下载和整理数据包括了表达数据和临床数据。
下载和整理好了数据之后,提取目标基因的表达量。
① 差异分析:可以观察这个基因在正常样品和肿瘤样品之间是否具有差异。
② 生存分析:通过生存分析,可以观察目标基因的表达量与病人的预后之间是否具有相关性。
③ 临床相关性分析:通过临床相关性分析,可以观察目标基因的表达量在不同的临床分组之间是否具有差异。
④ 绘制列线图和校准曲线。
⑤ 根据目标基因的表达量对样品进行分组,将样品分成高低表达两组,然后对两组进行差异分析,找到高低表达组的差异基因。
⑥ 对差异基因进行GO和KEGG富集分析,观察差异基因在哪些功能和通路上富集。
⑦ 免疫细胞浸润分析:观察哪些免疫细胞与目标基因之间具有相关性。
⑧ 肿瘤突变负荷的分析。
⑨ 药物敏感性分析:对药物进行循环观察,哪些药物的敏感性在目标基因的高低表达组之间是具有差异的。
⑩ 免疫治疗分析:通过免疫治疗分析,观察高低表达组之间哪个分组在接受免疫治疗的时候效果是更好的。
肿瘤的简写:
| 癌种 | 缩写 | 中文名称 | 癌种 | 缩写 | 中文名称 |
| Adrenocortical carcinoma | ACC | 肾上腺皮质癌 | Lung squamous cell carcinoma | LUSC | 肺鳞癌 |
| Bladder Urothelial Carcinoma | BLCA | 膀胱尿路上皮癌 | Mesothelioma | MESO | 间皮瘤 |
| Breast invasive carcinoma | BRCA | 乳腺浸润癌 | Ovarian serous cystadenocarcinoma | OV | 卵巢浆液性囊腺癌 |
| Cervica squamous cell carcinoma and endocervical adenocarcinoma | CESC | 宫颈鳞癌和腺癌 | Pancreatic adenocarcinoma | PAAD | 胰腺癌 |
| Cholangiocarcinoma | CHOL | 胆管癌 | Pheochromocytoma and Paraganglioma | PCPG | 嗜铬细胞瘤和副神经节瘤 |
| Colon adenocarcinoma | COAD | 结肠癌 | Prostate adenocarcinoma | PRAD | 前列腺癌 |
| Lymphoid Neoplasm Diffuse Large B-cell Lymphoma | DLBC | 弥漫性大B细胞淋巴瘤 | Rectum adenocarcinoma | READ | 直肠腺癌 |
| Esophageal carcinoma | ESCA | 食管癌 | Sarcoma | SARC | 肉瘤 |
| Glioblastoma multiforme | GBM | 多形成性胶质细胞瘤 | Skin Cutaneous Melanoma | SKCM | 皮肤黑色素瘤 |
| Head and Neck squamous cell carcinoma | HNSC | 头颈鳞状细胞癌 | Stomach adenocarcinoma | STAD | 胃癌 |
| Kidney Chromophobe | KICH | 肾嫌色细胞癌 | Testicular Germ Cell Tumors | TGCT | 睾丸癌 |
| Kidney renal clear cell carcinoma | KIRC | 肾透明细胞癌 | Thyroid carcinoma | THCA | 甲状腺癌 |
| Kidney renal papillary cell carcinoma | KIRP | 肾乳头状细胞癌 | Thymoma | THYM | 胸腺癌 |
