2017-2018-1 20155230《信息安全系统设计基础》第十三周学习总结
家庭作业:
- 3.58
long decode2(long x, long y, long z)
{
int result = x * (y - z);
if((y - z) & 1)
result = ~result;
return result;
}
- 3.59
因为w比特长度的两个数相乘,会产生一个2w长度的数,不管这两个数是无符号数还是补码表示的有符号数,把结果截取的低w比特都是相同的。所以我们可以用无符号数乘法指令mulq实现有符号数乘法:先把数有符号扩展致2w位,然后把这两个2w位的数相乘,截取低2w位即可。而截取就是求模运算,即 mod 2^w。
store_prod
movq %rdx, %rax #rax中保存y
cqto #将rax有符号扩展为rdx:rax,即rdx为全1
movq %rsi, %rcx #rcx中保存x
sarq $63, %rcx #rcx为为全1若x小于0,否则为0,即将x有符号扩展
#下面把这两个扩展的数当成无符号数进行运算,取低128bit。
#此时y表示为rdx:rax,x表示为rcx:rsi, 即y = rdx*2^64 + rax, x = rcx*2^64 + rsi
#x*y = rdx*rcx*2^128 + rdx*rsi*2^64 + rcx*rax*2^64 + rax*rsi
#由于我们只需要取低128位,所以对x*y进行取模操作mod 128,得到公式:rdx*rsi*2^64mod2^128 + rcx*rax*2^64mod2^128 + rax*rsi
#由于这里的寄存器都是64位的,所以对于rdx*rsi*2^64mod2^128这样的操作我们可以直接使用imulq指令,截取两个寄存器相乘的低64位,然后把他加到rax*rsi的高64位。
#下面实现公式
imulq %rax, %rcx #rcx*rax*2^64mod2^128(随后放在高64位)
imulq %rsi, %rdx #rdx*rsi*2^64mod2^128(随后放在高64位)
addq %rdx, %rcx #随后放在高64位
mulq %rsi #x*y即rax*rsi
addq %rcx, %rdx #放在高64位
movq %rax, (%rdi) #存储低64位
movq %rdx, 8(%rdi) #存储高64位
ret
- 3.60
A. x : %rdi n : %esi result : %rax mask : %rdx
B. result = 0 mask = 1
C. mask != 0
D. mask >>= n
E. result |= (x & mask)
long loop(long x, int n)
{
long result = 0;
long mask;
for(mask = 1; mask != 0; mask >>= n)
{
result |= (x & mask);
}
return result;
}
- 3.61
long cread_alt(long *xp)
{
static long tmp = 0;
if(xp == 0)
{
xp = &tmp;
}
return *xp;
}
00000000004004f0 <cread_alt>:
4004f0: 48 85 ff test %rdi,%rdi
4004f3: b8 38 10 60 00 mov $0x601038,%eax
4004f8: 48 0f 44 f8 cmove %rax,%rdi
4004fc: 48 8b 07 mov (%rdi),%rax
4004ff: c3 retq
- 3.62
typedef enum {MODE_A, MODE_B, MODE_C, MODE_D, MODE_E}
long switch3(long *p1, long *p2, mode_t action)
{
long result = 0;
switch(action)
{
case MODE_A:
result = *p2;
*p2 = *p1;
break;
case MODE_B:
result = *p1 + *p2;
*p1 = result;
break;
case MODE_C:
*p1 = 59;
result = *p2;
break;
case MODE_D:
*p1 = *p2;
case MODE_E:
result = 27;
break;
default:
result = 12;
}
return result;
}
- 3.63
long switch_prob(long x, long n)
{
long result = x;
switch(n)
{
case 0:
case 2:
result += 8;
break;
case 3:
result >>= 3;
break;
case 4:
result = (result << 4) - x;
case 5:
result *= result;
default:
result += 0x4b;
}
return result;
}
- 3.64
A. &A[i][j][k] = Xa + L(i*S*T + j*T + k)
B. R = 7,S = 5,T = 13
- 3.65
A. rdx (每次移位8,即按行移动)
B. rax(每次移位120 = 8 * 15,按列移动)
C. 由B,M = 15
- 3.66
NR(n)是数组的行数,所以我们找循环的次数,即rdi,得到rdi = 3n.
