Spring Cloud Alibaba学习笔记
一、Spring Cloud Alibaba相关介绍:
1、简介:
(1)、SpringCloud Netflix项目进入了维护模式。意味着SpringCloud Netflix 将不再开发新的组件。维护中的组件将通过平行组件所替代。
(2)、Spring Cloud Alibaba 致力于提供微服务开发的一站式解决方案。此项目包含开发分布式应用微服务的必需组件,方便开发者通过 Spring Cloud 编程模型轻松使用这些组件来开发分布式应用服务。使用Spring Cloud Alibaba,只需要添加一些注解和少量配置,就可以将Spring Cloud应用接入阿里微服务解决方案,通过阿里中间件来迅速搭建分布式应用系统。
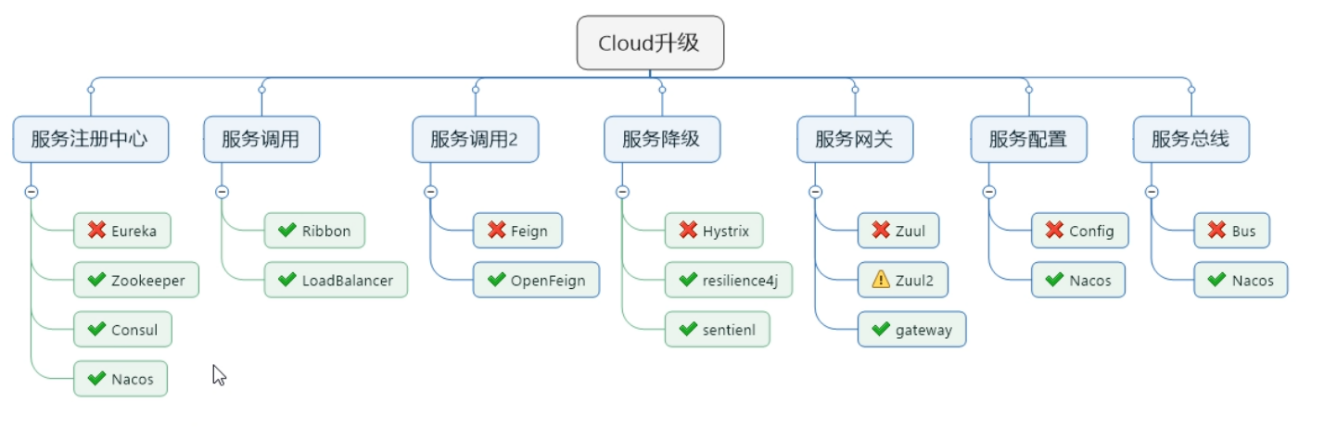
|
组件 |
技术 |
|
服务注册中心 |
× Eureka(已停更) √ Zookeeper √ Consul √ Nacos(推荐)
|
|
服务调用 |
√ Ribbon √ LoadBalancer
|
|
服务调用2 |
× Feign(已停更) √ OpenFeign
|
|
服务降级 |
× Hystrix(已停更) √ resilience4j √ sentienl
|
|
服务网关 |
× Zuul(已停更) ! Zuul2 √ gateway
|
|
服务配置 |
× Config(已停更) √ Nacos
|
|
服务总线 |
× Bus(已停更) √ Nacos
|
2、特点:
(1)、Flow control and service degradation(流量控制和服务降级):默认支持Servlet、RestTemplate、Dubbo和RocketMQ限流降级功能的介入,可以在运行时通过控制台修改限流降级规则,还支持查看限流降级的Metrics监控。
(2)、Service registeration and discovery(服务注册与发现):适配SpringCloud服务注册与发现标准,默认集成了 Ribbon 的支持。
(3)、Distributed configuration(分布式配置管理):支持分布式系统中的外部化配置,配置更改时自动刷新。
(4)、RPC Service(RPC 服务):远程调用服务。
(5)、Event-driven(消息驱动):基于SpringCloud Stream为微服务应用构建消息驱动能力。
