flume---高级配置5种

![]()
1-01 //以varo 形式接收的数据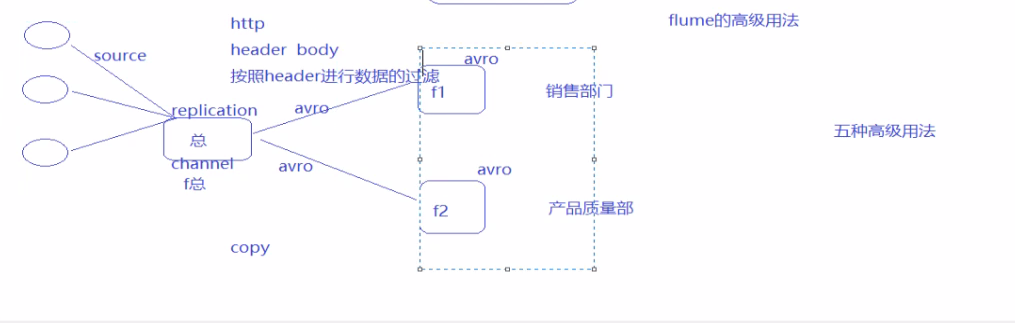
1)Replicating Channel Selector Flume支持Fan out流从一个源到多个通道。有两种模式的Fan out,分别是复制和复用。在复制的情况下,流的事件被发送到所有的配置通道。
在复用的情况下,事件被发送到可用的渠道中的一个子集。Fan out流需要指定源和Fan out通道的规则。 这次我们需要用到master,slave1两台机器。
//将数据发送给两台机器 05 机 将数据发送给06和04机器
*******************************************************************************
vim 05机
[root@linux05 conf]# vim replicate.conf
//将下面数据放入
a1.sources = r1
a1.channels = c1 c2
a1.sinks = k1 k2
# Describe/configure the source
a1.sources.r1.type = spooldir
a1.sources.r1.spoolDir=/flime
a1.sources.r1.channels = c1 c2
a1.sources.r1.selector.type = replicating
# Describe the sink
a1.sinks.k1.type = avro
a1.sinks.k1.channel = c1
a1.sinks.k1.hostname = linux04
a1.sinks.k1.port = 5555
a1.sinks.k2.type = avro
a1.sinks.k2.channel = c2
a1.sinks.k2.hostname = linux06
a1.sinks.k2.port = 5555
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
a1.channels.c2.type = memory
a1.channels.c2.capacity = 1000
a1.channels.c2.transactionCapacity = 100
********************************************************************************
//05配置好以后
配置04和06的 vim avro.conf
//在04和06机器 启动
vim 06机器
****************************
[root@linux06 conf]# vim avro.conf
a1.sources=r1
a1.sinks=k1
a1.channels=c1
a1.sources.r1.type=avro
a1.sources.r1.bind=linux06
a1.sources.r1.port=5555
a1.sinks.k1.type=logger
a1.channels.c1.type=memory
a1.channels.c1.capacity=1000
a1.channels.c1.tranactionCapacity=100
a1.sinks.k1.channel=c1
a1.sources.r1.channels=c1
//配置好以后
//输入启动命令
[root@linux04 conf]# flume-ng agent -c . -f avro.conf -n a1 -Dflume.root.logger=info,console
*********************************************************
//分发到第一台机器中
[root@linux06 Downloads]# scp -r apache-flume-1.6.0-bin root@linux04:`pwd`
//安装成 以后
[root@linux04 apache-flume-1.6.0-bin]# cd conf
**************************
//将下面内容放入
[root@linux04 conf]# vim avro.conf
a1.sources=r1
a1.sinks=k1
a1.channels=c1
a1.sources.r1.type=avro
a1.sources.r1.bind=linux04
a1.sources.r1.port=5555
a1.sinks.k1.type=logger
a1.channels.c1.type=memory
a1.channels.c1.capacity=1000
a1.channels.c1.tranactionCapacity=100
a1.sinks.k1.channel=c1
a1.sources.r1.channels=c1
*****************************************
//配置好以后
//输入启动命令
[root@linux04 conf]# flume-ng agent -c . -f avro.conf -n a1 -Dflume.root.logger=info,console
========================================================================================================================
//两台都启动好以后 注意:检查两台必须都启动
//将05机器 也启动
flume-ng agent -c . -f replicate.conf -n a1 -Dflume.root.logger=info,console
![]()