NC(n)是数组的列数,所以我们应该找每次循环更新时对指针增加的值,这个值等于sizeof(long) * NC(n),即r8,得到r8 = 8 * (4n + 1).
#define NR(n) (3*(n))
#define NC(n) (4*(n)+1)
- 3.67
A.
B. %rsp + 64
C. 通过以%rsp作为基地址,偏移8、16、24来获取strA s的内容(由于中间夹了一个返回地址,所以都要加8)
D. 通过传进来的参数%rdi(%rsp + 64 + 8),以此作为基地址,偏移8、16、24来写入strB r
E.
F. 题目读操作,可以发现编译器自动进行了优化——传递了基地址而非复制了整个数据结构。返回就是在调用它的函数的栈帧中存入一个相关的数据结构。
- 3.68
内存对齐可以通过结构体成员的位置逐渐缩小范围:
int t 为8(%rsi),所以4<B<=8
long u 为32(%rsi),所以24 < 8 + 4 + 2*a <= 32,得到6<A<=10
long y 为184(%rdi),所以176 < 4*A*B <= 184,得44 < A*B <=46。
所以AB = 45 或者AB = 46,结合A, B各自的范围,只可能为A = 9, B = 5.
- 3.69
A. 根据第4、5行的指令, idx的值为(bp + 40i + 8),由第1、2行指令,这里的8是因为第一个int first整数和内存对齐的原因,所以每一个a_struct的大小为40字节。
由于0x120 - 0x8 = 280字节,所以CNT = 280/40 = 7.
B. 由第6、7行指令知,idx和x数组内元素都是signed long类型的。由于整个a_struct数据类型大小为40字节,所以其内部应该为8*5 = 8 + 8*4:
typedef struct
{
long idx;
long x[4];
}
- 3.70
A.
e1.p : 0
e1.y : 8
e2.x : 0
e2.next : 8
B. 16 bytes
C.
void proc(union ele *up)
{
up->x = *(up->e2.next->e1.p) - up->e2.next->e1.y;
}
- 3.71
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#define SIZE_OF_BUFFER 10
int good_echo(void)
{
char *buffer = calloc(SIZE_OF_BUFFER, sizeof(char));
if (buffer == NULL)
{
fprintf(stderr, "Error: failed to allocate buffer.\n");
return -1;
}
while(1)
{
fgets(buffer, SIZE_OF_BUFFER, stdin);
if (strlen(buffer) == SIZE_OF_BUFFER-1) /*两种情况,一种是刚好输入了能填满缓冲区的字符数,另一种是大于缓冲区,一次不能读完*/
{
fputs(buffer, stdout);
if (buffer[SIZE_OF_BUFFER-1-1] == '\n')/*刚好输入了能填满缓冲区的字符数,结束读入*/
{
break;
}
memset(buffer, 0, strlen(buffer));/*清空缓冲区,因为要通过strlen判断读入了多少字符,继续读入*/
