Spark消费kafka的直连方式
spark消费kafka的两种方式
直连方式的两种
自动和手动
自动

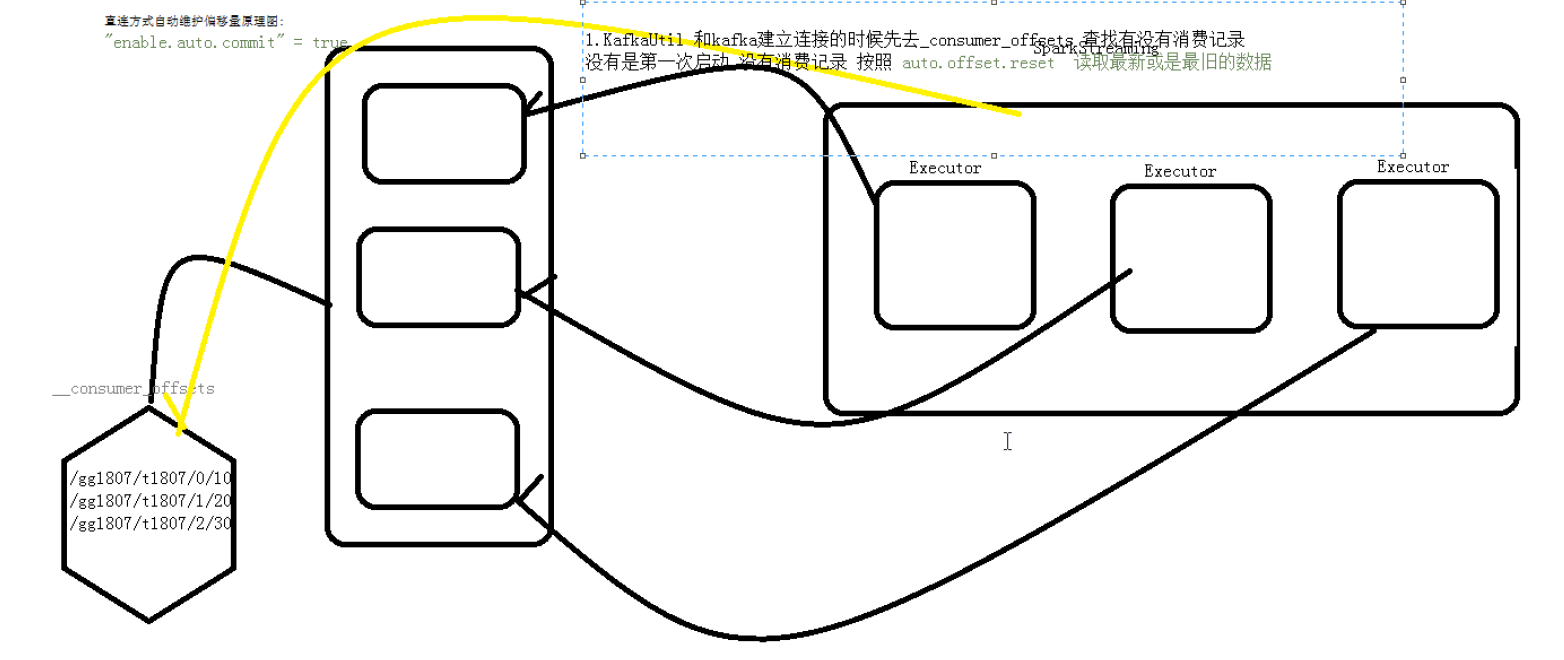
自动偏移量维护kafka 0.10 之前的版本是维护在zookeeper中的,kafka0.10以后的版本是维护在kafka中的topic中的
查看记录消费者的偏移量的路径 _consumer_offsets

案例:
注:先启动zookeeper 再启动kafka集群
命令:
zkServer.sh start
./kafka-server-start.sh -daemon ../config/server.properties
如下图:
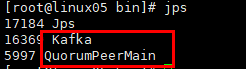
package com.bw.streaming.day03 import org.apache.kafka.clients.consumer.ConsumerRecord import org.apache.kafka.common.serialization.StringDeserializer import org.apache.spark.SparkConf import org.apache.spark.streaming.dstream.InputDStream import org.apache.spark.streaming.kafka010.{ConsumerStrategies, KafkaUtils, LocationStrategies} import org.apache.spark.streaming.{Seconds, StreamingContext} //直连方式 //自定记录偏移量 object RedirectWithAutoOffser { def main(args: Array[String]): Unit = { //入口 val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkStreamingKafkaWithDirect") val ssc = new StreamingContext(conf,Seconds(2)) val kafkaParams = Map[String, Object]( "bootstrap.servers" -> "linux04:9092", "key.deserializer" -> classOf[StringDeserializer], "value.deserializer" -> classOf[StringDeserializer], "group.id" -> "gg1803", //如果没有记录偏移量,就消费最新的数据 "auto.offset.reset" -> "earliest", //spark 消费kafka中的偏移量自动维护: kafka 0.10之前的版本自动维护在zookeeper kafka 0.10之后偏移量自动维护topic(__consumer_offsets) //开启自己动维护偏移量
