12-order by和group by 原理和优化 sort by 倒叙
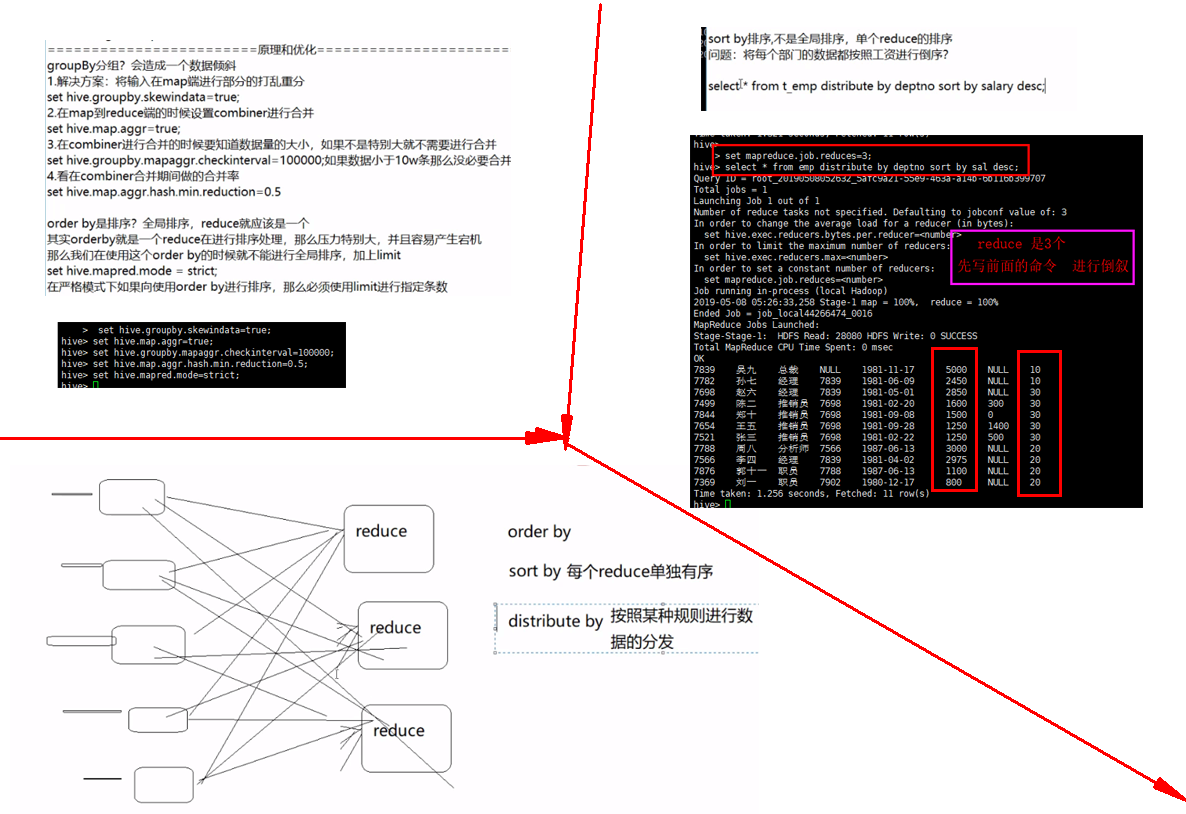
========================原理和优化================================== groupBy分组?会造成一个数据倾斜 1.解决方案:将输入在map端进行部分的打乱重分 set hive.groupby.skewindata=true; 2.在map到reduce端的时候设置combiner进行合并 set hive.map.aggr=true; 3.在combiner进行合并的时候要知道数据量的大小,如果不是特别大就不需要进行合并 set hive.groupby.mapaggr.checkinterval=100000;如果数据小于10w条那么没必要合并 4.看在combiner合并期间做的合并率 set hive.map.aggr.hash.min.reduction=0.5 order by是排序?全局排序,reduce就应该是一个 其实orderby就是一个reduce在进行排序处理,那么压力特别大,并且容易产生宕机 那么我们在使用这个order by的时候就不能进行全局排序,加上limit set hive.mapred.mode = strict; 在严格模式下如果向使用order by进行排序,那么必须使用limit进行指定条数 sort by排序,不是全局排序,单个reduce的排序 问题:将每个部门的数据都按照工资进行倒序? set mapreduce.job.reduces=3; select * from t_emp distribute by deptno sort by salary desc;
sort by 每个mr自己得文件单独排序
distribute by 分发将map端得数据按照一定得规则分发给不同得reduce端
set mapreduce.job.reduces=3;
与order by不同,order by是全局排序 其实sortby也可以全局排序 reduce是一个得时候就可以全局排序
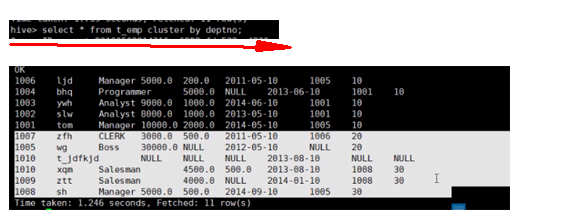
cluster by:分发+排序 == sort by+distribute by,但是cluster by 这个分发加上排序是只能指定一个字段
作为一个真正的程序员,首先应该尊重编程,热爱你所写下的程序,他是你的伙伴,而不是工具。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号