| Acute Myeloid Leukemia | LAML | 急性髓细胞样白血病 | Uterine Corpus Endometrial Carcinoma | UCEC | 子宫内膜癌 |
| Brain Lower Grade Glioma | LGG | 脑低级别胶质瘤 | Uterine Carcinosarcoma | UCS | 子宫肉瘤 |
| Liver hepatocellular carcinoma | LIHC | 肝细胞肝癌 | Uveal Melanoma | UVM | 葡萄膜黑色素瘤 |
| Lung adenocarcinoma | LUAD | 肺腺癌 |
3. 转录组数据下载
通过TCGA的官网进行下载。选择肿瘤,然后下载转录组数据。
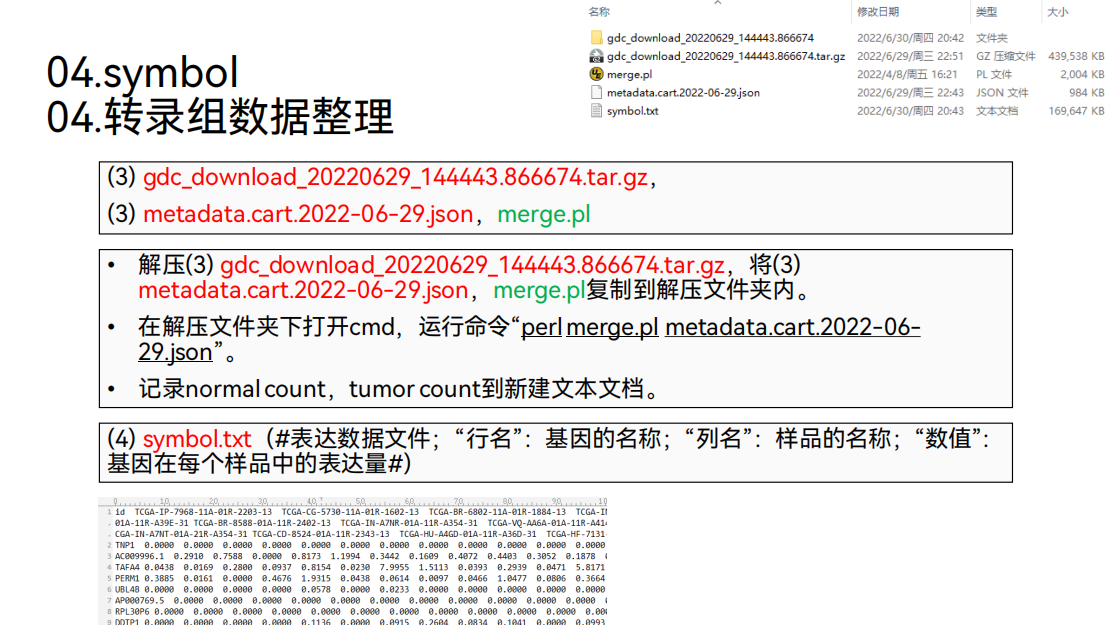
4. 转录组数据整理
TCGA下载的转录组数据,每个样品一个文件。
对这些文件进行整理,得到这样一个矩阵,在这个矩阵里面,行名是Ensemble ID,列名是样品的名称,里面的数值代表基因在每个样品中的表达量。
根据样品的名称,可以判断哪些样品是正常组的样品,哪些样品是肿瘤组的样品:对样品的名称按“-”切割。观察它的第四位,第四位是1或者2开头的话是正常组的样品。第四位是0开头的话是肿瘤组的样品。
在发表文章的时候用的比较多的是这种基因的名称。所以要将Ensemble ID转换成基因的名称。
转换好后,得到一个新的表格,在这个新的表格里面,行名是基因的名称,列名是样品的名称,里面的数值代表基因在每个样品中的表达量。
5. 临床数据下载
下载临床数据文件,也是通过官网进行下载,在数据类型里面选择“clinical”,就可以把临床数据下载下来。
6. 提取临床信息
下载好临床数据之后,提取里面的临床信息,可以得到这样一个表格,在这个表格里面,第一列是样品的名称,第二列是生存时间,单位是天,第三列是生存状态,1代表病人已经死亡了,0代表病人还存活。然后是年龄、性别、分级、分期,最后是TNM分期。
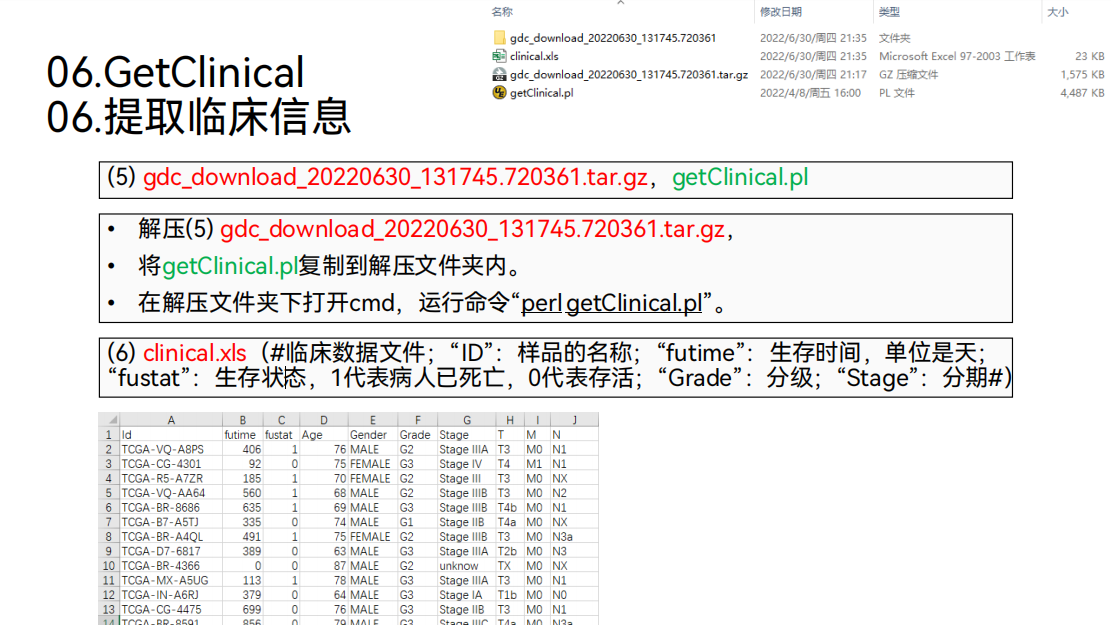
7. 泛癌的差异分析
通过泛癌的差异分析,可以观察目标基因“VCAN”在哪些肿瘤里面具有差异。
可以得到这样的图形:在这个图形中,横坐标是肿瘤的类型,纵坐标是目标基因“VCAN”的表达量。如果在某个肿瘤的上方标了星号,则说明在这个肿瘤中目标基因“VCAN”在正常样品和肿瘤样品之间是具有差异的。
以胃癌为例分析,我们就可以找到胃癌的简写STAD。可以看到,在胃癌上方是有星号的,说明这个基因在胃癌里面是具有差异的。同时也可以看到这个基因在胃癌的肿瘤样品里面是上调的。
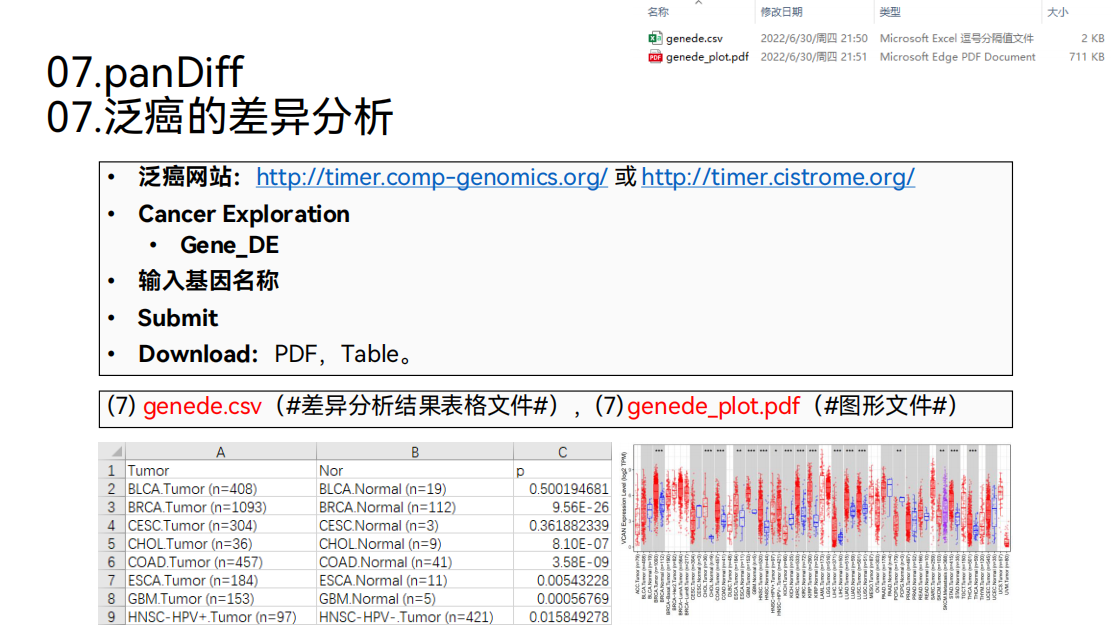
8. 单个肿瘤差异分析
接下来还可以做单个肿瘤的差异分析,得到这样的箱线图。
在这个图形里面,横坐标代表的是样品的类型,正常样品用蓝色表示,肿瘤样品用红色表示。纵坐标代表的是目标基因“VCAN”的表达量.
我们可以观察这个基因的表达量在正常样品和肿瘤样品之间是否有差异,可以得到差异的pvalue,如果pvalue小于0.001标三颗星,pvalue小于0.01标两颗星,pvalue小于0.05标一颗星。
可以看到这里标了三颗星,就说明目标基因“VCAN”在正常样品和肿瘤样品之间是具有差异的。同时,我们可以看到目标基因“VCAN”在肿瘤样品中是上调的。
9. 配对差异分析
接下来还可以做配对的差异分析,通过配对的差异分析,可以看到目标基因“VCAN”在正常样品和肿瘤样品之间也是具有差异的。
同时,我们可以看到目标基因“VCAN”在肿瘤样品中是上调的。

