二次排序 3
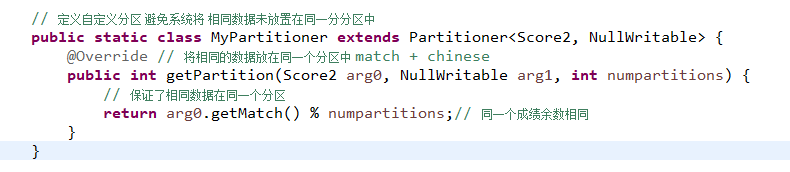
package com.bw.mr; import java.io.DataInput; import java.io.DataOutput; import java.io.IOException; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.io.WritableComparable; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Partitioner; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; //match chinese 数学成绩和 语文成绩 // 98 56 // 85 65 // 72 76 // 85 98 // 72 75 // 89 80 // 98 99 // 65 99 shuffle 的key排序 //需求 按照学生的考试成绩进行排序 1.按照数学成绩排序 2.数学成绩一致 按照语文成绩排序 //1. 默认给定了三次排序 integerw in....... public class SecondarySort2 { public static class SSMapper extends Mapper<LongWritable, Text, Score2, NullWritable> { @Override protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Score2, NullWritable>.Context context) throws IOException, InterruptedException { // 切分对象 String[] strs = value.toString().split(" "); context.write(new Score2(Integer.parseInt(strs[0].toString()), Integer.parseInt(strs[1].toString())), NullWritable.get()); } } public static class SSReducer extends Reducer<Score2, NullWritable, Score2, NullWritable> { @Override protected void reduce(Score2 arg0, Iterable<NullWritable> arg1, Reducer<Score2, NullWritable, Score2, NullWritable>.Context arg2) throws IOException, InterruptedException { arg2.write(arg0, NullWritable.get()); } } // 定义自定义分区 避免系统将 相同数据未放置在同一分分区中 public static class MyPartitioner extends Partitioner<Score2, NullWritable> { @Override // 将相同的数据放在同一个分区中 match + chinese public int getPartition(Score2 arg0, NullWritable arg1, int numpartitions) { // 保证了相同数据在同一个分区 return arg0.getMatch() % numpartitions;// 同一个成绩余数相同 } } public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); Job job = Job.getInstance(conf); job.setPartitionerClass(MyPartitioner.class); job.setJarByClass(SecondarySort2.class); job.setMapperClass(SSMapper.class); job.setMapOutputKeyClass(Score2.class); job.setMapOutputValueClass(NullWritable.class); job.setReducerClass(SSReducer.class); job.setOutputKeyClass(Score2.class); job.setMapOutputValueClass(NullWritable.class); job.setNumReduceTasks(2); FileInputFormat.addInputPath(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); job.waitForCompletion(true); } } class Score2 implements WritableComparable<Score2> { // 定义两个成绩 private int match; private int chinese; // 构造器 get set public int getMatch() { return match; } @Override public String toString() { return "Score2 [match=" + match + ", chinese=" + chinese + "]"; } public Score2(int match, int chinese) { super(); this.match = match; this.chinese = chinese; } public Score2() { super(); } public void setMatch(int match) { this.match = match; } public int getChinese() { return chinese; } public void setChinese(int chinese) { this.chinese = chinese; } // 利用shuffle排序 对象具备序列化 @Override public void readFields(DataInput in) throws IOException { this.match = in.readInt(); this.chinese = in.readInt(); } @Override public void write(DataOutput out) throws IOException { out.writeInt(this.match); out.writeInt(this.chinese); } // 重写 compareTo的方法 定义排序规则 @Override public int compareTo(Score2 o) { // 如果数学成绩一致的话 就去比较语文成绩 if (o.getMatch() == this.getMatch()) { return o.getChinese() - this.getChinese(); } else { // 比较数学成绩 return o.getMatch() - this.getMatch(); } } }

作为一个真正的程序员,首先应该尊重编程,热爱你所写下的程序,他是你的伙伴,而不是工具。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号