Ins图片爬取(基于python,selenium)
最近迷上了@桐谷美玲_MireiKiritani小姐姐的颜值,于是在Ins上也关注了一波,于是发现了一大波美图,可是ins出于版权方面的考虑并不在客户端和网页端直接提供图片的下载功能,由于之前学习python的最初阶段就学过爬虫,于是重操旧业打起了爬取美图的打算,也算是对python的一点复习吧。
part1:ins及其图片下载方式
移动端操作不便,而且学校IPV6网络设置好hosts就能轻松访问ins(虽然有时候不太稳定,不过这几天好像还可以=,=),首选通过PC端网页爬取。
用Chrome打开ins之后按F12就能进入开发模式,选取上面的图片就能找到相应的图片入口,但打开相应的div可以发现在当前页面下的图片全都是缩略图,所能获得的最大分辨率仅为640*640。这显然不能达到要求(`・ω・´),于是我开始找原图的URL。
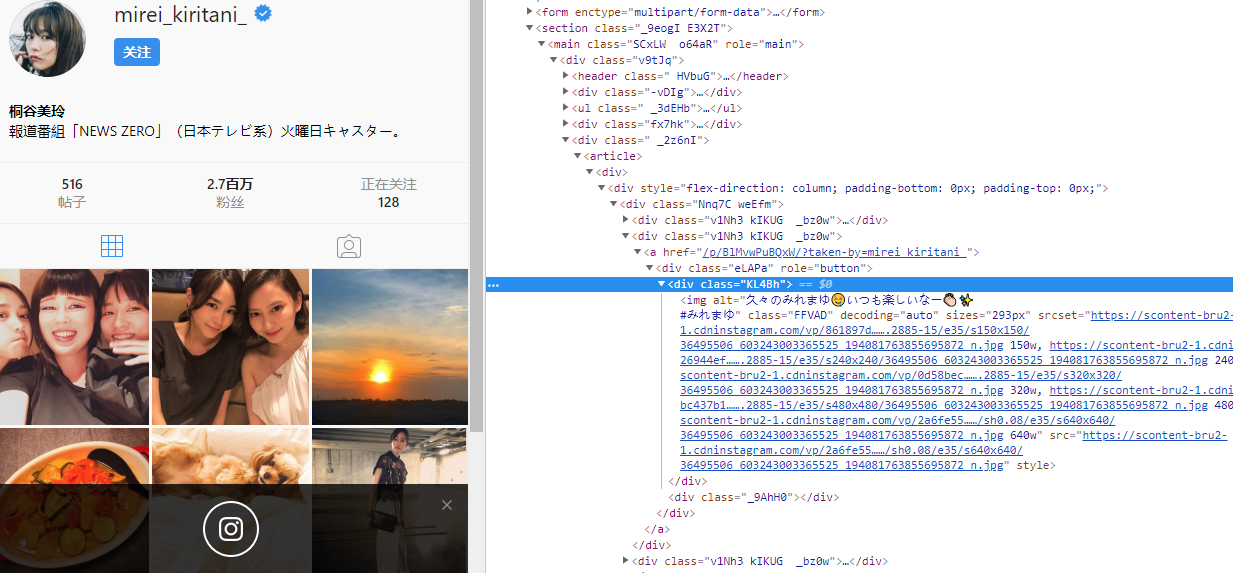
还有一个问题就是ins上面的图片全部都是使用js动态生成的,也就意味着我们在使用requests模块get到的内容仅仅是网页框架和一堆js脚本而已,对网页上的network进行监听就能看到js进行的xmlhttp requests.我们甚至能够在xmlhttp requests中找到原始图片的URL,但问题就是这个xmlhttp requests在向服务器发送请求时需要一个Query String,里面有一串需要随机生成的variable。可以通过查找页面的js代码找到这串key的生成代码,但对于好久没用js的我来说这段js代码无异于天书,感觉看懂需要把前端的知识好好复习复习。在这里我显然并没有这样的打算。