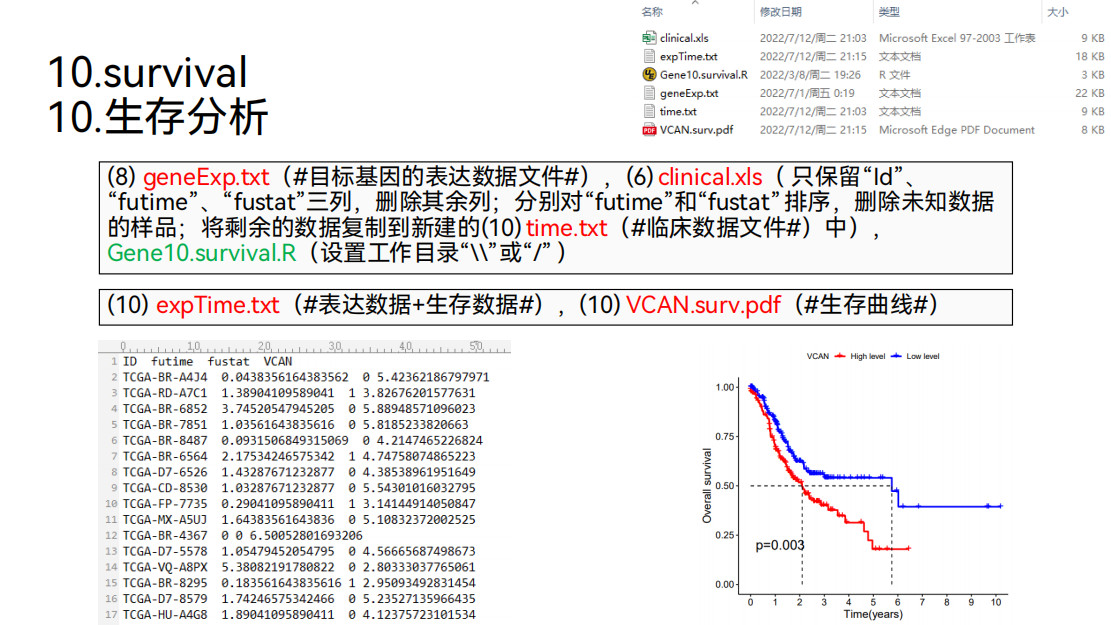
10. 生存分析
接下来可以对目标基因“VCAN”进行生存分析。
通过生存分析,我们就可以得到这样的生存曲线:
在这个生存曲线里面,横坐标是生存时间,单位是年,纵坐标是生存率。随着时间的推移,病人的生存率是下降的。
然后根据目标基因“VCAN”的表达量将样品分成高低表达两组。高表达组用红色表示,低表达组用蓝色表示。我们就可以比较高、低表达组之间病人的生存是否有差异,就可以得到差异的pvalue。
可以看到pvalue是小于0.05的,说明高低表达组之间的生存是具有差异的,同时我们可以看到低表达组的预后要优于高表达组。
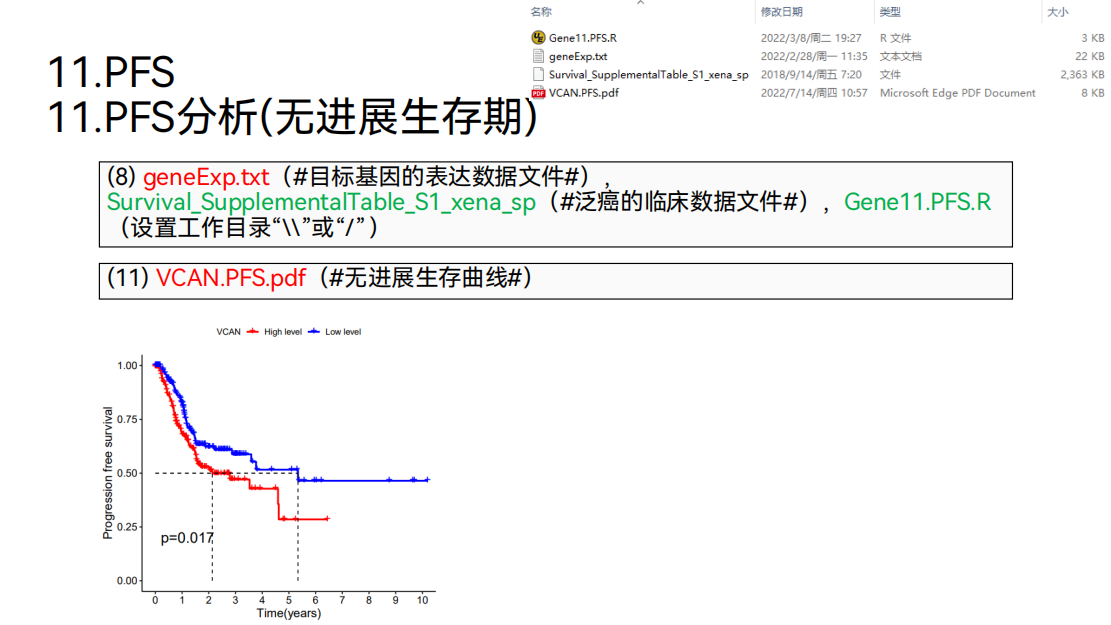
11. PFS分析
然后可以做PFS分析,通过PFS分析,我们就可以得到PFS的生成曲线。
我可以看到pvalue也是小于0.05的。说明高低表达组之间病人的无进展生存期也是具有差异的。
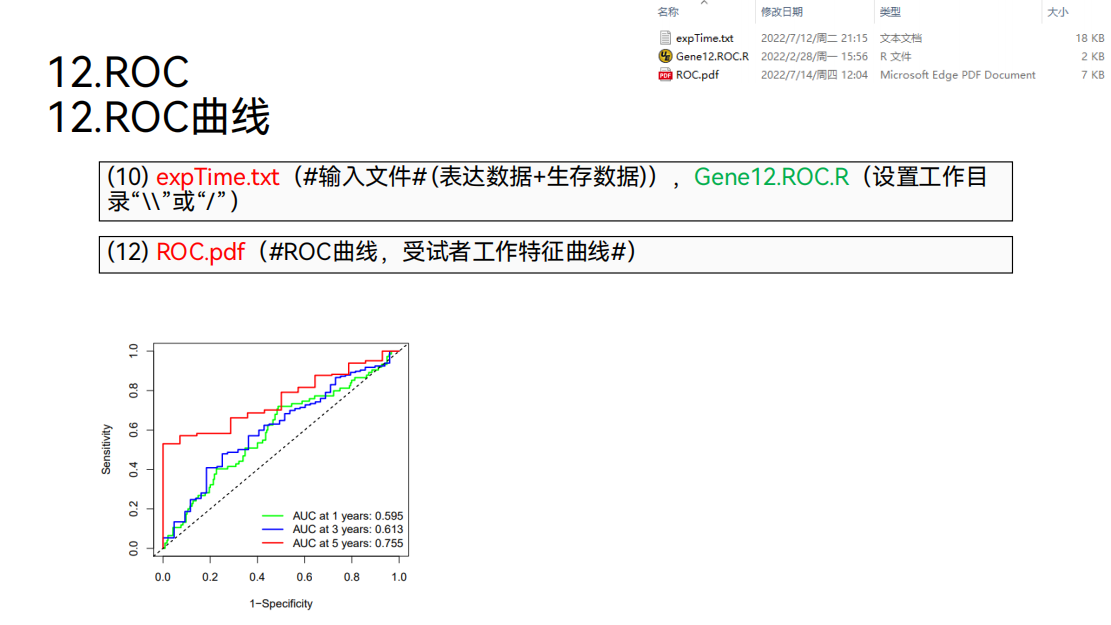
12. ROC曲线
然后我们可以绘制ROC曲线。ROC曲线主要是看曲线下的面积。曲线下的面积是介于0.5到1之间。曲线下的面积越大,就说明通过目标基因“VCAN”的表达量去预测病人生存的准确性越高。我们可以看到,五年ROC曲线下的面积大于0.7的,说明通过目标基因“VCAN”的表达量去预测病人五年生存期的准确性是比较高的。
13. 临床相关性分析
接下来可以做临床相关性分析。通过临床相关性分析,我们可以观察目标基因“VCAN”的表达量在不同的临床分组之间是否具有差异。
可以得到这样的图形,在这个图形里面,横坐标代表临床性状,这里以T分期为例,可以将病人分成T1、T2、T3、T4的病人。纵坐标代表目标基因“VCAN”的表达量。
观察目标基因“VCAN”的表达量在不同的临床性状之间是否具有差异,可以得到差异的pvalue。
可以看到T1和T2之间是具有差异的,T1和T3之间也是具有差异的,同时T1和T4之间也是具有差异的。但是T2、T3、T4之间是没有差异的。
说明T1以后的病人这个基因的表达量是上升了,但是T2期以后的病人这个基因的表达量没有明显的变化。

