Gateway路由网关详解
千里之行,始于足下
正文
一、Gateway路由网关:
Spring Cloud Gateway 是 Spring Cloud 生态中的 API 网关组件,专为微服务架构设计,基于响应式编程模型(Reactive Programming)构建,使用 Netty 作为运行时环境,提供动态路由、安全、监控、限流等核心功能。
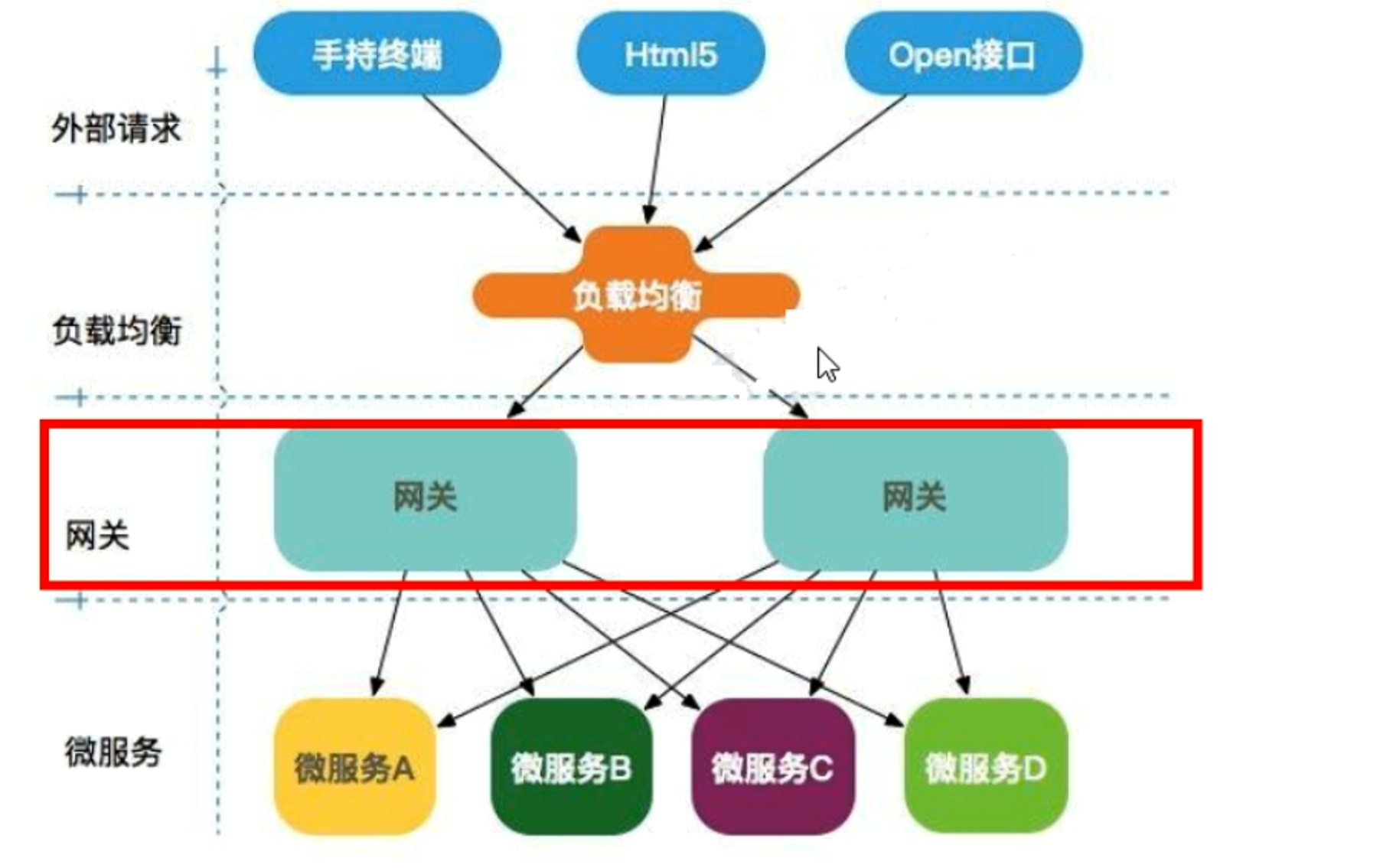
Spring Cloud Gateway的设计理念和存在意义围绕微服务架构的核心诉求展开,旨在解决分布式系统中 API 管理的复杂性,其核心目标可归纳为以下几点:
1、统一流量治理入口:
|
意义 |
微服务架构中服务数量激增,直接暴露所有服务端点存在安全风险和管理混乱问题 |
|
方案 |
作为统一入口,收敛所有内部服务的 API 暴露,对外提供标准化的访问路径,屏蔽内部服务细节(如服务名、实例地址) |
2、动态化与可编程性:
|
设计理念 |
|
支持通过配置(YAML/Java DSL)或代码动态定义路由规则、过滤器链,无需重启服务。 结合 Spring Cloud Config 或 Nacos 等配置中心,实现路由规则的实时更新,适应服务扩缩容、灰度发布等场景。 |
3、深度集成 Spring 生态:
|
意义 |
与 Spring Cloud 组件(如服务发现、熔断器、安全框架)无缝协作,降低技术栈复杂度 |
|
典型场景 |
自动从 Eureka/Nacos 获取服务实例列表,实现动态路由。 整合 Sentinel 实现熔断降级,或通过 Spring Security 集中鉴权。 |
4、非阻塞高性能架构:
|
设计理念 |
|
基于响应式编程模型(Reactive,使用 WebFlux 和 Reactor),采用非阻塞 I/O,避免传统同步阻塞网关(如 Zuul 1.x)的线程资源瓶颈。 适应高并发、低延迟场景(如物联网、实时通信),提升系统吞吐量。 |
5、灵活扩展与定制:
|
意义 |
通过过滤器链机制,允许开发者自定义逻辑(如限流算法、日志格式) |
|
扩展点 |
全局过滤器(Global Filter):适用于所有路由(如统一鉴权、日志记录)。 路由过滤器(Route Filter):针对特定路由的定制逻辑(如路径重写、请求头修改)。 |
6、云原生友好性:
|
设计目标 |
适配 Kubernetes、Service Mesh 等云原生环境 |
|
特性 |
轻量级部署,支持容器化。 与服务网格(如 Istio)互补,处理南北流量(网关)与东西流量(Sidecar)的分工协作。 |
二、Gateway核心概念:
1、Gateway三大核心:
|
Route(路由) |
路由是构建网关的基本模块,由ID,目标URI,一系列的断言和过滤器组成 |
|
Predicate(断言) |
开发人员可以匹配HTTP请求中的所有内容(例如请求头或请求参数),如果请求与断言相匹配则进行路由 |
|
Filter(过滤) |
使用过滤器,可以在请求被路由前或者之后对请求进行修改 |
2、Gateway工作原理:
Spring Cloud Gateway 作为微服务架构的 API 网关,其核心处理流程为:当客户端请求到达时,网关基于预设的路由规则(如路径、请求头等断言条件)匹配目标服务,随后通过过滤器(Filter)链对请求进行预处理(如鉴权、限流、路径重写),以非阻塞方式(底层基于 Netty 的非阻塞 I/O 模型处理连接,利用 Reactor 线程模型实现高并发)将请求转发至后端服务;待服务响应后,再经后置过滤器加工(如修改响应头、统一错误格式),最终将结果返回客户端,全程依托 Spring WebFlux 的响应式模型实现高性能和动态路由能力。
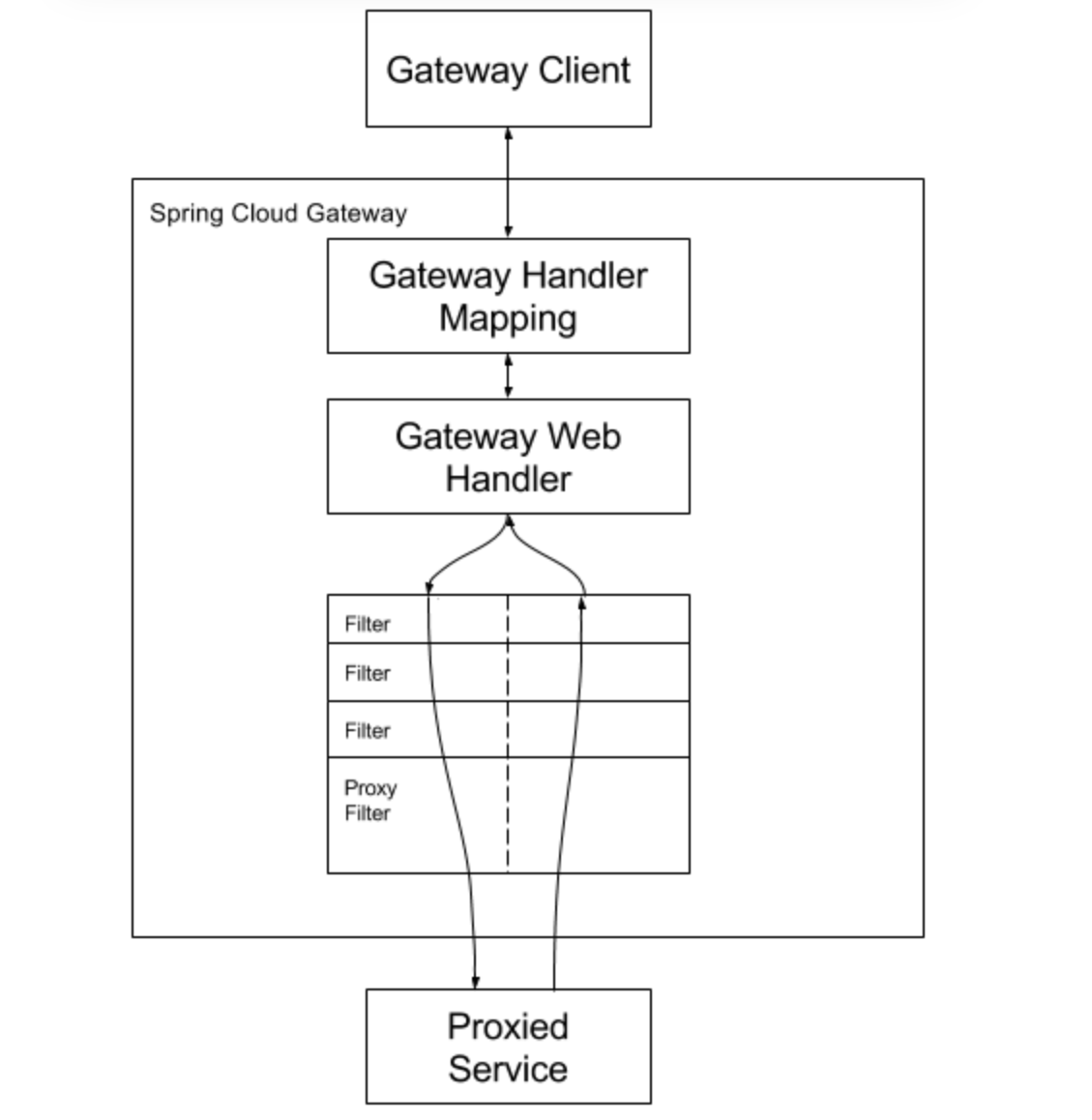
三、实战:
1、断言重写路由:
(1)、解耦客户端与后端服务,提升系统灵活性。
(2)、统一 API 入口,简化客户端调用逻辑。
(3)、动态适配后端服务路径,支持服务独立演进。
(4)、集成负载均衡和服务发现,提升系统可用性。
(5)、集中管理安全与流量控制,降低维护成本。
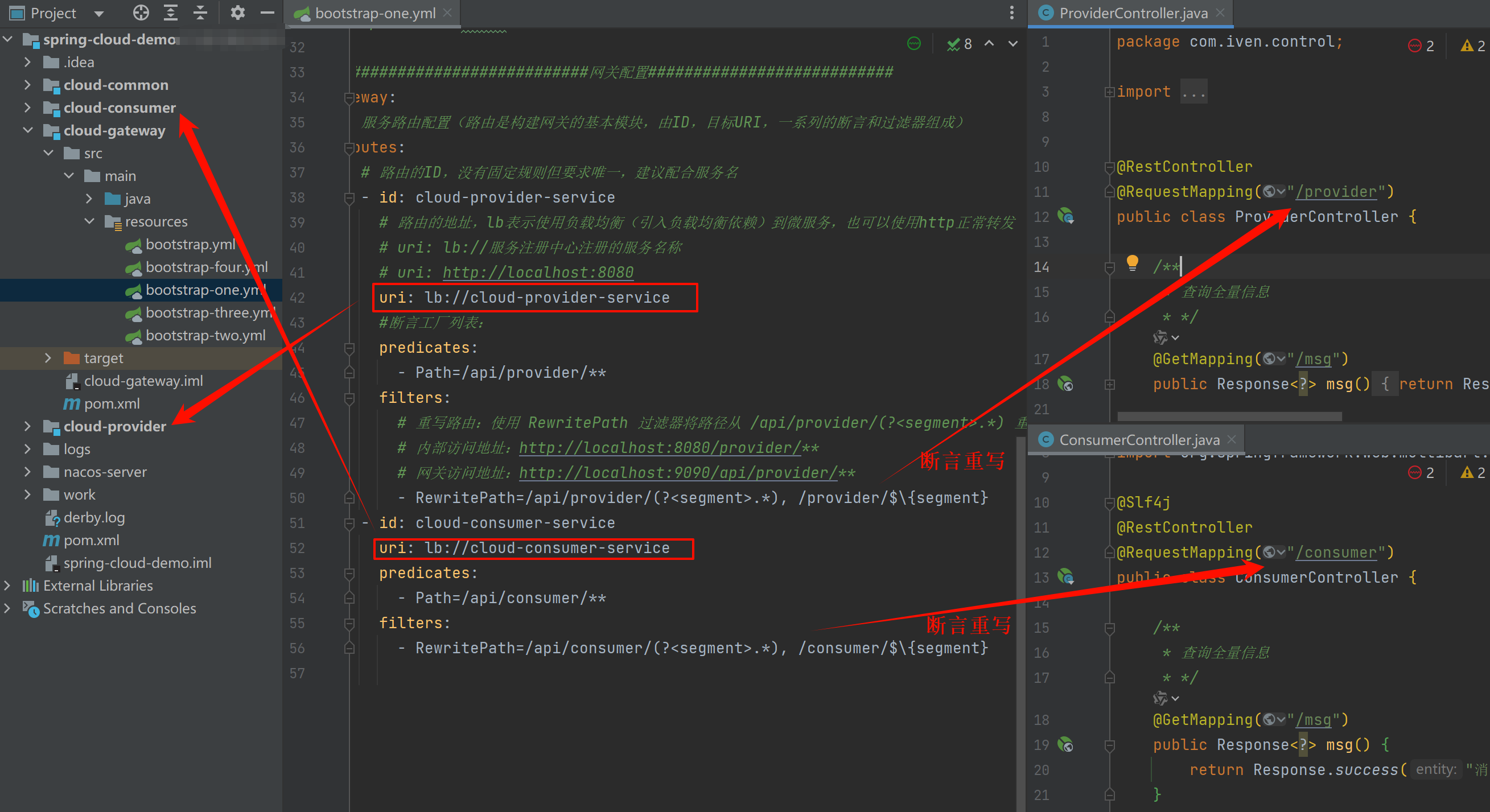