"enable.auto.commit" -> (true: java.lang.Boolean) ) val topics = Array("t1807a1") //直连方式 val stream: InputDStream[ConsumerRecord[String, String]] = KafkaUtils.createDirectStream[String,String](ssc, LocationStrategies.PreferConsistent, ConsumerStrategies.Subscribe[String,String](topics,kafkaParams)) stream.map(cr => cr.value()).print() //启动 ssc.start() ssc.awaitTermination() } }
结果: 不仅将原来topic中的数据拉取出来 还将消费的数据也拉取粗来了

这里断开程序
然后再开始运行程序
结果如下: 证明是自己记录了偏移量,从上次读到的数据开始拉取
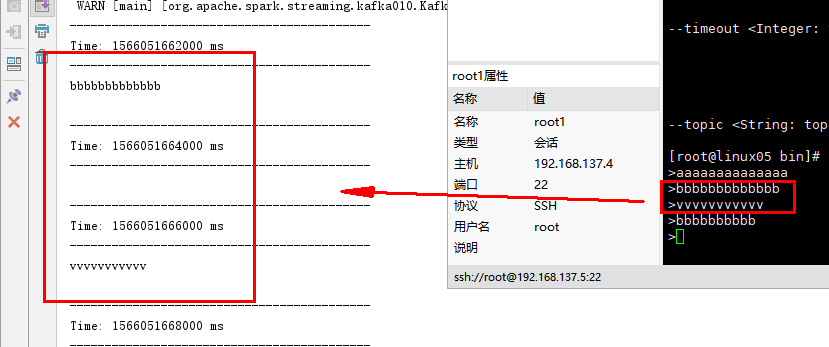
手动记录偏移量
案例
package com.bw.streaming.day03 import kafka.utils.ZKGroupTopicDirs import org.I0Itec.zkclient.ZkClient import org.apache.kafka.clients.consumer.ConsumerRecord import org.apache.kafka.common.TopicPartition import org.apache.kafka.common.serialization.StringDeserializer import org.apache.spark.SparkConf import org.apache.spark.streaming.dstream.InputDStream import org.apache.spark.streaming.kafka010._ import org.apache.spark.streaming.{Seconds, StreamingContext} /** * 直连方式手动维护偏移量 */ object Spa1 { def main(args: Array[String]): Unit = { //入口 val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkStreamingKafkaWithDirect") val ssc = new StreamingContext(conf,Seconds(2)) //消费者组的名称 val gname = "gg18033"; //kafka中topic名称 val tname = "t1807a1" val kafkaParams = Map[String, Object]( "bootstrap.servers" -> "linux04:9092", "key.deserializer" -> classOf[StringDeserializer], "value.deserializer" -> classOf[StringDeserializer], "group.id" -> gname, //如果没有记录偏移量,就消费最新的数据 "auto.offset.reset" -> "latest", //spark 消费kafka中的偏移量自动维护: kafka 0.10之前的版本自动维护在zookeeper kafka 0.10之后偏移量自动维护topic(__consumer_offsets) "enable.auto.commit" -> (false: java.lang.Boolean) ) val topics = Array(tname) //指定zk的地址,后期更新消费的偏移量时使用(以后可以使用Redis、MySQL来记录偏移量) val zkQuorum = "linux04:2181,linux05:2181,linux06:2181" //创建一个 ZKGroupTopicDirs 对象,其实是指定往zk中写入数据的目录,用于保存偏移量 /gg1803/offsets/test/1 val topicDirs = new ZKGroupTopicDirs(gname,tname) //获取 zookeeper 中的路径 "/gg1803/offsets/test/" val zkTopicPath = s"${topicDirs.consumerOffsetDir}" //是zookeeper的客户端,可以从zk中读取偏移量数据,并更新偏移量 val zkClient = new ZkClient(zkQuorum) //查询该路径下是否字节点(默认有字节点为我们自己保存不同 partition 时生成的) // /gg1803/offsets/test/0/10001" // /gg1803/offsets/test/1/30001" // /gg1803/offsets/test/2/10001" //读取 "/gg1803/offsets/test/"有没有子节点,返回的子节点的个数 val children = zkClient.countChildren(zkTopicPath) //直连方式 var stream: InputDStream[ConsumerRecord[String, String]] = null if(children == 0){ //程序第一次启动 stream = KafkaUtils.createDirectStream[String,String](ssc,LocationStrategies.PreferConsistent,ConsumerStrategies.Subscribe[String,String](topics,kafkaParams)) }else{ //手动维护过偏移量 //1.