
个人项目-论文查重
Github链接
👉👉👉👉 我的Github链接 👈👈👈👈
PSP
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 35 |
| · Estimate | 估计这个任务需要多少时间 | 30 | 35 |
| Development | 开发 | 400 | 420 |
| · Analysis | 需求分析 (包括学习新技术) | 60 | 80 |
| · Design Spec | 生成设计文档 | 40 | 45 |
| · Design Review | 设计复审 | 30 | 30 |
| · Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 20 | 20 |
| · Design | 具体设计 | 50 | 60 |
| · Coding | 具体编码 | 120 | 130 |
| · Code Review | 代码复审 | 30 | 35 |
| · Test | 测试(自我测试,修改代码,提交修改) | 50 | 60 |
| Reporting | 报告 | 90 | 100 |
| · Test Report | 测试报告 | 30 | 35 |
| · Size Measurement | 计算工作量 | 30 | 30 |
| · Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 30 | 35 |
| 合计 | 520 | 555 |
项目结构
/resources
├── orig.txt # 原始文本
├── orig_0.8_add.txt # 修改后的文本(添加部分内容)
├── orig_0.8_del.txt # 修改后的文本(删除部分内容)
├── orig_0.8_dis_1.txt # 修改后的文本(较少的词语变动)
├── orig_0.8_dis_10.txt # 修改后的文本(中等程度的词语变动)
├── orig_0.8_dis_15.txt # 修改后的文本(较多的词语变动)
/utils
├── SimHash.py # SimHash 算法的实现,用于计算文本的哈希值和相似度
├── SimilarityCal.py # 相似度计算模块,包含文件读取和相似度输出逻辑
├── TextUtil.py # 文本处理工具,负责分词、去除标点符号等操作
main.py # 主程序入口,负责调用各模块,计算并输出文本相似度
test_main.py # 单元测试文件,包含项目的测试用例
requirements.txt # 项目依赖的库和版本
功能实现概述
本项目的主要功能是实现一个论文查重算法,通过对原文和抄袭文本进行相似度计算,输出两者的重复率。该功能的核心算法基于SimHash,一种用于高效文本相似度计算的算法。
1. 算法原理
- SimHash 算法:SimHash 是一种局部敏感哈希算法,能够将高维文本特征映射为固定长度的二进制向量,两个文本的相似度通过计算它们的哈希值之间的海明距离来衡量。
- 文本分词:首先将文本转换为一系列标记(词或标点),并且通过算法删除部分标点符号。
- 特征加权:对每个词计算哈希值,并根据其权重调整哈希向量的加权值。
- 哈希值生成:通过计算加权后的向量,生成固定长度的 SimHash 值。
- 相似度计算:对两个文本的 SimHash 值计算海明距离,海明距离越小,相似度越高。
2. 调用过程简述
-
程序启动:
- 通过命令行调用主程序
main.py,传入原文文件路径、抄袭文本文件路径和输出文件路径。 - 命令示例:
python main.py orig.txt plag.txt output.txt
- 通过命令行调用主程序
-
文件读取:
- 使用
TextUtil.py中的read_file()函数读取原文和抄袭文本的内容。如果文件不存在或为空,程序会抛出异常并返回错误提示。
- 使用
-
分词处理:
- 调用
TextUtil.py中的tokenize()函数,对文件内容进行分词,并删除部分标点符号,以生成处理后的词汇列表。
- 调用
-
SimHash 计算:
- 使用
SimHash.py中的simhash()函数,对每个分词生成哈希值,并计算出两个文本的 SimHash 哈希值。
- 使用
-
相似度计算:
- 通过
SimHash.py中的hamming_distance()函数,计算两个 SimHash 值之间的海明距离。 - 根据海明距离,调用
SimilarityCal.py中的calculate_similarity()函数,计算两个文本的相似度,并输出百分比格式的重复率(精确到小数点后两位)。
- 通过
-
结果输出:
- 相似度计算完成后,程序将结果写入到输出文件中,格式为
重复率:百分比。
- 相似度计算完成后,程序将结果写入到输出文件中,格式为
3. 异常处理
- 当输入文件不存在或为空时,系统会给出提示,并返回 0% 的相似度,确保程序的稳健性。
测试
测试代码
import unittest
from utils.SimHash import simhash, hamming_distance
from utils.SimilarityCal import calculate_similarity
from utils.TextUtil import tokenize, read_file
import os
class TestSimHash(unittest.TestCase):
def test_simhash_identical_text(self):
tokens = tokenize("Hello world!")
simhash_value = simhash(tokens)
self.assertEqual(simhash_value, simhash(tokens)) # SimHash values should be identical
def test_simhash_different_text(self):
tokens1 = tokenize("Hello world!")
tokens2 = tokenize("Goodbye world!")
self.assertNotEqual(simhash(tokens1), simhash(tokens2)) # Different texts should produce different SimHash values
def test_hamming_distance(self):
tokens1 = tokenize("Hello world!")