网关配置文件bootstrap-one.yml:

#断言重写路由配置 # 假设有一个走网关请求 URL 是 http://localhost:9090/api/provider/v1/resource,根据上述配置: # 1、匹配: # 请求路径 /api/provider/v1/resource 匹配 Path=/api/provider/** 断言。 # 2、重写路径: # 使用 RewritePath 过滤器将路径从 /api/provider/v1/resource 重写为 /provider/v1/resource。 # 3、转发: # 最终请求将被转发到 lb://cloud-provider-service/provider/v1/resource。 # 对外暴露端口 server: port: 9090 spring: #项目名 application: name: cloud-gateway-service cloud: nacos: config: server-addr: localhost:8848 file-extension: yaml # namespace: 3fd40f6b-0bc9-4a59-8838-0a64269125b4 # context-path: /nacos # username: nacos # password: nacos discovery: server-addr: localhost:8848 # namespace: 3fd40f6b-0bc9-4a59-8838-0a64269125b4 # username: nacos # password: nacos #############################网关配置########################### gateway: # 服务路由配置(路由是构建网关的基本模块,由ID,目标URI,一系列的断言和过滤器组成) routes: # 路由的ID,没有固定规则但要求唯一,建议配合服务名 - id: cloud-provider-service # 路由的地址,lb表示使用负载均衡(引入负载均衡依赖)到微服务,也可以使用http正常转发 # uri: lb://服务注册中心注册的服务名称 # uri: http://localhost:8080 uri: lb://cloud-provider-service #断言工厂列表: predicates: - Path=/api/provider/** filters: # 重写路由:使用 RewritePath 过滤器将路径从 /api/provider/(?<segment>.*) 重写为 /provider/$\{segment}。 # 内部访问地址:http://localhost:8080/provider/** # 网关访问地址:http://localhost:9090/api/provider/** - RewritePath=/api/provider/(?<segment>.*), /provider/$\{segment} - id: cloud-consumer-service uri: lb://cloud-consumer-service predicates: - Path=/api/consumer/** filters: - RewritePath=/api/consumer/(?<segment>.*), /consumer/$\{segment}
注:
使用lb做负载均衡需引入相关依赖
<!--负载均衡-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-loadbalancer</artifactId>
</dependency>
2、令牌桶算法限流过滤器:
在微服务架构中,网关作为所有请求的入口点,承担着路由、认证、安全等职责。随着业务规模的扩大和用户量的增长,请求流量会显著增加,这可能导致后端服务过载,影响系统的稳定性和响应时间。在网关层进行限流过滤器的部署,可以有效保护后端服务,提升用户体验,优化资源分配,并增强系统的整体稳定性。通过这种方式,可以更好地应对高并发场景,确保系统的可靠性和性能。
(1)、网关层限流过滤器的优点:
1)、控制请求速率:平滑地控制请求发送速率,防止瞬时高流量冲击系统。
2)、保障稳定性:避免后端服务过载,确保系统的稳定性和可用性。
3)、公平分配资源:合理分配系统资源,确保每个服务都能获得公平的服务响应时间。
4)、支持突发流量:允许一定程度的突发流量,同时保持长期稳定的请求处理能力。
5)、灵活配置:可以根据业务需求动态调整限流策略,适应不同的应用场景。
(2)、Gateway-RequestRateLimiter限流的实现原理:
Spring Cloud Gateway 的 RequestRateLimiter 基于令牌桶算法实现分布式限流,其原理是:通过 redis-rate-limiter 集成 Redis,系统以固定速率(replenishRate,如每秒 5 个令牌)向令牌桶填充令牌,桶容量上限为 burstCapacity(如 10 个令牌),允许突发流量短时消耗积累的令牌;当每个请求到达时,网关通过 Redis 原子化操作(Lua 脚本)检查当前请求的限流键(由 key-resolver 定义,如按 IP 生成唯一键)尝试从桶中获取令牌,若桶中存在可用令牌则放行并扣除令牌,否则触发限流(返回 HTTP 429),借助 Redis 的分布式存储和原子性特性,确保多网关实例间的限流状态严格一致,实现高并发场景下精准、灵活的流量控制。
(3)、令牌桶算法与漏桶算法:
|
对比维度 |
令牌桶算法 |
漏桶算法 |
|
核心思想 |
以固定速率生成令牌,请求需获取令牌才能通过。 |
以恒定速率处理请求,超出速率的请求排队或丢弃。 |
|
流量特性 |
允许突发流量(桶内令牌可累积)。 |
强制平滑流量(恒定速率输出,无法应对突发)。 |
|
实现复杂度 |
简单(仅需管理令牌生成和消耗)。 |
较高(需维护请求队列和漏出速率)。 |
|
适用场景 |
需要容忍突发流量的场景(如秒杀、API 突发调用)。 |
需严格限制请求速率的场景(如音视频流控)。 |
|
资源利用率 |
高(突发期可快速消费累积令牌)。 |
低(严格限速可能导致带宽浪费)。 |
|
典型工具 |
Spring Cloud Gateway、 Google Guava RateLimiter |
Nginx 限流模块、 pache 的 mod_ratelimit |
(4)、相关实现:
1)、POM依赖:
|
特性 |
spring-boot-starter-data-redis-reactive |
spring-boot-starter-data-redis |
|
编程模型 |
响应式(Reactive) |
同步(Blocking) |
|
客户端 |
Lettuce(强制) |
Lettuce/Jedis(可选) |
|
适用场景 |
高并发、非阻塞 I/O |
常规同步操作 |
<!-- Redis Reactive 依赖 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis-reactive</artifactId>
</dependency>
2)、YML配置文件:bootstrap-two.yml
集成Redis配置令牌桶限流机制:
指定令牌填充速度replenishRate、令牌桶容量burstCapacity、限流策略KeyResolver
#令牌桶算法限流过滤器 # 令牌桶的基本逻辑是: # 每个IP对应一个桶,桶里有令牌,每秒补充一定的令牌数,最多不超过桶的容量。当请求到来时,如果桶里有足够的令牌,则允许通过并消耗一个令牌,否则拒绝。 # 对外暴露端口 server: port: 9090 spring: #项目名 application: name: cloud-gateway-service cloud: nacos: config: server-addr: localhost:8848 file-extension: yaml # namespace: 3fd40f6b-0bc9-4a59-8838-0a64269125b4 # context-path: /nacos # username: nacos # password: nacos discovery: server-addr: localhost:8848 # namespace: 