(6)、Alibaba Cloud Object Storage(阿里云对象存储):阿里云提供的海量、安全、低成本、高可靠的云存储服务。支持在任何应用、任何时间、任何地点存储和访问任意类型的数据。
(7)、Alibaba Cloud SchedulerX(阿里云调度器):提供秒级、精准、高可靠、高可用的定时(基于 Cron 表达式)任务调度服务。同时提供分布式的任务执行模型,如:网格任务,网格任务支持海量子任务均匀分布到所有的 Woker(schedulerx-client)上执行。
(8)、Alibaba Cloud SMS(阿里云短信):提供阿里云短信服务支持。
二、Nacos服务注册与配置中心:
Nacos是一个更易于构建云原生应用的动态服务发现、配置管理和服务管理平台。即是注册中心与配置中心的组合。
1、Nacos单机模式:
(1)、下载地址:
Nacos服务器是独立安装部署的,因此需要下载相应的Nacos服务端程序:下载地址
(2)、解压启动:
IDEA-Terminal控制台启动与关闭:
#打开nacos的bin目录 cd \nacos\bin\ # nacos独立模式启动 .\startup.cmd -m standalone #nacos关闭 .\shutdown.cmd:
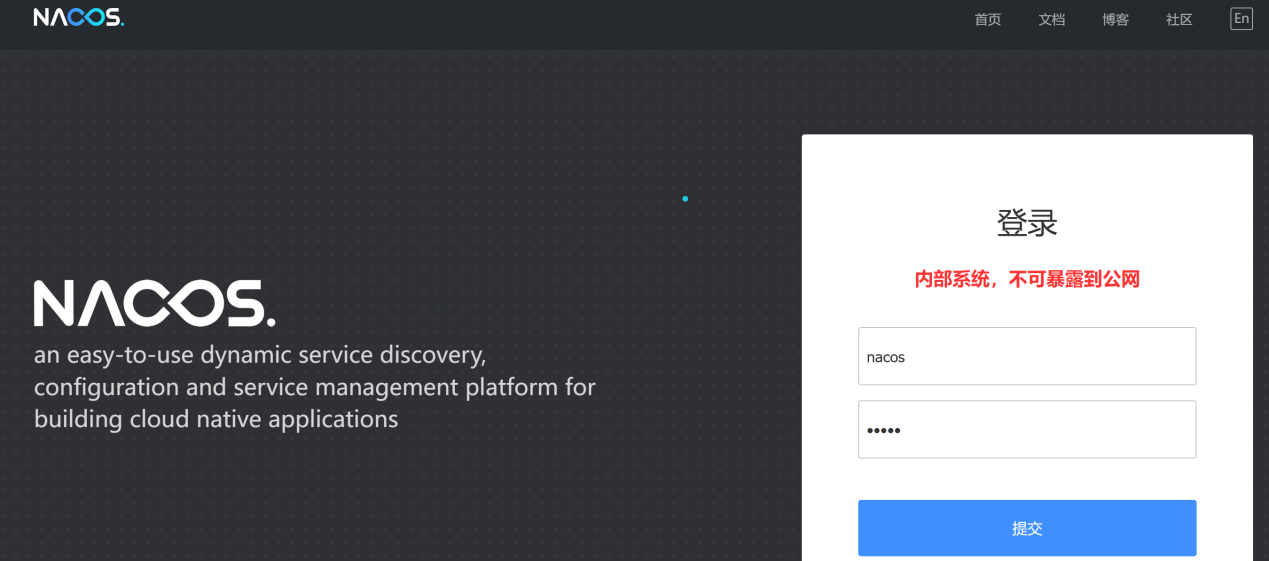
(3)、访问注册中心:
地址:http://localhost:8848/nacos/index.html,默认的用户名和管理员密码都是nacos
(4)、可采用配置方式启动:
-m standalone
注:
在单节点的情况下,Nacos将数据存放在自带的一个嵌入式数据库中
2、Nacos服务注册与发现:
父工程POM对SpringCloudAlibaba依赖进行统一管理:
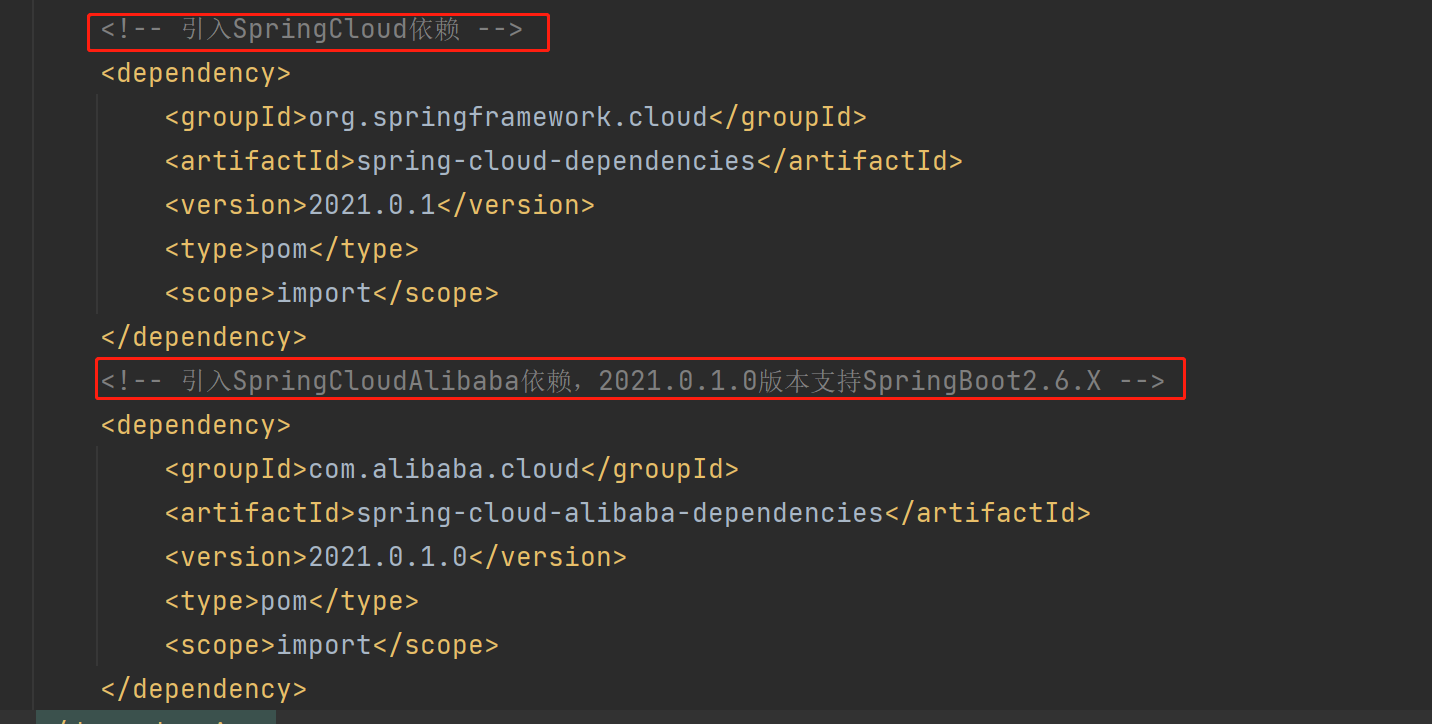
<!-- 引入SpringCloud依赖 -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>2021.0.1</version>
<type>pom</type>
<scope>import</scope>
</dependency>
<!-- 引入SpringCloudAlibaba依赖,2021.0.1.0版本支持SpringBoot2.6.X -->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-alibaba-dependencies</artifactId>