14. 临床相关性的热图
然后可以绘制临床相关性的热图。
首先可以根据目标基因“VCAN”的表达量对样品进行分组,将样品分成高低表达两组。低表达组用蓝色表示,高表达组用红色表示。
在这里加上病人的临床性状,就可以观察这里面的临床性状在高低表达组之间是否就有差异,可以得到差异的pvalue。
如果在某个临床性状的后面加上了星号,就说明这个临床性状在目标基因“VCAN”的高低表达组之间是具有差异的。
如,T分期在高低表达组之间是具有差异的。

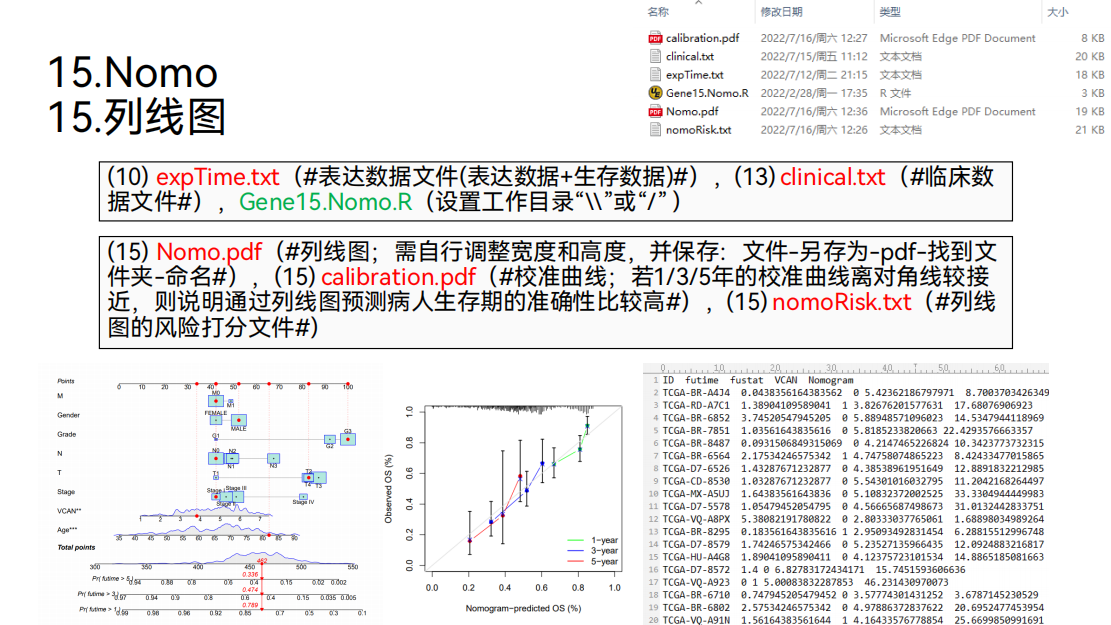
15. 列线图
然后可以绘制列线图。
在列线图的上方,我们首先可以看到单独打分的刻度,根据单独打分的刻度,我们就可以得到每个临床性状的打分。
比如,对于某个病人,如果他的M分期是M0,她就可以得42分。如果她是女性,她又可以得42分。再看目标基因“VCAN”的表达量,如果是26的话,他又可以得33分。
所以每个临床性状我们都可以得到一个打分,我们就可以将这里面所有临床性状的打分进行相加,就可以得到这个病人的综合打分。
得到了综合打分之后,我们就可以对照这里面综合打分的刻度,比如对于某个病人,他的综合打分是414分。然后我们就可以对照综合打分的刻度去预测病人的生存期。
可以看到这个病人他大于一年的生存率就是0.929。大于三年的生存率是0.792,大于五年的生存率是0.72。
这样的话,根据列线图,我们就可以预测病人的生存期。
16. 独立预后分析
然后可以做独立预后分析。
通过独立预后分析,可以观察目标基因“VCAN”是否可以独立于其他的临床性状,作为独立的预后因子。
独立分析包括了单因素独立分析和多因素独立分析。
先看一下单因素。单因素就是将这里面的因素一个一个输入,跟生存时间和生存状态进行比较。如果在单因素里面pvalue小于0.05,就说明这个因素与病人的预后是相关的。
再看一下多因素,多因素是将这里面的因素一次性输入,跟生存时间和生存状态进行比较。它会考虑因素之间的相互作用,如果在多因素里面pvalue还是小于0.05的话,就说明这个因素是可以独立于其他的因素,作为独立的预后因子。
可以看到目标基因“VCAN”,它在单因素和多因素里面pvalue都是小于0.05的,就说明目标基因“VCAN”是可以独立于其他的临床性状。作为独立的预后因子。

