商圈标签
商圈标签
一、使用百度地图开发平台(lbs),根据经纬度查询商圈
注:中国的经纬度范围大约为:维度3.86~53.55,经度73.66~135.05不在范围内的数据可不做处理
第一步:注册百度地图开发平台的账号,申请地址:http://lbsyun.baidu.com/
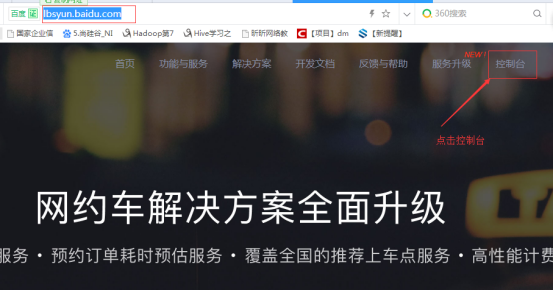
第二步:填写注册信息

第三步:创建应用(申请密钥)
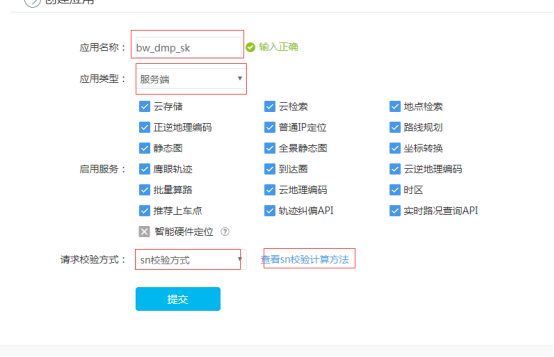
第四步:生成SN码
|
package test; import java.io.UnsupportedEncodingException; import java.net.URLEncoder; import java.security.NoSuchAlgorithmException; import java.util.LinkedHashMap; import java.util.Map; import java.util.Map.Entry; //java版计算signature签名public class SnCal { public static void main(String[] args) throws UnsupportedEncodingException, NoSuchAlgorithmException { SnCal snCal = new SnCal(); // 计算sn跟参数对出现顺序有关,get请求请使用LinkedHashMap保存<key,value>,该方法根据key的插入顺序排序;post请使用TreeMap保存<key,value>,该方法会自动将key按照字母a-z顺序排序。所以get请求可自定义参数顺序(sn参数必须在最后)发送请求,但是post请求必须按照字母a-z顺序填充body(sn参数必须在最后)。以get请求为例:http://api.map.baidu.com/geocoder/v2/?address=百度大厦&output=json&ak=yourak,paramsMap中先放入address,再放output,然后放ak,放入顺序必须跟get请求中对应参数的出现顺序保持一致。 Map paramsMap = new LinkedHashMap<String, String>(); paramsMap.put("address", "百度大厦"); paramsMap.put("output", "json"); paramsMap.put("ak", "yourak");
// 调用下面的toQueryString方法,对LinkedHashMap内所有value作utf8编码,拼接返回结果address=%E7%99%BE%E5%BA%A6%E5%A4%A7%E5%8E%A6&output=json&ak=yourak String paramsStr = snCal.toQueryString(paramsMap);
// 对paramsStr前面拼接上/geocoder/v2/?,后面直接拼接yoursk得到/geocoder/v2/?address=%E7%99%BE%E5%BA%A6%E5%A4%A7%E5%8E%A6&output=json&ak=yourakyoursk String wholeStr = new String("/geocoder/v2/?" + paramsStr + "yoursk");
// 对上面wholeStr再作utf8编码 String tempStr = URLEncoder.encode(wholeStr, "UTF-8");
// 调用下面的MD5方法得到最后的sn签名7de5a22212ffaa9e326444c75a58f9a0 System.out.println(snCal.MD5(tempStr)); }
// 对Map内所有value作utf8编码,拼接返回结果 public String toQueryString(Map<?, ?> data) throws UnsupportedEncodingException { StringBuffer queryString = new StringBuffer(); for (Entry<?, ?> pair : data.entrySet()) { queryString.append(pair.getKey() + "="); queryString.append(URLEncoder.encode((String) pair.getValue(), "UTF-8") + "&"); } if (queryString.length() > 0) { queryString.deleteCharAt(queryString.length() - 1); } return queryString.toString(); }
// 来自stackoverflow的MD5计算方法,调用了MessageDigest库函数,并把byte数组结果转换成16进制 public String MD5(String md5) { try { java.security.MessageDigest md = java.security.MessageDigest .getInstance("MD5"); byte[] array = md.digest(md5.getBytes()); StringBuffer sb = new StringBuffer(); for (int i = 0; i < array.length; ++i) { sb.append(Integer.toHexString((array[i] & 0xFF) | 0x100) .substring(1, 3)); } return sb.toString(); } catch (java.security.NoSuchAlgorithmException e) { } return null; }}
|
二、建立商圈字典
pom.xml 新增如下配置
|
<!--FastJson 解析Json--> <dependency> <groupId>com.alibaba</groupId> <artifactId>fastjson</artifactId> <version>1.2.47</version> </dependency> <!--GeoHash地理位置算法--> <dependency> <groupId>ch.hsr</groupId> <artifactId>geohash</artifactId> <version>1.3.0</version> </dependency> |
BusinessUtil
|
package cn.bw.dmp.util;
import com.alibaba.fastjson.JSON; import com.alibaba.fastjson.JSONObject; import org.apache.commons.httpclient.HttpClient; import org.apache.commons.httpclient.methods.GetMethod; import org.apache.commons.lang.StringUtils;
import java.io.UnsupportedEncodingException; import java.net.URLEncoder; import java.util.LinkedHashMap; import java.util.Map;
