《Convolutional Neural Networks》课堂笔记
Lesson 4 Convolutional Neural Networks
这篇文章其实是 Coursera 上吴恩达老师的深度学习专业课程的第四门课程的课程笔记。
参考了其他人的笔记继续归纳的。
边缘检测示例 (Edge detection example)
卷积运算时卷积神经网络最基本的组成部分,我们使用边缘检测作为入门样例。

我们输入一个 \(6\times6\) 的灰度图像,因为没有 RGB 三通道,所以它是一个 \(6\times6\times1\) 的矩阵。为了检测图像中的垂直边缘,我们构造一个这样的 \(3\times3\) 的矩阵 \(\begin{bmatrix}1 & 0 & -1\\ 1 & 0 & -1\\ 1 & 0 & -1\end{bmatrix}\)。在卷积神经网络的术语中,它被称为过滤器;在论文中有时候也被称为核。
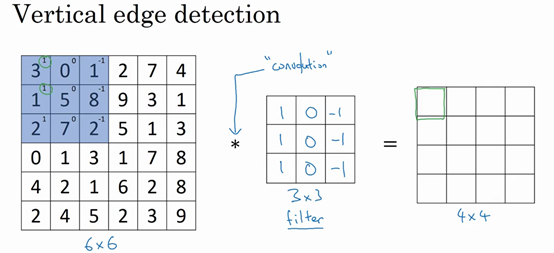
这个卷积运算的输出将会是一个 \(4\times4\) 的矩阵。为了计算第一个元素,在 \(4\times4\) 左上角的那个元素,我们使用 \(3\times3\) 的过滤器,将其覆盖在输入图像,然后进行元素乘法运算。即
然后将这个矩阵每个元素相加得到最左上角的元素,即
计算第二个元素类似,把蓝色的方块,向右移动一步。
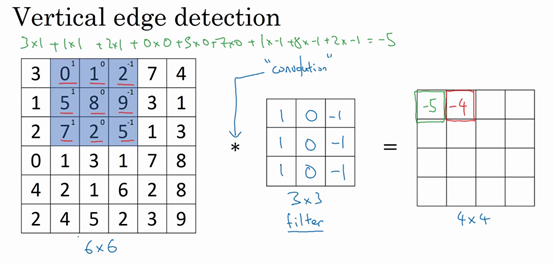
最终我们就可以计算得到 \(4\times4\) 的矩阵。

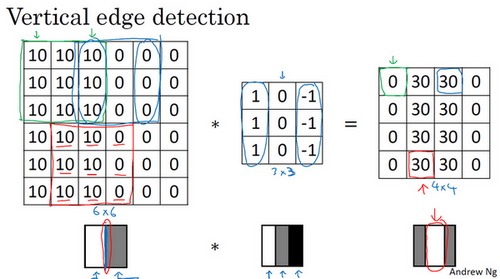
为什么它是一个边缘过滤器呢?以一个简单的例子来看。输入一个简单的 \(6\times6\) 的图片,左边的像素值较亮,右边的像素值较暗,它有一个特别明显的垂直边缘在图像中间。所以我们用垂直边缘过滤器对其进行卷积运算后,我们可以检测到得到的矩阵中间有段亮一点的区域,其对应原图片中的垂直边缘。因为这个例子中,图片太小了,所以检测到的边缘太粗了,如果是 \(1000\times1000\) 的图像,它能很好地检测出图像中的垂直边缘。
而且,我们使用的图片是由亮变暗,如果使用由暗变亮的图片,就会得到下面的矩阵。
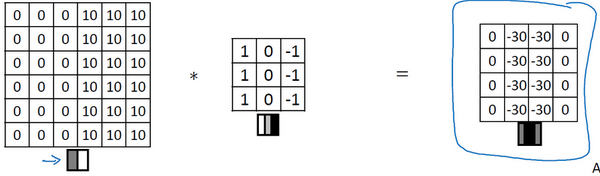
所以特地的过滤器可以为我们区分明暗变化的区别。
同理,我们也可以有其他的边缘检测的过滤器。
如 Sobel 过滤器,\(\begin{bmatrix}1 & 0 & - 1 \\ 2 & 0 & - 2 \\ 1 & 0 & - 1 \\\end{bmatrix}\)。它的优点在于增加了中间一行元素的权重,这使得结果的鲁棒性会更高一些。
再如 Scharr 过滤器,\(\begin{bmatrix} 3& 0 & - 3 \\ 10 & 0 & - 10 \\ 3 & 0 & - 3 \\\end{bmatrix}\)。它也是经常使用的数字组合,用来检测垂直边缘。
Padding
Padding 是一个基本的卷积操作。
之前我们的例子,使用一个 \(3\times3\) 的过滤器卷积一个 \(6\times6\) 的图像,最后会得到一个 \(4\times4\) 的输出。这背后的数学解释是,如果有一个 \(n\times n\) 的图像,用 \(f\times f\) 的过滤器做卷积,那么输出的维度就是 \((n-f+1)\times(n-f+1)\)。
这样的话,有两个缺点:
- 每次做卷积操作,图像会缩小;
- 角落边缘的像素(如下图中绿色阴影)可能只被一个输出所使用,而在中间的像素点(如下图中红色阴影),就会有许多 \(3\times3\) 的区域与之重叠。所以那些在角落或者边缘的像素点在输出中采用较少,意味着我们丢掉了图像边缘位置的许多信息。

为了解决这些问题,我们可以在卷积操作之前填充这幅图像。我们可以沿着图像边缘再填充一层像素,那么 \(6\times6\) 的图形填充成了 \(8\times8\) 的图像。这样,再用 \(3\times3\) 的过滤器进行卷积,得到的还是一个 \(6\times6\) 的图像。
习惯上,我们是用 0 进行填充。如果 \(p\) 是填充的数量,在这个例子里,\(p=1\)。因为我们在周围都填充了一个像素点,输出也就变成了 \((n+2p-f+1)\times(n+2p-f+1)\)。
至于选择填充多少像素,通常由两个选择,分别叫做 Valid 卷积和 Same 卷积。
Valid 卷积意味着不填充。就像最初说的那样,如果有一个 \(n\times n\) 的图像,用 \(f\times f\) 的过滤器做卷积,那么输出的维度就是 \((n-f+1)\times(n-f+1)\)。
Same 卷积意味着填充后,输出大小和输入大小是一样的。也就是 \(n+2p-f+1=n\),即 \(p=\frac{f-1}{2}\)。
习惯上,\(f\) 通常是奇数,原因是:
- 如果 \(f\) 是一个偶数,那么我们只能使用一些不对称填充。只有在 \(f\) 是奇数的情况下,same 卷积才会有自然的填充;
- 如果是奇数维过滤器,它就有一个中心点,便于指出过滤器的位置。
卷积步长 (Strided convolutions)
卷积步长是构建卷积神经网络的另一个基本操作。
假如我们想用 \(3\times3\) 的过滤器卷积一个 \(7\times7\) 的图像,和之前不同的是,我们把步长设为 2。还是一样的计算过程,只是之前我们移动蓝框的步长是 1,现在移动的步长是 2,我们每次让过滤器跳过 2 个像素。
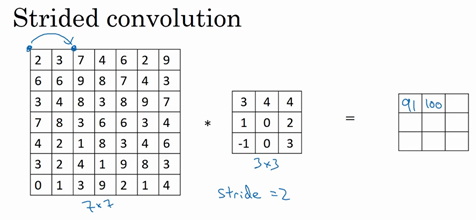
数学原理是,如果用一个 \(f\times f\) 的过滤器卷积一个 \(n\times n\) 的图像,padding 为 \(p\),步长为 \(s\),输出的维度就为 \((\frac{n+2p-f}{s}+1)\times(\frac{n+2p-f}{s}+1)\)。如果商不是一个整数的情况下,我们向下取整。这个原则实现的方式是,只在蓝框完全包括在图像或填充完的图像内部时,才进行运算。如果有任意一个蓝框移动到了外面,就不进行运算。因此公式就变成了
三维卷积
假如我们不仅想检测灰度图像的特征,也想检测 RGB 彩色图像的特征。彩色图像为 \(6\times6\times3\),那么现在需要的是一个对应的三维的过滤器,维度为 \(3\times3\times3\)。

给这些参数起个名字(原图像),这里的第一个 6 代表图像高度,第二个 6 代表宽度,这个 3 代表通道的数目。同样你的过滤器也有一个高,宽和通道数,并且图像的通道数必须和过滤器的通道数匹配,所以这两个数(紫色方框标记的两个数)必须相等。
这样,输出会是一个 \(4\times4\times1\) 的图像。
类似的,我们把过滤器这个立方体一步步移动进行元素乘法运算。

如果同时使用多个过滤器,同时检测多个特征。那么同样的计算步骤,得到一个不同的 \(4\times4\times1\) 的输出。将它与之前的输出堆叠,这样就得到一个 \(4\times4\times2\) 的输出了。

把我们的例子泛化来说就是。如果有一个 \(n\times n \times n_c\) 的输入图像,其中 \(n_c\) 是通道数目,然后使用了 \(n_{c'}\) 个维度为 \(f\times f \times n_c\) 的过滤器,最终得到 \((n-f+1)\times(n-f+1)\times n_{c'}\) 的输出。当然,这里的设定是步长为 1 且没有 padding。
单层卷积神经网络
\(a^{[0]}\) 到 \(a^{[1]}\) 的计算过程是,首先执行线性函数,然后所有元素相乘做卷积。具体来说,运行线性函数再加上偏差,然后应用激活函数 ReLU,公式如下。其中过滤器我们用 \(W^{[1]}\) 表示。
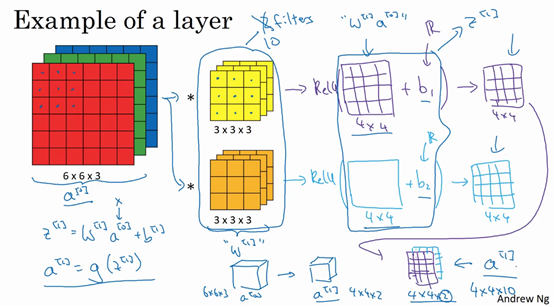
假设我们有 10 个 \(3\times3\times3\) 的过滤器,那么这些过滤器一共有 270 个参数。而每个过滤器还要再加上一个偏差 \(b\),所以一共就有 280 个参数。
简单的卷积神经网络示例
举个例子说明一下。
我们输入比较小的图片,大小是 \(39\times39\times3\)。
然后第一层,我们用 \(3\times3\) 的过滤器来提取特征,使用的是 valid 卷积,也就是 \(f^{[1]}=3,s^{[1]}=1,p^{[1]}=0\)。如果有 10 个过滤器,那么下一层的激活值为 \(37\times37\times10\)。
第二层还是一个卷积层,使用 \(5\times5\) 的过滤器,过滤器的参数是 \(f^{[2]}=5,s^{[2]}=2.p^{[2]}=0\)。而且有 20 个过滤器,那么输出结果是 \(17\times17\times20\)。
第三层为最后一个卷积层,过滤器的参数为 \(f^{[3]}=5,s^{[3]}=2,p^{[3]}=0\)。使用了 40 个过滤器,那么输出结果为 \(7\times7\times40\)。
通过前面三层,我们得到了 \(7\times7\times40=1960\) 个特征,将其平滑或展开成 1960 个单元,然后将其输入 logistic 回归单元或者 softmax 回归单元。

池化层
一个典型的卷积神经网络通常由三层。卷积层 Conv,池化层 POOL,和全连接层 FC。

池化层是用来缩减模型的大小,提高计算速度,且提高所提取特征的鲁棒性的。
举一个简单的例子。假如输入时一个 \(4\times4\) 的矩阵,用到的池化类型是最大池化 (max pooling)。执行最大池化的树池是一个 \(2\times2\) 矩阵,执行过程就是把 \(4\times4\) 的矩阵拆分成不同的区域,输出区域中的最大元素值。
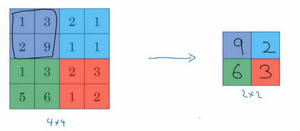
因为我们使用的过滤器是 \(2\times2\),步长是 2,即\(f=2,s=2\)。所以最后得到的矩阵是 \(2\times2\) 的。
而对一个 \(5\times5\) 的矩阵使用 \(f=3,s=1\) 的池化过滤器进行最大池化的话,过程如下。

还有一种不太常用的池化类型——平均池化 (average pooling)。也就是取每个区域中的平均值。
下面这个平均池化的超参数 \(f=2,s=2\)。
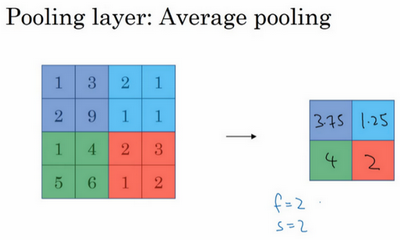
总结一下,池化的超级参数包括过滤器大小 \(f\) 和步长 \(s\)。常用的参数值为 \(f=2,s=2\),其效果相当于高度和宽度缩减一半。最大池化时,往往很少用到 padding。大部分情况下,\(p=0\)。即最大池化的输入为 \(n_H\times n_W \times n_c\),输出则为 \([\frac{n_H-f}{s}+1]\times[\frac{n_W-f}{s}+1]\times n_c\),输入通道与输出通道个数相同,因为对每个通道都做了池化。
需要注意的是,池化过程中没有需要学习的参数。执行反向传播时,反向传播没有参数适用于最大池化。
卷积神经网络示例
假设我们有一张 \(32\times32\times3\) 的 RGB 图片,它含有某个数字,我们想识别它是 0-9 这 10 个数字中的哪一个,于是构建一个神经网络来实现这个功能。
我们要使用的这个网络模型和经典网络 LeNet-5 非常相似,许多参数选择都与 LeNet-5 相似。
第一层使用过滤器大小为 \(5\times5\),步长为 1,padding 为 0,过滤器个数为 6,那么输出为 \(28\times28\times6\)。将这层标记为 CONV1。
然后构建一个池化层,使用的是最大池化。参数为 \(f=2,s=2,p=0\)。输出为 \(14\times14\times6\),标记为 POOL1。
在计算神经网络有多少层时,通常只统计具有权重和参数的层。因为池化层没有权重和参数,只有一些超参数。所以我们把 CONV1 和 POOL1 共同作为一个卷积,标记为 Layer1。
接着,我们再构建一个卷积层,过滤器大小为 \(5\times5\),步长为 1,过滤器个数为 16,则输出为 $10\times10\times1$6,标记为 CONV2。
然后做最大池化,仍然参数为 \(f=2,s=2,p=0\)。得到输出为 \(5\times5\times16\),标记为 POOL2。
这样我们得到了 \(5\times5\times16=400\) 个特征,将他们平整化为一个大小为 400 的一维向量,利用这个向量构建下一层。
下一层有 120 个单元,也就是我们的第一个全连接层,标记为 FC3。这 400 个单元与 120 个单元紧密相连,这句是全连接层。它的权重矩阵为 \(W^{[3]}\),维度为 \(120\times400\)。
然后我们再添加一个 84 个单元的全连接层,标记为 FC4。
最后用这 84 个单元填充一个 softmax 单元。因为我们是要识别 10 个数字,所以 softmax 会有 10 个输出。
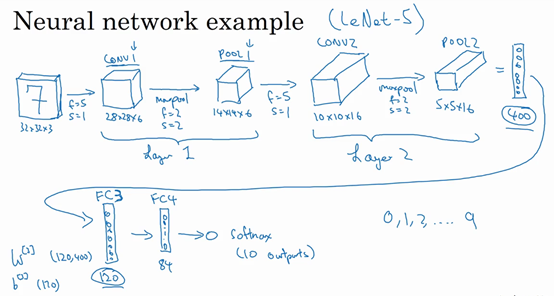
随着神经网络深度的加深,高度和宽度通常都会减小,而通道数量会增加,然后得到一个全连接层。
在神经网络中,常见模式就是一个或多个卷积后面跟随一个池化层,然后重复,接着是几个全连接层,最后是一个 softmax。
以下是刚刚列出的神经网络的激活值形状和大小。
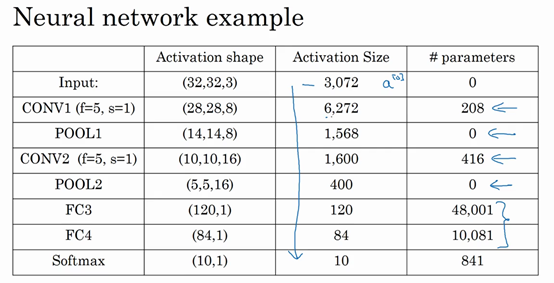
其实许多参数都存在于神经网络的全连接层。观察可发现,随着神经网络的加深,激活值尺寸会逐渐变小,如果激活值尺寸下降太快,也会影响神经网络性能。
经典网络
LeNet-5
LeNet-5 是针对灰度图片训练的,所以输入的图片大小只有 \(32\times32\times1\)。LeNet-5 的论文是在 1998 年撰写的,当时人们并不使用 padding。而且,人们更喜欢使用平均池化,现在一般用最大池化更多一些。

AlexNet
AlexNet 是以论文的第一作者 Alex Krizhevsky 的名字命名的,另外两位合著者是 Ilya Sutskever 和 Geoffery Hinton。
AlexNet 使用 \(227\times227\times3\) 的图片作为输入,实际上原文中使用的图像是 \(224\times224\times3\),但是尝试推导一下,我们会发现 \(227\times227\times3\) 这个尺寸更好一些。
实际上,它和 LeNet 有很多相似之处,不过 AlexNet 要大得多。前面讲到的 LeNet 或 LeNet-5 大约有 6 万个参数,而 AlexNet 大约有 6000 万个参数。当用于训练图像和数据集时,AlexNet 能够处理非常相似的基本构造模块,这些模块往往包含着大量的隐藏单元或数据。AlexNet 比 LeNet 表现更为出色的另一个原因是它使用了 ReLu 激活函数。

在写这篇论文的时候,GPU 的处理速度还比较慢,所以 AlexNet 采用了非常复杂的方法在两个 GPU 上进行训练。大致原理是,这些层分别拆分到两个不同的 GPU 上,同时还专门有一个方法用于两个 GPU 进行交流。
VGG-16
VGG-16 网络没有那么多超参数,这是一种只需要专注于构建卷积层的简单网络。VGG-16 中使用的是 same 卷积中的参数。
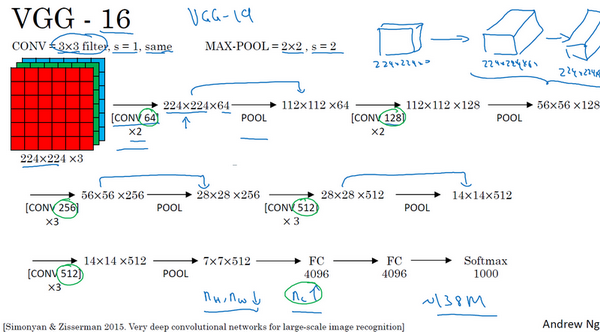
VGG-16 这个数字 16,其实指的是这个网络中包含 16 个卷积层和全连接层。确实是个很大的网络,总共包含约 1.38 亿个参数。但它的结构并不复杂,这种相对一致的网络结构对研究者很有吸引力,而它的主要缺点是需要训练的特征数量非常巨大。
残差网络 (Residual Networks, ResNets)
非常非常深的神经网络是很难训练的,因为存在梯度消失和梯度爆炸问题。而跳跃连接 (skip connection) 可以从某一层网络层获取激活,然后迅速反馈给另外一层,甚至是神经网络的更深层。我们可以利用跳跃连接构建能够训练深度网络的 ResNets,有时深度能够超过 100 层。
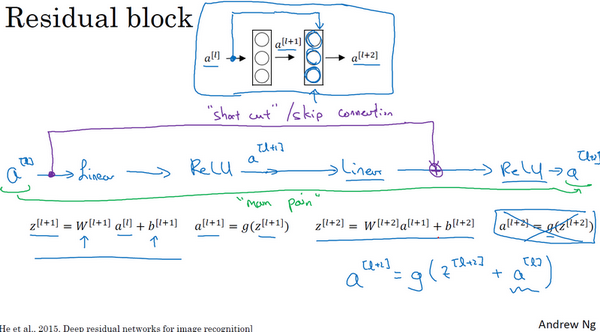
ResNets 是由残差块 (residual block) 构建的。
以一个两层神经网络为例。从 \(a^{[l]}\) 到 \(a^{[l+2]}\) 需要进行以下的计算。
即这是这组网络层的主路径。
在残差网络中,我们将 \(a^{[l]}\) 直接向后,拷贝到神经网络的深层,在 ReLU 非线性激活函数前加上 \(a^{[l]}\),这是一条捷径。\(a^{[l]}\) 的信息直接到达神经网络的深层,不再沿着主路径传递,这就意味着最后这个等式 \(a^{[l+2]}=g(z^{[l+2]})\) 去掉了。取而代之的是另一个 ReLU 非线性函数,即 \(a^{[l+2]}=g(z^{[l+2]}+a^{[l]})\),也就是加上的 \(a^{[l]}\) 产生了一个残差块。
ResNet 的发明者是何恺明 (Kaiming He)、张翔宇 (Xiangyu Zhang)、任少卿 (Shaoqing Ren) 和孙剑 (Jian Sun),他们发现使用残差块能够训练更深的神经网络。
下面这个网络,并不是一个残差网络,而是一个普通网络 (plain network),这个术语来自 ResNet 论文。

把它变成 ResNet 的方法是加上所有跳跃连接,每两层增加一个捷径,构成一个残差块。

如果我们使用标准优化算法训练一个普通网络,如梯度下降法或其他优化算法。没有残差,没有这些捷径或者跳跃连接,我们会发现,随着网络深度的增加,训练错误会先减少然后增多。而理论上,随着网络深度的增加,应该训练得越来越好才对。但实际上,对于一个普通网络来说,深度越深意味着用优化算法越难训练。
ResNets 有助于解决梯度消失和梯度爆炸问题,让我们在训练更深网络的同时,又能保证良好的性能。
Why ResNets work?
假设有一个大型神经网络,其输入为 \(X\),输出激活值 \(a^{[l]}\),标记为 Big NN。我们再给这个网络额外增加两层,最后输出为 \(a^{[l+2]}\)。可以把这两层看作一个 ResNets 块,即具有捷径连接的残差块。我们在整个网络中使用 ReLU 激活函数,所以激活值都大于等于 0。
对于 \(a^{[l+2]}\) 来说,\(a^{[l+2]}=g(z^{[l+2]}+a^{[l]})=g(W^{[l+2]}a^{[l+1]}+b^{[l+2]}+a^{[l]})\)。而使用 L2 正则化的话,会压缩 \(W^{[l+2]}\) 的值。如果 \(W^{[l+2]},b^{[l+2]}\) 的值为 0,那么 \(a^{[l+2]}=g(a^{[l]})=a^{[l]}\)。
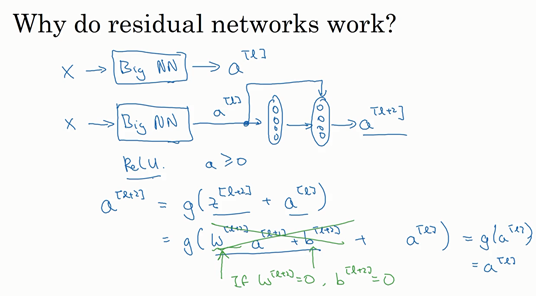
也就是说,残差块学习的是一个恒等式函数,所以它的效率并不会逊色于更简单的神经网络。
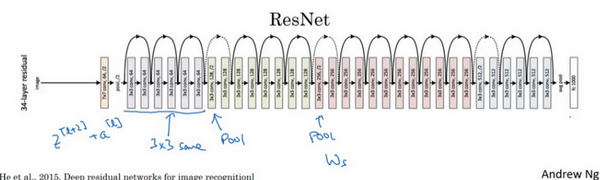
下面是一个普通网络,我们给它输入一张图片,它有多个卷积层,最后输出了一个 softmax。

只需要给它添加跳跃连接,我们就可以把它转化为 ResNets。这个网络有很多层 \(3\times3\) 卷积,而且它们大多都是 same 卷积。
1x1卷积
过滤器为 \(1\times1\),值为 2,输入一张 \(6\times6\times1\) 的图片,然后对它做卷积。因为过滤器大小为 \(1\times1\times1\),结果相当于把这个图片乘以数字 2。看起来用处不大,只是对输入矩阵乘以某个数字。
但如果是一张 \(6\times6\times32\) 的图片,那么使用 \(1\times1\) 过滤器进行卷积效果更好。具体来说,\(1\times1\) 卷积所实现的功能是遍历这 36 个单元格,计算输入中的 32 个数字和过滤器中 32 个数字的元素积之和,然后应用 ReLU 非线性函数。

所以 \(1\times1\) 卷积可以从根本上理解对这 32 个不同的位置都应用一个全连接层,以便在输入层上实施一个非平凡(non-trivial) 计算。
这种方法通常称为 \(1\times1\) 卷积,有时也被称为 Network in Network,在林敏、陈强和杨学成的论文中有详细描述。虽然论文中关于架构的详细内容并没有得到广泛应用,但是 \(1\times1\) 卷积或 Network in Network 这种理念却很有影响力,很多神经网络架构都受到它的影响。
我们可以使用 \(1\times1\) 卷积来压缩通道数 \(n_c\),因为输出层的通道数与过滤器的个数是一致的。

谷歌 Inception 网络
构建卷积层时,我们要决定过滤器的大小,要不要添加池化层等,Inception 网络的作用就是代替我们来决定卷积层中的过滤器类型。虽然网络架构会因此变得更加复杂,但网络表现却非常好。
假设我们输入层的维度是 \(28\times28\times192\),而我们可以使用多种卷积形式,然后把结果堆叠在一起。为了保持维度不变,有些过滤器需要使用 same 卷积,也就是要使用 padding。
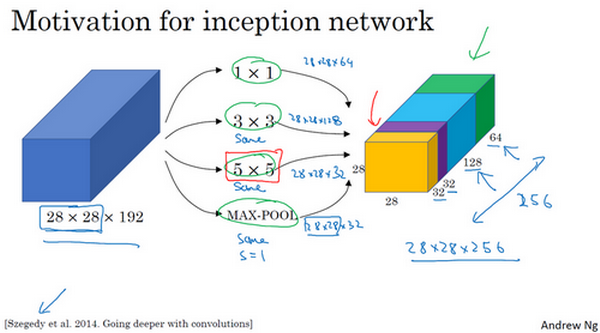
这样 Inception 模块会输出 \(28\times28\times256\)。这就是 Inception 网络的核心内容,基本思想是 Inception 网络不需要人为决定使用哪个过滤器或者是否需要池化,而是由网络自行确定这些参数。我们可以给网络添加这些参数的所有可能值,然后把这些输出连接起来,让网络自己学习需要什么样的参数,采用哪些过滤器组合。
不难发现,Inception 层可能会出现计算成本的问题。以 \(5\times5\) 过滤器为例。
直接进行 same 卷积计算的话,乘法运算的总次数为每个输出值所需要执行的乘法运算次数(\(5\times5\times192\))乘以输出值个数(\(28\times28\times32\)),也就是 1.2 亿(120422400)。

现在我们使用另外一种架构,先对输入层使用 \(1\times1\) 卷积,然后再进行 \(5\times5\) 卷积。我们先缩小网络,然后再扩大它。有时候这被称为瓶颈层。它的计算成本是这样的,第一层卷积 \((1\times1\times192)\times(28\times28\times16)\),结果约是 240 万;第二层卷积 \((5\times5\times16)\times(28\times28\times32)\),结果约是 1000 万。所以总的来说,这样的计算成本为 1240 万,相比之前的 1.2 亿,计算成本下降了十分之一。
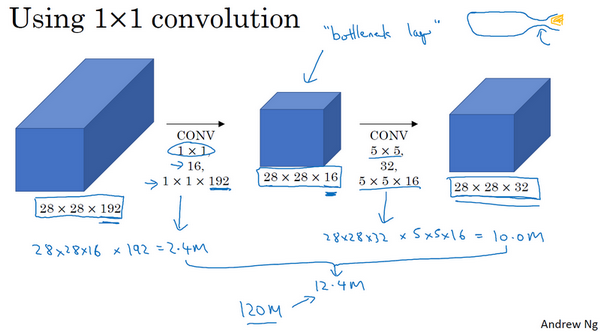
所以这样,一个 Inception 模块就变成了下图所示。需要注意的是,池化层为了维持宽和高,需要用到 padding,而为了避免最后输出,池化层占据所有通道,我们还需要用 \(1\times1\) 过滤器压缩它的通道数。

所以论文中的 Inception 网络,其实是 Inception 模块的叠加。

当然,我们也能发现它其实还有一些分支。它们包含了一个隐藏层,通过一些全连接层,然后又一个 softmax 来预测,输出结果的标签。这样,确保了即便是隐藏单元和中间层也参与了特征计算,它们也能预测图片的分类。这在 Inception 网络中,起到了一种调整的效果,并且能防止网络发生过拟合。
Inception 网络是由 Google 公司的作者所研发的,它被叫做 GoogleLeNet,为了向 LeNet 网络致敬。
目标检测 (Object detection)
目标定位 (Object localization)
定位分类问题是,不仅要用算法判断图片中是不是一辆汽车,还要在图片中标记出它的位置,用边框或红色方框把汽车圈起来。
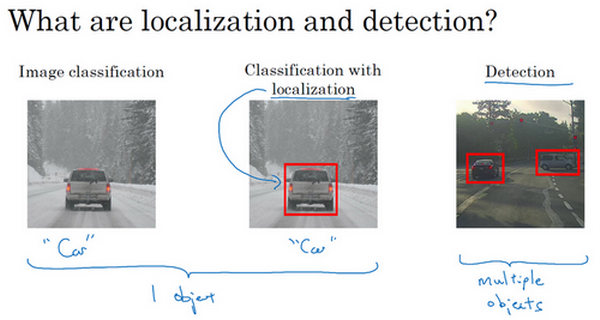
假设我们在构建汽车自动驾驶系统,对象包括以下几类:行人、汽车、摩托车和背景(不含有以上几类)。这四个分类就是 softmax 函数可能输出的结果。而我们还想定位图片中汽车的位置的话,可以让神经网络多输出几个单元,输出一个边界框,标记为 \(b_x,b_y,b_h,b_w\)。
我们设定图片左上角坐标为 \((0,0)\),右下角坐标为 \((1,1)\)。边界框的中心点为 \((b_x,b_y)\),高度为 \(b_h\),宽度为 \(b_w\)。

所以最后目标标签为
其中,\(p_c\) 表示是否含有对象,如果含有行人、汽车或摩托车,那么 \(p_c=1\),否则为 0;而 \(b_x,b_y,b_h,b_w\) 是边界框的参数;\(c_1,c_2,c_3\) 则表示对象属于行人、汽车或摩托车中的哪一类。不过这个问题里,我们假设图片最多只会出现其中一个对象。
所以上面展示的汽车的图片,它的标签则为
如果图片中没有检测对象,那么标签则为
因为这种情况下,\(p_c=0\),其他参数变得毫无意义,所以我们写成问号,表示"don't care"的参数。
这样神经网络的损失函数分两种情况。如果图片存在定位对象,也就是 \(y_1=p_c=1\),那么损失值为 \(L\left(\hat{y},y \right) = \left( \hat{y_1} - y_{1} \right)^{2} + \left(\hat{y_2} - y_{2}\right)^{2} + \ldots\left( \hat{y_8} - y_{8}\right)^{2}\),即每个元素相应差值的平方和。如果不存在定位对象,也就是 \(y_1=p_c=0\),那么损失值为 \((\hat{y_1}-y_1)^2\),这种情况下,我们只需要关注输出 \(p_c\) 的准确度。
特征点检测 (Landmark detection)
假设我们正在构建一个人脸识别应用,我们可能需要定位很多个脸部特征点。需要做的就是,对神经网络稍做修改,输出这些特征点的坐标 \((l_{1x},l_{1y}),(l_{2x},l_{2y}),\dots\)。

具体做法是,准备一个卷积神经网络和一些特征集。将人脸图片输入卷积网络,输出 1 (有人脸)或 0 (无人脸),然后输出各个特征点的坐标。假设有 64 个特征点的话,我们这里就有 129 个输出单元。
基于滑动窗口的目标检测算法
假设我们想构建一个汽车检测算法。首先,创建一个标签训练集,如下图所示,这些图片几乎都被汽车占据,是剪裁过的图片。使用这些图片去训练卷积神经网络,然后我们就可以用它来实现滑动窗口目标检测。

以图中的图片作为测试图片,首先选定一个特定大小的窗口(图中的红色方框),然后将窗口中的内容输入卷积神经网络进行预测。然后窗口不断滑动与预测,直到这个窗口滑过图像的每一个角落。

我们还可以用更大一些的窗口再进行一遍滑动,重复这些操作。这样,不论汽车在图片的什么位置,总有一个窗口可以检测到它。
滑动窗口目标检测算法的缺点很明显,就是计算成本。滑动步长大一些可以减少窗口个数,但是粗糙间隔尺寸会影响性能。
把神经网络的全连接层转化成卷积层
以下图中第一行的卷积神经网络为例。要把两个全连接层转换为卷积层,需要做的是,用 400 个 \(5\times5\times16\) 过滤器和 \(1\times1\times400\) 过滤器来代替,也就如下图中第二行所示。
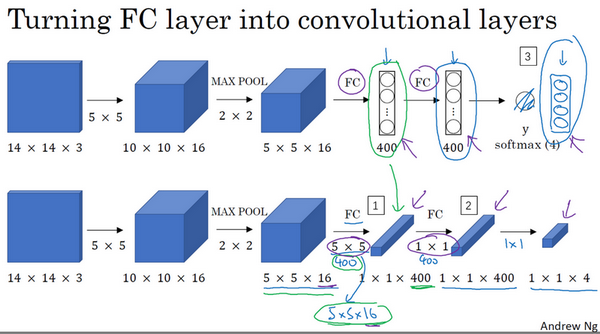
滑动窗口的卷积实现
假设我们训练集使用的图片大小是 \(14\times14\times3\),要检测的图片是 \(16\times16\times3\) 大小的。设定的窗口大小为 \(14\times14\),步长为 2,那么一共要滑动 4 次,运行 4 次卷积网络。
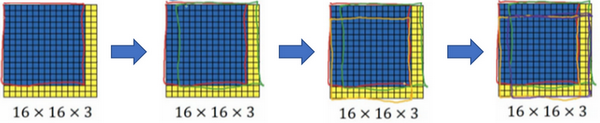
可是我们发现,这 4 次卷积中很多计算都是重复的,尤其在第一步中。我们可以对其进行卷积实现。

直接将整张图片输入卷积神经网络,如上图所示。这样我们可以一次性得到 4 次卷积的结果。
Bounding Box 预测
为了得到更精准边界框,我们可以使用 YOLO 算法,YOLO (You onlu look once) 算法由 Joseph Redmon,Santosh Divvala,Ross Girshick 和 Ali Farhadi 提出。
具体做法是,在图像上放一个网格。方便起见,举例使用的是 \(3\times3\) 网格,实际实现时会用更精细的网格,如 \(19\times19\)。然后将算法应用到 9 个格子上,每个格子会有一个对应的 \(y\) 标签。我们之前定义的 \(y\) 标签如下
这样,我们就会有一个 \(3\times3\times8\) 的输出。我们输入的目标标签 \(y\) 也应该是 \(3\times3\times8\) 的。

需要注意的是,把对象分配到格子是指将这个对象的中点分配到的格子。所以即使对象可以横跨多个格子,也只会被分配到 9 个格子其中之一。如果使用更精细的网格,两个对象的中点处于同一个格子的概率就会更低。而且,由于边界框坐标是以格子为基础定义的,当对象比较大时,边界框可能会超出格子,其宽 \(b_w\) 和高 \(b_h\) 可能会大于 1。
YOLO 算法的一个优点就是,因为这是一个卷积实现,所以它的运行速度非常快,可以达到实时识别。
交并比 (Intersection over union)
当算法给我们输出了边界框,我们要如何判断这个结果的好坏呢?这时,我们就能用到交并比。交并比 (IoU) 函数计算的算法输出的边界框与实际边界框的交集和并集之比。如下图中,算法给出的是紫色边界框,实际边界框是红色的,那么他们的并集是绿色阴影区域,交集是黄色阴影区域。

一般约定,在计算机检测任务中,如果 \(IoU\ge0.5\),就表示检测正确。当然,IoU 越高,边界框越精确。
非极大值抑制 (Non-man suppression)
算法可能对同一个对象做出多次检测,而非极大值抑制可以确保算法对每个对象只检测一次。
当我们运行对象分类和定位算法时,每个格子都运行一次,所以可能会有很多个格子都输出检测到车的结果。而非极大值抑制做的就是清理这些检测结果。

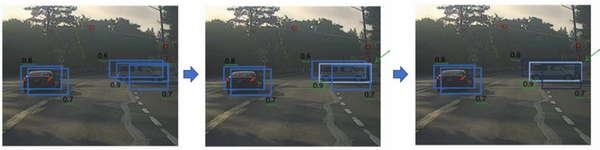
具体来说,算法首先会看看每次报告每个检测结果相关的概率 \(p_c\),然后认为概率最大的那个边框是最可靠的检测。以上图中的右边车辆为例,0.9 的边框是概率最大的边框。然后,非极大值抑制会逐一审视剩下的边框,所有和这个最大的边框有很高的交并比的话,这些边框(如上图中右边车辆的 0.6 和 0.7 边框)就会被抑制。然后,在最后剩下的边框中,选择 \(p_c\) 最高的一个作为最后的输出结果。

当然,在极大值抑制之前,可以先做一遍筛选,把预测概率小于某个阈值(假设为 0.6)的边框去除。
如果要同时检测三种对象,比如说行人、汽车、摩托车。那么,我们应该独立进行三次非极大值抑制,对每个输出类别都做一次。
Anchor Boxes
假设我们想让一个格子检测出多个对象,我们可以使用 anchor box。以下图为例,行人和汽车的中点几乎在同一个地方,如果我们仍然按之前的定义来定义输出向量 \(y\),算法将无法输出检测结果。

而 anchor box 的思路是,先定义两个不同形状的 anchor box,然后把预测结果和这两个 anchor box 关联起来。当然,有时候可能会使用到更多的 anchor box,5个甚至更多。
于是我们要使用的标签 \(y\) 就定义成如下所示
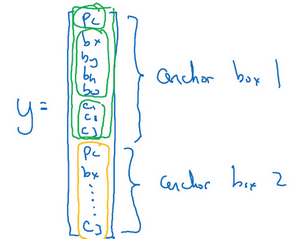
不用 anchor box 的话,输出 \(y\) 的维度是 \(3\times3\times8\),而用了两个 anchor box 之后,我们的输出维度就成了 \(3\times3\times16\),或者说是 \(3\times3\times2\times8\)。而且,使用了 anchor box 之后,当我们检测到对象,要确定把它归为哪个 anchor box,是使用交并比进行判断的。如下图中,检测出来红色边框 1 与 anchor box 2 有更高的交并比,所以它的数据将写入标签中 anchor box 2 的位置。

综合 YOLO 算法
现在我们将之前谈到的组件都组装到 YOLO 算法中来。
首先,我们先来构建训练集。假设我们要训练一个算法去检测三种对象:行人、汽车和摩托车,使用两个 anchor box,那么我们的标签 \(y\) 就是 \(3\times3\times2\times8\),如下图所示。

以编号 1 的格子为例,里面没有我们需要检测的对象,所以它的标签 \(y\) 为上图中第二个 \(y\) 标签所示,\(p_c\) 都为 0,其他的为 don't cares。而对于编号 2 的格子,我们可以检测到里面的汽车,而且它的边界框(编号 3)和第二个 anchor box(编号 5)的交并比更高,所以编号 2 格子的标签 \(y\) 为上图中的第三个 \(y\) 标签所示。
预测的过程其实类似。仍然使用 2 个 anchor box,那么对于 9 个格子中任何一个都会有两个预测的边界框,其中一个的概率 \(p_c\) 很低。接下来,我们去掉那些概率很低的边界框。最后,我们对每个检测类别单独运行非极大值抑制。
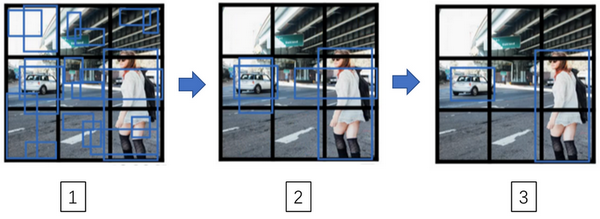
候选区域 (Region proposal)
Ross Girshick,Jeff Donahue,Trevor Darrell 和 Jitendra Malik 提出了一种叫 R-CNN 的算法,也叫做区域 CNN。这个算法尝试选出一些区域,在这些区域上运行卷积神经网络,而不是每个滑动窗口。
选出候选区域的方法是运行图像分割算法,找出可能存在对象的区域。
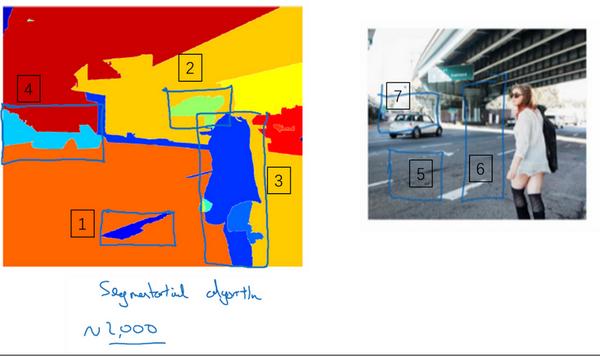
现在 R-CNN 算法的一个缺点是太慢了,所以这些年来有一些对 R-CNN 算法的改进工作。如 Ross Girshik 提出了快速的 R-CNN 算法,它的基本原理还是 R-CNN 算法,不过用卷积实现了滑动窗口。

但是快速 R-CNN 算法在获取候选区域的聚类步骤仍然非常缓慢。任少卿等人提出了更快的 R-CNN 算法,使用卷积神经网络来获取候选区域色块。不过这些算法实现其实还是比 YOLO 算法慢得多。
人脸识别 (Face recognition)
人脸验证 (face verification) 和人脸识别 (face recognition) 其实不是一样的问题。
人脸验证是,假设我们有一张输入图片,以及某人的 ID 或者是名字,系统要做的是,验证输入图片是否是这个人。有时候也被称作 1 对 1 问题,只需要弄明白这个人是否和他声称的身份相符。
人脸识别是,假设我们有一个验证系统,里面有 K 个人的数据,然后我们输入一张图片,系统该输出这张图片是系统中的哪一个人或者不在系统内。
一次学习 (One-shot learning)
人脸识别所面临的一个挑战就是需要解决一次学习问题,这意味着在大多数人脸识别应用中,我们需要通过单单一张图片或者单单一个人脸样例就能去识别这个人。而之前我们知道,深度学习是需要大量的训练数据的。
现在假设数据库里有 4 张公司员工的照片,然后系统得辨认编号 1 和编号 2 是不是数据库中四个人之一。

所以在一次学习问题中,只能通过一个样本进行学习,以能够认出同一个人。
有一种办法是,将人的照片放进卷积神经网络进行训练,使用 softmax 来输出 5 种标签分别对应这 4 个人或者不在数据库中。但这有两个问题,一是这么小的训练集不足以训练一个稳健的神经网络,二是如果临时有新人加入公司,softmax 的输出就要变成 5 种标签,那么这个卷积神经网络也就要重新训练了。
所以,我们可以学习 similarity 函数。具体来说,就是它以两张图片作为输入,然后输出这两张图片的差异值。如果是同一个人的两张照片,我们希望它输出一个很小的值;如果是两个长相差别很大的人的照片,它输出一个很大的值。所以在识别过程中,如果两张图片的差异值小于某个阈值 \(\tau\),那么我们就认为这两张图片是同一个人;反之,则是不同的人。

Siamese 网络 (Siamese network)
一般来说,将图片输入卷积神经网络,经过一些卷积、池化和全连接层,最终会得到一个特征向量(如下图中的编号 1 和编号 2),然后把这个特征向量输入 softmax 单元来做分类。但在 siamese 网络中,我们会把这个特征向量作为输入图片的特征编码。然后比较两张图片的特征编码之差的范数。

这就是 siamese 网络架构,它来自 Yaniv Taigman,Ming Yang,Marc‘ Aurelio Ranzato 和 Lior Wolf 开发的 DeepFace 系统。
所以这个网络的目标就是,它计算得到的编码可以用于函数 \(d\),以用来区别两张图片是否是同一个人。
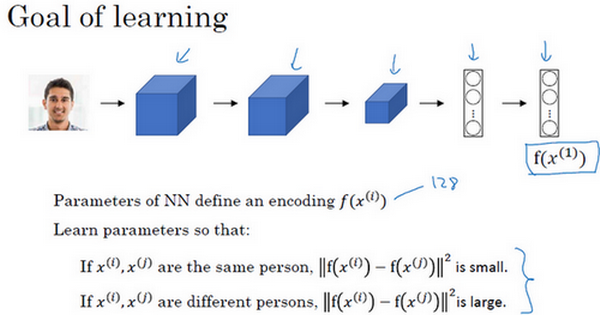
三元组损失 (Triplet loss)
要想通过学习神经网络的参数来得到优质的人脸图片编码,方法之一就是定义三元组损失函数然后应用梯度下降。
为了应用三元组损失函数,我们需要比较成对的图像。如下图。

我们要做的就是将 Anchor 图片和 Positive 图片的距离很接近,而和 Negative 图片的距离更远。
所以,三元组损失代表我们通常会同时看三张图片:Anchor (A),Positive (P) 和 Negative (N)。也就是我们希望
也就是 \(d(A,P)\leq d(A,N)\)。公式也可以变形成如下所示
但是,如果 \(f\) 总是输出为 0 的话,这个公式没有任何意义,它会一直成立。所以我们需要使它小于一个很小的负数 \(-\alpha\),它也叫间隔 (margin)。通常,这个值也是写在公式的左边。
这样的话,损失函数也是基于三元图片组,取这个和 0 的最大值。如下所示
只要这个距离差小于等于 0,网络并不会关心它的负值有多大。
整个网络的代价函数就是这些单个三元组损失的总和。
假设我们的训练集是来自 1,000 个人的 10,000 张照片,可能是平均每个人 10 张照片。我们要把它们组成成对的三元组。如果每个人我们只有一张照片,那么就没法训练这个系统。但是,在训练完这个系统后,可以把它应用到 one-hot learning 问题上。
如果我们随机的选择 \(A,P,N\) 构成三元组的话,那么约束条件 \(d(A,P) + a \leq d(A,N)\) 很容易达到。所以我们应该尽可能选择难训练的三元组,也就是 \(d(A,P)\) 很接近 \(d(A,N)\),即 \(d(A,P)\approx d(A,N)\)。这样算法会竭尽全力使右边这个式子变大或者左边这个式子变小。并且这样选择还能增加学习算法的计算效率,节省资源去计算简单的三元组。
人脸识别与二分类
另一种训练神经网络的方法是选取一对神经网络,选取 siamese 网络,使其同时计算这些输入图片,然后将其特征向量输入到逻辑回归单元进行预测。如果是相同的人,输出为 1,否则为 0.这就把人脸识别问题转换为了一个二分类问题。

假如特征向量是 128 维的,那么最后的逻辑回归单元其实就是计算如下
也有其他的形式来计算,如 \(\chi^{2}\) 公式。
有一个计算技巧帮我们显著提高部署效果。我们可以把数据库中的图片存储为特征编码,而每次进行人脸识别时,我们只需要计算新图片的特征编码,然后将它和数据库中的编码进行比较,就可以输出预测值。
神经风格迁移 (Neural style transfer)
神经风格迁移就是将风格图像 (S) 中的风格应用到内容图像 (C) 上,生成新的图像 (G)。如下。

CNN 特征可视化
我们可以可视化卷积网络中深度较大的层真正在做什么。
以下面的 Alexnet 为例。

我们看第一层的隐藏单元,找到那些使得单元激活最大化的一些图片或者是图片块。选择一些隐藏单元,可以看到不同的隐藏单元找到了不同的边缘或者特征。

第一层的隐藏单元通常会找一些简单的特征,比如说边缘或者颜色阴影。
随着层数的加深,我们可以看到一些更复杂的特征。


代价函数
神经风格迁移系统的代价函数 \(J\) 是用来评判生成图像 G 的好坏。我们把这个代价函数定义分为两个部分。
第一部分被称作内容代价 \(J_{content}(C,G)\),这是一个关于内容图片和生成图片的函数,它用来度量生成图片的内容与内容图片的内容有多相似。
第二部分为风格代价 \(J_{style}(S,G)\),它用来度量生成图片的风格和风格图片的风格的相似度。
那么我们用两个超参数 \(\alpha\) 和 \(\beta\) 作为两部分代价的权重。
对于代价函数来说,为了生成一个新图像,我们需要随机初始化生成图像 G。然后使用梯度下降的方法将代价函数最小化,更新 \(G:=G-\frac{\partial}{\partial G}J(G)\)。这里其实我们更新的是生成图像的像素值。
下图是一个例子,我们从内容图片(编号 1)和风格图片(编号 2)开始,最开始初始化一张白噪声图(编号 3)。然后不断迭代更新,逐渐生成图片(编号4, 5, 6)。

内容代价函数
通常我们会在隐含层 \(l\) 来计算内容代价。由于太浅的隐含层特征过于简单,太深的隐含层特征过于复杂,所以 \(l\) 一般既不太浅也不很深。
我们使用 \(a^{[l][C]}\) 和 \(a^{[l][G]}\),代表这两个图片 \(C\) 和 \(G\) 的 \(l\) 层的激活函数值。为了衡量他们在内容上的相似度,我们定义内容代价函数为
我们取 \(l\) 层的隐含单元的激活值,按元素相减,内容图片的激活值与生成图片相比较,然后取平方,也可以在前面加上归一化或者不加,比如 \(\frac{1}{2}\) 或者其他的,都影响不大,因为这都可以由这个超参数 \(\alpha\) 来调整。
风格代价函数
假如下图这样一个神经网络,我们选择某一层 \(l\)(编号 1),使用这一层为图片的风格定义一个深度测量。我们要做的就是将图片的风格定义为这一层中各个通道之间激活项的相关系数。
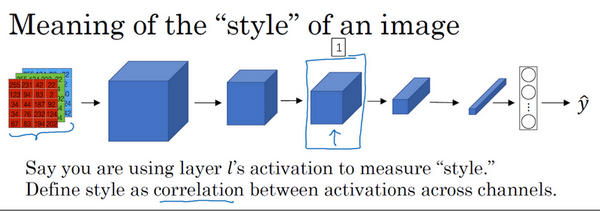
我们把这一层的激活项取出,假设它有 5 个通道,以不同的颜色表示。

而假设红色的通道(编号 1)对应的是编号 3 神经元,它能找出图片中特定位置是否含有垂直的条纹;而黄色的通道(编号 2)对应的是编号 4 神经元,它能粗略地找出橙色的区域。那么如果它们有高度相关性,这幅图片中出现垂直纹理的地方,很大概率就会是橙色的;如果它们不相关,这幅图片中出现垂直纹理的地方,很大概率就不会是橙色的。所以我们需要使用不同通道之间的相关系数来定义图片的风格。

这样,我们需要计算一个风格矩阵 \(G^{[l](S)}\),它是一个 \(n_c\times n_c\) 维度的矩阵。设 \(a_{i,\ j,\ k}^{[l]}\) 为隐藏层 \(l\) 中 \((i,j,k)\) 位置的激活项,在这个矩阵中 \(k\) 和 \(k'\) 元素被用来描述 \(k\) 通道和 \(k'\) 通道之间的相关系数。那么
其实就是将两个通道上不同位置的激活项乘积都加起来。严格来说,它是一种非标准的互相关函数,因为我们没有减去平均数。
然后,我们对生成图像做同样的操作。
如果两个通道中的激活项数值都很大,那么 \(G_{{kk}^{'}}^{[l]}\) 也会变得很大,对应地,如果他们不相关那么 \(G_{{kk}^{'}}^{[l]}\) 就会很小。
最后,如果我们将 \(S\) 和 \(G\) 代入到风格代价函数中去计算,这将得到这两个矩阵之间的误差,因为它们是矩阵,所以在这里加一个 \(F\)(Frobenius范数),这实际上是计算两个矩阵对应元素相减的平方的和,我们把这个式子展开,从 \(k\) 和 \(k'\) 开始作它们的差,把对应的式子写下来,然后把得到的结果都加起来,作者在这里使用了一个归一化常数,也就是 \(\frac{1}{2n_{H}^{[l]l}n_{W}^{[l]}n_{C}^{[l]}}\),再在外面加一个平方,但是一般情况下我们不用写这么多,一般我们只要将它乘以一个超参数 \(\beta\) 就行。
最后,我们只要按代价函数的公式,把这两部分组装起来就可以了。
References
[2] 深度学习 500 问