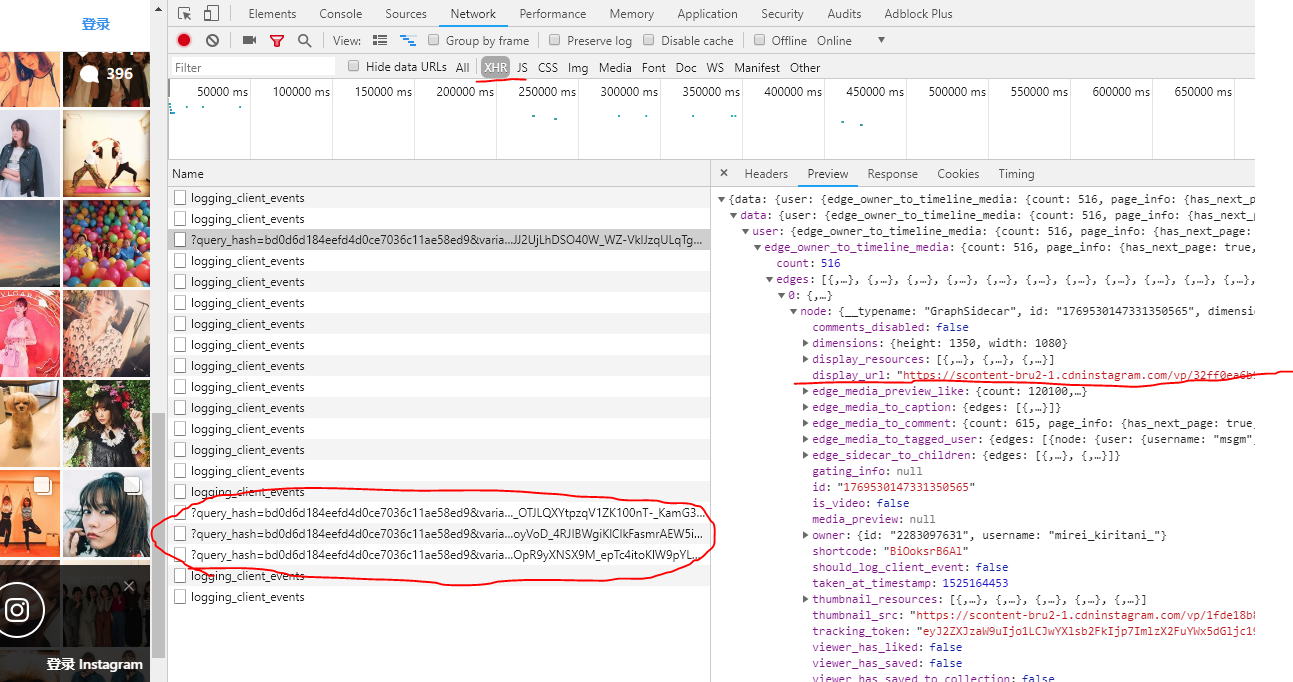
页面xmlhttp-request加载

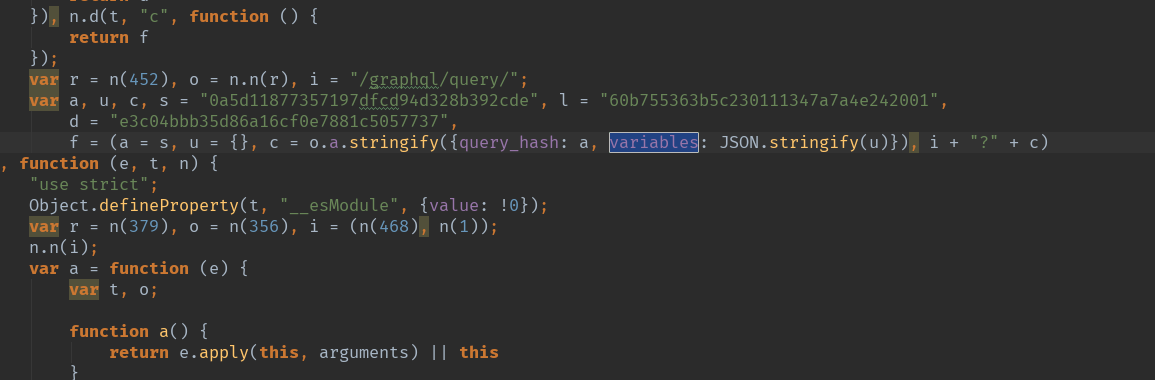
js中variable生成的部分代码
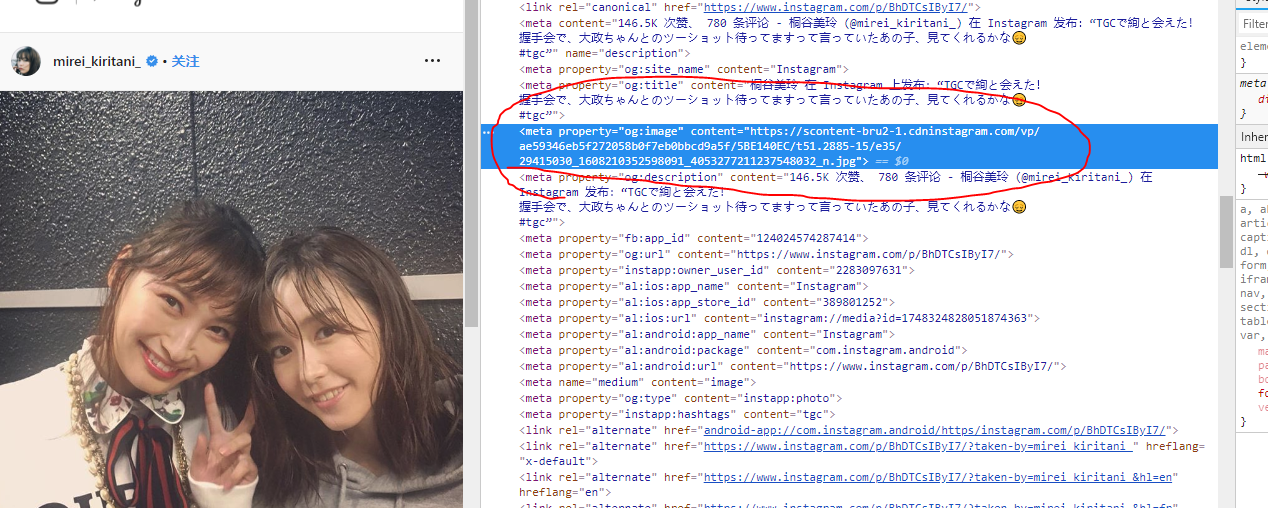
我们似乎需要找到一个更可行的方法来获得ins上原始图片的URL,而这个方法就在这个页面上。我们可以点开每一张图片从而到达图片详情页,而在详情页里面自然就有我们所需要的原图URL。而且幸运的是在图片详情页的html中,我们可以直接使用requests获得这个url!