<version>2021.0.1.0</version>
<type>pom</type>
<scope>import</scope>
</dependency>
相关微服务注册到nacos注册中心,添加依赖:

<!--nacos服务发现依赖-->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId>
</dependency>
YML配置:
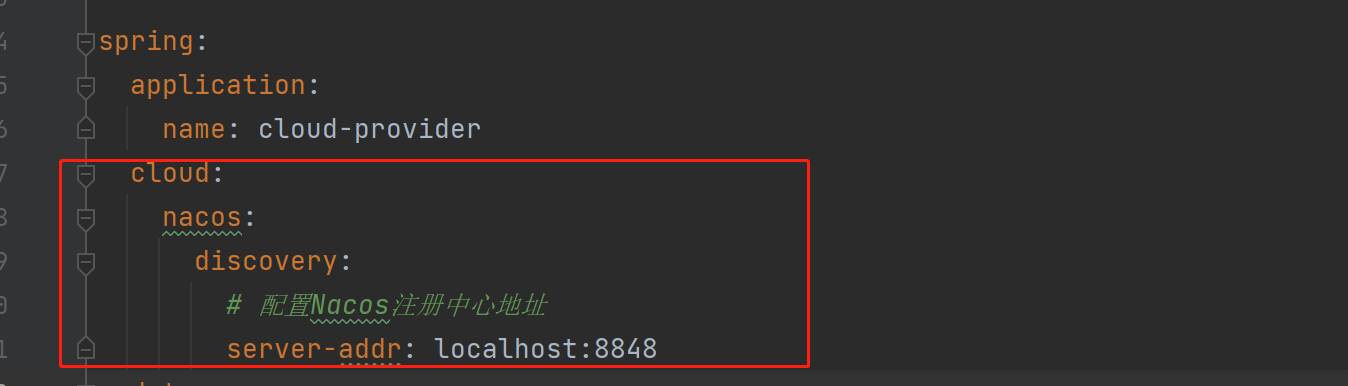
服务发现:
注:
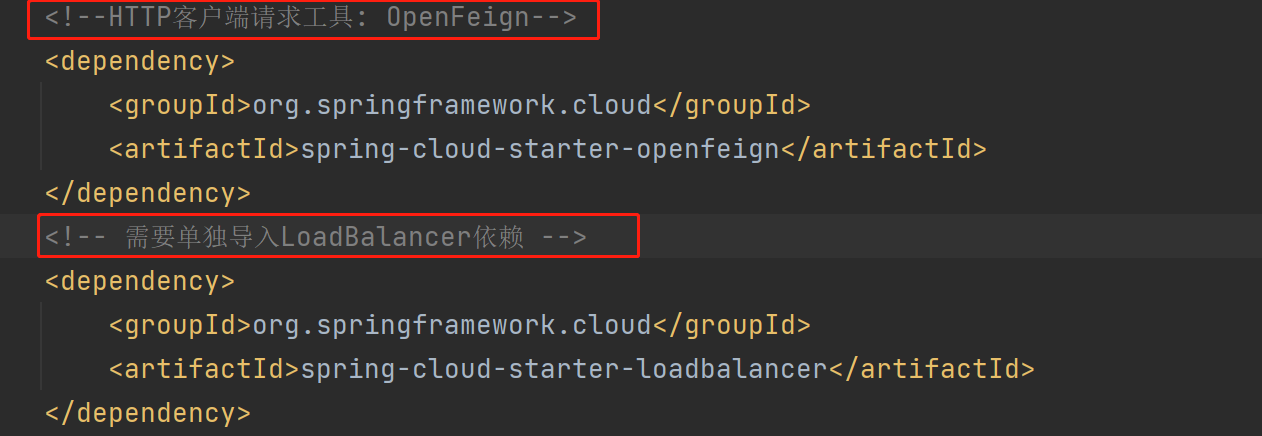
OpenFeign实现服务远程调用与负载均衡需导入相关依赖:
3、Nacos临时与非临时实例:
(1)、概述:
Nacos是一个服务发现和配置管理平台,它支持两种类型的实例:临时实例和非临时实例。
- 1)、临时实例:
临时实例是指在Nacos注册的服务实例,它们的生命周期与服务提供者的生命周期相同。采用心跳机制向Nacos发送请求保持在线状态,一旦心跳停止,即服务提供者关闭或崩溃时,临时实例将自动注销。临时实例适用于短期任务或临时服务。
- 2)、非临时实例:
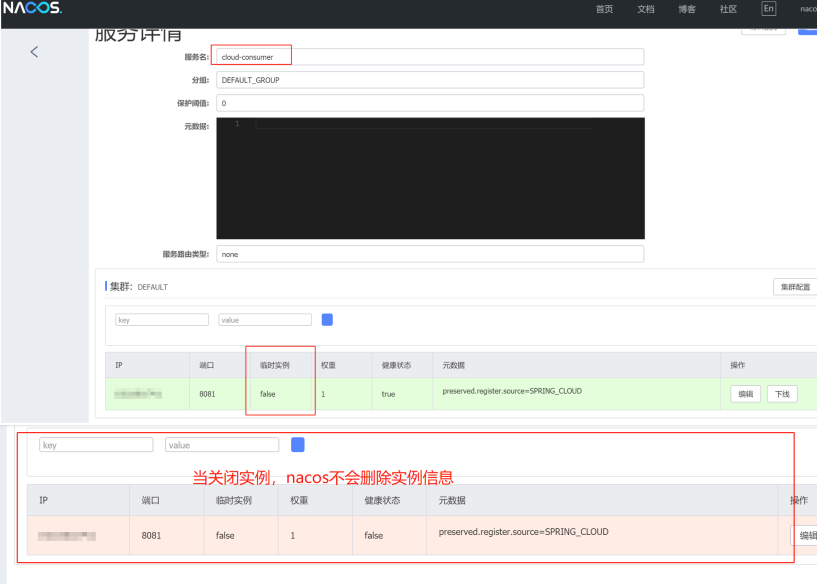
非临时实例是指在Nacos注册的服务实例,它们的生命周期不受服务提供者的影响,由Nacos主动进行联系,如果连接失败,那么不会移除实例信息,而是将健康状态设定为false,相当于会对某个实例状态持续地进行监控。非临时实例适用于长期任务或持久服务。
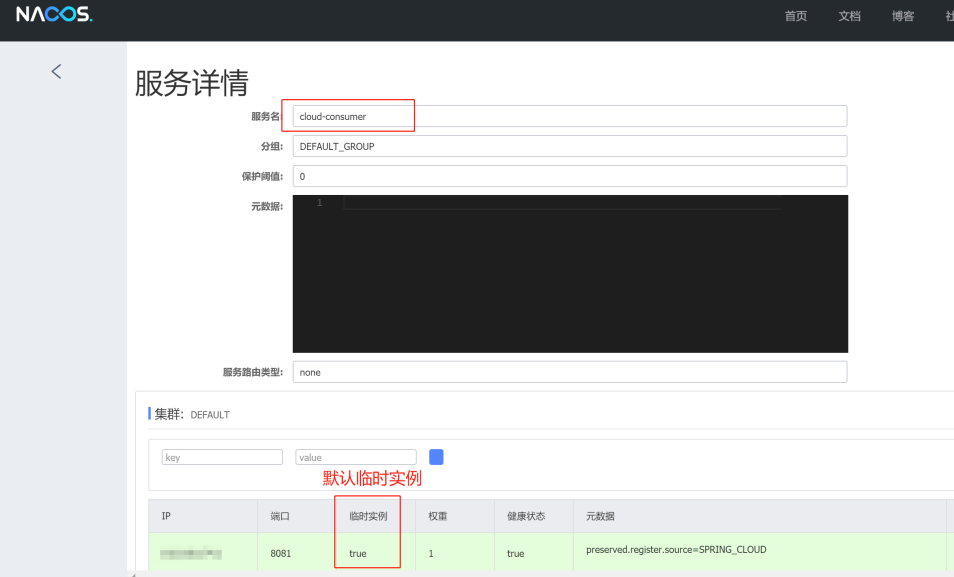
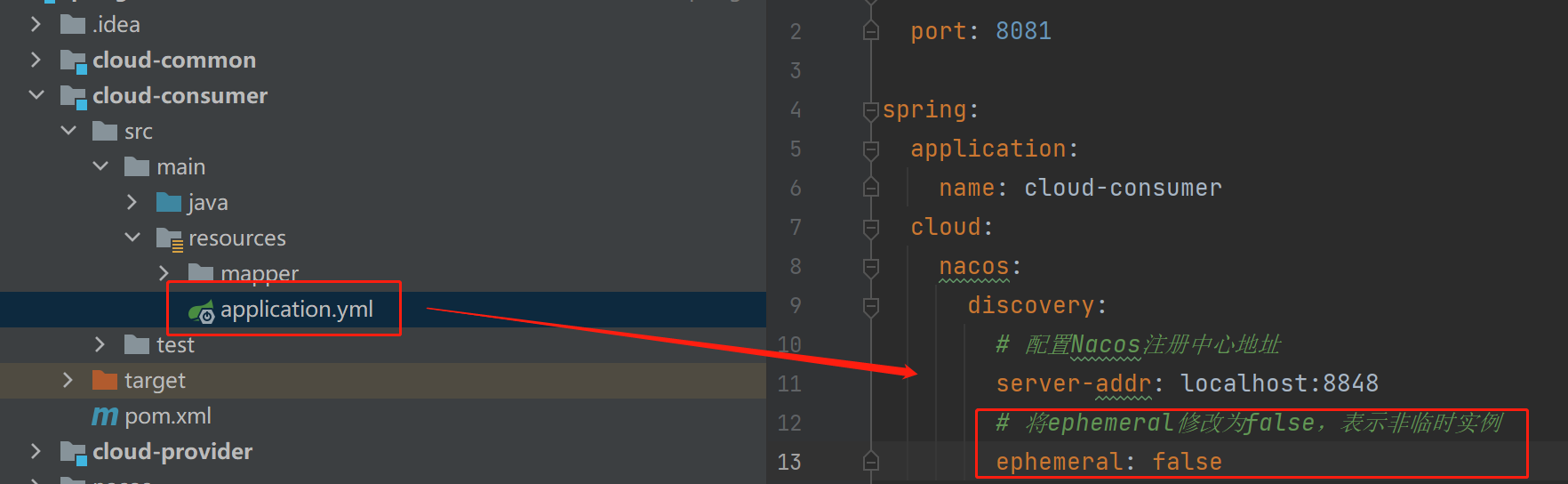
(2)、非临时实例配置:
配置声明:
4、Nacos服务配置中心:
SpringCloud Config可以通过配置服务来加载远程配置,实现在远端对配置文件的集中管理,利用bootstrap.yml中的配置获取远程配置文件,再进入到配置文件加载环节,而Nacos同样支持这样的操作。
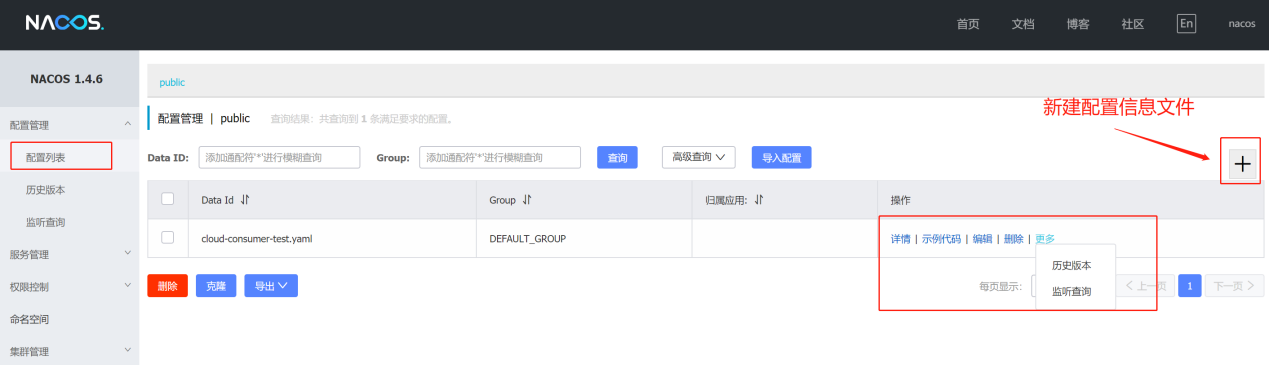
(1)、发布配置信息文件:
命名规则:服务名称-环境.yaml