tokens2 = tokenize("Goodbye world!")
simhash1 = simhash(tokens1)
simhash2 = simhash(tokens2)
self.assertGreater(hamming_distance(simhash1, simhash2), 0) # Ensure Hamming distance is non-zero
def test_empty_file(self):
with open('empty.txt', 'w') as f:
f.write("")
with open('empty.txt', 'r') as f:
result = f.read()
self.assertEqual(result, "") # Empty files should return empty content
os.remove('empty.txt')
def test_calculate_similarity_identical(self):
with open('test1.txt', 'w') as f:
f.write("This is a test.")
with open('test2.txt', 'w') as f:
f.write("This is a test.")
calculate_similarity('test1.txt', 'test2.txt', 'output.txt')
with open('output.txt', 'r') as f:
output = f.read()
self.assertEqual(output, "100.00") # Identical files should have 100% similarity
os.remove('test1.txt')
os.remove('test2.txt')
os.remove('output.txt')
def test_calculate_similarity_different(self):
with open('test1.txt', 'w') as f:
f.write("This is a test.")
with open('test2.txt', 'w') as f:
f.write("Completely different content.")
calculate_similarity('test1.txt', 'test2.txt', 'output.txt')
with open('output.txt', 'r') as f:
output = f.read()
self.assertLess(float(output), 100.00) # Completely different files should have less than 100% similarity
os.remove('test1.txt')
os.remove('test2.txt')
os.remove('output.txt')
def test_tokenize_with_punctuation(self):
text = "Hello, world!"
tokens = tokenize(text)
self.assertIn("world", tokens)
self.assertIn("Hello", tokens)
def test_tokenize_random_punctuation_removal(self):
text = "This, is a test!"
tokens = tokenize(text)
self.assertIn("test", tokens) # Ensure words remain intact
# Check that some punctuation is removed, but not all
self.assertTrue(any(punct in tokens for punct in [',', '!']))
def test_tokenize_no_punctuation(self):
text = "Hello world"
tokens = tokenize(text)
self.assertEqual(tokens, ["Hello", "world"])
def test_calculate_similarity_partially_similar(self):
with open('test1.txt', 'w') as f:
f.write("Hello world!")