}
else if (strlen(buffer) < SIZE_OF_BUFFER-1)/*一定是最后一次读入,结束读入*/
{
fputs(buffer, stdout);
break;
}
else
{
break;
}
}
free(buffer);
return 0;
}
int main(int argc, char const *argv[])
{
return good_echo();
}
- 3.72
A. andq $-16, X这条指令相当于将低4位置零,也就是使得rax中保存的8n+30对16取整。所以s2-s1为8n+30对16取整的结果。
B. p的值为rsp(r8)-15对16取整的结果,确保了p数组的起始地址为16的整数倍。
C. 8n + 30对16取整有两种可能:一种是8n本身就是16的整数倍即n = 2k,此时取整后为8n+16; 另一种是8n = 16k + 8即n = 2k + 1,此时取整后为8n + 24。由System V AMD64 ABI标准可知,s1的地址为16的整数倍(即结尾为0000),所以s2的地址也肯定是16的整数倍(结尾为0000)。又因p是由s2减15对16取整得到的结果,所以p和s2之间肯定相差2字节,即e2 = 2 bytes. 所以e1最大为(n为奇数) :8n + 24 - 16 - 8n = 8 bit, 最小为(n为偶数):8n + 16 -16 - 8n = 0.(这个题我估计没有考虑到ABI标准对于栈帧对齐的问题,s1的地址本来就应该是16的整数倍)
D. 由A B C可知,这种方法保证了s2 和 p的起始地址为16的整数倍,而且保证了e1最小为8n,能够存储p数组。
- 3.73
find_range:
vxorps %xmm1, %xmm1, %xmm1
vucomiss %xmm0, %xmm1
ja .L5
jp .L8
movl $1, %eax
je .L3
.L8:
seta %al
movzbl %al, %eax
addl $2, %eax
ret
.L5:
movl $0, %eax
.L3:
rep;ret
- 3.74
find_range:
vxorps %xmm1, %xmm1, %xmm1
vucomiss %xmm0, %xmm1
cmova $0, %eax
cmove $1, %eax
cmovb $2, %eax
cmovp $3, %eax
rep;ret
- 3.75
A. 每一个复数变量使用两个%xmm寄存器传送。
B. 通过%xmm0和%xmm1返回一个复数类型值。
要点
-
二进制小数表示方法是依据小数点后几位来表示对应的2的负几次方,如二进制小数0.001表示十进制小数0.125,不过这种表示方法只能在表示x/2^n时能十分精确,形如十分之一这类分母不是2的几次方的小数,计算机只能通过二进制小数来近似表示。这类小数在不同的计算机容易引起不必要的误差。
-
我们知道了什么是虚拟存储器,也知道在计算机中这些基本进制的转换。然后就知道了信息在计算机中的大小用字来衡量,而且其中还有整数和浮点数的区分。还有IEEE标准下的浮点运算。C语言中浮点数分为float和double类型。在相同长度的无符号和有符号整数之间进行强制类型转换时,大多数C语言实现遵循的原则是底层的位模式不变。由于编码的长度有限,与传统整数何实数运算相比,计算机运算具有完全不同的属性。 掩码是位运算的重要应用,对特定位可以置一,可以清零。所有逻辑运算都可以用与、或、非表达(最大式、最小式),而与或非可以用“与非”或“或非”表达,所以,只要一个与非门,就可以完成所有的逻辑运算。