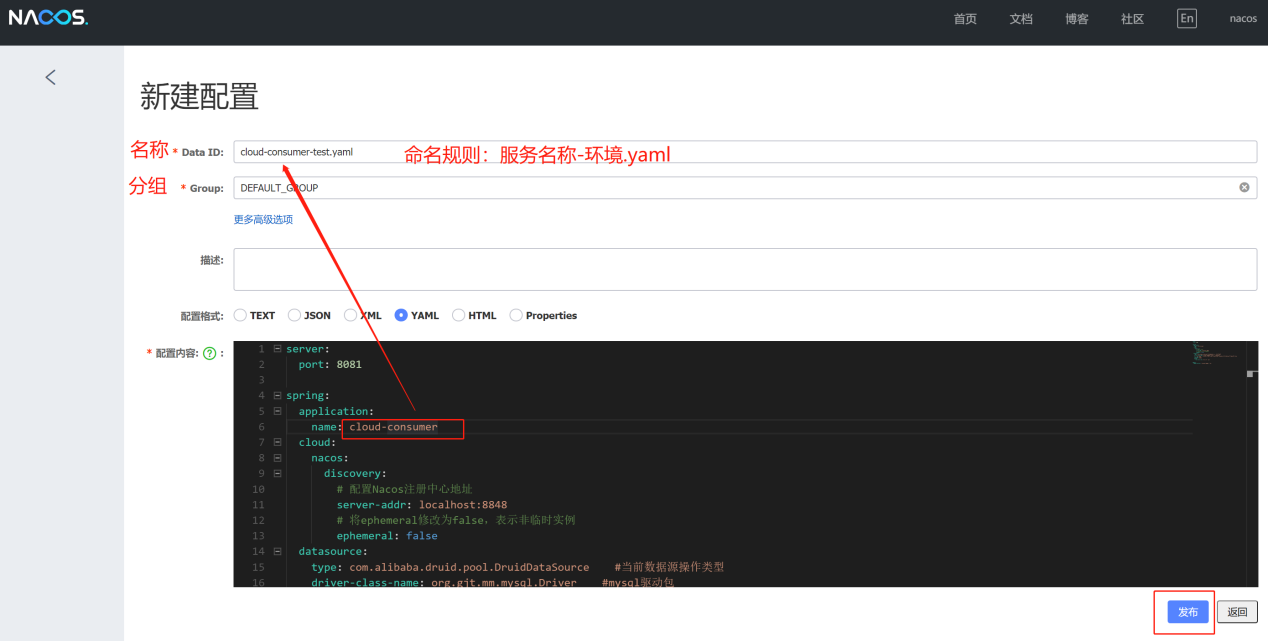
(2)、客户端获取配置信息:
添加相关依赖:
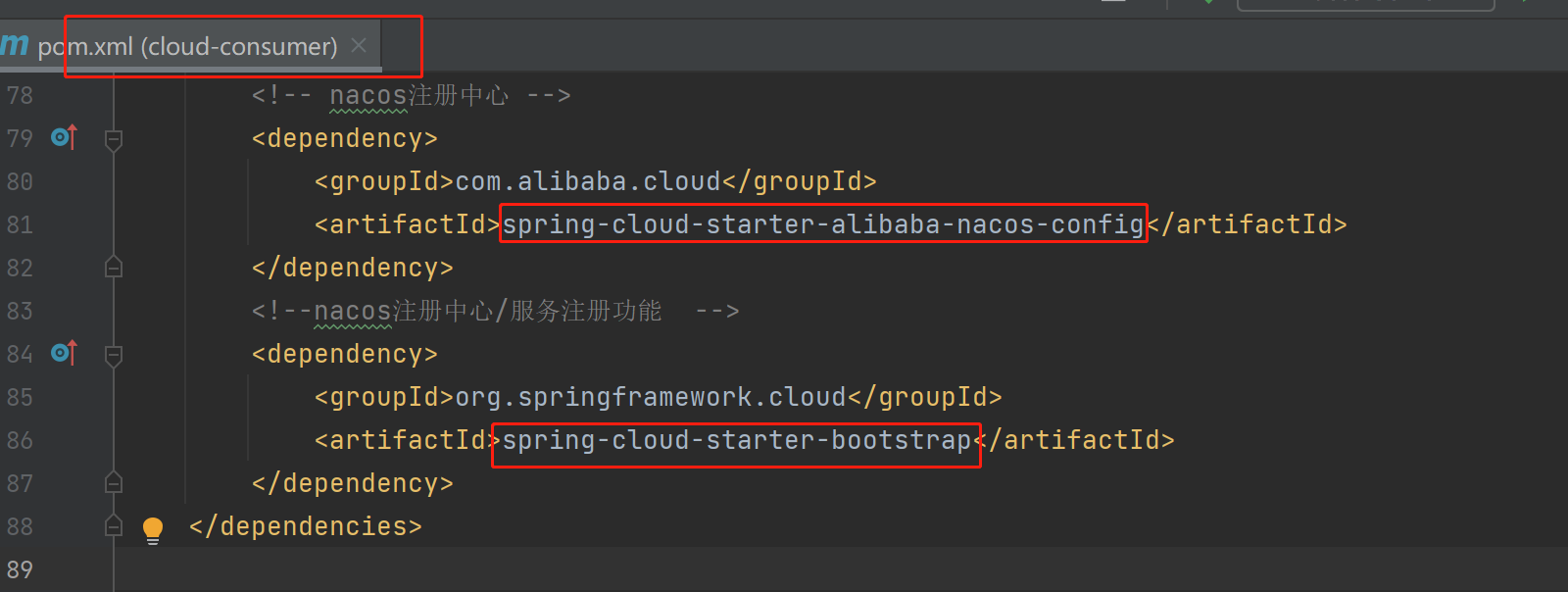
<!-- nacos注册中心 -->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-config</artifactId>
</dependency>
<!--nacos注册中心/服务注册功能 -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-bootstrap</artifactId>
</dependency>
bootstrap.yml实现配置文件远程获取:
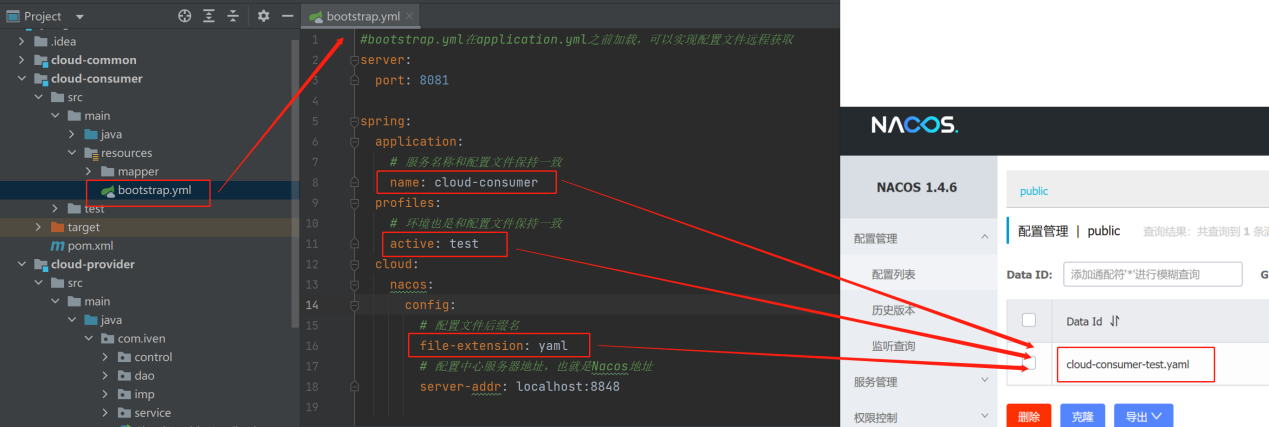
注:bootstrap.yml在application.yml之前加载,且可同时存在,最后无论是远端配置还是本地配置都会被加载
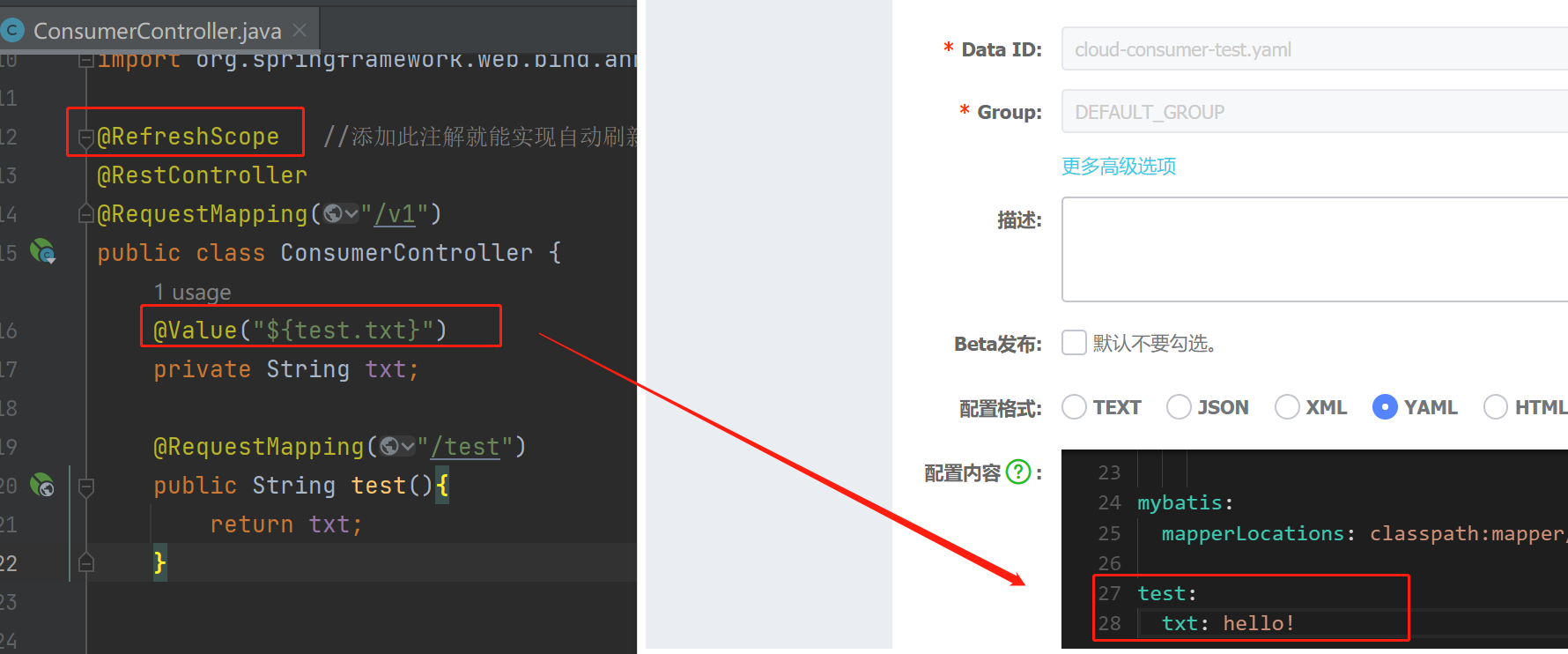
(3)、配置信息热更新:
Nacos支持配置文件的热更新,即在配置文件中添加一个属性,而此时可能需要实时修改,并在后端实时更新,可通过Spring Cloud原生注解@RefreshScope实现配置自动更新。
5、Nacos的多环境配置方案:
(1)、Data Id方案:
在默认的namespace命名空间和默认的group分组的条件下,通过修改 spring.profiles.active属性就能进行多环境下配置文件的获取。即通过修改 spring.profiles.active 属性就能获取不同环境(dev、test、prod等)的配置信息。
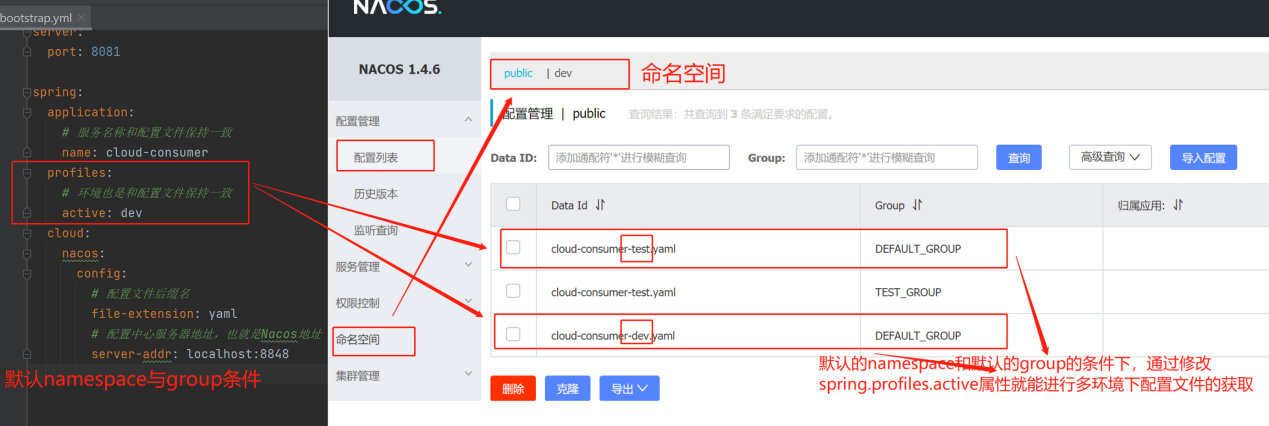
(2)、Group分组方案:
在默认namespace命名空间和相同的 Data Id 的情况下,通过修改分组(不同分组),能够获取相同Data Id 的配置文件信息。
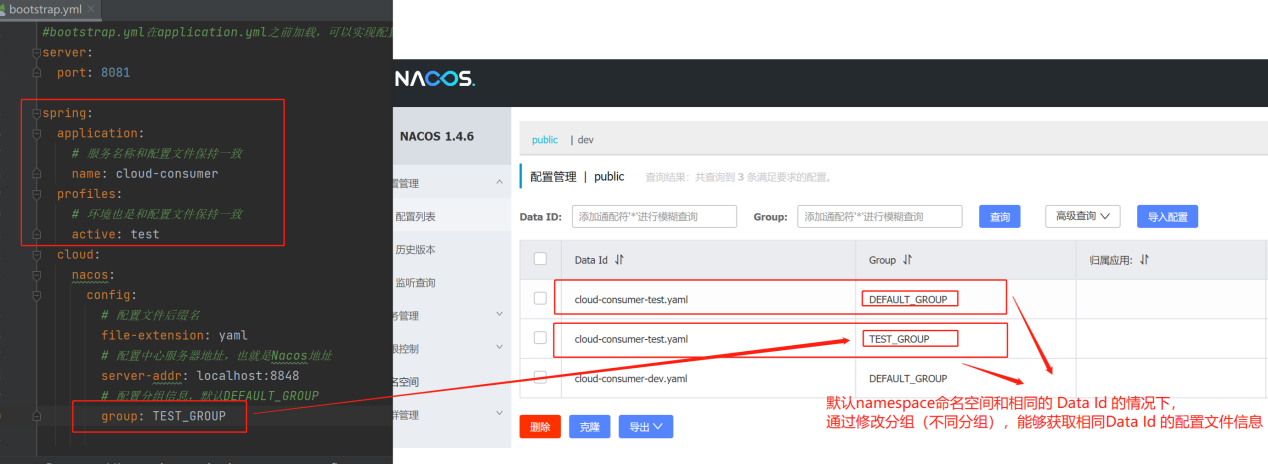
(3)、Namespace 命名空间方案:
通过Namespace、Group与Data Id 确定完整的配置获取路径
- 1)、新建Namespace命名空间:
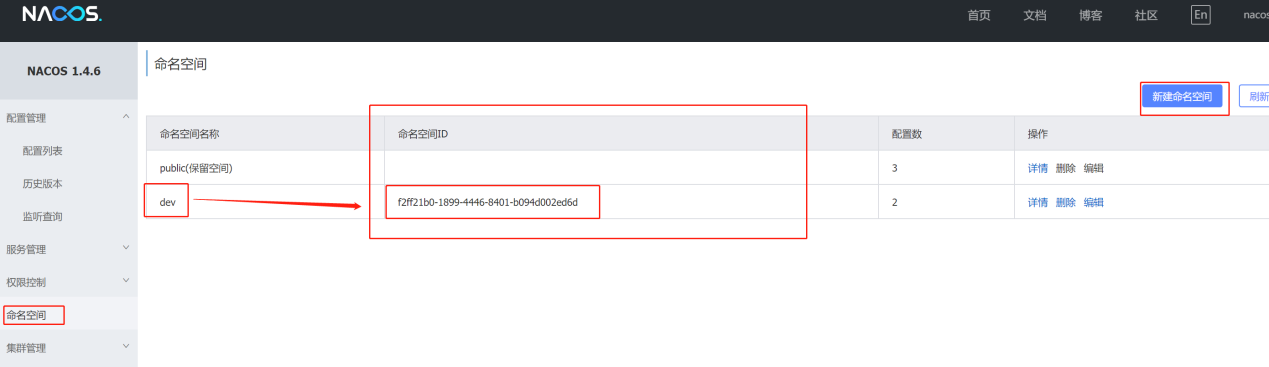
