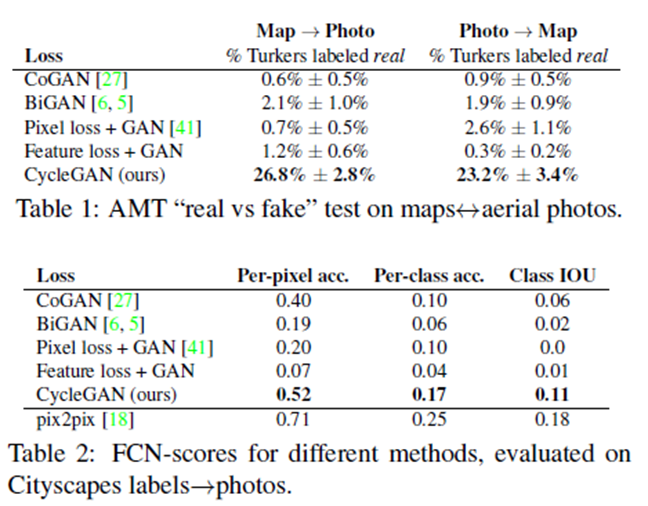
CycleGAN
CycleGAN解决了模型需要成对数据进行训练的困难。
前文说到的pix2pix,它和CycleGAN的区别在于,pix2pix模型必须要求 成对数据 (paired data),而CycleGAN利用 非成对数据 也能进行训练(unpaired data)。
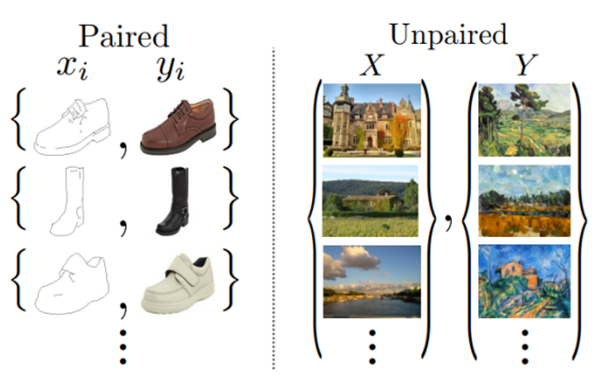
CycleGAN的原理可以概述为: 将一类图片转换成另一类图片 。也就是说,现在有两个样本空间,X和Y,我们希望把X空间中的样本转换成Y空间中的样本。(获取一个数据集的特征,并转化成另一个数据集的特征)
因此,实际的目标就是学习从X到Y的映射。我们设这个映射为F。它就对应着GAN中的 生成器 ,F可以将X中的图片x转换为Y中的图片F(x)。对于生成的图片,我们还需要GAN中的 判别器 来判别它是否为真实图片,由此构成对抗生成网络。设这个判别器为 。这样的话,根据这里的 生成器 和 判别器 ,我们就可以构造一个GAN损失,表达式为:
![]()
这个损失实际上和原始的GAN损失是一模一样的。
从理论上讲,对抗训练可以学习和产生与目标域Y相同分布的输出。但单纯的使用这一个损失是无法进行训练的。原因在于,在足够大的样本容量下,网络可以将相同的输入图像集合映射到目标域中图像的任何随机排列,其中任何学习的映射可以归纳出与目标分布匹配的输出分布(即:映射F完全可以将所有x都映射为Y空间中的同一张图片,使损失无效化)。
因此,单独的对抗损失Loss不能保证学习函数可以将单个输入Xi映射到期望的输出Yi。
对此,作者又提出了所谓的“循环一致性损失”(cycle consistency loss)。
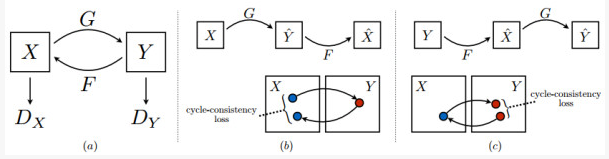
我们再假设一个映射G,它可以将Y空间中的图片y转换为X中的图片G(y)。CycleGAN同时学习F和G两个映射,并要求 ![]() 以及
以及 ![]() 也就是说,将X的图片转换到Y空间后,应该还可以转换回来。这样就杜绝模型把所有X的图片都转换为Y空间中的同一张图片了。
也就是说,将X的图片转换到Y空间后,应该还可以转换回来。这样就杜绝模型把所有X的图片都转换为Y空间中的同一张图片了。
根据 ![]() 和
和 ![]() 循环一致性损失就定义为:
循环一致性损失就定义为:
![]()
同时,我们为G也引入一个判别器 ![]() 由此可以同样定义一个GAN的损失
由此可以同样定义一个GAN的损失 ![]() 最终的损失就由三部分组成:
最终的损失就由三部分组成:
![]()
实现过程
- 网络结构
生成网络使用了这篇文章中的网络结构。判别器网络采用了70*70的PathGANs。
2. 训练细节
<1> 两个操作使得模型训练更加稳定
(1)对于LGAN使用最小二乘损失替换对数loss
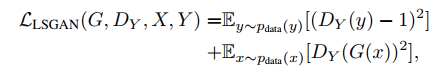
(2)在DX,DY中,使用先前生成的图片而不是最近生成的。使用一个能容纳50张图像的图像池。
<2> λ的值设置为10.使用Adam优化求解,batch size为1.前100个epoch学习率设置为0.0002,后100个epoch学习率线性递减直至0.
限制
对颜色、纹理等的转换效果比较好,对多样性高的、多变的转换效果不好(如几何转换)。
加上弱或半监督效果会更好。
注:

恒等映射,保护颜色。

实验