1-02 //以varo 形式接收的数据
[root@linux05 conf]# vim replicate1.conf
//将下面的文件放入
a1.sources = r1
a1.channels = c1 c2
a1.sinks = k1 k2
# Describe/configure the source
a1.sources.r1.type = spooldir
a1.sources.r1.spoolDir=/flime
a1.sources.r1.channels = c1 c2
a1.sources.r1.selector.type = replicating
# Describe the sink
a1.sinks.k1.type = avro
a1.sinks.k1.channel = c1
a1.sinks.k1.hostname = linux04
a1.sinks.k1.port = 5555
a1.sinks.k2.type=logger
a1.sinks.k2.channel = c2
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
a1.channels.c2.type = memory
a1.channels.c2.capacity = 1000
a1.channels.c2.transactionCapacity = 100
**********************************************************************************
//执行命令
[root@linux05 conf]# flume-ng agent -c . -f replicate1.conf -n a1 -Dflume.root.logger=info,console
//
[root@linux05 /]# mkdir flime
[root@linux05 /]# cd /flime/
[root@linux05 flime]# echo "ccccccc ">>a1.txt
[root@linux05 flime]#
//看下面图 监控



2. http 进行分类 接收数据
将数据分类 multiplexing
将一个source端采集的数据 给两个channel
根据header 头
不是副本形式 是header头是那个 给那个
vim complex.conf
//将下面配置放入
a1.sources = s1 a1.channels = c1 c2 a1.sinks = k1 k2 # For each one of the sources, the type is defined a1.sources.s1.type = org.apache.flume.source.http.HTTPSource a1.sources.s1.port = 8887 a1.sources.s1.channels = c1 c2 a1.sources.s1.selector.type = multiplexing a1.sources.s1.selector.header = company a1.sources.s1.selector.mapping.ali = c1 a1.sources.s1.selector.mapping.baidu = c2 a1.sources.s1.selector.default = c2 # Each sink's type must be defined a1.sinks.k1.type = avro a1.sinks.k1.hostname = linux04 a1.sinks.k1.port = 5555 a1.sinks.k1.channel = c1 a1.sinks.k2.type = avro a1.sinks.k2.hostname = linux06 a1.sinks.k2.port = 5555 a1.sinks.k2.channel = c2 # Each channel's type is defined. a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 a1.channels.c2.type = memory a1.channels.c2.capacity = 1000 a1.channels.c2.transactionCapacity = 100
//将其他两台机器都开启
否则连接不上
//输入命令
[root@linux05 conf]# flume-ng agent -c . -f complex.conf -n a1 -Dflume.root.logger=info,console
//启动成功后 用java测试
package com.bw.tcp; import java.io.BufferedOutputStream; import java.io.BufferedReader; import java.io.InputStreamReader; import java.io.OutputStream; import java.io.PrintWriter; import java.net.HttpURLConnection; import java.net.InetSocketAddress; import java.net.Socket; import java.net.SocketAddress; import java.net.URL; import java.util.Date; public class TcpTest { public static void main(String[] args) throws Exception { sendData(); } public static void sendData() { try { URL url = new URL("http://linux05:8887"); HttpURLConnection connection = (HttpURLConnection) url.openConnection(); connection.setDoInput(true); // 设置可输入 connection.setDoOutput(true); // 设置该连接是可以输出的 connection.setRequestMethod("POST"); // 设置请求方式 connection.setRequestProperty("Content-Type", "application/json;charset=UTF-8"); PrintWriter pw = new PrintWriter(new BufferedOutputStream(connection.getOutputStream())); pw.write("[{ \"headers\" :{\"company\" : \"baidu\"},\"body\" : \"idoall_TEST1\"}]"); pw.flush(); //这里改百度 就是百度监控到了 pw.close(); //这里改阿里 就是另一台机器 BufferedReader br = new BufferedReader(new InputStreamReader(connection.getInputStream(), "utf-8")); String line = null; StringBuilder result = new StringBuilder(); while ((line = br.readLine()) != null) { // 读取数据 result.append(line + "\n"); } connection.disconnect(); System.out.println(result.toString()); } catch (Exception e) { e.printStackTrace(); } } }
![]()
![]()


![]()

![]()

![]()