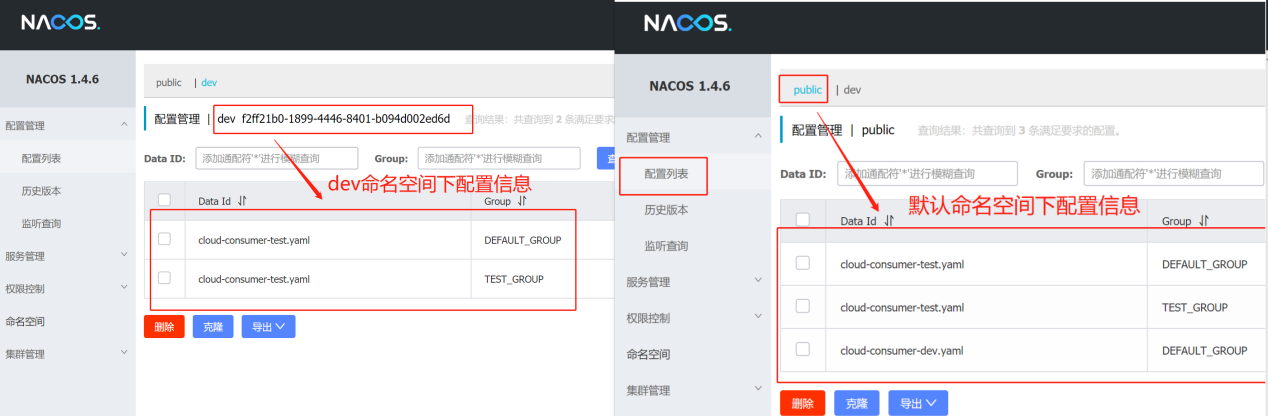
- 2)、在不同的命名空间下,实例和配置都是相互之间隔离的,可以在配置文件中指定当前的命名空间:
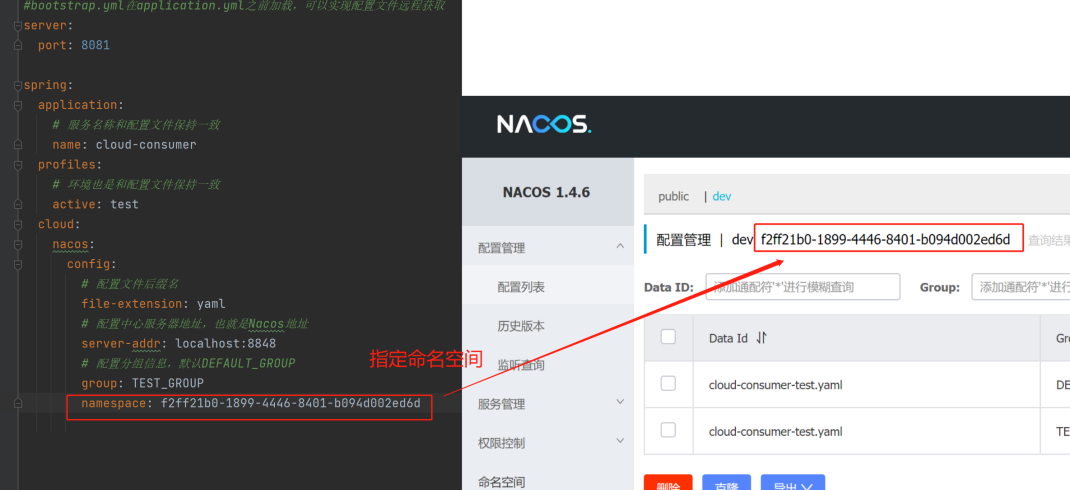
6、Nacos 高可用集群与持久化配置:
(1)、Nacos 集群架构:
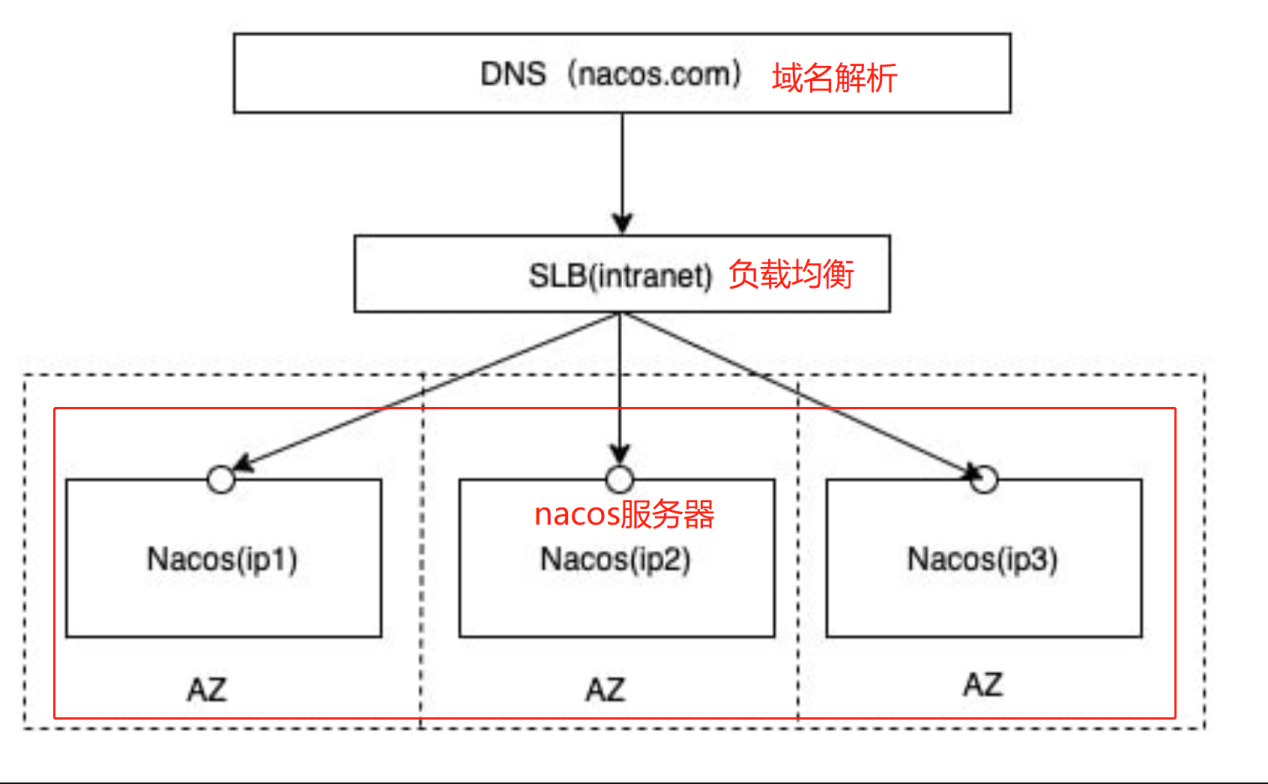
在所有的Nacos服务端之前建立一个负载均衡(Nginx),通过访问负载均衡服务器来间接访问到各个Nacos服务器
(2)、Nacos的数据存储模式(持久化配置):
在单节点的情况下,Nacos实际上是将数据存放在自带的一个嵌入式数据库中,而这种模式只适用于单节点。
在多节点集群模式下采用此模式,数据存储是存在一致性问题的。为了解决这个问题,Nacos 采用集中式存储的方式来支持集群化部署,目前只支持MySQL的存储。

(3)、Nacos 高可用集群:
- 1)、Linux服务器准备:
JDK安装、Nginx安装、MySQL安装
- 2)、Nacos集群配置:(相关参考)
相关操作,利用Nginx实现负载均衡
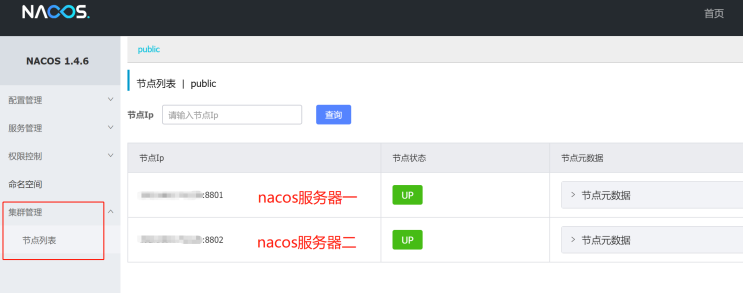
Nacos高可用配置流程: 1、修改Nacos基础配置:../nacos/conf/application.properties 2、修改Nacos的集群配置:../nacos/conf/cluster.conf 3、修改Nginx的负载均衡配置:/etc/nginx/nginx.conf
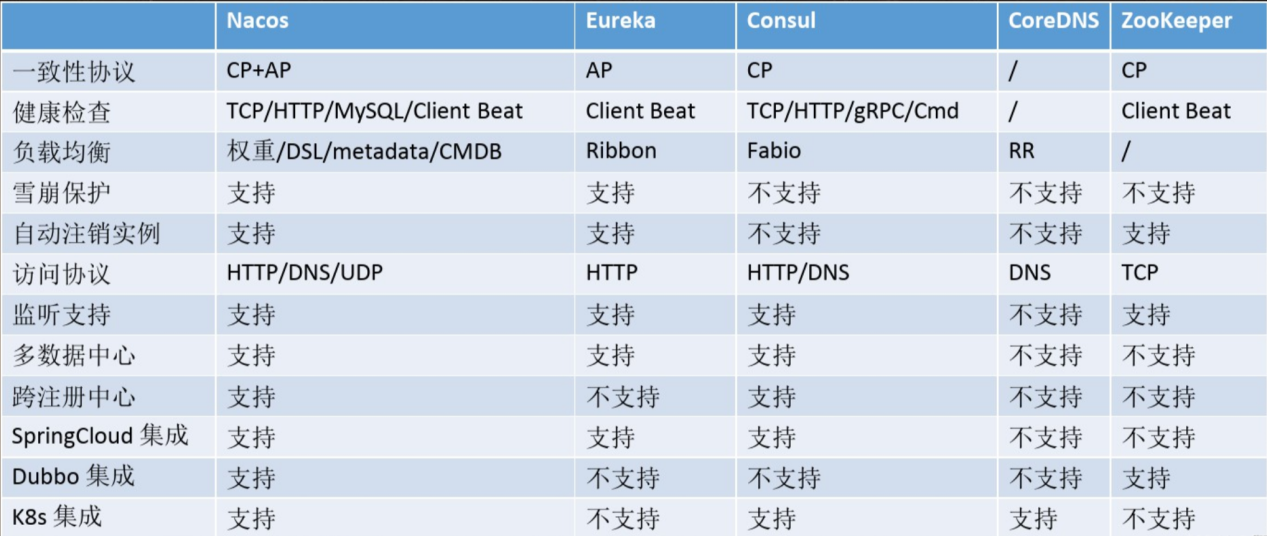
7、Nacos的CAP原则:
Nacos 支持AP和CP模式的切换:
Nacos 集群默认采用AP模式,当集群内均是非临时实例时采用CP模式
注:
分布式系统中无法同时保证一致性和可用性的,要同时保证可用性和一致性,代表着某个节点数据更新之后,需要立即将结果通知给其他节点,并且要尽可能的快,这样才能及时响应保证可用性,这就对网络的稳定性要求非常高,但是实际情况下,网络很容易出现丢包等情况,并不是一个可靠的传输,如果需要避免这种问题,就只能将节点全部放在一起,但是这显然违背了分布式系统的概念,因此,对于分布式系统而言,分区容错性是一个最基本的要求,我们在设计分布式系统的时候只能从一致性(C)和可用性(A)之间进行取舍
(1)、一致性(C):分布式系统中所有数据备份同一时刻值都相同。