3fd40f6b-0bc9-4a59-8838-0a64269125b4 # username: nacos # password: nacos #############################网关配置########################### gateway: # 服务路由配置(路由是构建网关的基本模块,由ID,目标URI,一系列的断言和过滤器组成) routes: # 路由的ID,没有固定规则但要求唯一,建议配合服务名 - id: cloud-provider-service # 路由的地址,lb表示使用负载均衡(引入负载均衡依赖)到微服务,也可以使用http正常转发 # uri: lb://服务注册中心注册的服务名称 # uri: http://localhost:8080 uri: lb://cloud-provider-service #断言工厂列表: predicates: - Path=/provider/** filters: # 限流过滤器 - name: RequestRateLimiter args: # 填充速率,每秒允许通过请求数 redis-rate-limiter.replenishRate: 5 # 令牌桶容量,系统允许的突发请求量,即短时间内可以处理的最大请求数 redis-rate-limiter.burstCapacity: 10 # bean,配置限流策略 key-resolver: '#{@ipKeyResolver}' - id: cloud-consumer-service uri: lb://cloud-consumer-service predicates: - Path=/consumer/** filters: - name: RequestRateLimiter args: redis-rate-limiter.replenishRate: 5 redis-rate-limiter.burstCapacity: 10 key-resolver: '#{@ipKeyResolver}' # redis 配置 redis: host: localhost # 单机模式-host port: 6379 # 单机模式-端口 timeout: 3000 # 连接超时时间(毫秒) lettuce: # lettuce连接池 pool: max-active: 8 # 连接池最大连接数(使用负值表示没有限制) max-wait: -1 # 连接池最大阻塞等待时间(使用负值表示没有限制) max-idle: 8 # 连接池中的最大空闲连接 min-idle: 0 # 连接池中的最小空闲连接
3)、限流策略key-resolver配置:
import org.springframework.cloud.gateway.filter.ratelimit.KeyResolver; import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; import org.springframework.context.annotation.Primary; import reactor.core.publisher.Mono; import java.util.Objects; @Configuration public class RateLimitConfig { /** * 根据ip限流策略 * @return 限流策略 * */ @Bean @Primary // 设置默认解析器(多个KeyResolver策略需指定) public KeyResolver ipKeyResolver() { return exchange -> // 获取请求的远程地址(即客户端IP地址),并确保不为null Mono.just(Objects.requireNonNull(exchange.getRequest() // 获取远程地址(InetSocketAddress) .getRemoteAddress()) // 获取InetSocketAddress中的InetAddress对象 .getAddress() // 获取客户端的IP地址(以字符串形式返回) .getHostAddress()); } /** * 根据uri路径限流策略 * @return 限流策略 */ @Bean() public KeyResolver uriKeyResolver() { return exchange -> Mono.just(exchange.getRequest().getURI().getPath()); } }
