


【数据库】数据库知识点(转)
一、主键 外键
主键:数据库表中对存储对象予以唯一和完整表示的数据列或属性的组合。一个数据列只能有一个主键,主键取值不能为null
外键:一个表存在的另一个表的主键。
二、数据库事务的四个特性
ACID
A(Atomicity)原子性:事务的所有操作都是原子的,要么都做,要么都不做,不可能停滞在中间的某个步骤。事务执行发生错误会回滚(rollback)到执行之前。
C(Correspondence)一致性:事务开始之前和执行之后,数据库的完整性约束没有被破坏
I(Isolation)隔离性:隔离状态执行事务,使他们好像是系统在给定时间内执行的唯一操作。如果有两个事务,运行在相同的事件内,隔离性保证只有一个事务在使用系统。为了防止事务操作的混淆,必须使得在同一时间只有一个请求用于同一数据。
D(Durability)持久性:事务完成后,它对数据库的更改会持久的保存在数据库中,不会被回滚。
三、索引
数据库索引,是数据库管理系统中一个排序的数据结构,可以用于快速查询,更新数据库表中的数据。索引的实现通常是使用B树或B+树。
在数据之外,数据库系统维护这满足特定查找算法的数据结构,这些数据结构以某种方式引用数据,这样就可以在这些数据结构上实现高级查找算法,这种数据结构就是索引。
为表设置索引增加了数据库的存储空间,而且在插入和修改数据时要花费时间去修改索引。
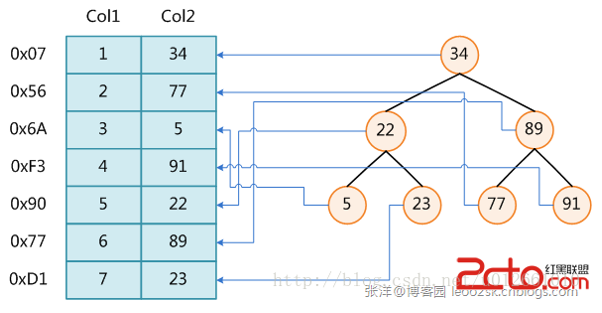
上图演示了索引。左边是数据表,一共两列七条数据,最左边是数据的物理地址。为了加快Col2的查找,可以维护一个右边所示的二叉查找树,每个节点分别包含索引键值和一个指向对应数据物理地址的指针,这样就可以利用二叉查找树在O(log2n)复杂度内获取到相应数据。
3.1索引的建立原则:
在经常需要搜索的列上。
在作为主键的列上
经常用在连接的列上,主要是一些些外键。
在经常需要根据范围去查找的列上
在经常需要进行排序的列上
经常使用在Where字句的列上。
3.2根据数据库的功能,可以建立以下三种索引:唯一索引,主键索引,聚集索引。
唯一索引:不允许表其中任何两行记录具有相同索引值的索引。
主键索引:在数据库关系图中为表定义主键将自动创建主键索引,它要求主键中的值都唯一,当查询中用到主键索引时,允许对数据的快速访问。
聚集索引:表中行的物理顺序与键值的逻辑(索引)顺序相同。
3.3B+/-Tree性能分析
3.3.1 局部性原理和磁盘预读:
由于存储介质的特性,磁盘本身存取就比主存慢很多,再加上机械运动耗费,磁盘的存取速度往往是主存的几百分分之一,因此为了提高效率,要尽量减少磁盘I/O。为了达到这个目的,磁盘往往不是严格按需读取,而是每次都会预读,即使只需要一个字节,磁盘也会从这个位置开始,顺序向后读取一定长度的数据放入内存。这样做的理论依据是计算机科学中著名的局部性原理:当一个数据被用到时,其附近的数据也通常会马上被使用。程序运行期间所需要的数据通常比较集中。
由于磁盘顺序读取的效率很高(不需要寻道时间,只需很少的旋转时间),因此对于具有局部性的程序来说,预读可以提高I/O效率。
预读的长度一般为页(page)的整倍数。页是计算机管理存储器的逻辑块,硬件及操作系统往往将主存和磁盘存储区分割为连续的大小相等的块,每个存储块称为一页(在许多操作系统中,页得大小通常为4k),主存和磁盘以页为单位交换数据。当程序要读取的数据不在主存中时,会触发一个缺页异常,此时系统会向磁盘发出读盘信号,磁盘会找到数据的起始位置并向后连续读取一页或几页载入内存中,然后异常返回,程序继续运行。
3.3.2 性能分析:
上文说过一般使用磁盘I/O次数评价索引结构的优劣。先从B-Tree分析,根据B-Tree的定义,可知检索一次最多需要访问h个节点。数据库系统的设计者巧妙利用了磁盘预读原理,将一个节点的大小设为等于一个页,这样每个节点只需要一次I/O就可以完全载入。为了达到这个目的,在实际实现B-Tree还需要使用如下技巧:
每次新建节点时,直接申请一个页的空间,这样就保证一个节点物理上也存储在一个页里,加之计算机存储分配都是按页对齐的,就实现了一个node只需一次I/O。
B-Tree中一次检索最多需要h-1次I/O(根节点常驻内存),渐进复杂度为O(h)=O(logdN)。一般实际应用中,出度d是非常大的数字,通常超过100,因此h非常小(通常不超过3)。
而红黑树这种结构,h明显要深的多。由于逻辑上很近的节点(父子)物理上可能很远,无法利用局部性,所以红黑树的I/O渐进复杂度也为O(h),效率明显比B-Tree差很多。
综上所述,用B-Tree作为索引结构效率是非常高的。
四、连接的种类
| table1 | table2 | ||
| id | name | id | score |
| 1 | lee | 1 | 90 |
| 2 | zhang | 2 | 100 |
| 4 | wang | 3 | 70 |
1.外链接:包括左外连接,右外连接或完整外部链接
2.左连接: left join 或left outer join
左外连接的结果集包括left outer字句中指定的左表的所有行。如果左表的某行在右表中没有匹配行,相关联的结果集行中右边所有选择列均为空null