(2)、可用性(A):负载过大后,集群整体中非故障节点还能响应客户端的读写请求。
(3)、分区容错性(P):服务间相互调用问题,分布式系统节点之间组成的网络本来应该是连通的,当遇到某节点或网络分区故障(比如网络丢包等)的时候,仍然能够对外提供满足一致性或可用性的服务。由于当前的网络硬件肯定会出现延迟丢包等问题,所以分区容忍性是我们必须需要实现的。
三、Sentinel服务降级熔断与限流:
Sentinel:分布式系统的流量防卫兵。随着微服务的流行,服务与服务之间的稳定性变得越来越重要,Sentinel以流量为切入点,从流量控制、熔断降级、系统负载保护等多个维度保护服务的稳定性,解决服务雪崩、降级、熔断与限流等问题。
1、Sentinel服务安装与部署:
(1)、下载地址:
Sentinel服务器是独立安装部署的,因此需要下载相应的Sentinel服务端程序:相关地址
(2)、解压启动Sentinel控制台:
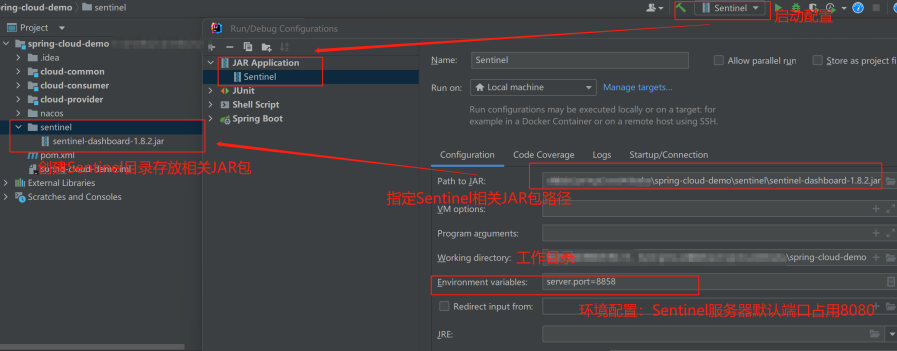
(3)、访问Sentinel管理界面:
地址:http://localhost:8858/#/dashboard,默认的用户名和管理员密码都是sentinel

(4)、初始化服务监控:
相关微服务连接到Sentinel控制台进行监控,添加依赖:

<!--sentinel监控-->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-sentinel</artifactId>
</dependency>
YML配置:
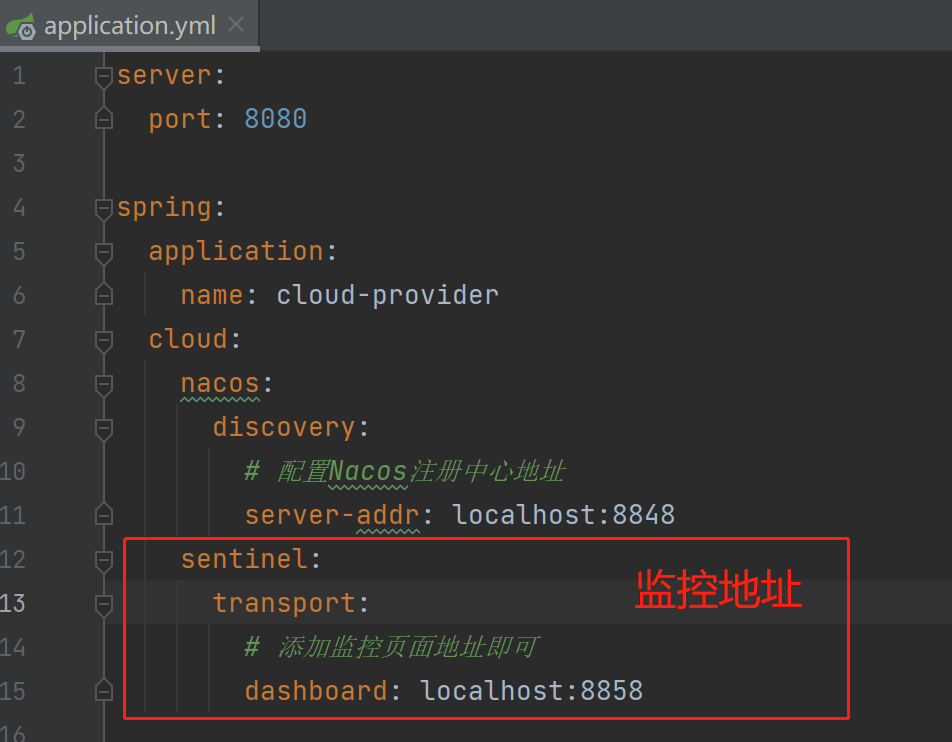
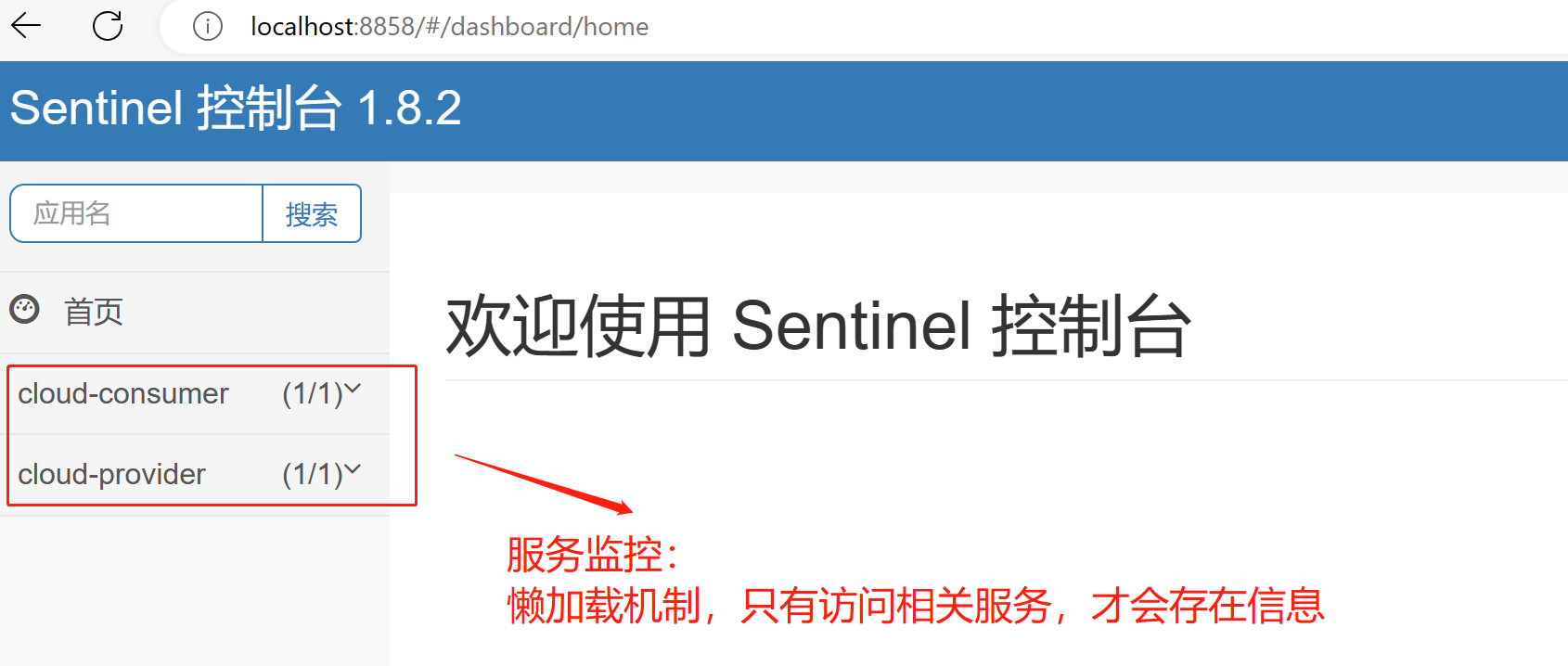
初始化监控:
注:
只有当被监控的服务发起请求调用后才会被Sentinel监控到,Sentinel是懒加载机制
2、Sentinel限流与异常处理:
由于机器不可能无限制的接受和处理客户端的请求,如果不加以限制,当发生高并发情况时,系统资源将很快被耗尽。为了避免这种情况,可以添加流量控制(也可以说是限流),当一段时间内的流量到达一定的阈值的时候,新的请求将不再进行处理,这样不仅可以合理地应对高并发请求,同时也能在一定程度上保护服务器不受到外界的恶意攻击。
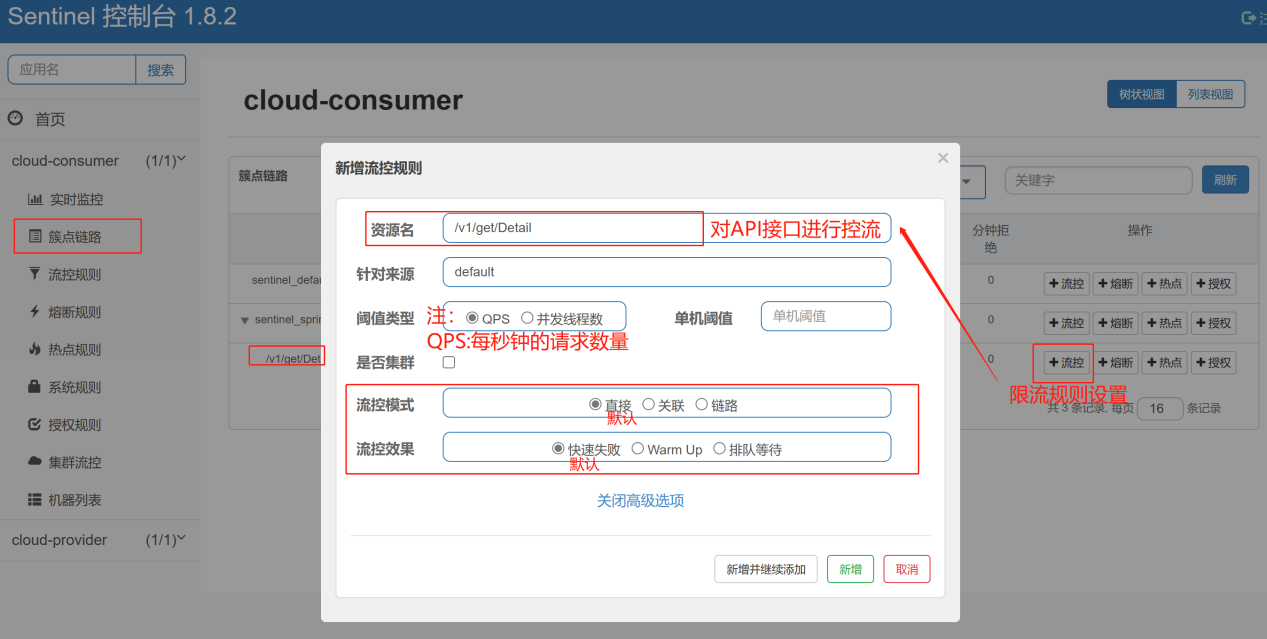
(1)、流控规则——限流
|
备注 |