public class BusinessUtil { public static String getBusniss(String lonAndLat) throws Exception{ // 计算sn跟参数对出现顺序有关,get请求请使用LinkedHashMap保存<key,value>,该方法根据key的插入顺序排序;post请使用TreeMap保存<key,value>,该方法会自动将key按照字母a-z顺序排序。所以get请求可自定义参数顺序(sn参数必须在最后)发送请求,但是post请求必须按照字母a-z顺序填充body(sn参数必须在最后)。以get请求为例:http://api.map.baidu.com/geocoder/v2/?address=百度大厦&output=json&ak=yourak,paramsMap中先放入address,再放output,然后放ak,放入顺序必须跟get请求中对应参数的出现顺序保持一致。 Map paramsMap = new LinkedHashMap<String, String>(); //paramsMap.put("address", "百度大厦"); paramsMap.put("callback", "renderReverse"); paramsMap.put("location", lonAndLat); paramsMap.put("output", "json"); paramsMap.put("pois", "1"); paramsMap.put("extensions_town", "true"); paramsMap.put("ak", "cZDWGxNBoUOsOusVflIqee2YD1CZmGdA"); // 调用下面的toQueryString方法,对LinkedHashMap内所有value作utf8编码,拼接返回结果address=%E7%99%BE%E5%BA%A6%E5%A4%A7%E5%8E%A6&output=json&ak=yourak String paramsStr = toQueryString(paramsMap); // 对paramsStr前面拼接上/geocoder/v2/?,后面直接拼接yoursk得到/geocoder/v2/?address=%E7%99%BE%E5%BA%A6%E5%A4%A7%E5%8E%A6&output=json&ak=yourakyoursk String wholeStr = new String("/geocoder/v2/?" + paramsStr + "8ZhxmMycfBliDffZTITX5T13p7c8Bepw"); // 对上面wholeStr再作utf8编码 String tempStr = URLEncoder.encode(wholeStr, "UTF-8"); String sn = MD5(tempStr); //String url = "http://api.map.baidu.com"+ tempStr + "&sn="+ sn; String url = "http://api.map.baidu.com/geocoder/v2/?"+paramsStr + "&sn=" + sn; //调用HttpClient访问Baidu LBS 百度地图开放平台 HttpClient httpClient = new HttpClient(); GetMethod get = new GetMethod(url); int status = httpClient.executeMethod(get); String business = ""; if(status == 200){ String response = get.getResponseBodyAsString(); response = response.replaceAll("renderReverse&&renderReverse\\(",""); response = response.substring(0,response.length()-1); JSONObject jo = JSON.parseObject(response); JSONObject result = jo.getJSONObject("result"); //获取商圈 business = result.getString("business"); //如果商圈为空,获取具体的地址最小到镇 if(StringUtils.isEmpty(business)){ StringBuffer buffer = new StringBuffer(); JSONObject addr = result.getJSONObject("addressComponent"); String province = addr.getString("province"); String city = addr.getString("city"); String district = addr.getString("district"); String town = addr.getString("town"); if(StringUtils.isNotEmpty(province)){ buffer.append(province+";"); } if(StringUtils.isNotEmpty(province)){ buffer.append(city+";"); } if(StringUtils.isNotEmpty(province)){ buffer.append(district+";"); } if(StringUtils.isNotEmpty(province)){ buffer.append(town); } business = buffer.toString(); } } return business; }
// 对Map内所有value作utf8编码,拼接返回结果 public static String toQueryString(Map<?, ?> data) throws UnsupportedEncodingException { StringBuffer queryString = new StringBuffer(); for (Map.Entry<?, ?> pair : data.entrySet()) { queryString.append(pair.getKey() + "="); queryString.append(URLEncoder.encode((String) pair.getValue(), "UTF-8") + "&"); } if (queryString.length() > 0) { queryString.deleteCharAt(queryString.length() - 1); } return queryString.toString(); }
// 来自stackoverflow的MD5计算方法,调用了MessageDigest库函数,并把byte数组结果转换成16进制 public static String MD5(String md5) { try { java.security.MessageDigest md = java.security.MessageDigest .getInstance("MD5"); byte[] array = md.digest(md5.getBytes()); StringBuffer sb = new StringBuffer(); for (int i = 0; i < array.length; ++i) { sb.append(Integer.toHexString((array[i] & 0xFF) | 0x100) .substring(1, 3)); } return sb.toString(); } catch (java.security.NoSuchAlgorithmException e) { } return null; }
public static void main(String[] args) throws Exception{ System.out.println(BusinessUtil.getBusniss("40.499603,116.420812")); } }
|
建立经纬度字典
|
package cn.bw.dmp.tools
|
三、商圈标签的开发
|
package cn.bw.dmp.tags
|
四、将商圈标签合并上下文标签
|
package cn.bw.dmp.tags
|

 浙公网安备 33010602011771号
浙公网安备 33010602011771号