4)、自定义过滤器进行IP限流处理:
声明Cache进行IP黑名单缓存:
import com.google.common.cache.Cache; import com.google.common.cache.CacheBuilder; import java.util.concurrent.TimeUnit; /** * IP 黑名单缓存 * * Guava CacheBuilder: * 一、核心优点 * 1、高性能本地访问:微秒级响应,适用于高频读取场景(如网关 IP 校验) * 2、灵活过期策略:支持写入后/访问后双维度自动过期 * 3、自动内存管理:基于 LRU 的容量限制(maximumSize)防止 OOM * 4、细粒度并发控制:通过 concurrencyLevel 优化锁竞争 * 5、内置监控统计:通过 cache.stats() 获取命中率、淘汰次数等指标 * 二、主要不足 * 1、单机局限性:集群环境下数据不一致,需额外同步机制 * 2、内存容量受限:大流量场景易触发频繁淘汰或 GC 压力 * 3、无持久化能力:服务重启后数据丢失,需冷启动预热 * 4、缓存穿透风险:未命中时可能穿透到后端系统 */ public class IpBlackCache { public static final Cache<String, Boolean> IP_CACHE = CacheBuilder.newBuilder() // 最大cache数量 100条 .maximumSize(100) // 写入后300s过期 .expireAfterWrite(300, TimeUnit.SECONDS) // 不访问 60s过期 .expireAfterAccess(60, TimeUnit.SECONDS) // 最多8个同时更新缓存的并发, 默认4 .concurrencyLevel(8) // 开启cache统计 .recordStats() .build(); }
自定义过滤器进行IP限流处理:
import com.alibaba.fastjson.JSONObject; import com.iven.utils.IpBlackCache; import lombok.extern.slf4j.Slf4j; import org.springframework.cloud.gateway.filter.GatewayFilterChain; import org.springframework.cloud.gateway.filter.GlobalFilter; import org.springframework.core.Ordered; import org.springframework.http.HttpStatus; import org.springframework.http.server.reactive.ServerHttpResponse; import org.springframework.stereotype.Component; import org.springframework.web.server.ServerWebExchange; import reactor.core.publisher.Flux; import reactor.core.publisher.Mono; import java.util.HashMap; import java.util.Map; @Slf4j @Component public class GatewayIpRateLimiterFilter implements GlobalFilter, Ordered { /** * 过滤函数,用于处理每个请求 * @param exchange 服务器web交换对象,包含请求和响应 * @param chain 网关过滤链,用于执行下一个过滤器 * @return Mono<Void> 表示异步处理完成 */ @Override public Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) { ServerHttpResponse httpResponse = exchange.getResponse(); String ip = exchange.getRequest().getRemoteAddress().getAddress().getHostAddress(); // 检查黑名单 Boolean ipCache = IpBlackCache.IP_CACHE.getIfPresent(ip); if (ipCache != null && ipCache) { //修改code为429,太多请求 httpResponse.setStatusCode(HttpStatus.TOO_MANY_REQUESTS); if (!httpResponse.getHeaders().containsKey("Content-Type")) { httpResponse.getHeaders().add("Content-Type", "application/json"); } Map<String, String> errorInfo = new HashMap<>(); errorInfo.put("code", HttpStatus.TOO_MANY_REQUESTS.toString()); errorInfo.put("msg", "访问太频繁"); String httpBody = JSONObject.toJSONString(errorInfo); log.info("该ip:{}已被拉入黑名单,错误信息{}", ip, httpBody); return httpResponse.writeWith(Flux.just(exchange.getResponse().bufferFactory().wrap(httpBody.getBytes()))); } // 采用默认令牌桶算法,如果触发限流,返回HTTP响应状态码429 // 若需替换默认算法(如改用漏桶算法),实现RateLimiter接口,重写isAllowed方法 return chain.filter(exchange).then(Mono.fromRunnable(() -> { // 检查限流结果,将IP放入黑名单缓存中 if (httpResponse.getStatusCode() == HttpStatus.TOO_MANY_REQUESTS) { IpBlackCache.IP_CACHE.put(ip, true); } })); } /** * 获取拦截器顺序,使用最高级别,第一拦截 */ @Override public int getOrder() { return Ordered.HIGHEST_PRECEDENCE; } }
扩展:自定义的Redis令牌桶限流
@Component public class XxxRedisRateLimiter extends RedisRateLimiter { public Mono<Response> isAllowed(xxx) { xxx } }

3、重试过滤器:
|
一、重试过滤器的优点: |
|
1、容错性提升:自动处理瞬时故障(如网络抖动、服务短时不可用)。 2、可用性增强:降低单次调用失败对核心流程的影响。 3、运维成本降低:减少人工介入,实现自动化恢复。 4、用户体验优化:通过后台重试避免用户感知到频繁失败。 |
|
二、重试机制的核心价值: |
|
1、应对分布式系统的不可靠性:网络和服务依赖的故障是常态,需容错机制保障稳定性。 2、解决瞬时故障的普遍性:服务重启、资源竞争等短暂问题可通过重试快速恢复。 3、缓解依赖服务的波动性:第三方服务或云基础设施可能存在不稳定性,重试提供缓冲。 4、强化系统鲁棒性:在部分故障下维持核心功能,避免整体崩溃。 |
|
三、典型使用场景: |
|
1、HTTP/API调用:处理5xx服务端错误或网络超时。 2、数据库操作:应对连接超时、死锁等临时异常。 3、消息队列消费:消息处理失败后重试,确保最终一致性。 4、文件/资源访问:临时IO错误或资源锁冲突的场景。 |
|
四、注意事项: |
|
1、避免无限重试:设定最大重试次数,防止雪崩效应。 2、区分错误类型:仅对可恢复错误(如5xx、超时)重试,非重试错误(如4xx)直接失败。 3、退避策略:采用递增延迟(如指数退避),缓解下游服务压力。 4、监控与告警:记录重试日志,及时发现异常高频重试模式。 |
(1)、网关配置文件bootstrap-three.yml:
#重试过滤器 # 设置重试次数:最多重试3次。 # 状态码系列:当响应的状态码属于SERVER_ERROR系列(即5xx状态码)时,会触发重试。 # 指定状态码:当响应的状态码为SERVICE_UNAVAILABLE(通常是503状态码)时,也会触发重试 # 对外暴露端口 server: port: 9090 spring: #项目名 application: name: cloud-gateway-service cloud: nacos: config: server-addr: localhost:8848 file-extension: yaml # namespace: 3fd40f6b-0bc9-4a59-8838-0a64269125b4 # context-path: /nacos # username: nacos # password: nacos discovery: server-addr: localhost:8848 # namespace: 3fd40f6b-0bc9-4a59-8838-0a64269125b4 # username: nacos # password: nacos #############################网关配置########################### gateway: # 服务路由配置(路由是构建网关的基本模块,由ID,目标URI,一系列的断言和过滤器组成) routes: # 路由的ID,没有固定规则但要求唯一,建议配合服务名 - id: cloud-provider-service # 路由的地址,lb表示使用负载均衡(引入负载均衡依赖)到微服务,也可以使用http正常转发 # uri: lb://服务注册中心注册的服务名称 # uri: http://localhost:8080 uri: lb://cloud-provider-service #断言工厂列表: predicates: - Path=/provider/** filters: # 重试过滤器 - name: Retry args: # 重试次数 retries: 3 # 哪些段的状态码需要重试, 默认5xx series: - SERVER_ERROR # 指定哪些状态需要重试 statuses: SERVICE_UNAVAILABLE - id: cloud-consumer-service uri: lb://cloud-consumer-service predicates: - Path=/consumer/** filters: - name: Retry args: retries: 3 series: - SERVER_ERROR statuses: SERVICE_UNAVAILABLE
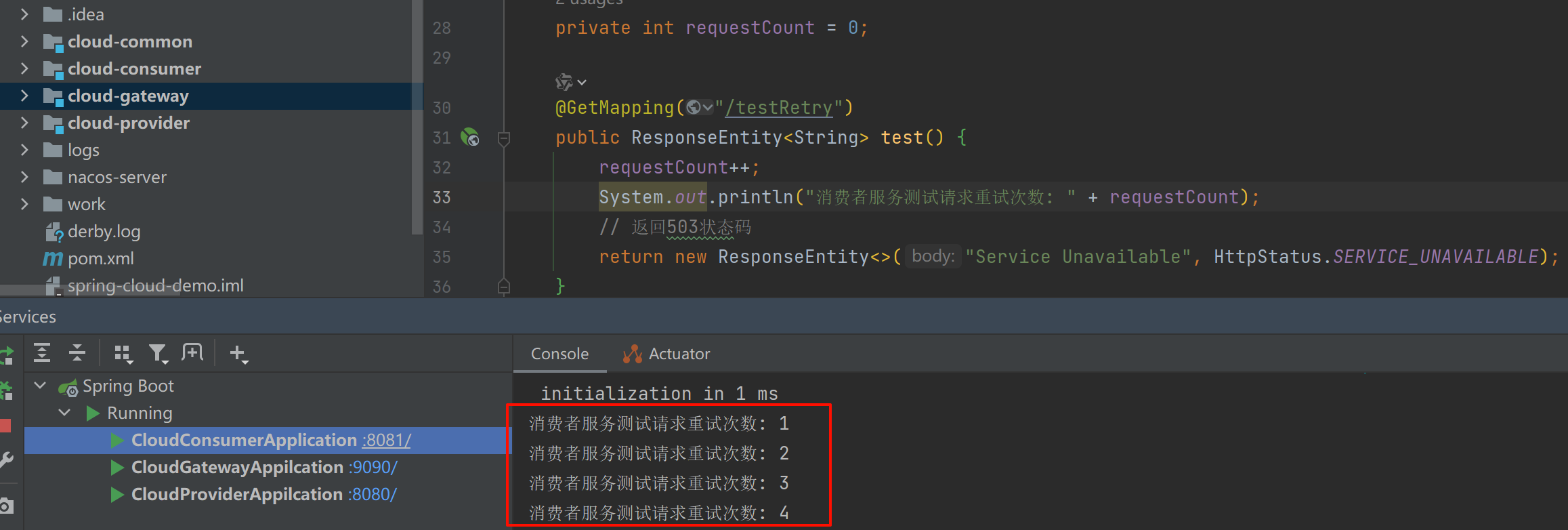
(2)、相关测试接口:
/** * 重试过滤器测试 * */ private int requestCount = 0; @GetMapping("/testRetry") public ResponseEntity<String> test() { requestCount++; System.out.println("生产者服务测试请求重试次数: " + requestCount); // 返回503状态码 return new ResponseEntity<>("Service Unavailable", HttpStatus.SERVICE_UNAVAILABLE); }
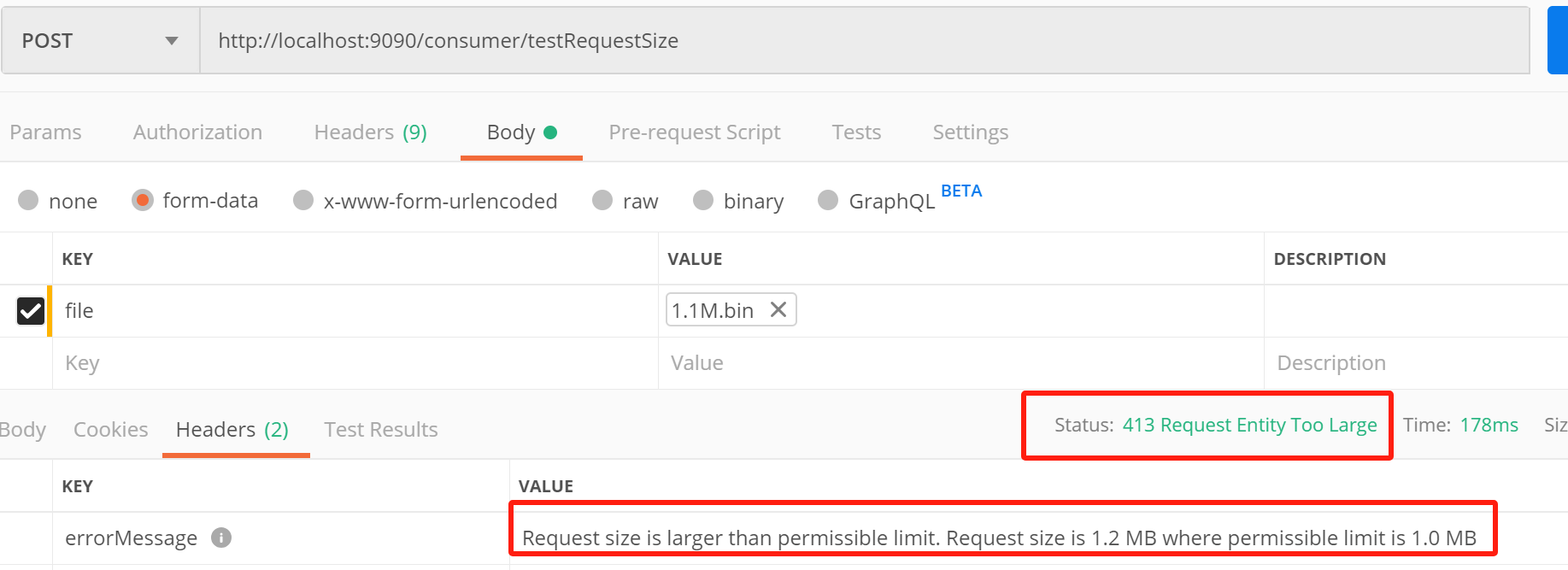
4、请求大小限制过滤器:
当客户端请求体大小超过 maxSize 设定值时,网关会直接拦截请求,返回 HTTP 413 (Payload Too Large) 状态码
(1)、保障系统稳定性:拦截超大请求,防止内存溢出和服务崩溃