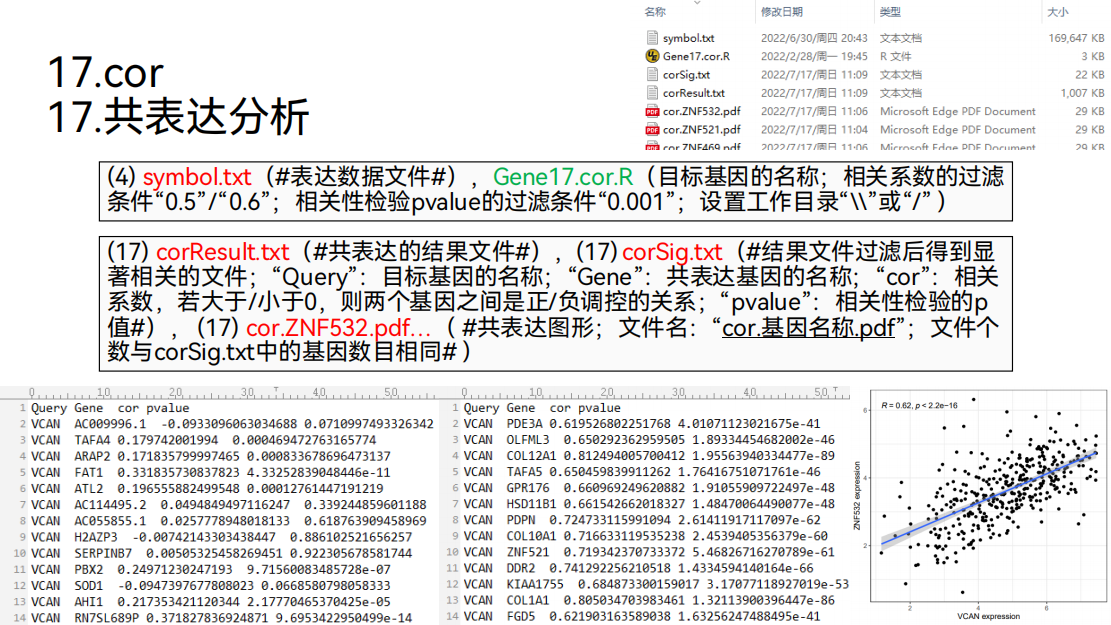
17. 共表达分析
接下来还可以做共表达分析。
通过共表达分析,我们可以得到这样一个表格。在这个表格里面,第一列是目标基因“VCAN”的名称。第二列是与目标基因“VCAN”具有共表达关系的基因。
第三列是相关系数。如果相关系数大于零,说明这两个基因之间是正调控的关系。如果相关系数小于零,说明这两个基因之间是负调控的关系。
最后一列是相关性检验的pvalue,我们可以根据相关系数和相关性检验的pvalue对基因。进行过滤得到显著相关的基因。
18. 共表达圈图
接下来可以绘制共表达圈图,在这个图形里面,最外圈代表的是基因的名称。
我们首先可以找到目标基因“VCAN”,然后再看一下连线的颜色,绿色代表负相关,红色代表正相关。
通过这个图形,可以很直观的看出哪些基因与目标基因“VCAN”之间是正调控的关系,哪些基因的话与目标基因“VCAN”之间是负调控的关系。

19. 目标基因分组的差异分析
然后可以做差异分析。
我们可以根据目标基因“VCAN”对样品进行分组,将样品分成高低表达两组,然后可以观察哪些基因在高低表达组之间是具有差异的,就可以得到差异的表格。
在这个表格里面,第一列是基因的名称,第二列是基因在低表达组的均值,第三列是基因在高表达组的均值,然后是log FC,接下来是差异的pvalue,对pvalue进行校正,我们就可以得到FDR值。
一般是按照log FC的绝对值大于1,FDR小于0.05进行过滤,找到显著的差异基因。
得到了差异基因之后,可以对差异基因进行可视化,得到差异基因的热图。
在这个图形里面,横坐标代表样品。对样品进行分组,左边蓝色样品是低表达组的样品,右边红色样品是高表达组的样品。纵坐标是差异基因的名称。里面的颜色,红色代表高表达,蓝色代表低表达。
通过这个图形可以观察到,右上部分红色区域这些基因在目标基因的高表达组中是上调的,左下部分这些基因正好相反,它在目标基因的低表达组中是上调的。

20. GO富集分析
接下来可以对差异基因进行GO的富集分析,观察差异基因在哪些功能上具有富集,可以得到GO的圈图。
在这个图形里面,最外圈代表的是GO的ID,因为GO它可以分为BP、CC和MF三大类。所以在绘制图形的时候,可以用不同的颜色表示。
第二个圆圈代表的是每个GO上基因的数目。第二个圆圈的颜色代表的是富集显著性的pvalue,颜色越红就说明差异基因在这个GO上富集越显著。
第三个圆圈是富集在每个GO上差异基因的数目。
最里面的柱状图代表的是基因的比例。


21. KEGG富集分析
接下来还可以做通路的富集分析,通过通路的富集分析,我们就可以得到柱状图和气泡图。
在柱状图里面,纵坐标代表通路的名称,横坐标代表附集在每个通路上基因的数目。柱子的颜色代表富集的显著性,颜色越红说明差异基因在这个通路上富集越显著,
在气泡图里面,纵坐标是通路的名称。横坐标代表的是基因的比例。圆圈的大小代表富集在每个通路上基因的数目,圆圈的颜色代表富集的显著性,圆圈越红说明差异基因在这个通路上富集越显著。