-
gcc 命令调用了一整套的程序,C预处理器扩展源代码、编译器产生两个源文件的汇编代码,名字分别是p1.s和p2.s、汇编器会将汇编代码转化成二进制目标文件p1.o和p2.o、链接器将两个目标代码文件与实现库函数的代码合并,产生最终的可执行代码文件P。
-
ISA(指令集体系结构或指令集架构)定义了处理器状态、指令的格式,以及每条指令对状态的影响。
-
程序计数器(通常称为PC,用%rip表示),给出将要执行的下一条指令在内存中的地址。
-
整数寄存器文件:包含16个命名的位置,分别存储64位的值。存储地(对应于C语言的指针)或整数数据。
-
条件码寄存器:保存最近执行的算数或逻辑指令的状态信息,它们用来实现控制或数据流中的条件变化。
-
一组向量寄存器可以存放一个或多个整数或浮点数值。
-
在命令行中使用-s选项,就能看到c语言编译器产生的汇编代码,这回产生一个.s文件
-
64位机器上想要得到32代码:gcc -m32 -S xxx.c
-
寄存器中esi edi可以用来操纵数组,esp ebp用来操纵栈帧。
-
对于寄存器32位的eax,16位的ax,8位的ah,al都是独立的。
-
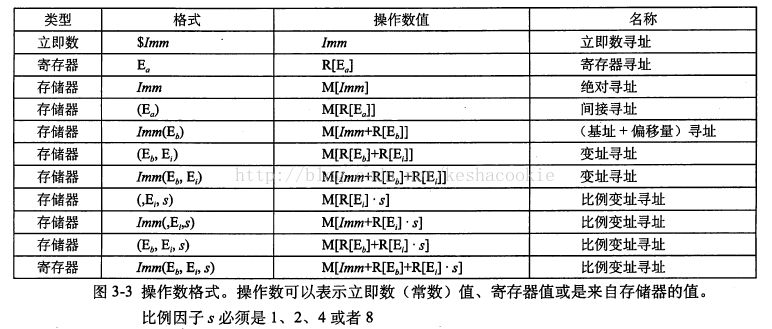
操作数的三种类型:立即数、寄存器、存储器
-
三种寻址方式:立即数寻址、寄存器寻址方式、存储器寻址方式寻址方式。
-
有效地址计算: Imm + R[rb] + R[ri]*s。
-
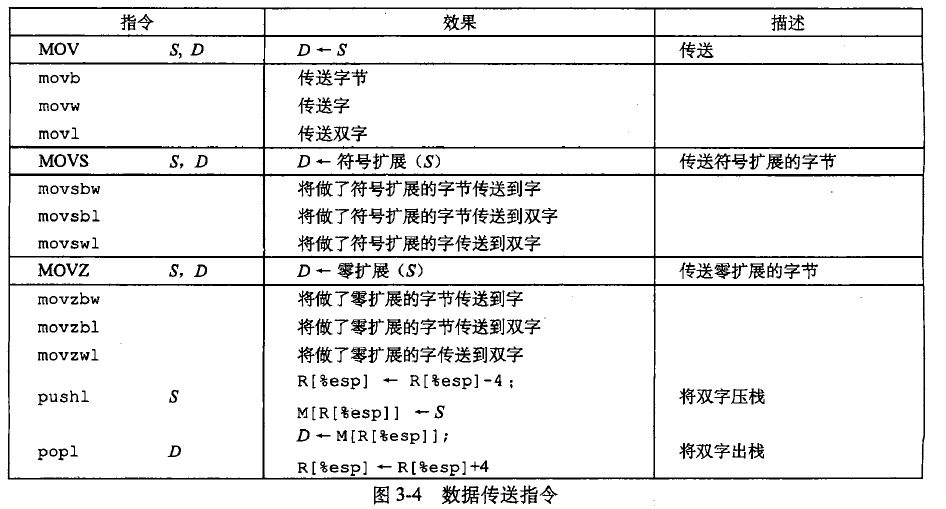
数据传送指令MOV:MOV相当于C语言中的赋值指令'='。不能从内存地址直接MOV到另一个内存地址,要用寄存器中转一下。
-
mov指令只会更新目的操作数指定的那些寄存器字节的内存位置。但movl时,会吧寄存器的高4个字节设置成0,movz指令把目的中剩余的字节填充为0,movs类中的指令通过符号扩展来填充,把源操作的最高位进行复制。
-
push和pop:push是入栈,pop是弹出,遵循先进后出的原则。
-
一元操作:只有一个操作数,既是源又是目的,可以是一个寄存器,或者存储器位置。二元操作:第二个操作数既是源也是又是目的,可以是寄存器或者存储器位置,但是不能同时是存储器位置。
-
移位操作:先给出移位量,第二项给出要移位的数值,未给出时右%cl寄存器的低m位决定。
-
条件码:CF:进位标志、ZF:零标志、SF:符号标志、OF:溢出标志。leal指令不改变任何条件码
-
CMP指令根据他们的两个操作数之差来设置条件码。除了只设置条件码而不更新目标寄存器之外,CMP与SUB行为是一样的。
-
条件码的使用方法:一般不直接读取 1.可以根据条件码的某个组合,将一个字节设置成0或1,2.可以跳转到程序某个其他的部分,3.可以有条件的传送数据。
-
c语言以及汇编中的控制跳转语句:
条件语句:
c语言:
if(a)
b;
else
c;
汇编:
if(a)
goto l1;
c;
goto end;
l1:
b;
end:
循环语句:
c语言:
do
b;
while(c);
汇编:
l1:
b;
if(c)
goto l1;
-
switch语句可以根据一个整数索引值进行多重分支,执行其的关键步骤是通过跳转表来访问代码位置。
-
IA32利用程序栈来支持过程调用。
-
call指令目标:即指明被调用过程起始的指令地址。调用可以是直接的也可以是间接的。
-
ret指令从栈中弹出地址A,并把PC设置为A。
-
backtrace/bt:打印当前的函数调用栈的所有信息。加n参数backtrace (-)n/bt -n:n是一个正整数,表示只打印栈顶上(下)n层的栈信息。
-
frame n:n是一个从0开始的整数,是栈中的层编号。比如:frame 0,表示栈顶,frame 1,表示栈的第二层。
-
up n表示向栈的上面移动n层,不加参数n,表示向上移动一层。
-
down n:表示向栈的下面移动n层,不加参数n,表示向下移动一层。
- movb、movsbl和movzbl之间的差别:寄存器%eax 的低位字节设置为%edx 的第二个字节。movb指令不改变其他三个字节。根据原字节的最高为,movsbl指令将其他三个字节设为全1或全0。movzbl指令无论如何都是将其他三个字节设为全0。
假设 %dh =8D,%eax=98765432
movb %dh ,%a1 %eax=9876548D
movsbl %dh , %eax %eax=FFFFFF8D
movzbl %dh,%eax %eax=0000008D
我的问题和理解
- 问题1:一个程序在运行过程中,一个函数会调用另一个函数(比如递归),那么函数在进入的时候都会往栈里压点什么东西,函数退出时会弹出点什么东西,内层的函数是如何返回的,返回给外层函数的谁,返回到哪里,内层函数是怎么知道返回地址的?
会压入: 原来ebp的值, 参数, 以及调用函数的下一个指令地址,在调用一个函数时, 编译器就计算好函数需要的空间, 然后esp = ebp-需要的空间, 通过ebp+偏移量来访问。在函数里调用另外一个函数时, 原来fun的ebp值压栈。
- 问题2:什么是算术运算?什么是关系运算?什么是逻辑运算?
算术运算、关系运算和逻辑运算是计算机运算中的基本运算方式。
算术运算是基本的数值运算,在C语言中有加、减、乘、除和除余五种。另外还有单项算术运算和前置运算和后置运算等变化。输出值还是数值。
关系运算主要是对两个 运算量进行大小 关系的比较,输入值为1或0两个逻辑值。
逻辑运算是表示运算量的逻辑关系,运算的结果也是1或者0.
各种运算在同一个算式中也有顺序问题,C语言的运算顺序比较复杂,有15个优先级。
结伴学习
- 与结对伙伴共同学习的是第3章,对于本身汇编就没怎么学好却要在后面的学习中学习网络攻防的我们来说,这一章至关重要,我们需要汇编的指令进行优化、寻找、攻击漏洞。我对我自己对汇编的要求就是能看懂和分析,不要求能够编写复杂的汇编程序。以上有我们小组在这周的再一次的学习中存在的疑问。
代码托管
学习进度条
| 代码行数(新增/累积) | 博客量(新增/累积) | 学习时间(新增/累积) | 重要成长 | |
|---|---|---|---|---|
| 目标 | 5000行 | 30篇 | 400小时 | |
| 第一周 | 7/7 | 1/1 | 4/4 | |
| 第三周 | 62/69 | 2/3 | 15/19 | |
| 第五周 | 161/230 | 2/5 | 22/41 | |
| 第七周 | 82/312 | 1/6 | 17/58 | |
| 第八周 | 140/452 | 1/7 | 15/73 | |
| 第九周 | 57/509 | 3/10 | 18/91 | |
| 第十一周 | 104/613 | 1/11 | 14/105 | |
| 第十三周 | 276/889 | 2/13 | 19/124 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号