说明 |
|
单机阈值 |
请求的次数 |
|
QPS限流 |
当每秒钟的请求数量达到设定的阈值的时候,则进行限流操作 |
|
并发线程数限流 |
当排队的线程数达到设定的阈值的时候,则进行限流操作 |
一、流控模式:
1)、直接(默认)模式:
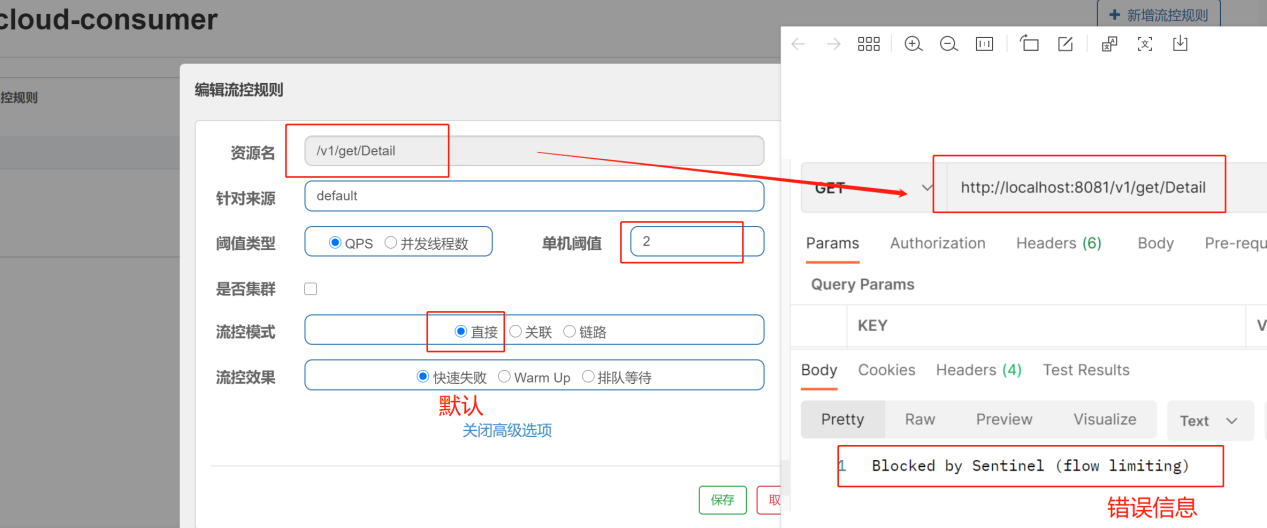
只针对于当前接口
|
阈值类型 |
结论 |
|
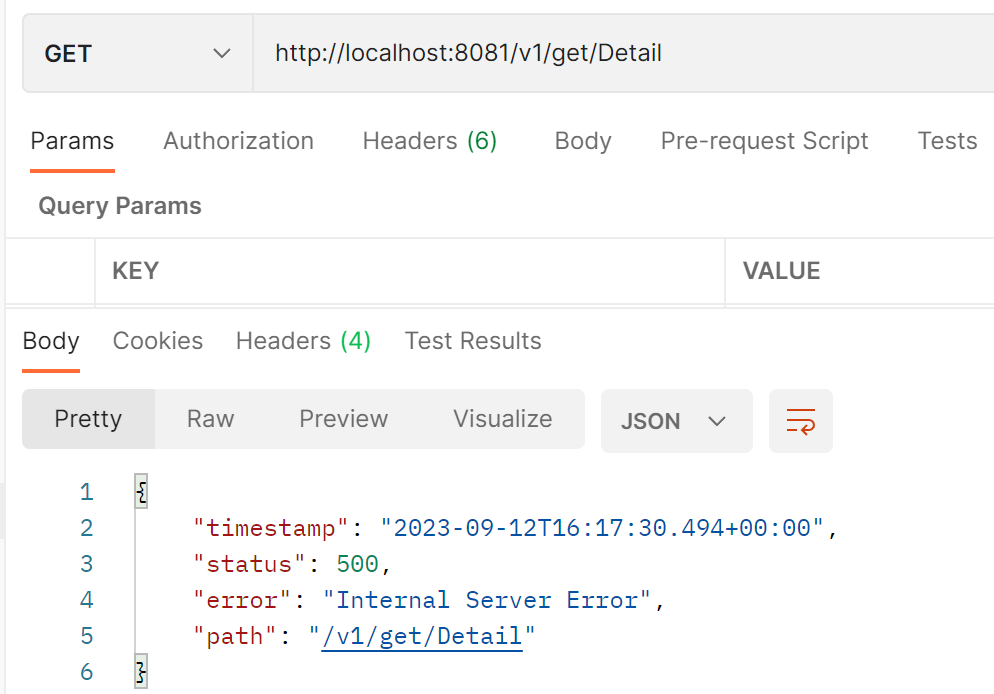
QPS |
表示1秒钟向API接口发送请求超出设定次数2,就直接-快速失败,报默认错误【报错:Blocked by Sentinel (flow limiting)】,反之,正常执行 |
|
并发线程数 |
表示1秒内访问该 API 接口的线程数,当排队的线程数达到设定的阈值的时候,则进行限流操作,通常出现在接口访问响应慢的时候。如果操作很快,也不会出现限流。 |
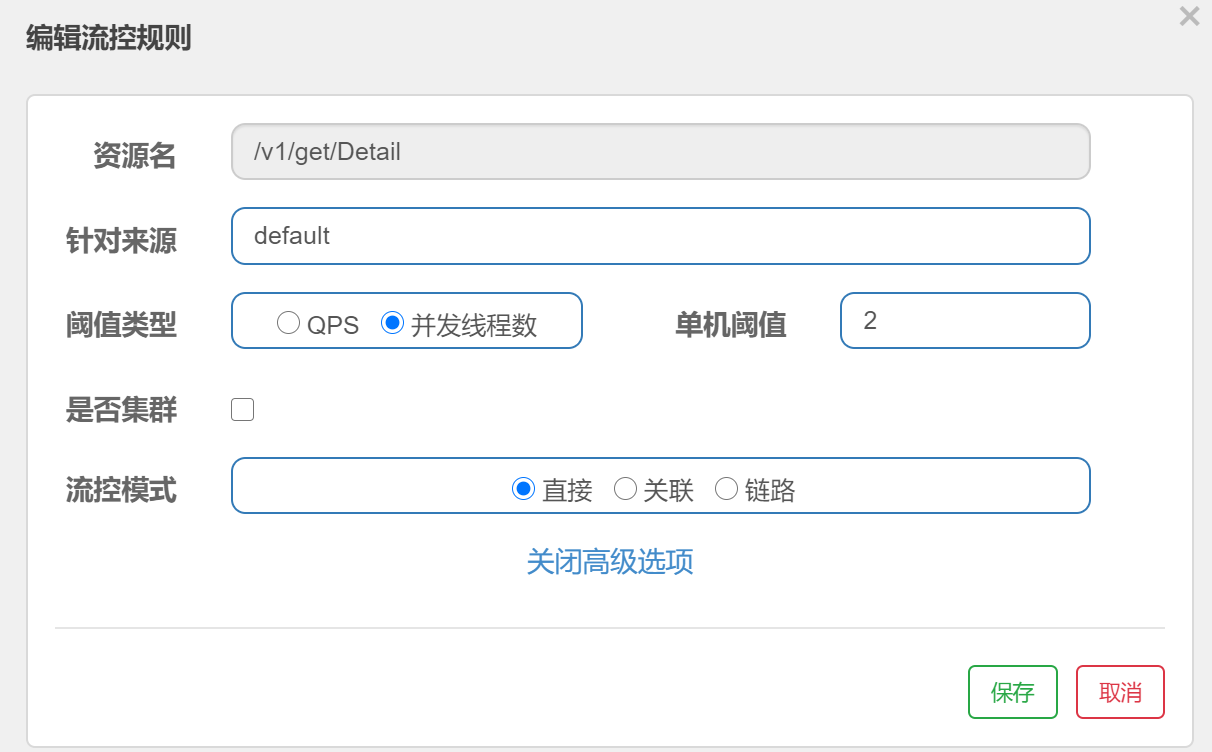
2)、关联模式:
与当前接口关联的其他接口超过设定阈值时,会导致当前接口被限流。
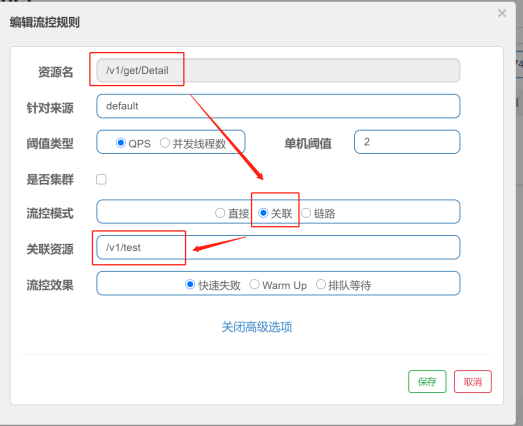
备注:适用于下单接口(当前的A)、支付接口(关联的B)。密集请求B ,然后访问A,结果啊A出现了流控报错
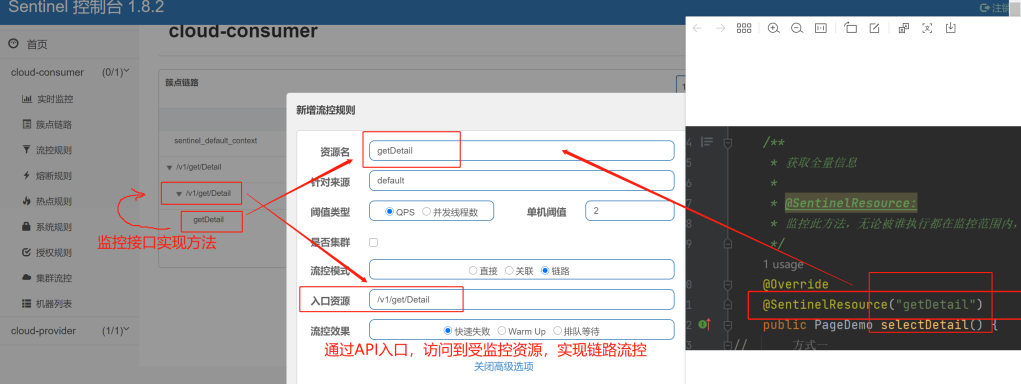
3)、链路模式:
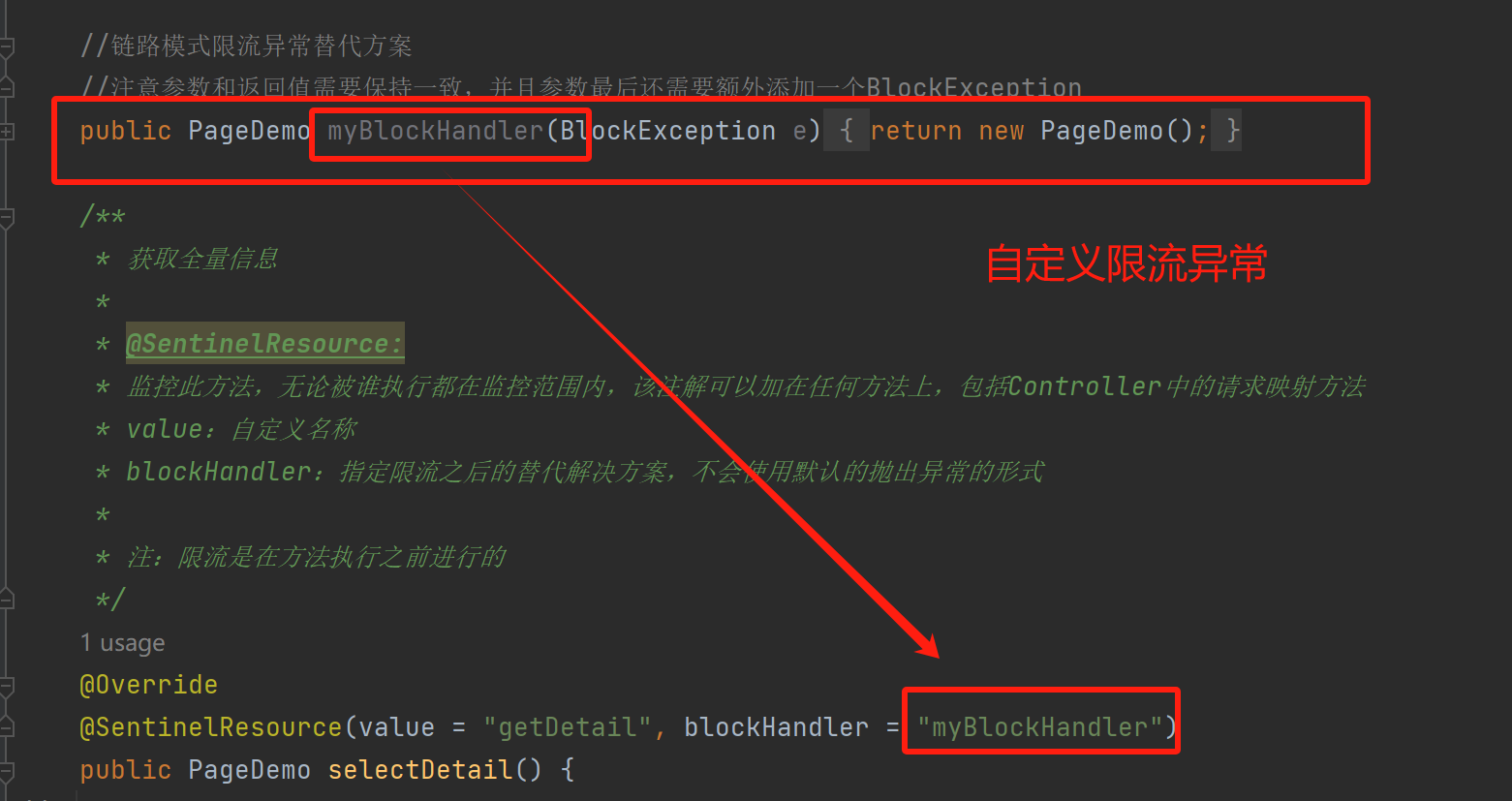
更细粒度的限流,能精确到具体的方法,使用@SentinelResource注解标注某方法,那么该方法就会被监控,当从指定接口链路过来的资源请求达到限流条件时,则开启限流。
注:限流是在方法执行之前进行的
- 添加方法监控:
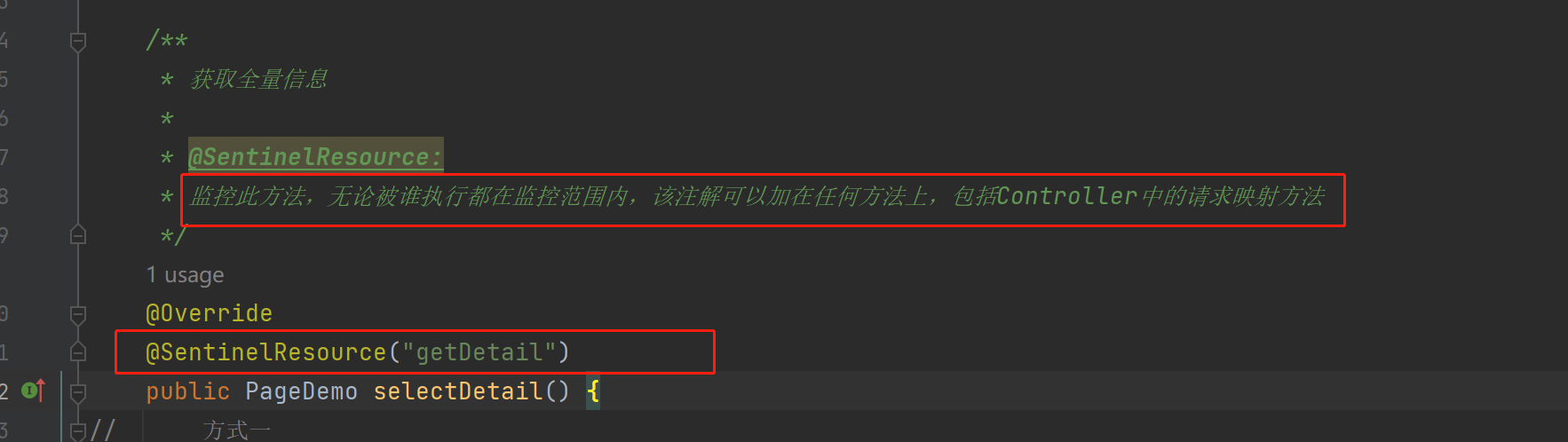
@SentinelResource: 监控指定方法,无论被谁执行都在监控范围内,该注解可以加在任何方法上,包括Controller中的请求映射方法,value是自定义名称。
- 配置关闭Context收敛,实现不同链路的单独控制:
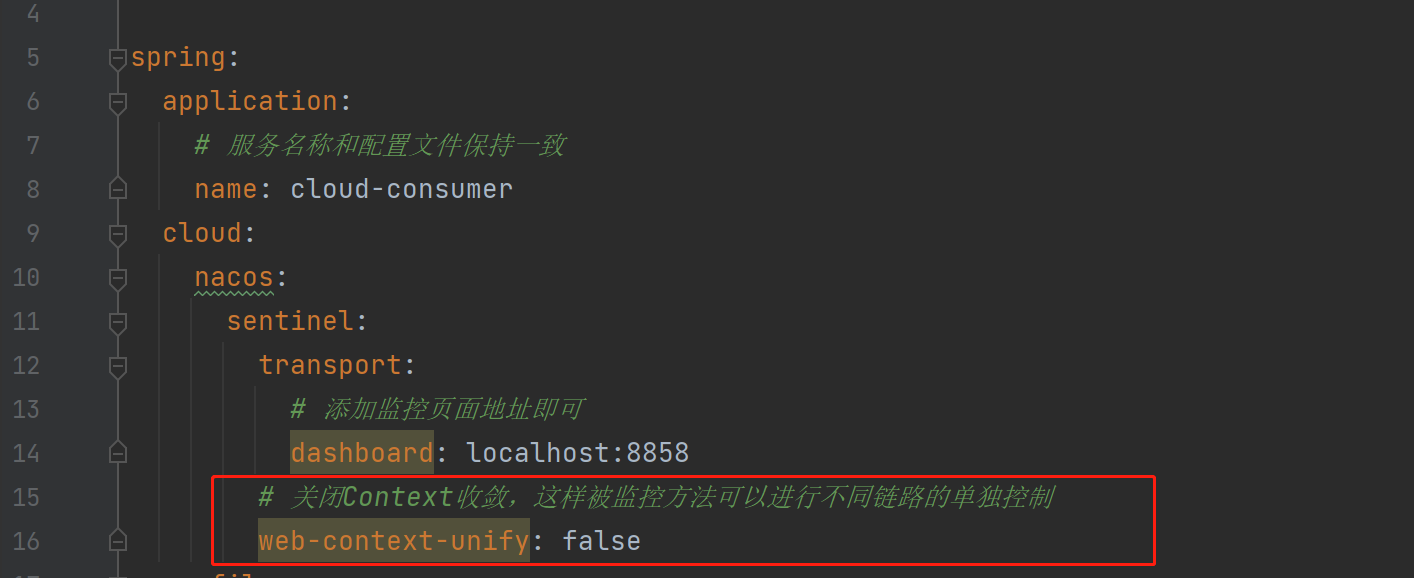
- 添加链路限流规则:
- 限流返回错误信息:
二、流控效果
1)、快速失败:
直接失败,抛出异常(默认)

2)、Warm up(预热):
