《Neural Networks and Deep Learning》课程笔记
# Lesson 1 Neural Network and Deep Learning
这篇文章其实是 Coursera 上吴恩达老师的深度学习专业课程的第一门课程的课程笔记。
参考了其他人的笔记继续归纳的。
逻辑回归 (Logistic Regression)
逻辑回归的定义
神经网络的训练过程可以分为前向传播(forward propagation) 和反向传播 (backward propagation) 的 过程。我们通过逻辑回归的例子进行说明。
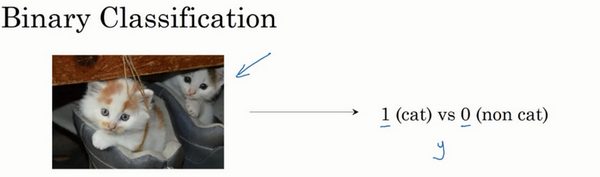
逻辑回归是一个用于二分类 (binary clasification) 的算法。比如说,我们有一张图片作为输入,比如下图中的猫,如果识别这张图片为猫,则输出标签1作为结果;如果识别出不是猫,那么输出标签0作为结果。而我们把输出结果用 \(y\) 表示就如下图所示。
图片在计算机中保存的话,我们需要保存三个矩阵,它们分别对应图片中的红、绿、蓝三种颜色通道。如果图片是 \(64\times64\) 像素的,那么这三个矩阵的大小都是 \(64\times64\)。
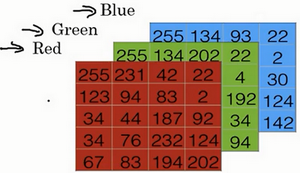
为了把这张图片的像素值转换为特征向量 \(x\),我们需要把三个矩阵展开为一个向量,而这个向量的总维度用 \(n_x\) 表示的话,就是 \(n_x=3\times64\times64=12,288\)。
符号定义:
\(x\):表示一个 \(n_x\) 维数据,为输入数据,维度为 \((n_x,1)\);
\(y\):表示输出结果,取值为 \((0,1)\);
\((x^{(i)},y^{(i)})\):表示第 \(i\) 组数据,可能是训练数据,也可能是测试数据;
\(X=[x^{(1)},x^{(2)},\dots,x^{(m)}]\):表示所有的训练数据集的输入值,放在一个 \(n_x\times m\) 的矩阵中,每一列为一组数据,其中 \(m\) 表示样本数目;
\(Y=[y^{(1)},y^{(2)},\dots,y^{(m)}]\):对应表示所有训练数据集的输出值,维度为 \(1\times m\)。
其实对于逻辑回归来说,我们想要的输出结果是预测,称为 \(\hat{y}\),也就是对实际值 \(y\) 的估计。\(\hat{y}\) 表示 \(y=1\)
的一种可能性,用上面的例子来说,就是让 \(\hat{y}\) 告诉我们这是一只猫的图片的几率有多大。
逻辑回归使用的参数有两个: \(w\) (表示特征权重,维度与特征向量相同)和 \(b\) (表示偏差)。这时我们不能使用 \(\hat{y}=w^Tx+b\) 进行预测,这实际是一个线性回归,而我们需要让 \(\hat{y}\) 在 0 到 1 之间来表示对结果的预测。因此,我们使用 sigmoid 函数,这个非线性函数,即 \(\hat{y}=\sigma(w^Tx+b)\)。
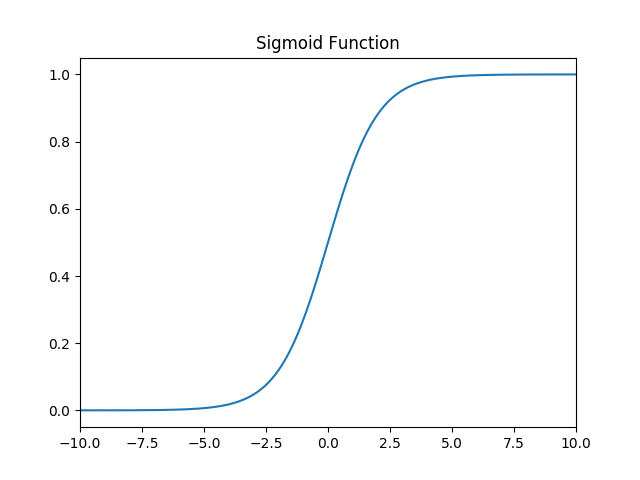
sigmoid 函数
函数的定义为:$ f(x) = \frac{1}{1 + e^{-x}} $,其值域为 $ (0,1) $。
函数图像如下所示
逻辑回归的代价函数
为了训练逻辑回归模型的参数,我们需要一个代价函数 (cost function),有时也翻译为成本函数。我们通过训练代价函数来得到我们需要的参数 \(w\) 和 \(b\)。
损失函数 (loss function),又称为误差函数,用来衡量算法的运行情况。一般定义为:\(L(\hat{y},y)\)。
通过损失函数,我们可以衡量预测输出值和实际值有多接近。一般我们用预测值和实际值的平方差或者它们平方差的一半,但是通常在逻辑回归中不这么做。因为学习逻辑回归参数的时候,我们的优化目标不是凸优化,只能找到多个局部最优值,梯度下降法很可能找不到全局最优值。
所以,在逻辑回归中使用的损失函数是
当 \(y=1\) 时,损失函数 \(L=-log(\hat{y})\),如果想要损失函数尽可能的小,那么 \(\hat{y}\) 就要尽可能大,因为 sigmoid 函数值域是 \((0,1)\),所以 \(\hat{y}\) 会无限接近 1。
当 \(y=0\) 时,损失函数 \(L=-log(1-\hat{y})\),如果想要损失函数尽可能的小,那么 \(\hat{y}\) 就要尽可能小,因为 sigmoid 函数值域是 \((0,1)\),所以 \(\hat{y}\) 会无限接近 0。
当然,损失函数只是对于单个训练样本定义的,它衡量的是算法在单个训练样本中表现如何。为了衡量算法在全部训练样本上的表现如何,我们需要定义一个算法的代价函数,也就是对 \(m\) 个样本的损失函数求均值:
所以在训练逻辑回归模型时候,我们需要找到合适的参数来让代价函数的总代价降到最低。逻辑回归可以看作一个非常小的神经网络。
梯度下降法 (Gradient Descent)
梯度下降法可以在测试集上,通过最小化代价函数 \(J(w,b)\) 来训练参数 \(w\) 和 \(b\)。
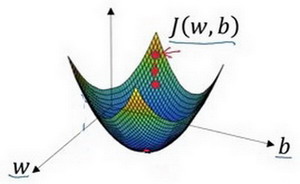
形象化地来表示梯度下降法如下图所示。
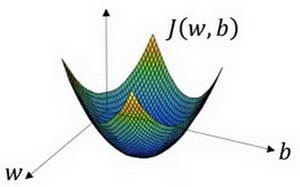
在上图中,横轴表示参数 \(w\) 和 \(b\),在实际操作中,\(w\) 可以是更高维度的。这里仅为了绘图需要,定义 \(w\) 和 \(b\) 为单一实数,代价函数就是图中的曲面,因此曲面的高度就是代价函数 \(J(w,b)\) 在某一点的函数值。

如上图,代价函数是一个凸函数 (convex function)。

而上图,就不太一样了。它是非凸的,而且有很多个不同的局部最小值。由于逻辑回归的代价函数的特性,我们必须定义代价函数 \(J(w,b)\) 为凸函数。初始化参数 \(w\) 和 \(b\) 可以采用随机初始化的方法,对于逻辑回归几乎所有的初始化方法都有效,因为函数是凸函数,无论在哪里初始化,应该达到同一点或大致相同的点。
比如说下图,从最开始的小红点开始初始化,朝最陡的下坡方向走,不断地迭代,直到走到全局最优解或者接近全局最优解的地方。
细节化说明梯度下降法
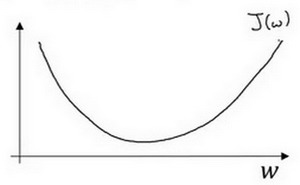
假定代价函数 \(J(w)\) 只有一个参数 \(w\),即用一维曲线代替多维曲线。如下图所示。
迭代就是不断地重复下图的公式:
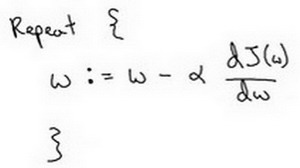
其中,
\(:=\) 表示更新参数,
\(\alpha\) 表示学习率 (learning rate),用来控制步长 (step),即向下走一步的长度 \(\frac{dJ(w)}{dw}\) 就是函数 \(J(w)\) 对 \(w\) 求导 (derivative),在代码中我们会使用 \(dw\) 表示这个结果。
对于导数更加形象化的理解就是斜率 (slope),如图该点的导数就是这个点相切于 \(J(w)\) 的小三角形的高除宽。假设我们以如图点为初始化点,该点处的斜率的符号是正的,即 \(\frac{dJ(w)}{dw}>0\),所以接下来会向左走一步。整个梯度下降法的迭代过程就是不断地向左走,直至逼近最小值点。

那么现在把代价函数的参数重新设定为两个,\(w\) 和 \(b\)。迭代的公式则为:
其中,\(\partial\) 表示求偏导符号,\(\frac{\partial{J(w,b)}}{\partial {w}}\) 就是函数 \(J(w,b)\) 对 \(w\) 求偏导。
逻辑回归中的梯度下降
假设样本只有两个特征 \(x_1\) 和 \(x_2\),为了计算 \(z\),我们需要输入参数 \(w_1\)、\(w2\) 和 \(b\),除此之外还有特征值 \(x_1\) 和 \(x_2\)。因此 \(z\) 的计算公式为:
回想一下逻辑回归的公式:
其中 \(z=w^Tx+b\), \(\sigma(z)=\frac{1}{1+e^{-z}}\)。
损失函数:
代价函数:
现在先只考虑单个样本的情况,单个样本的代价函数(也就是损失函数)为:
其中,\(a\) 是逻辑回归的输出,\(y\) 是样本的标签值。
前面我们已经说了如何在单个训练样本上计算代价函数的前向步骤,现在我们来通过反向计算出导数。
而对于参数 \(w\) 和 \(b\) 来说:
而对于我们刚刚说的单样本情况:
所以,总得来说,单样本的梯度下降算法更新一次步骤如下:
- 计算 \(dz\);
- 计算 \(dw_1,dw_2,db\);
- 更新 \(w_1,w_2,b\)
扩展到 m 个样本的梯度下降是类似的。给相应的值,添加上标 \(^{(i)}\) 就行了。
伪代码如下图所示。

向量化 (Vectorization)
向量化是非常基础的去除代码中 for 循环的艺术。for 循环非常没有效率而且也没美观。
向量化后的公式如下:
前向传播
后向传播
当然,我们希望多次迭代进行梯度下降,仍然还会需要使用到 for 循环。
浅层神经网络 (Shallow Neural Network)
神经网络看起来是下图这个样子。我们可以把许多个 sigmoid 单元堆叠起来形成一个神经网络。
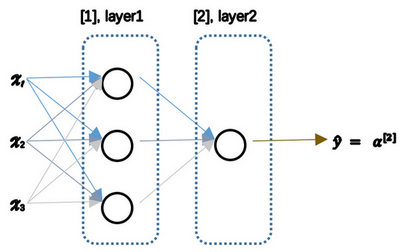
在这个神经网络对应的 3 个节点,首先计算第一层网络中的各个节点相关的数 \(z^{[1]}\),接着计算 \(a^{[1]}\)。同理再计算下一层的网络。注意这里,我们使用了上标 \(^{[m]}\) 表示第 m 层网络中节点相关的数,这些节点的集合被称为第 m 层网络。
整个计算过程,公式如下:
此时 \(a^{[2]}\) 就是整个神经网络最终的输出,用 \(\hat{y}\) 表示网络的输出。
与逻辑回归类似,神经网络我们也需要反向计算。
神经网络的表示
以下图的神经网络例子来说明一下。
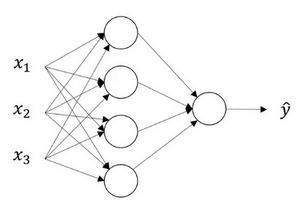
其中输入特征 \(x_1,x_2,x_3\),被称为神经网络的输入层 (input layer);接着第二层的四个节点,我们称之为隐藏层 (hide layer);最后只有一个结点构成的层被称为输出层 (output layer),它负责产生预测值。在论文里,也有人把这个神经网络称为一个两层的神经网络,因为输入层不算作一个标准的层。
引入符号标记
在这里,我们用符号 \(a^{[0]}\) 表示输入特征,从而替代了向量 \(x\)。\(a\) 表示激活的意思,它以为着网络中不同层的值会传递到它们后面的层中,输入层将 \(x\) 传递给隐藏层,所以我们将输入层的激活值称为 \(a^{[0]}\)。同理,下一层即隐藏层也会产生激活值,我们记为 \(a^{[1]}\)。它们是向量,具体地说,隐藏层的第一个单元我们将表示为 \(a^{[1]}_1\),以此类推。
隐藏层以及最后的输出层是带有参数的,这里的隐藏层将有两个参数 \(W\) 和 \(b\)。因为隐藏层算第一层,所以我们给它们加上上标 \(^{[1]}\),即 \((W^{[1]},b^{[1]})\)。在这个例子里,参数 \(W\) 是一个 \(4\times3\) 的矩阵,而参数 \(b\) 是一个 \(4\times1\) 的向量。其中,4 源自于隐藏层有 4 个节点(隐藏层单元),3 源自于输入层有 3 个输入特征。相似地,输出层也有参数 \(W^{[2]}\) 和 \(b^{[2]}\),它们的维数分别是 \(1\times4\) 和 \(1\times1\)。
神经网络的计算
依旧以上面的两层的神经网络为例。我们从隐藏层的第一个神经元开始计算,与逻辑回归相似,这个神经元的计算同样也分为两步:
第一步,计算 \(z_1^{[1]}\),\(z_1^{[1]}=w_1^{[1]T}x+b_1^{[1]}\);
第二步,通过激活函数计算 \(a_1^{[1]}\),\(a_1^{[1]}=\sigma(z_1^{[1]})\)。
隐藏层的余下几个神经元的计算过程一样,只是符号表示不同,最终分别可以得到 \(a_2^{[1]},a_3^{[1]},a_4^{[1]}\)。
向量化计算
转换成向量化之后,公式如下
具体到第一层隐藏层的计算则如下
也就是对于我们简单的两层神经网络来说,只需要四个公式就能计算完
而对于 m 个样本来说,只需要对每个样本计算这个四个公式就行了,使用 for 循环就能实现。当然,可以向量化的话,我们还是要使用向量化。
按列把变量都拼成矩阵,类似如下
那么计算就可以变形为如下所示
其中上标 \(^{(i)}\) 代表的是第 i 个样本。
激活函数 (Activation functions)
使用一个神经网络时,需要决定使用哪种激活函数用在隐藏层上,哪种用在输出节点上。之前,我们都一直在用 sigmoid 函数,但是,有时其他的激活函数效果会更好。
常用的激活函数
(1)sigmoid 激活函数
函数的定义为:$ f(x) = \frac{1}{1 + e^{-x}} $,其值域为 $ (0,1) $。
函数图像如下:
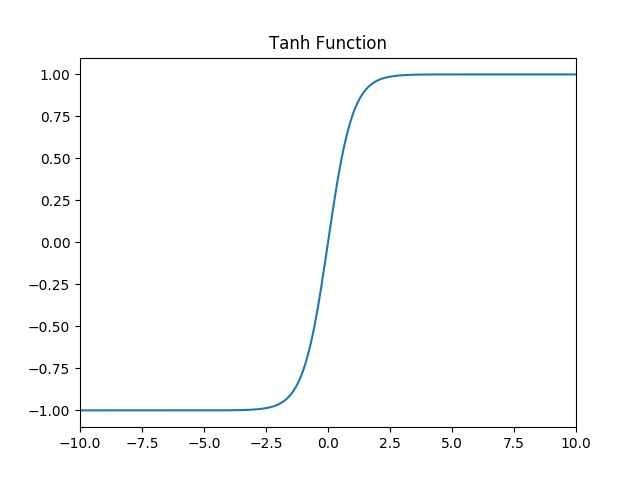
(2)tanh 激活函数
函数的定义为:$ f(x) = tanh(x) = \frac{e^x - e{-x}}{ex + e^{-x}} $,值域为 $ (-1,1) $。
函数图像如下:
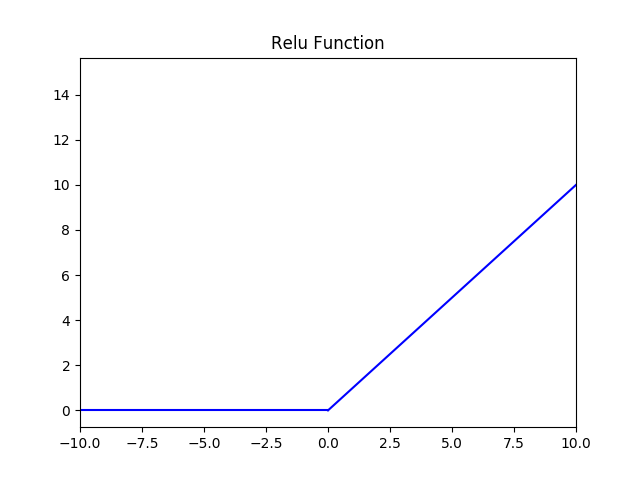
(3)Relu 激活函数
函数的定义为:$ f(x) = max(0, x) $ ,值域为 $ [0,+∞) $;
函数图像如下:
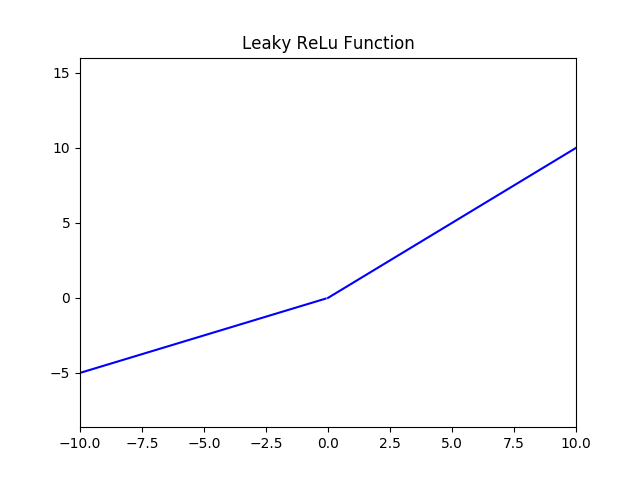
(4)Leak Relu 激活函数
函数定义为:
,值域为 $ (-∞,+∞) $。
图像如下($ a = 0.5 $):
选择激活函数的经验法则
如果输出是 0、1 值(二分类问题),则输出层选择 sigmoid 函数,然后其它的所有单元都选择 Relu 函数。
这是很多激活函数的默认选择,如果在隐藏层上不确定使用哪个激活函数,那么通常会使用 Relu 函数。
有时,也会使用 tanh 函数,但 Relu 的一个优点是:当 \(z\) 值为负时,导数等于 0。在 \(z\) 的区间变动很大的情况下,激活函数的导数或者激活函数的斜率都会远大于 0,在实践中,使用 Relu 激活函数神经网络通常会比使用 sigmoid 或者 tanh 激活函数学习的更快。而且,sigmoid 和 tanh 函数的导数在正负饱和区的梯度都会接近于0,这会造成梯度弥散,Relu 和 Leaky Relu 函数大于 0 部分都为常数,不会产生梯度弥散现象(但是,Relu 进入负半区的时候,梯度为 0,神经元此时不会训练,产生所谓的稀疏性,而 Leaky Relu 不会有这问题)。
所以,总得来说:
sigmoid 函数:除了输出层是一个二分类问题,基本不会用它;
tanh 函数:几乎适合所有场合;
Relu 函数:最常用的默认函数,如果不确定用哪个激活函数,就使用 Relu 或者 Leaky Relu。其中,Leaky Relu 的参数 \(a\) 一般设为 0.01。
激活函数的导数
对常见激活函数,导数计算如下:
| 原函数 | 函数表达式 | 导数 | 备注 |
|---|---|---|---|
| Sigmoid 激活函数 | \(f(x)=\frac{1}{1+e^{-x}}\) | \(f^{'}(x)=\frac{1}{1+e^{-x}}\left( 1- \frac{1}{1+e^{-x}} \right)=f(x)(1-f(x))\) | 当 \(x=10\),或 \(x=-10\),\(f^{'}(x) \approx0\),当 \(x=0\)\(f^{'}(x) =0.25\) |
| Tanh 激活函数 | \(f(x)=tanh(x)=\frac{e^x-e^{-x}}{e^x+e^{-x}}\) | \(f^{'}(x)=-(tanh(x))^2\) | 当 \(x=10\),或 \(x=-10\),\(f^{'}(x) \approx0\),当 \(x=0\)\(f^{`}(x) =1\) |
| Relu 激活函数 | \(f(x)=max(0,x)\) | \(f^{'}(x)=\begin{cases} 0,x<0 \\ 1,x>0 \\ undefined,x=0\end{cases}\) | 通常 \(x=0\) 时,给定其导数为 1 和 0 |
| Leaky Relu 激活函数 | \(f(x)=max(0.01x,x)\) | \(f^{'}(x)=\begin{cases} 0.01,x<0 \\ 1,x>0 \\ undefined,x=0\end{cases}\) | 通常 \(x=0\) 时,给定其导数为 1 和 0.01 |
随机初始化 (Random Initialization)
训练神经网络时,权重随机初始化是很重要的。对于逻辑回归,把权重初始化为 0 当然也是可以的,但是对于一个神经网络,如果把权重或者参数都初始化为 0,那么梯度下降将不会起作用。也就是说,我们把权重都初始化为 0,由于所有的隐含单元都是对称的,都会开始计算同一个函数,所以无论运行梯度下降多久,他们都一直计算同样的函数。
所以,我们需要进行随机初始化参数。具体做法为,把 \(W^{[1]}\) 设为 np.random.randn(4,4),这样生成了一个高斯分布的随机数矩阵,通常再乘上一个小的数,比如 0.01,这样把它初始化为很小的随机数。然后 \(b\) 没有这个对称的问题 (symmetry breaking problem),所以可以把 \(b\) 初始化为 0。类似地,\(W^{[2]}\) 和 \(b^{[2]}\) 也进行这样的初始化。
对于为什么要将参数初始化为比较小的随机数,原因是,如果我们使用 tanh 或者 sigmoid 激活函数,如果数值波动太大,\(z\) 就会很大或者很小,这种时候就很可能停在 tanh 或者 sigmoid 函数的平坦的地方,这些地方梯度很小,也就意味着梯度下降会很慢,学习也就很慢。
其实有时有比 0.01 更好的常数,当我们训练一个只有一层隐藏层的网络时,设为 0.01 可能可以。但是当训练一个非常非常深的神经网络,可能就需要试试 0.01 以外的常数了。
深层神经网络 (Deep Neural Networks)
神经网络的层数是这么定义的:从左到右,由 0 开始定义。如下图所示。
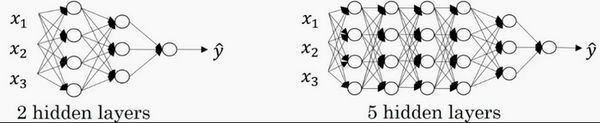
有一个隐藏层的神经网络,就是一个两层神经网络。当我们算神经网络的层数时,我们不算输入层,我们只算隐藏层和输出层。
前向传播和反向传播 (Forward and Backward Propagation)
前向传播
输入 \(a^{[l-1]}\),输出是 \(a^{[l]}\),缓存为 \(z^{[l]}\);从实践中来看,我们还可以缓存下 \(w^{[l]}\) 和 \(b^{[l]}\),这样更容易在不同的环节中调用函数。
那么,前向传播的步骤为
向量化的版本为
前向传播需要喂入 \({A}^{[0]}\) 也就是 \(X\),来初始化;初始化的是第一层的输入值。\({a}^{[0]}\) 对应于一个训练样本的输入特征,而 \({{A}^{[0]}}\) 对应于一整个训练样本的输入特征,所以这就是这条链的第一个前向函数的输入,重复这个步骤就可以从左到右计算前向传播。
反向传播
输入为 \({{da}^{[l]}}\),输出为 \({{da}^{[l-1]}},{{dw}^{[l]}}, {{db}^{[l]}}\)。
所以反向传播的步骤可以写成
向量化的版本为
核对矩阵的维数
当实现深度神经网络的时候,可以拿一张纸过一遍算法中矩阵的维数。
\(w\) 的维度是 (下一层的维数,前一层的维数),即 \(w^{[l]}:(n^{[l]},n^{[l-1]})\);
\(b\) 的维度是 (下一层的维数,1),即 \(b^{[l]}:(n^{[l]},1)\);
类似地,\(z^{[l]},a^{[l]}:(n^{[l]},1)\)。
\({{dw}^{[l]}}\) 和 \({{w}^{[l]}}\) 维度相同,\({{db}^{[l]}}\) 和 \({{b}^{[l]}}\) 维度相同,且 \(w\) 和\(b\) 向量化维度不变,但 \(z\), \(a\) 以及 \(x\) 的维度会向量化后发生变化。
向量化后:
\({Z}^{[l]}\) 可以看成由每一个单独的 \({z}^{[l]}\) 叠加而得到,\({Z}^{[l]}=({{z}^{[l][1]}},{{z}^{[l][2]}},{{z}^{[l][3]}},…,{{z}^{[l][m]}})\),
\(m\) 为训练集大小,所以 \({Z}^{[l]}\) 的维度不再是 \(({{n}^{[l]}},1)\),而是 \(({{n}^{[l]}},m)\)。
\({A}^{[l]}\):\(({n}^{[l]},m)\),\({A}^{[0]} = X =({n}^{[l]},m)\)
参数与超参数 (Parameters vs Hyperparameters)
什么是超参数?
比如算法中的learning rate \(\alpha\)(学习率)、iterations(梯度下降法循环的数量)、\(L\)(隐藏层数目)、\({{n}^{[l]}}\)(隐藏层单元数目)、choice of activation function(激活函数的选择)都需要你来设置,这些数字实际上控制了最后的参数 \(W\) 和 \(b\) 的值,所以它们被称作超参数。
如何寻找超参数的最优值?
走 Idea—Code—Experiment—Idea 这个循环,尝试各种不同的参数,实现模型并观察是否成功,然后再迭代。
References
[2] 深度学习 500 问

 浙公网安备 33010602011771号
浙公网安备 33010602011771号