with open('test2.txt', 'w') as f:
f.write("Hello universe!")
calculate_similarity('test1.txt', 'test2.txt', 'output.txt')
with open('output.txt', 'r') as f:
output = f.read()
self.assertGreater(float(output), 0.00)
self.assertLess(float(output), 100.00) # Files with some overlap should have similarity between 0 and 100
os.remove('test1.txt')
os.remove('test2.txt')
os.remove('output.txt')
def test_read_file_nonexistent(self):
# Test non-existent file case
with self.assertRaises(ValueError):
read_file("nonexistent_file.txt")
def test_calculate_similarity_nonexistent_file(self):
# Test similarity calculation with nonexistent file
with self.assertRaises(ValueError):
calculate_similarity('nonexistent1.txt', 'nonexistent2.txt', 'output.txt')
def test_calculate_similarity_empty_file(self):
# Test similarity calculation with empty file
with open('empty.txt', 'w') as f:
f.write("")
with self.assertRaises(ValueError):
calculate_similarity('empty.txt', 'empty.txt', 'output.txt')
# os.remove('empty.txt')
def test_calculate_similarity_invalid_content(self):
# Case where files have invalid content (e.g., only spaces or empty tokens)
with open('test_invalid1.txt', 'w') as f:
f.write(" ") # Invalid content, only spaces
with open('test_invalid2.txt', 'w') as f:
f.write(" ") # Invalid content, only spaces
calculate_similarity('test_invalid1.txt', 'test_invalid2.txt', 'output_invalid.txt')
# Check if the output is "0.00" due to invalid content
with open('output_invalid.txt', 'r') as f:
output = f.read()
self.assertEqual(output, "0.00") # Expecting 0.00 similarity for invalid content
# Cleanup
os.remove('test_invalid1.txt')
os.remove('test_invalid2.txt')
os.remove('output_invalid.txt')
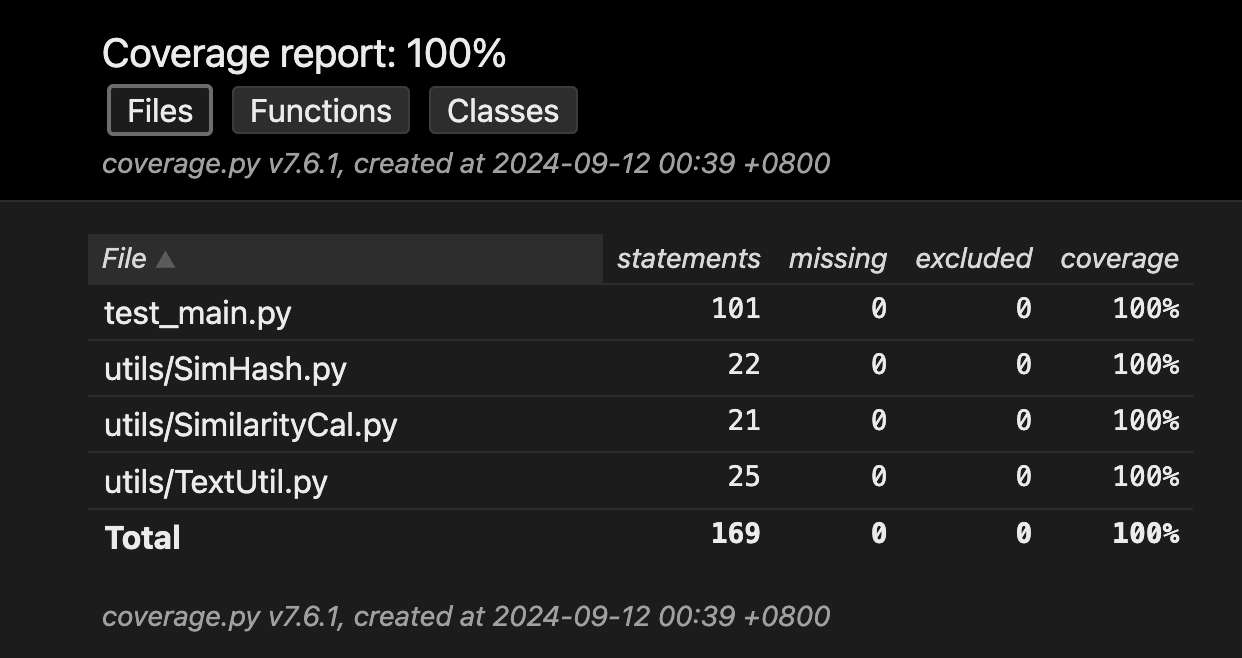
测试结果
内存使用

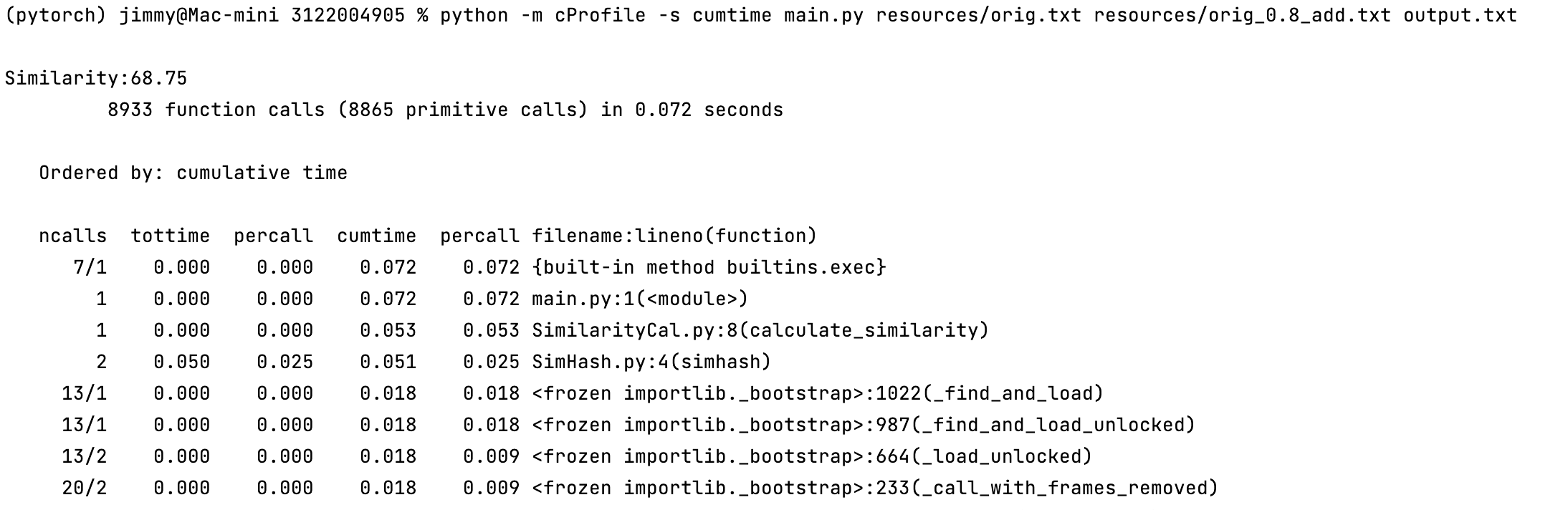
性能分析
使用cprofile查看代码调用次数和运行时间,基本上没有可以优化的空间,只将原本手动去除标点符号的方法,修改为使用正则表达式。
虽然代码调用次数大幅减少,但是运行时间基本没有变化。最后最大调用次数是哈希值计算函数,未来可优化的地方为手动实现哈希值的计算。

【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步