例:select * from table1 left join table2 on table1.id=table2.id
结果:
1 lee 1 90
2 zhang 2 100
4 wang null null
包含左表(table1)的所有数据,返回符合指定条件的右表的数据,不符合的null
3.右连接:right join 或right outer join
右外连接的结果集包括right outer字句中指定的右表的所有行。如果右表的某行在左表中没有匹配行,相关联的结果集行中左边所有选择列均为空null
例:select * from table1 right join table2 on table1.id=table2.id
结果:
1 lee 1 90
2 zhang 2 100
null null 3 70
包含右表(table2)的所有数据,返回符合指定条件的左表的数据,不符合的null
4.完整外部连接full join 或full outer join
返回左表和右表的所有数据,当某一行没有匹配行时,显示null
例:select * from table1 full join table2 on table1.id = table2.id
结果:
1 lee 1 90
2 zhang 2 100
4 wang null null
null null 3 70
5.内连接:只显示符合条件的 join 或inner join
例:select * from table1 join table2 on table1.id = table2.id
结果
1 lee 1 90
2 zhang 2 100
6.交叉连接:没有where字句的交叉连接产生连接表的所有记录的笛卡尔积。
例:select * from table1 cross join table2
结果:
1 lee 1 90
2 zhang 1 90
4 wang 1 90
1 lee 2 100
2 zhang 2 100
4 wang 2 100
1 lee 3 70
2 zhang 3 70
4 wang 3 70
五、数据库范式:
这里引用一篇大佬的文章,看过之后感觉清新脱俗。
https://www.cnblogs.com/lca1826/p/6601395.html
1.第一范式(1NF):属性不可分
2.第二范式(2NF):非主属性完全依赖于码,不存在非主属性的部分依赖
3.第三范式(3NF):在2NF的基础上消除传递函数依赖
4.BC范式(BCNF):符合3NF,并且主属性不依赖于主属性
这里主要区别3NF和BCNF,一句话就是3NF是要满足不存在非主属性对候选码的传递函数依赖,BCNF是要满足不存在任一属性(包含非主属性和主属性)对候选码的传递函数依赖。
六、数据库优化
1.SQL语句优化:
1)应尽量避免在 where 子句中使用!=或<>操作符,否则将引擎放弃使用索引而进行全表扫描。
2)应尽量避免在 where 子句中对字段进行 null 值判断,否则将导致引擎放弃使用索引而进行全表扫描,如:
select id from t where num is null
可以在num上设置默认值0,确保表中num列没有null值,然后这样查询:
select id from t where num=0
3)很多时候用 exists 代替 in 是一个好的选择
4)用Where子句替换HAVING 子句 因为HAVING 只会在检索出所有记录之后才对结果集进行过滤
2.索引
3.数据库结构优化:
1)范式:例如消除冗余
2)反范式:添加冗余(为了减少join)
3)拆分表:分为水平拆分和垂直拆分(再看)
4)服务器硬件优化
七、存储过程
是一些预编译的SQL语句。存储过程可以说是一个记录集,它是由一些T-SQL语句组成的代码块,再给这些代码块起一个名字,用到这个功能的时候调用就行了。
八.MYSQL常用语句:
选择:select * from table1 where 范围
插入:insert into table1(field1,field2) values(value1,value2)
删除:delete from table1 where 范围
更新:update table1 set field1=value1 where 范围
查找:select * from table1 where field1 like ’%value1%’ ---like的语法很精妙,查资料!
排序:select * from table1 order by field1,field2 [desc]
总数:select count as totalcount from table1
求和:select sum(field1) as sumvalue from table1
平均:select avg(field1) as avgvalue from table1
最大:select max(field1) as maxvalue from table1
最小:select min(field1) as minvalue from table1
分页:select * from table1 limit 0,5//第一个数是到第一行的偏移量(初始行是0不是1),第二个数是指定返回行的最大数目
参考资料:
