Hbase 取数据 和放数据 使用mr
//将从hbas数据库中用mr读取的数据放入到 hdfs中
注:引入 jar 包
//使用mr 将hbase数据库中的单词计算出来
创建表 wordcount 放入4条数据


在eclipce中
package com.bw.hbase; import java.io.IOException; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.hbase.HBaseConfiguration; import org.apache.hadoop.hbase.client.Result; import org.apache.hadoop.hbase.client.Scan; import org.apache.hadoop.hbase.io.ImmutableBytesWritable; import org.apache.hadoop.hbase.mapreduce.TableMapReduceUtil; import org.apache.hadoop.hbase.mapreduce.TableMapper; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; //使用mr 计算 hbase数据库中单词的数量 public class HBaseWC { // 表中的数据是: // hello jack // hello world // hello tom // hello lmc // Text 单词 IntWritable是总数 public static class HMapper extends TableMapper<Text, IntWritable> { // map端的输出的值是将单词 拆分 (hello 1) (hello 1)(jack 1) ........... IntWritable outval = new IntWritable(1);// 输出的每个单词数量都是1 @Override protected void map(ImmutableBytesWritable key, Result value, Mapper<ImmutableBytesWritable, Result, Text, IntWritable>.Context context) throws IOException, InterruptedException { // 1.不需要key值 因为key是row_key 表中自带的 不变的那个值 byte[] val = value.getValue("info".getBytes(), "word".getBytes()); String word = new String(val); String[] split = word.split(" "); for (String str : split) { context.write(new Text(str), outval); } } } public static class HReducer extends Reducer<Text, IntWritable, Text, IntWritable> { // 重写reduce方法 @Override protected void reduce(Text arg0, Iterable<IntWritable> arg1, Reducer<Text, IntWritable, Text, IntWritable>.Context arg2) throws IOException, InterruptedException { int count = 0; for (IntWritable i : arg1) { count++; } arg2.write(arg0, new IntWritable(count)); } } public static void main(String[] args) throws Exception { Configuration conf = HBaseConfiguration.create(); conf.set("hbase.zookeeper.quorum", "linux04:2181"); Job job = Job.getInstance(conf); job.setJarByClass(HBaseWC.class); Scan scan = new Scan(); TableMapReduceUtil.initTableMapperJob("wordcount", scan, HMapper.class, Text.class, IntWritable.class, job); job.setReducerClass(HReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); FileOutputFormat.setOutputPath(job, new Path("hbasewc")); job.waitForCompletion(true); } }
//将数据放入本地中
// 先从hdfs上将数据拿出来,再放入hbase数据库中
a.将数据放入工程中 还有jar 都需要导入

b.输入代码 先到map 再到Tablereduce端 八股文
package com.bw.hbase; import java.io.IOException; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.hbase.HBaseConfiguration; import org.apache.hadoop.hbase.HColumnDescriptor; import org.apache.hadoop.hbase.HTableDescriptor; import org.apache.hadoop.hbase.client.HBaseAdmin; import org.apache.hadoop.hbase.client.Mutation; import org.apache.hadoop.hbase.client.Put; import org.apache.hadoop.hbase.io.ImmutableBytesWritable; import org.apache.hadoop.hbase.mapreduce.TableMapReduceUtil; import org.apache.hadoop.hbase.mapreduce.TableReducer; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import com.bw.hbase.HBaseWC.HReducer; //将hdfs中的数据存储到hbse中 public class Hdfs2Hbase { public static class WMapper extends Mapper<LongWritable, Text, Text, IntWritable>{ IntWritable val = new IntWritable(1); @Override protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException { String[] strs = value.toString().split(" "); for (String str : strs) { context.write(new Text(str), val); } } } //接收的是 Text IntWritable 输出的是 ImmutableBytesWritable public static class WReduer extends TableReducer<Text, IntWritable, ImmutableBytesWritable>{ @Override protected void reduce(Text arg0, Iterable<IntWritable> arg1, Reducer<Text, IntWritable, ImmutableBytesWritable, Mutation>.Context arg2) throws IOException, InterruptedException { int count=0; for (IntWritable i : arg1) { count++; } //rowkey put(family,qualifier.value) //table rowkey hello info:count 3 Put put = new Put(arg0.toString().getBytes()); put.add("info".getBytes(),"count".getBytes(),(""+count).getBytes()); //ImmutableBytesWritable w = new ImmutableBytesWritable(); //w.set(byte[]) //将单词 设置为row_key 再将列族 列 和数据放入 arg2.write(new ImmutableBytesWritable(arg0.toString().getBytes()),put); } } public static void main(String[] args) throws Exception { Configuration conf = HBaseConfiguration.create(); conf.set("hbase.zookeeper.quorum", "linux04:2181"); //创建表 HBaseAdmin admin = new HBaseAdmin(conf); if(admin.tableExists("wcresult")) { admin.disableTable("wcresult"); } HTableDescriptor hd = new HTableDescriptor("wcresult"); HColumnDescriptor hcd = new HColumnDescriptor("info"); hcd.setMaxVersions(3); hd.addFamily(hcd); admin.createTable(hd); Job job = Job.getInstance(conf); job.setJarByClass(Hdfs2Hbase.class); job.setMapperClass(WMapper.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(IntWritable.class); job.setReducerClass(HReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); FileInputFormat.addInputPath(job, new Path("word1.txt")); TableMapReduceUtil.initTableReducerJob("wcresult", WReduer.class, job); job.waitForCompletion(true); } }
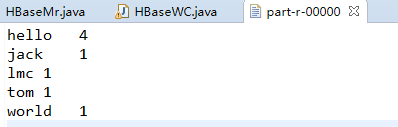
//运行完成以后 去hbase中查看表 和数据 结果

作为一个真正的程序员,首先应该尊重编程,热爱你所写下的程序,他是你的伙伴,而不是工具。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号