先将维护的偏移量读取出来(zookeeper redis mysql) var offsets: collection.mutable.Map[TopicPartition, Long] = collection.mutable.Map[TopicPartition, Long]() for (i <- 0 until children) { // path = "/gg1803/offsets/test/0" val partitionOffset = zkClient.readData[Long](s"$zkTopicPath/${i}") // wordcount/0 val tp = new TopicPartition(tname, i) //将不同 partition 对应的 offset 增加到 fromOffsets 中 // wordcount/0 -> 10001 offsets.put(tp,partitionOffset.toLong) } stream = KafkaUtils.createDirectStream[String,String](ssc,LocationStrategies.PreferConsistent,ConsumerStrategies.Subscribe[String,String](topics,kafkaParams,offsets)) } //记录偏移量 stream.foreachRDD(rdd =>{ //转换rdd为带偏移量的rdd val ranges: Array[OffsetRange] = rdd.asInstanceOf[HasOffsetRanges].offsetRanges //业务处理 rdd.foreach(println(_)) //记录偏移量 for(osr <- ranges){ //println(osr.topic +" " + osr.partition +" " + osr.fromOffset +" " + osr.untilOffset ) // /g001/offsets/wordcount/0 val zkPath = s"${topicDirs.consumerOffsetDir}/${osr.partition}" //将该 partition 的 offset 保存到 zookeeper // /g001/offsets/test/0/20000 //如果目录不存在先创建 //println(zkPath) if(!zkClient.exists(zkPath)){ zkClient.createPersistent(zkPath,true) } //写入数据 zkClient.writeData(zkPath,osr.untilOffset) } }) //启动 ssc.start() ssc.awaitTermination() } }
结果如下:
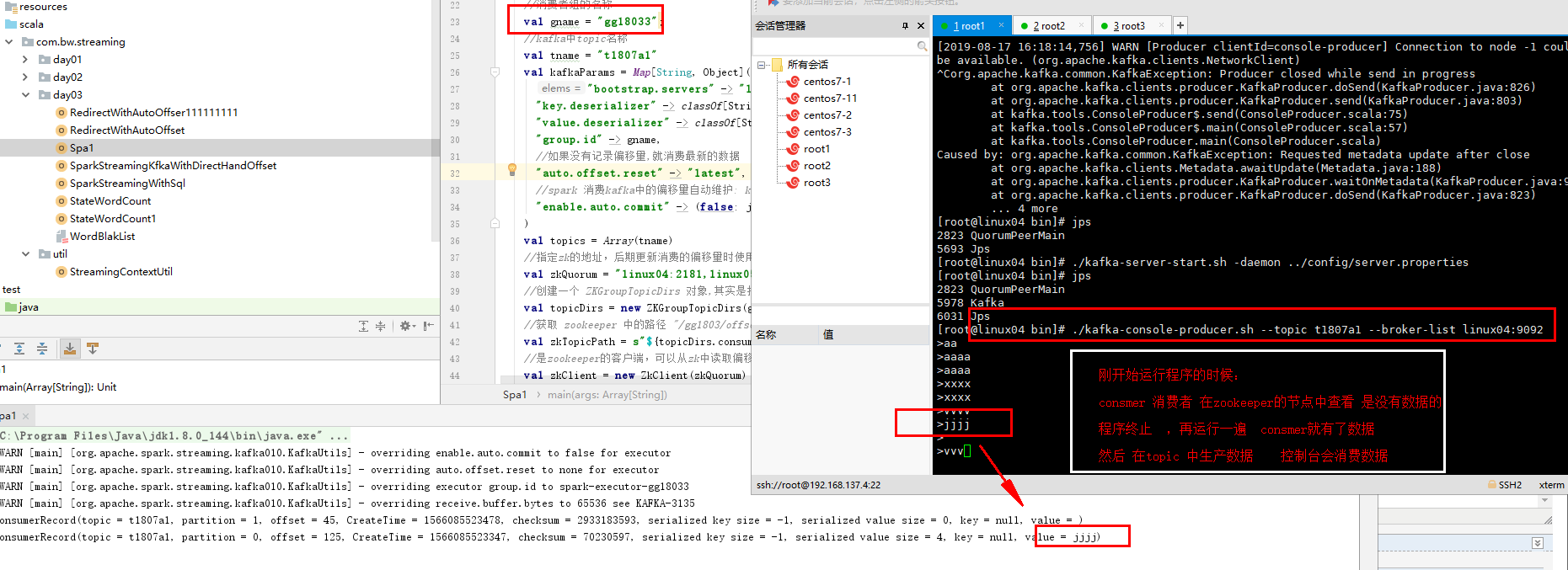
这个是正确的讲解:截图上面的笔记不要看
1. 之前在zk节点中是没有消费者组,
2.程序运行一次 将消费者组 消费记录放入zk节点中
3.将程序关闭,
4.然后再将程序运行
5.在kafka生产数据
6.查看控制台 打印的消费数据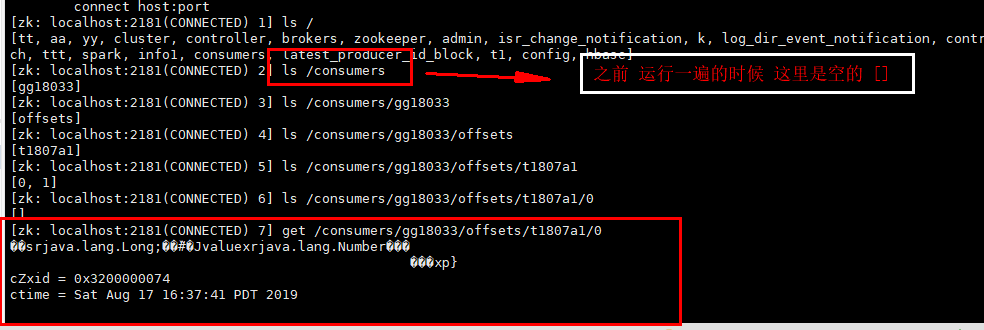
作为一个真正的程序员,首先应该尊重编程,热爱你所写下的程序,他是你的伙伴,而不是工具。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号