

DiscoGAN
一、目的
提出一个基于GAN的网络框架来学习发现跨域关系(cross-domain relation),把寻找这种关系变成了用一种风格的图片生成另一种风格。
下面是论文列举的手提包生成鞋、鞋生成手提包的示意图。

二、模型
标准的GAN模型
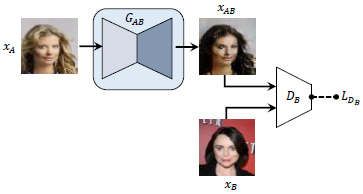
图中xA、xB分别表示A里面和B里面的真实样本,xAB表示真实样本xA经生成器GAB生成的样本。
标准的GAN模型很容易发生模式崩溃。
带有重建损失的GAN模型
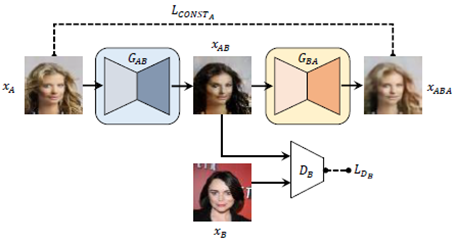
GAB表示域A到域B的生成器,GBA表示域B到域A的生成器。为了找到有意义的对应关系,需要将这个映射限制成一对一映射,意思就是说,GAB和GBA应该是刚好相反的映射。对于所有的A里面的真实样本xA,GAB(xA)都要在B里面,对于GBA(xB)也一样。
基于前面所提出的一对一映射,对于所有的A里面的真实样本xA,GAB(xA)都要在B里面,这相当于要满足GBA(GAB(xA))=xA这个条件,但是这个条件很难优化,于是改为最小化距离d(GBA(GAB(xA)),xA),这个d可以是L1,L2等等的度量函数。
生成器的损失函数如下:
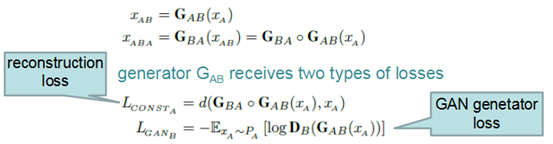
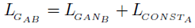
生成器GAB收到两个损失,一个是重建损失(reconstruction loss),描述经过两个生成器之后的重建效果与原始真实样本的差距,另外一个是原始GAN的生成损失,表示GAB生成的样本来自B的逼真性。
判别器的损失如下:
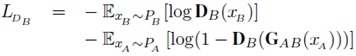
D表示相应域的判别器。
相对于原始的GAN模型,这里的重建约束虽然迫使重建样本与原始的一样,但是这仍然会导致类似的模式崩溃问题。
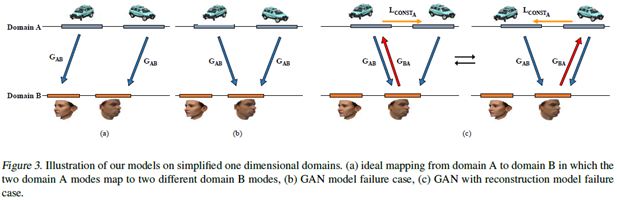
(a)是我们理想的映射,一对一的;(b)是原始GAN的结果,A中的多个模式映射到了B中的一个模式,就是模式崩溃的情况;(c)是加入了重建损失的GAN,A中两个模式的数据都映射到了B中的一个模式,而B中一个模式的数据只能映射到A中这两个模式中的一个。重建损失使得模型在(c)中的两个状态之间震荡,而并不能解决模式崩溃问题。
对(c)的解释:当出现模式崩溃时,重建损失强制要求重建样本和原来的样本一样,所以会在DomainA中两个模式之间震荡。
DiscoGAN
为了解决模式崩溃的问题,就要使得不管是GAB还是GBA,不同模式生成出来的就应该是不同的,于是很自然地想到了对称结构,就是再加一个反过来的生成网络,迫使A和B中的数据一一对应。
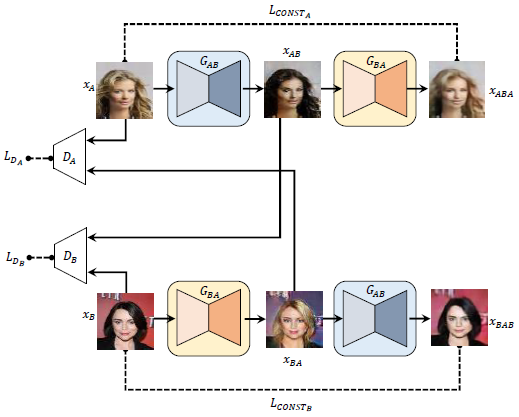
模型中包含两个生成器GAB,这两个GAB是一样的,还有两个生成器GBA,这两个也是一样的。这样就实现了一对一的映射。
损失函数如下:
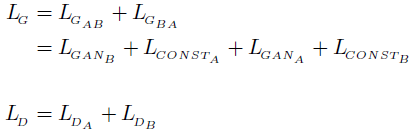
网络结构:

三、实验
toy实验
首先为了证明所提出的这种对称模型对于模式崩溃问题的良好性能,做了一个演示实验。A和B中的数据都是二维的,真实样本都取自混合高斯模型。用3个线性层和一个ReLU激活层作为生成器,判别器用5个线性层,每层后面接一个ReLU层,最后再接一个sigmoid层将输出限定在[0,1]之间。
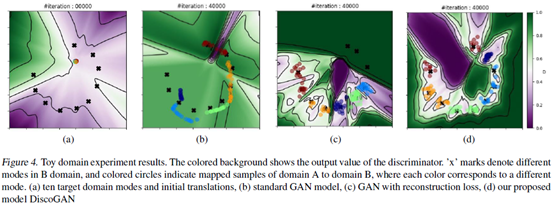
彩色背景表示判别器的输出值,”x”表示B种不同的模式。(a)标示了10个目标模式和最初的转换结果;(b)是标准的GAN迭代40000次的结果;(c)是加入重建损失的网络迭代40000次的结果;(d)是文章提出的DiscoGAN迭代40000次后的结果。标准GAN的许多不同颜色的转换点都位于B相同的模式下,海蓝和浅蓝色的点离得很近,橙色和绿色的点也在一起,多种颜色的点(A中的多种模式)都映射到B的同一种模式下。带有重建损失的GAN的模式崩溃问题已经不那么严重了,但是海蓝、绿色和浅蓝色的点仍然会在少数几个模式上重叠。标准的GAN和带有重建损失的GAN都没有覆盖B中的所有模式,DiscoGAN将A中的样本转换为B中有边界不重叠的区域,避免了模式崩溃,并且产生的B样本覆盖了所有10种模式,因此这个映射是双射,从A转换的样本也把B的鉴别器个骗过了。
转换实验
汽车到汽车,人脸到人脸,性别转换(a,b),头发颜色转换(c),是否戴眼镜转换(d),先转换性别再转换头发颜色(e),头发颜色、性别来回转(f),椅子到汽车,汽车到人脸







轮廓和图像互转