3.
一个failover给两台failover 默认只给一台 当这台挂了 给另一台 不会坏 高可靠性

[root@linux05 conf]# vim failover.conf
a1.sources = r1 a1.channels = c1 c2 a1.sinks = k1 k2 # Describe/configure the source a1.sources.r1.type = spooldir a1.sources.r1.spoolDir=/flime a1.sources.r1.channels = c1 c2 a1.sources.r1.selector.type = replicating # Describe the sink a1.sinks.k1.type = avro a1.sinks.k1.channel = c1 a1.sources = r1 a1.channels = c1 c2 a1.sinks = k1 k2 # Describe/configure the source a1.sources.r1.type = spooldir a1.sources.r1.spoolDir=/flime a1.sources.r1.channels = c1 c2 a1.sources.r1.selector.type = replicating # Describe the sink a1.sinks.k1.type = avro a1.sinks.k1.channel = c1 a1.sources = r1 a1.channels = c1 c2 a1.sinks = k1 k2 # Describe/configure the source a1.sources.r1.type = spooldir a1.sources.r1.spoolDir=/flime a1.sources.r1.channels = c1 c2 a1.sources.r1.selector.type = replicating # Describe the sink a1.sinks.k1.type = avro a1.sinks.k1.channel = c1 a1.sources = r1 a1.channels = c1 c2 a1.sinks = k1 k2 # Describe/configure the source a1.sources.r1.type = spooldir a1.sources.r1.spoolDir=/flime a1.sources.r1.channels = c1 c2 a1.sources.r1.selector.type = replicating # Describe the sink a1.sinks.k1.type = avro a1.sinks.k1.channel = c1 a1.sinks.k1.hostname = linux04 a1.sinks.k1.port = 5555 #这个是配置failover的关键,需要有一个sink group a1.sinkgroups = g1 a1.sinkgroups.g1.sinks = k1 k2 ##处理的类型是failover a1.sinkgroups.g1.processor.type = failover ##优先级,数字越大优先级越高,每个sink的优先级必须不相同 a1.sinkgroups.g1.processor.priority.k1 = 5 a1.sinkgroups.g1.processor.priority.k2 = 10 ##设置为10秒,当然可以根据你的实际状况更改成更快或者很慢 a1.sinkgroups.g1.processor.maxpenalty = 10000 a1.sinks.k2.type = avro a1.sinks.k2.channel = c2 a1.sinks.k2.hostname = linux06 a1.sinks.k2.port = 5555 # Use a channel which buffers events in memory a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 a1.channels.c2.type = memory a1.channels.c2.capacity = 1000 a1.channels.c2.transactionCapacity = 100
**********************************************************************
//将前面两台机器启动
//输入命令
[root@linux05 conf]# flume-ng agent -c . -f failover.conf -n a1 -Dflume.root.logger=info,console
![]()
//监控文件夹
//查看监控
![]()


//默认给了06机器 他的优先级高
//要是报错了 就说明宕机了 就给了另一台机器
![]()


![]()

![]()

5. 负载均衡 也是两个sinks端 组成一个组 一个source 给一个channel 一个channel给两个sinks


[root@linux05 conf]# vim loadbalance.conf
a1.sources = r1 a1.channels = c1 a1.sinks = k1 k2 # Describe/configure the source a1.sources.r1.type = spooldir a1.sources.r1.spoolDir=/flime a1.sources.r1.channels = c1 # Describe the sink a1.sinks.k1.type = avro a1.sinks.k1.channel = c1 a1.sinks.k1.hostname = linux04 a1.sinks.k1.port = 5555 #这个是配置Load balancing的关键,需要有一个sink group a1.sinkgroups = g1 a1.sinkgroups.g1.sinks = k1 k2 a1.sinkgroups.g1.processor.type = load_balance a1.sinkgroups.g1.processor.backoff = true a1.sinkgroups.g1.processor.selector = round_robin a1.sinks.k2.type = avro a1.sinks.k2.channel = c1 a1.sinks.k2.hostname = linux06 a1.sinks.k2.port = 5555 # Use a channel which buffers events in memory a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 a1.channels.c2.type = memory a1.channels.c2.capacity = 1000 a1.channels.c2.transactionCapacity = 100
***************************************************************
//先将别的两台启动 否则会报错
//在将05启动
[root@linux05 conf]# flume-ng agent -c . -f loadbalance.conf -n a1 -Dflume.root.logger=info,console

//三台都启动以后
//输入命令




 浙公网安备 33010602011771号
浙公网安备 33010602011771号