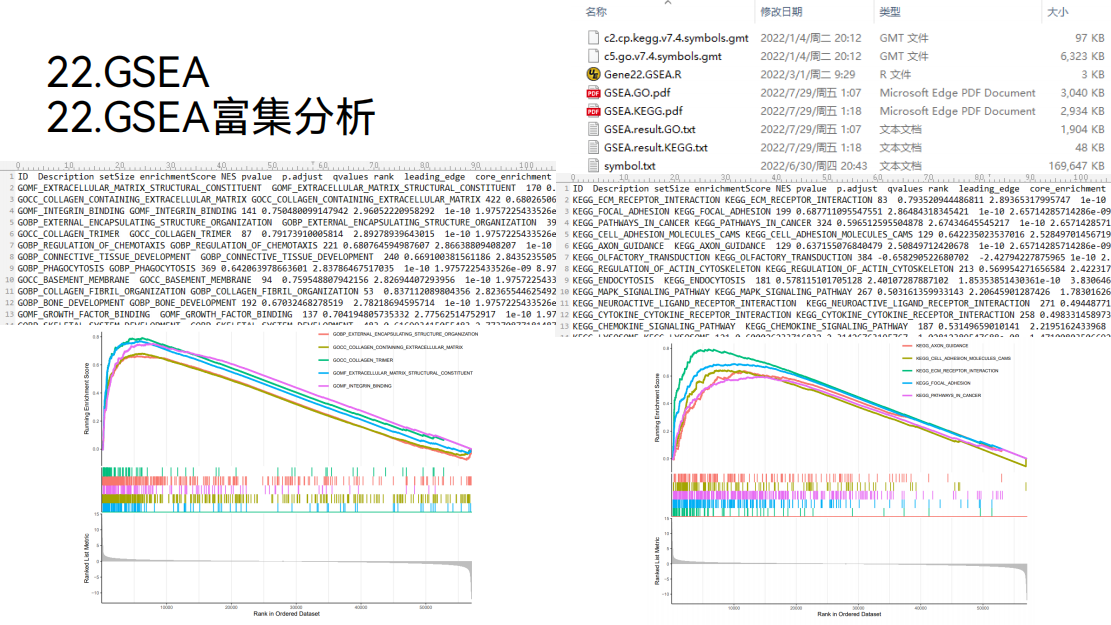
22. GSEA富集分析
接下来还可以做GSEA富集分析。
通过GSEA富集分析,可以观察哪些功能或通路在目标基因“VCAN”的高表达组中是活跃的,哪些功能或通路在目标基因“VCAN”的低表达组中是活跃的。
可以得到GSEA富集分析的图形,在这个图形里面,主要是看曲线的峰值,如果这个峰值出现在上方,就说明这些功能或通路在目标基因“VCAN”的高表达组中是活跃的,如果这个峰值出现在下方,就说明这些功能或通路在目标基因“VCAN”的低表达组中是活跃的。

23. 肿瘤微环境
然后可以做肿瘤微环境的分析,通过肿瘤微环境的分析,我们就可以得到肿瘤微环境的打分,即可以得到这样一个表格,在这个表格里面,第一列是样品的名称,第二列是基质细胞的打分,第三列是免疫细胞的打分。最后一列是将这两个打分进行相加得到的综合打分。
打分的含义:如果基质细胞的打分越高,就说明在这个样品中,基质细胞的含量越高。如果免疫细胞的打分越高,就说明在这个样品中,免疫细胞的含量越高。如果综合的打分越高,就说明在这个样品中,基质细胞和免疫细胞的综合含量越高。

24. 肿瘤微环境差异分析
得到了打分的表格之后,接下来就可以做肿瘤微环境的差异分析,观察这三个打分在目标基因“VCAN”的高低表达组之间是否具有差异,可以得到差异的pvalue。
可以看到这三个打分的pvalue都是小于0.05的,说明这三个打分在高低表达组之间都是具有差异的。
同时,可以看到这三个打分在目标基因“VCAN”的高表达组中都是上调的,就说明基质细胞和免疫细胞的含量在目标基因“VCAN”的高表达组中的含量都是更高的。

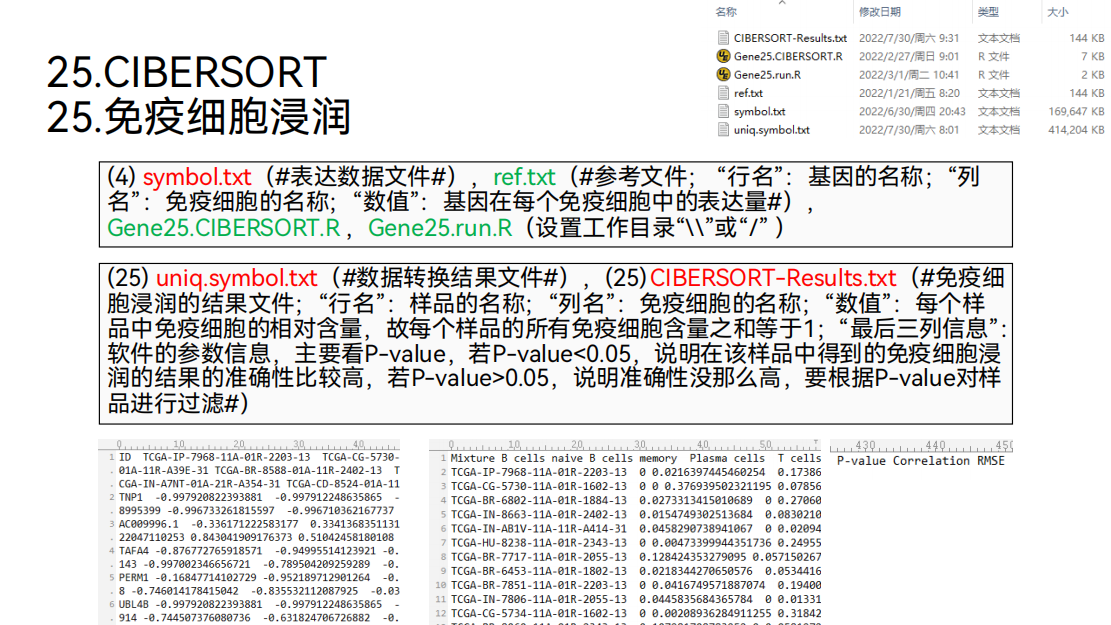
25. 免疫细胞
然后可以做免疫细胞浸润的分析。
通过免疫细胞浸润的分析,可以得到这样一个表格。在这个表格里面,行名是样品的名称,列名是免疫细胞的名称,里面的数值代表每个样品中免疫细胞的含量。
因为这里面的含量是相对含量。所以对于每个样品来说,所有的免疫细胞之和是等于1的.
26. 免疫细胞差异
得到了免疫细胞浸润的结果之后,接下来就可以做免疫细胞的差异分析。
可以得到这样的柱状图,在这个图形里面,横坐标代表免疫细胞的名称,纵坐标代表免疫细胞的含量。根据目标基因“VCAN”的表达量,可以将样品分成高低表达两组,低表达组用蓝色表示,高表达组用红色表示。如果在某个免疫细胞的上方有星号,就说明这个免疫细胞在目标基因“VCAN”的高低表达组之间是具有差异的。同时可以看到这个免疫细胞在目标基因“VCAN”的高或低表达组中是上调的。

