的情况 |
| 1 | ALERT | 警告 | 必须马上采取措施解决的问题 |
| 2 | CRIT |
严重 | 比较严重的情况 |
| 3 | ERR |
错误 | 运行出现错误 |
| 4 | WARNING | 提醒 | 可能会影响系统动能的事件 |
| 5 | NOTICE | 注意 | 不会影响系统但值得注意 |
| 6 | INFO | 信息 | 一般信息 |
| 7 | DEBUG | 调试 | 程序或系统调试信息等 |
5、日志记录的一般格式
公共日志/var/log/messages 文件的记录格式
时间标签:信息发出的日期和时间
主机名:生成消息的计算机的名称
子系统名称:发出消息的应用程序的名称
消息:消息的具体内容
6、用户日志分析
(1)、保存了用户登录、退出系统等相关信息
/var/log/lastlog:最近的用户登录事件
/var/log/wtmp :用户登录、注销及系统开、关机事件
/var/run/utmp :当前登录的每个用户的详细信息
/var/log/secure :与用户验证相关的安全性事件
(2)、分析工具
users 、who 、w 、last 、lastb
last命令用于查询成功登录到系统的用户记录
lastb命令用于查询登录失败的用户记录
(3)、由相应的应用程序独立进行管理
Web服务:/var/log/httpd/
access_log 记录客户访问事件
error_lpg 记录错误事件
代理服务:/var/log/squid/
access.log 、cache.log
分析工具
文本查看、grep过滤检索、Webmin管理套件中查看
awk、sed等文本过滤、格式化编辑工具
Webalizer、Awstats等专用日志分析工具
7、日志管理策略
(1)、及时做好备份和归档
(2)、延长日志保存期限
(3)、控制日志访问权限
日志中可能会包含各类敏感信息,如账户、口令等
(4)、集中管理日志
将服务器的日志文件发到统一的日志文件服务器
便于日志信息的统一收集、整理和分析
杜绝日志信息的意外丢失、恶意篡改或删除

 浙公网安备 33010602011771号
浙公网安备 33010602011771号