

DCGAN
DCGAN对卷积神经网络的结构做了一些改变,以提高样本的质量和收敛的速度,这些改变有:
-
取消所有pooling层。G网络中使用转置卷积(transposed convolutional layer)进行上采样,D网络中用加入stride的卷积代替pooling。
-
在D和G中均使用batch normalization(让数据更集中,不用担心太大或者太小的数据,可以稳定学习,有助于处理初始化不良导致的训练问题,也有助于梯度流向更深的网络,防止G崩溃。同时,让学习效率变得更高。)
-
去掉全连接层,而直接使用卷积层连接生成器和判别器的输入层以及输出层,使网络变为全卷积网络
-
G网络中使用ReLU作为激活函数,最后一层使用tanh
-
D网络中使用LeakyReLU作为激活函数
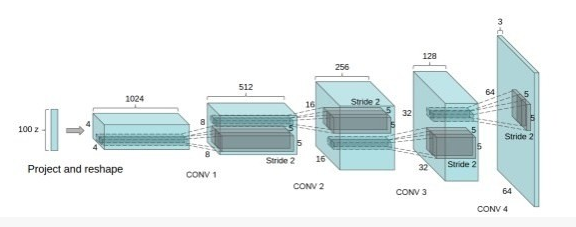
DCGAN中的G网络示意:
对于BN:
(1)把BN用到每一层会导致样本震荡和模型不稳定,不要把BN用到生成器的输出层和判别器的输入层。
(2)直接用 batch norm 可能是有问题的。同一批(batch)里面的数据太过相似,对一个无监督的 GAN 而言,很容易被带偏而误认为它们这些数据都是一样的。也就是说,最终的生成模型的结果会混着同一个 batch 里好多其它特征。这不是我们想要的形式。可以用RBN或者VBN克服。
Reference Batch Norm:
取出一批数据(固定的)当作我们的参照数据集 R。然后把新的数据 batch 都依据 R 的平均值和标准差来做规范化。
这个方法也有一些问题:如果 R 取得不好,效果也不会好。或者,数据可能被 R 搞得过拟合。换句话说:我们最后生成的数据可能又都变得跟 R 很像。
Virtual Batch Norm:
这里,我们依旧是取出 R,但是所有的新数据 x 做规范化的时候,我们把 x 也加入到 R 中形成一个新的 virtual batch V。并用这个 V 的平均值和标准差来标准化 x。这样就能极大减少 R 的风险。
DCGAN对抗训练细节
训练图像除了缩放到tanh激活函数的[-1,1]范围之外没有经过其他的预处理。所有的模型都是通过小批量随机梯度下降法(mini-batch stochastic gradient descent)进行训练的, 小批量的大小是 128。 所有权重的初始化为均值为 0 和方差为 0.02的正态分布。在LeakyReLU, 所有模型的leak的斜率设置为0.2。之前的 GAN是使用momentum加快训练速度,DCGAN是使用Adam优化程序调整超参数。建议使用的学习率是0.001,太高的话使用0.0002代替。此外,动量项beta1在建议的0.9训练动荡且不稳定,但降低到0.5是有利于模型的稳定。