part2 技术与方法构思
我们需要下载图片就需要获得每张图片的URL,经过前面的讨论我已经大致确定了URL获取方式:
ins个人主页 --> ins图片详情页URL --> ins图片详情页 -->详情页中的原图URL
就像前面说到过的,ins个人主页上的图片是通过js动态生成的,这就意味着我们没有办法通过requests简单的获得所有所需的URL,这时候对于并不精通js相关的我来说也就只剩下selenium模拟浏览器这一条路了。关于selenium我在这里也不想多说,之前我也使用过,不过并不熟,配合着文档和Google也就能实现自己所需要的功能了。
整个技术思路就是通过selenium模拟浏览器行为获得ins个人主页上面关于所有图片详情页的URL,然后通过URL使用requests获得所有详情页的HTML,最后通过html解析模块获得相应原始图片url,最后直接使用requests下载图片。
part3 代码与遇到的问题
好久没写Python和爬虫了,虽然大致过程还是有数,但做起来还是需要边测试边搜索文档,这里由于selenium与chrome的加入,对于一些设计网络和程序控制方面的东西还是需要自己尝试。
import requests import time import os from lxml import etree from selenium import webdriver from selenium.webdriver.common.keys import Keys from selenium.webdriver.common.action_chains import ActionChains options = webdriver.ChromeOptions() options.add_argument('lang=zh_CN.UTF-8') driver = webdriver.Chrome(chrome_options = options) target = "https://www.instagram.com/mirei_kiritani_/" url_set = set([]) driver.get(target) url_set=set([])#set用来unique URL pic_index = 0 url_set_size = 0 save_dir = './pic/' if not os.path.exists(save_dir): os.mkdir(save_dir) header = { #requests header最好设置一下,否则服务器可能会拒绝访问 'accept': '*/*', 'accept-encoding': 'gzip, deflate, br', 'accept-language': 'zh-CN,zh;q=0.9,en;q=0.8,en-US;q=0.7', 'cookie': 'shbid=4419; rur=PRN; mcd=3; mid=W1E7cAALAAES6GY5Dyuvmzfbywic; csrftoken=uVspLzRYlxjToqSoTlf09JVaA9thPkD0; urlgen="{\"time\": 1532050288\054 \"2001:da8:e000:1618:e4b8:8a3d:8932:2621\": 23910\054 \"2001:da8:e000:1618:6c15:ccda:34b8:5dc8\": 23910}:1fgVTv:SfLAhpEZmvEcJn0037FXFMLJr0Y"', 'referer': 'https://www.instagram.com/', 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36', } while(True): divs = driver.find_elements_by_class_name('v1Nh3') #这里最好使用xxxx_by_class_name,我尝试过用xpath绝对路径,但是好像对于页面变化比较敏感 for u in divs: url_set.add(u.find_element_by_tag_name('a').get_attribute('href')) if len(url_set) == url_set_size: #如果本次页面更新没有加入新的URL则可视为到达页面底端,跳出 break url_set_size = len(url_set) ActionChains(driver).send_keys(Keys.PAGE_DOWN).perform()#三次滑动,保证页面更新足够 ActionChains(driver).send_keys(Keys.PAGE_DOWN).perform() ActionChains(driver).send_keys(Keys.PAGE_DOWN).perform() time.sleep(3) #下载图片: def pic_download(u_download): global pic_index rec = requests.get(u_download, headers = header) selector = etree.HTML(rec.content) meta = selector.xpath('/html/head/meta[10]')[0] #使用xpath解析页面 real_pic_url = meta.get("content").strip() pic_extend = real_pic_url[-4:] file_name = save_dir + "mirei_" + str(pic_index) + pic_extend pic_index += 1 f = open(file_name,'wb') pic_bin = requests.get(real_pic_url).content f.write(pic_bin) f.close() for url_ in url_set: pic_download(url_)
主要还是在控制chrome滑动窗口的时候需要对滑动次数和页面HTML更新速度进行微调,否则会出现selenium没法获取页面变化的问题。还有就是在获取url的时候最好保持chrome在前台运行(反正不能最小化,可能无法PAGEDOWN?),否则会出问题。
最后想说的就是这只是一个最简陋的爬虫,后续在下载,解析过程中有很多可以优化的地方,比如并发下载,selenium设置优化等等,这里我就不深入了。
附上下载后的美图(づ ̄3 ̄)づ╭❤~
参考:
http://selenium-python-zh.readthedocs.io/en/latest/locating-elements.html
https://blog.csdn.net/lb245557472/article/details/79978374

 浙公网安备 33010602011771号
浙公网安备 33010602011771号