27. 免疫细胞相关性
然后也可以做免疫细胞的相关性分析,就可以得到相关性的气泡图。
在这个图形里面,纵坐标代表免疫细胞的名称。横坐标代表相关系数,同时也可以得到相关性检验的pvalue,如果pvalue小于0.05,就说明这些免疫细胞与目标基因“VCAN”之间的相关性是显著的。
再看相关系数,如果相关系数小于0,就说明这些免疫细胞与目标基因“VCAN”之间是负调控的关系。如果相关系数大于0,就说明这些免疫细胞与目标基因“VCAN”之间是正调控的关系。

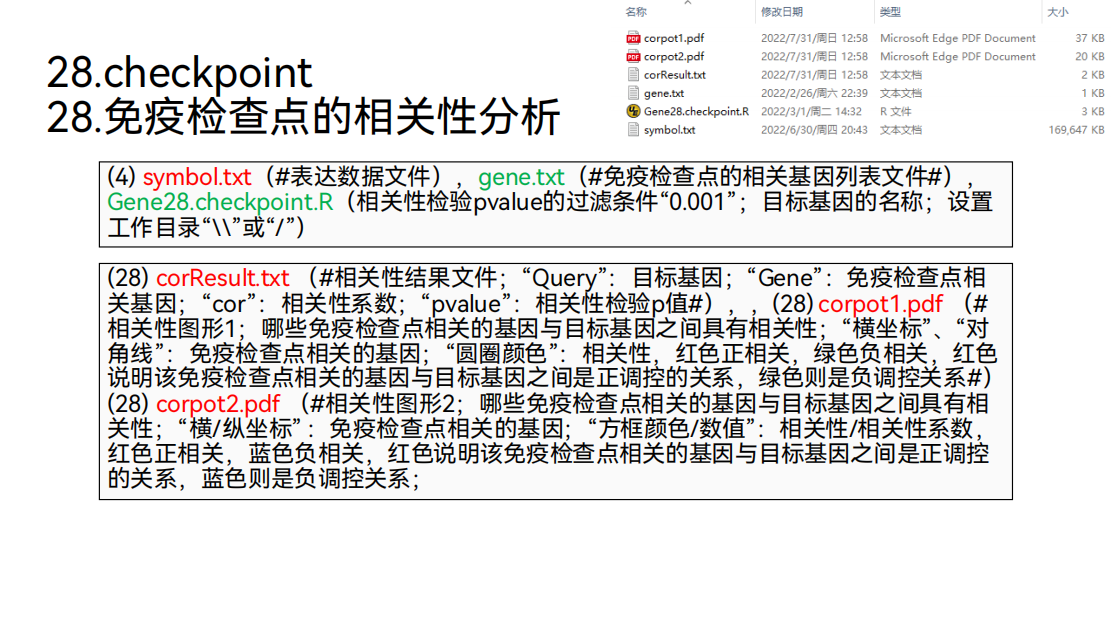
28. 免疫检查点相关性
接下来还可以做免疫检查点的相关性分析。可以得到这样的相关性图形,在这个图形里面,横坐标和对角线代表的都是免疫检查点相关的基因。里面的颜色,红色代表正相关,绿色代表负相关。
通过这个图形,可以观察到,这里面免疫检查点相关的基因与目标基因“VCAN”之间都是正调控的关系。

29. 肿瘤突变负荷
接下来还可以做肿瘤突变负荷的分析,可以得到相关性的图形。在这个图形里面,横坐标代表目标基因“VCAN”的表达量,纵坐标代表病人的肿瘤突变负荷。然后可以得到相关系数和相关性检验的pvalue。
可以看到,相关系数是小于0的,相关性检验的pvalue是小于0.05的,说明目标基因“VCAN”的表达量与肿瘤突变负荷之间是负相关的关系。