(2)、强化安全防护:阻断DDoS攻击,避免恶意大流量冲击后端
(3)、优化网络性能:降低无效带宽消耗,提升整体吞吐量
(4)、统一流量治理:标准化异常响应格式,简化客户端错误处理逻辑
(1)、网关配置文件bootstrap-four.yml:
#请求大小限制过滤器 # 当客户端请求体大小超过 maxSize 设定值时,网关会直接拦截请求,返回 HTTP 413 (Payload Too Large) 状态码。 # 单位换算 maxSize 以字节为单位,计算方式: 1MB = 1024 * 1024 = 1,048,576 bytes # Windows系统文件生成(PowerShell)0.9M文件:fsutil file createnew 0.9M.bin 900000 # Windows系统文件生成(PowerShell)1.1M文件:fsutil file createnew 1.1M.bin 1100000 # 对外暴露端口 server: port: 9090 spring: #项目名 application: name: cloud-gateway-service cloud: nacos: config: server-addr: localhost:8848 file-extension: yaml # namespace: 3fd40f6b-0bc9-4a59-8838-0a64269125b4 # context-path: /nacos # username: nacos # password: nacos discovery: server-addr: localhost:8848 # namespace: 3fd40f6b-0bc9-4a59-8838-0a64269125b4 # username: nacos # password: nacos #############################网关配置########################### gateway: # 服务路由配置(路由是构建网关的基本模块,由ID,目标URI,一系列的断言和过滤器组成) routes: # 路由的ID,没有固定规则但要求唯一,建议配合服务名 - id: cloud-provider-service # 路由的地址,lb表示使用负载均衡(引入负载均衡依赖)到微服务,也可以使用http正常转发 # uri: lb://服务注册中心注册的服务名称 # uri: http://localhost:8080 uri: lb://cloud-provider-service #断言工厂列表: predicates: - Path=/provider/** filters: # 请求大小限制过滤器 - name: RequestSize args: # 单位字节:限制1M maxSize: 1000000 - id: cloud-consumer-service uri: lb://cloud-consumer-service predicates: - Path=/consumer/** filters: - name: RequestSize args: maxSize: 1000000
(2)、相关测试接口:
/** * 请求大小限制过滤器测试 * */ @PostMapping("/testRequestSize") public ResponseEntity<String> handleFileUpload(@RequestParam("file") MultipartFile file) { // 网关会先拦截大文件请求,此处只需要处理通过网关的合法请求 return ResponseEntity.ok().body(String.format("文件上传成功!文件名:%s,大小:%d 字节", file.getOriginalFilename(), file.getSize())); }



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· winform 绘制太阳,地球,月球 运作规律
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人