spark08
spark08
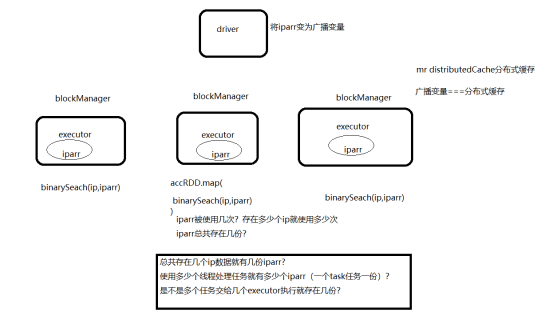
这就是广播变量,每个executor中复用一份数据,在driver端将数据广播出去,在executor端使用
|
val bd = sc.broadcast(iparr) |
广播变量的内部机制
比特洪流技术(快播,迅雷),共享资源
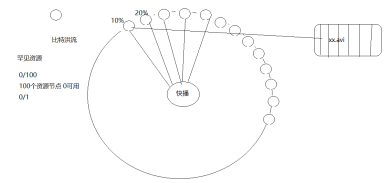

广播变量实现类就是torrent实现类,就是之前用的种子,存放的数据交给每个blockManager组件进行管理,广播变量不能广播rdd,一般广播的都是小的带有规则信息的文件
在spark集群中的序列化
|
object SeriaTest {
|

在算子中创建对象,一条数据创建一个对象

在闭包引用的时候一个task任务用一份数据
|
[root@master Downloads]# hdfs dfs -cat /srresult003/part-00003 (master02,Executor task launch worker for task 3,com.bw.spark.Student@198c75f4) (master02,Executor task launch worker for task 3,com.bw.spark.Student@198c75f4) ^[[A[root@master Downloads]# hdfs dfs -cat /srresult003/part-00001 (master01,Executor task launch worker for task 1,com.bw.spark.Student@6df927c2) (master01,Executor task launch worker for task 1,com.bw.spark.Student@6df927c2) ^[[A[root@master Downloads]# hdfs dfs -cat /srresult003/part-00002 (master,Executor task launch worker for task 2,com.bw.spark.Student@3adc2bae) (master,Executor task launch worker for task 2,com.bw.spark.Student@3adc2bae) [root@master Downloads]# hdfs dfs -cat /srresult003/part-00000 (master02,Executor task launch worker for task 0,com.bw.spark.Student@198c75f4) (master02,Executor task launch worker for task 0,com.bw.spark.Student@198c75f4) |
广播变量中每个executor单独使用一份数据
累加器(accumulator)
(共享变量)
|
object accTest { |
计算iptest中的ip2Long所用的时长和binarySearch所用的时长?
jdbcRDD
|
object accTest { |
spark On yarn
配置yarn资源管理平台
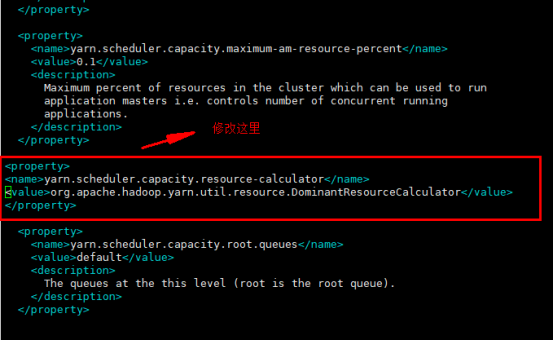
capacity-scheduler.xml 文件:
1.

2.
|
<property> <name>yarn.scheduler.capacity.resource-calculator</name> <!-- <value>org.apache.hadoop.yarn.util.resource.DefaultResourceCalculator</value> --> <value>org.apache.hadoop.yarn.util.resource.DominantResourceCalculator</value> </property> |
3.修改所有 yarn 节点的 yarn-site.xml,在该文件中添加如下配置
4.

|
<property> <name>yarn.nodemanager.pmem-check-enabled</name> <value>false</value> </property> <property> <name>yarn.nodemanager.vmem-check-enabled</name> <value>false</value> </property> |
以上是修改yarn中的配置、
|
5.测试
|

6.
|
spark-submit --master yarn --deploy-mode cluster --class org.apache.spark.examples.SparkPi /root/Downloads/spark-2.2.0-bin-hadoop2.7/examples/jars/spark-examples_2.11-2.2.0.jar 10 |
|
spark-submit --master yarn --deploy-mode cluster --class org.apache.spark.examples.SparkPi /root/Downloads/spark-2.2.0-bin-hadoop2.7/examples/jars/spark-examples_2.11-2.2.0.jar 10 |
spark任务在yarn上面的运行提交命令
7.
|
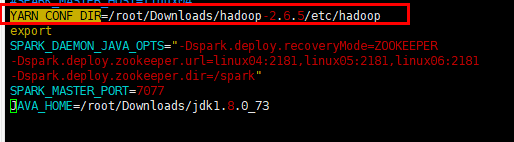
在提交任务到yarn中的时候,一定要知道提交的yarn的集群地址,所以要在spark-env.sh中配置一个开关地址,设定yarn的配置文件位置
8.
|



在yarn的监控页面中的8088端口可以查看任务,点击applicationMaster就可以查看任务的监控页面
在spark任务提交到yarn的集群中的时候存在两种模式,--cluster以集群形式运行 --client客户端形式运行
cluster模式下任务是运行在集群中的,所有的结果都分布在不同的contianer中,所以不会展示出来,想要查看日志,必须将所有日志全部总结在一起,才能得到结果
yarn logs -applicationId id
客户端模式可以直接将结果展示到控制台中
不管是在standalone集群中还是yarn的集群中,运行的时候都要产生executor和driver
sparkPi的结果数据一定在drvier中,能展示到控制台中整名client和driver在一起
在集群模式cluster模式中,结果没有办法展示,所以driver不在客户端,driver和appMaster在一起
如果提交任务后将client端关闭,cluster模式不影响 client模式会停止运行
yarn中的spark-shell
|
Error: Cluster deploy mode is not applicable to Spark shells. Run with --help for usage help or --verbose for debug output |
spark-shell只能运行在client模式中
在client模式下
CoarseGrainedExecutorBackEnd executor进程
spark-submit;在哪提交的任务,哪里就存在这个进程
executorLauncher:这个就是client模式的appMaster
在cluster模式
CoarseGrainedExecutorBackEnd executor进程
spark-submit;在哪提交的任务,哪里就存在这个进程
appMaster == driver
spark standalone集群的HA


export
SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER
-Dspark.deploy.zookeeper.url=master:2181,master01:2181,master02:2181
-Dspark.deploy.zookeeper.dir=/spark"
在每个机器的spark-env.sh中将master的地址去掉
增加上面的zk内容
多启动一个master就可以了

 浙公网安备 33010602011771号
浙公网安备 33010602011771号