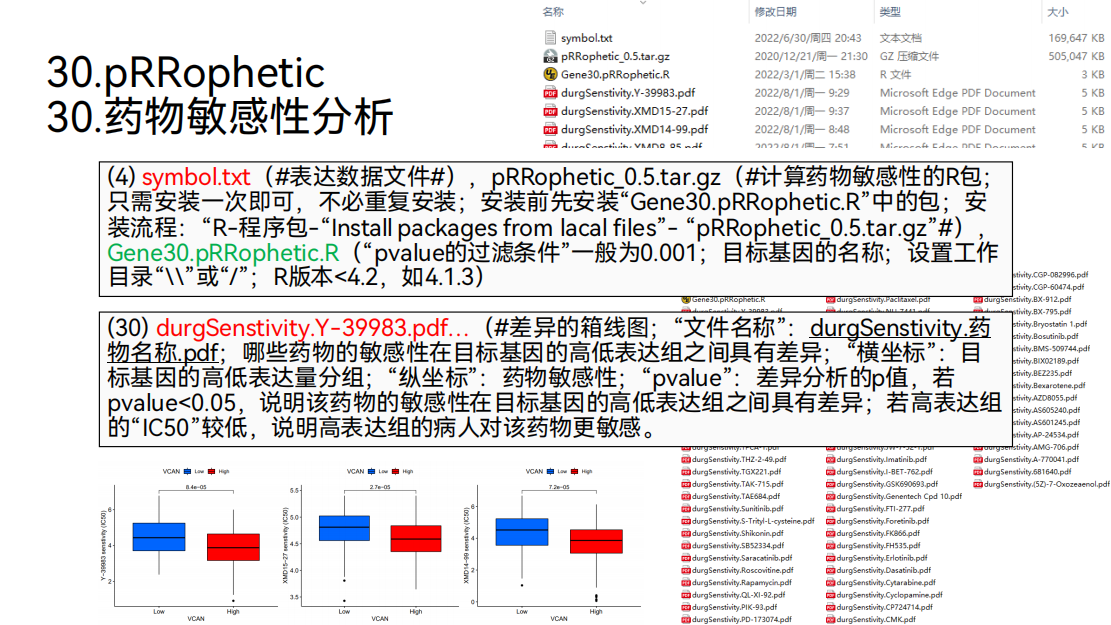
30. 药物敏感性分析
接下来可以做药物敏感性的分析。
对药物进行循环观察,哪些药物的敏感性在高低表达组之间是具有差异的。就可以得到这样的箱线图,在这个图形里面,根据目标基因“VCAN”对样品进行分组,将样品分成高低表达两组。低表达组用蓝色表示,高表达组用红色表示。纵坐标代表药物的敏感性。
然后观察这个药物的敏感性在高低表达组之间是否就有差异,就可以得到差异的pvalue。可以看到pvalue是小于0.05的,就说明这个药物的敏感性在高低表达组之间是具有差异的。
同时,可以看到,对于高表达组的病人,他的IC 50值是更低的,就说明高表达组的病人对这个药物是更敏感的。
31. 免疫治疗分析
然后也可以做免疫治疗的分析。通过免疫治疗的分析,可以观察高低表达组之间哪个分组在接受免疫治疗的时候,效果是更好的。
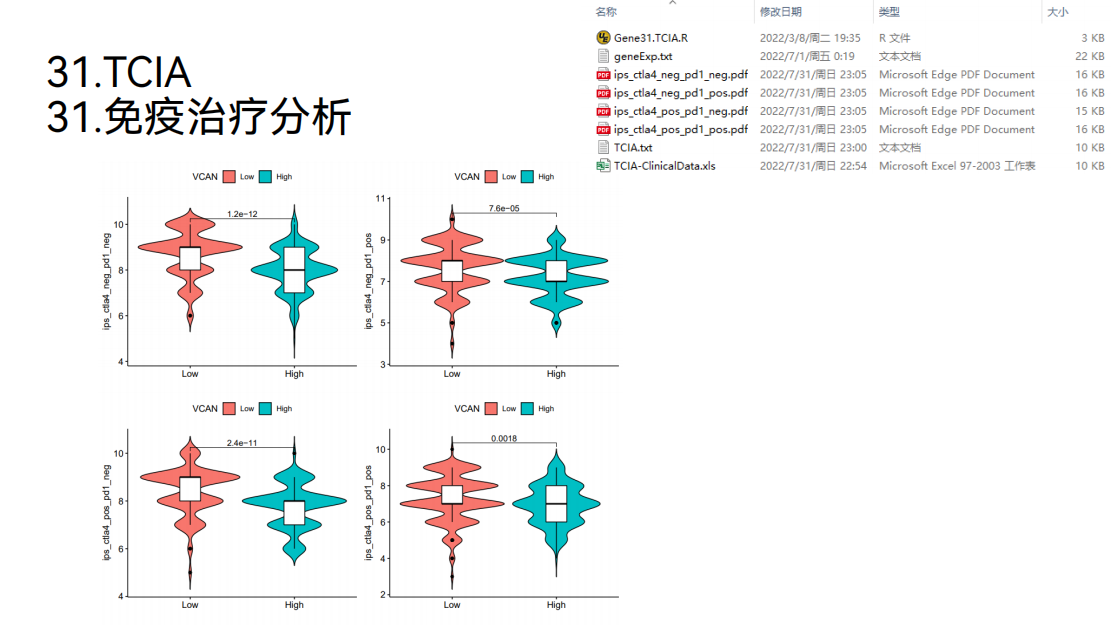
得到这样的小提琴图,在这个图形里面,横坐标代表目标基因“VCAN”的分组,纵坐标代表免疫的评分。这个免疫评分越高,就说明病人接受免疫治疗的效果越好。可以看到这个评分在高低表达组之间是具有差异的。同时,可以看到,低表达组的免疫评分是更高的,就说明低表达组在接受免疫治疗的时候,效果是更好的。
再看这里面评分的含义。可以看到右上角的图形是PD1的阳性,就说明低表达组在接受抗PD1治疗的时候,效果是比较好的。
再看左下角的图,是CTLA4的阳性,就说明低表达组在接受抗CTLA4治疗的时候,效果是比较好的。
再看右下角的图,在这个图形里面pvalue也是小于0.05的,并且低表达组的评分是更高的。PD1是阳性,CTLA4也是阳性,就说明低表达组在接受这两个联合用药的时候,效果是比较好的。
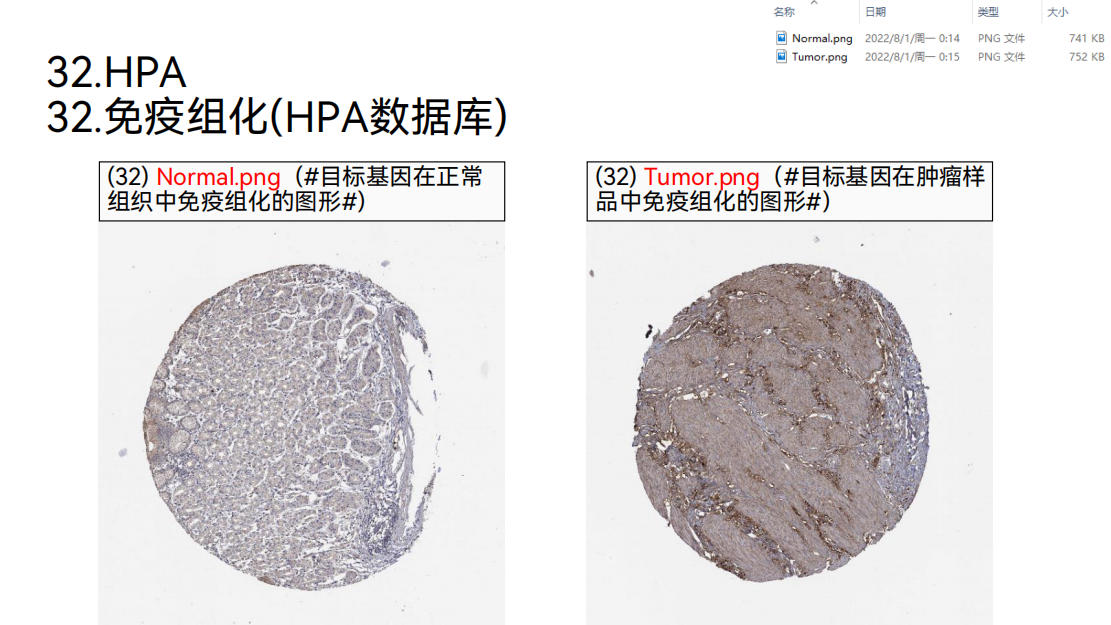
32. 免疫组化
免疫组化的分析。可以从这个HPA数据库下载免疫组化的图片。可以下载两个图片,一个是正常组的图片,另外一个是肿瘤组的图片,