请求从(指定阈值除以codeFactor(默认值为3))开始,经预热时长逐渐升至指定阈值,形成一个缓冲保护。
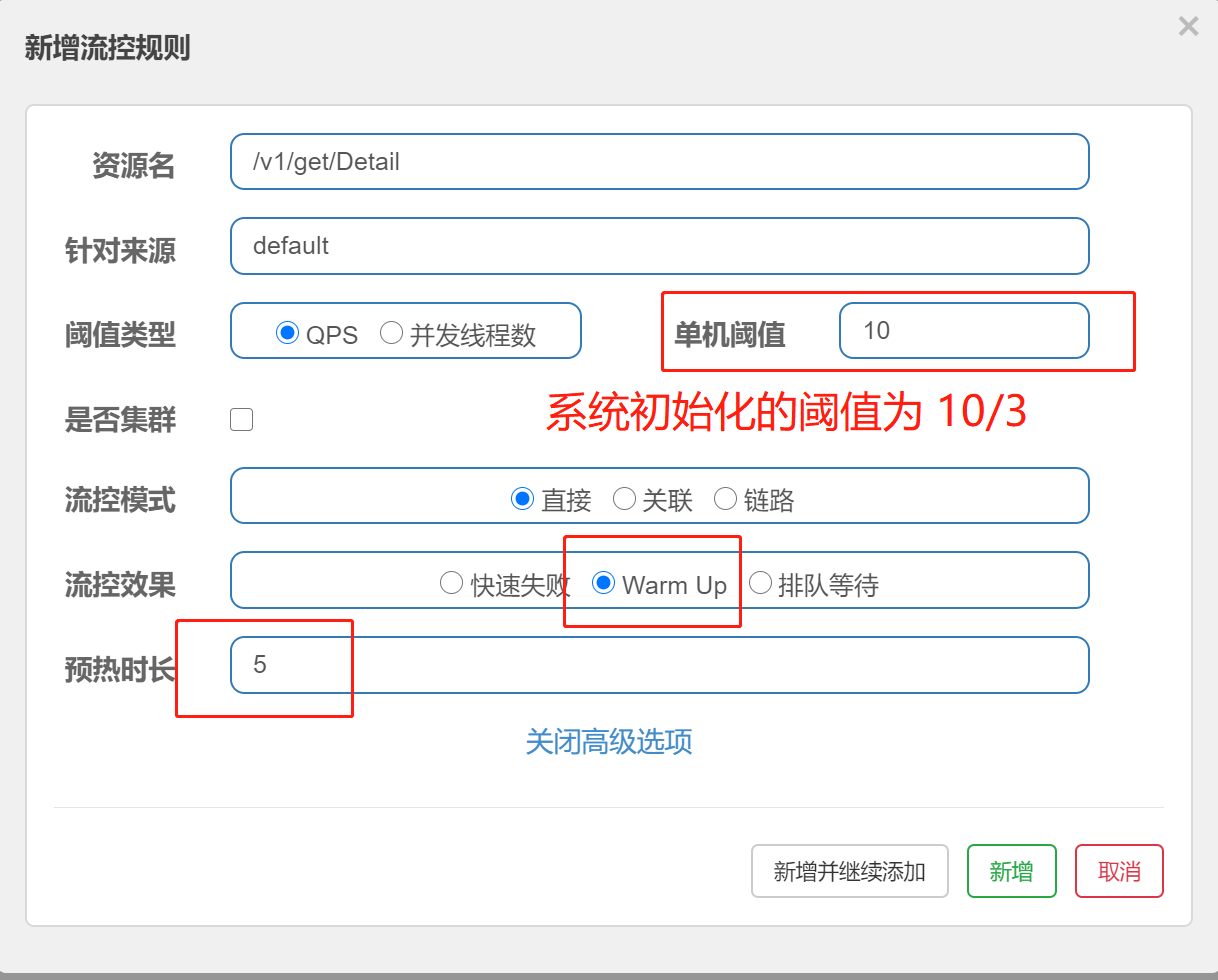
备注:阈值设置为10 ,预热时长设置为5秒。系统初始化的阈值为10/3,经过5秒后阈值慢慢升高至10。适用于秒杀系统在开启的瞬间,会有很多流量上来,可能导致系统崩溃,预热的方式就是为了保护系统,可以慢慢的把请求的流量放进来,慢慢的把初始化阈值 QPS/3增长到指定设置的阈值。
3)、排队等待:
匀速排队,让请求一均匀的速度通过,阈值类型必须设置为 QPS,否则无效。
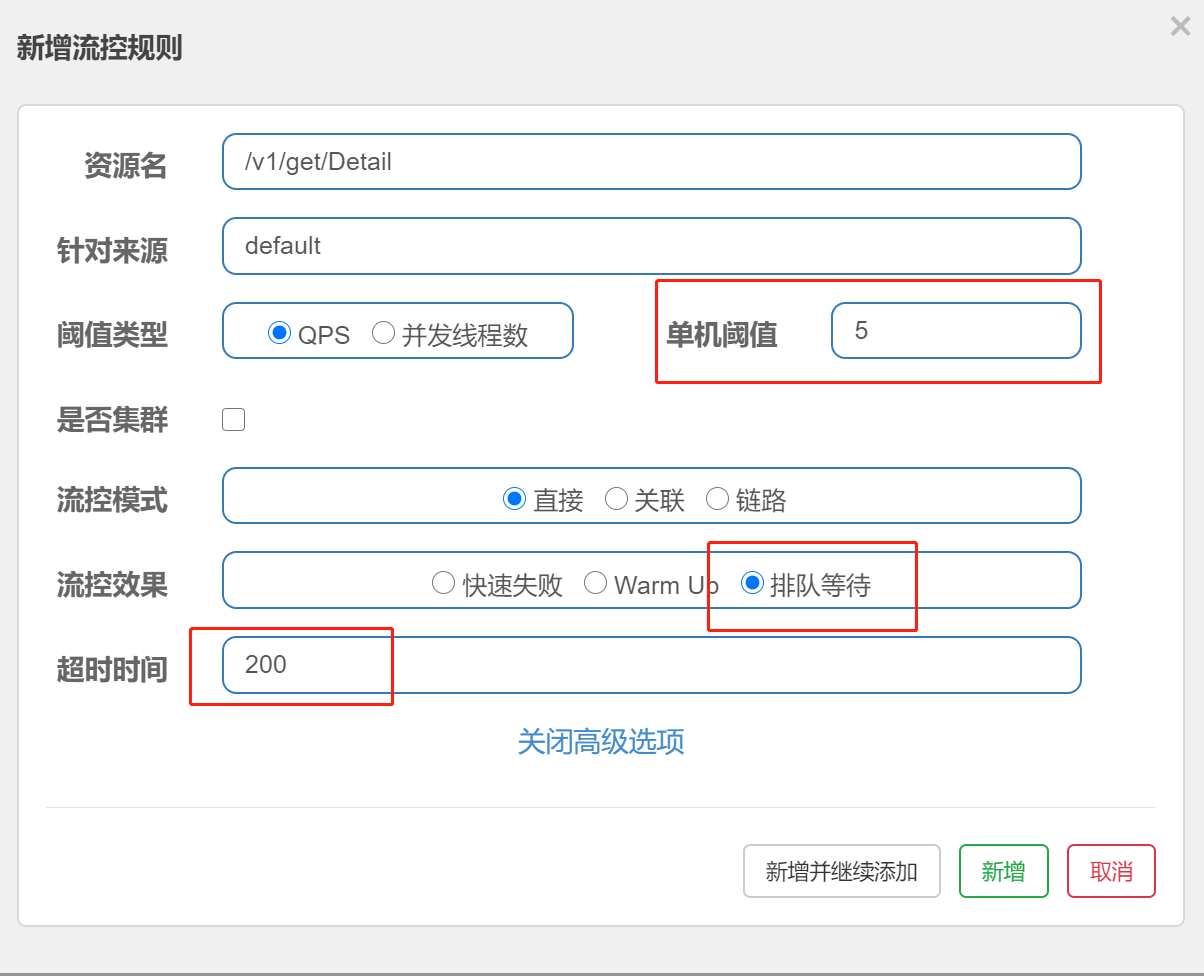
备注:接口每秒5次请求,超过的话就排队等待,等待超时时间为200毫秒,超过200毫秒 没有响应就报错
(2)、热点规则——热点参数限流:
由于不同参数被携带访问的频率是不一样的,所以需要设置对应的热点规则,当访问指定资源名的时,携带有指定参数索引(指资源方法的第几个参数,从0开始计数),并且在指定时间窗内QPS达到阈值时进行精准限流。目前热点key规则仅支持QPS限流模式。
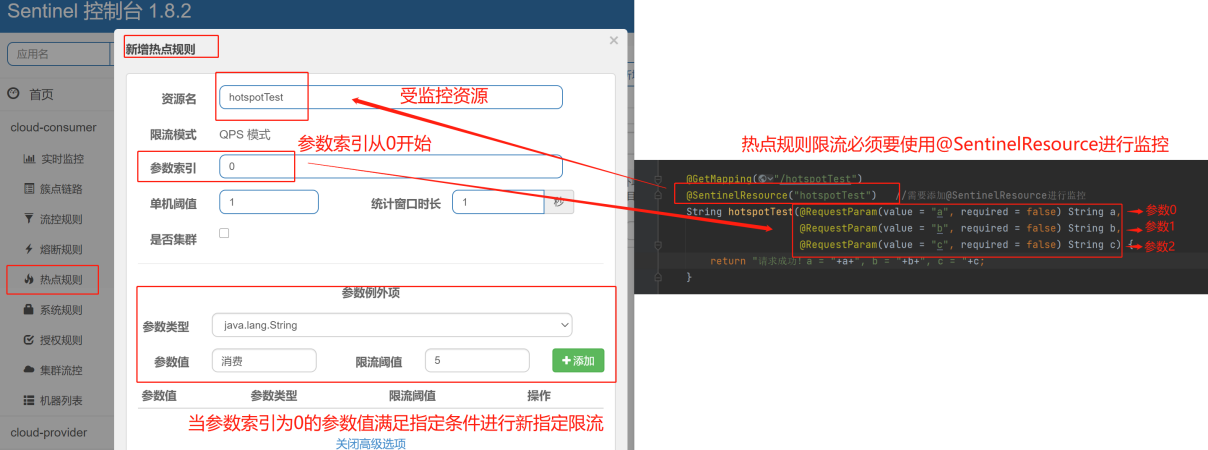
备注:不仅实现对请求携带的热点参数的限流,还实现对热点参数携带特定值的特例限流
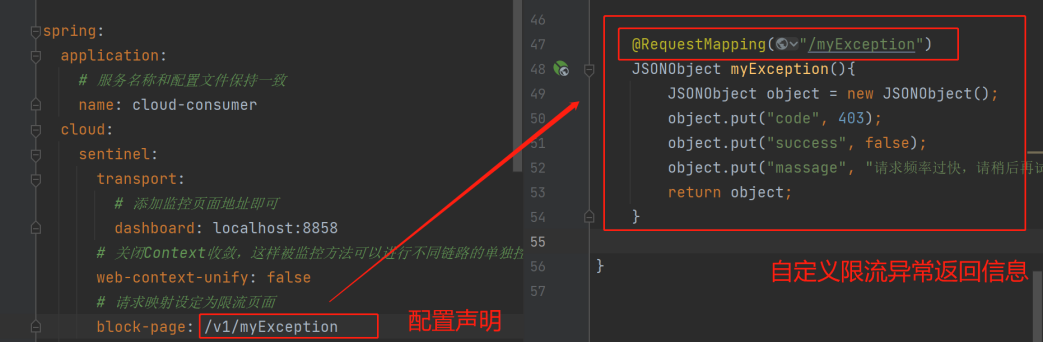
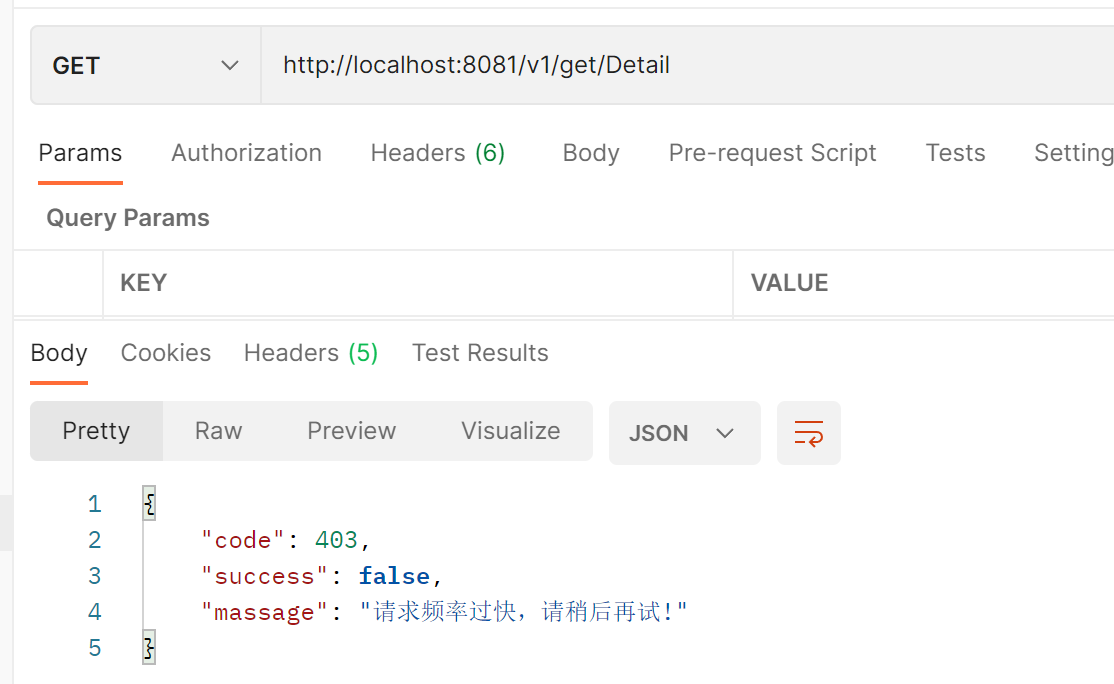
(3)、自定义返回限流的异常信息:
Sentinel限流异常默认:

自定义限流异常信息:
- 1)、默认限流异常信息自定义:
- 2)、链路模式限流异常信息自定义:
3、Sentinel服务降级与熔断:
(1)、Sentinel服务熔断策略:
熔断策略有三种模式
1)、慢调用比例(SLOW_REQUEST_RATIO):
选择以慢调用比例作为阈值,需要设置允许的慢调用最大RT(即最大的响应时间),当请求的响应时间大于最大RT(即最大的响应时间)则统计为慢调用,并且统计时长内请求数大于设置的最小请求数,慢调用的比例(慢调用次数 / 调用次数)大于设定的比例阈值,则会触发熔断策略,在接下来的熔断时长内请求会自动被熔断。经过熔断时长之后,熔断器会进入探测恢复状态(HALF-OPEN 半开状态),若接下来的一个请求响应时间小于设置的慢调用RT则结束熔断,若大于设置的慢调用RT则会再次被熔断。
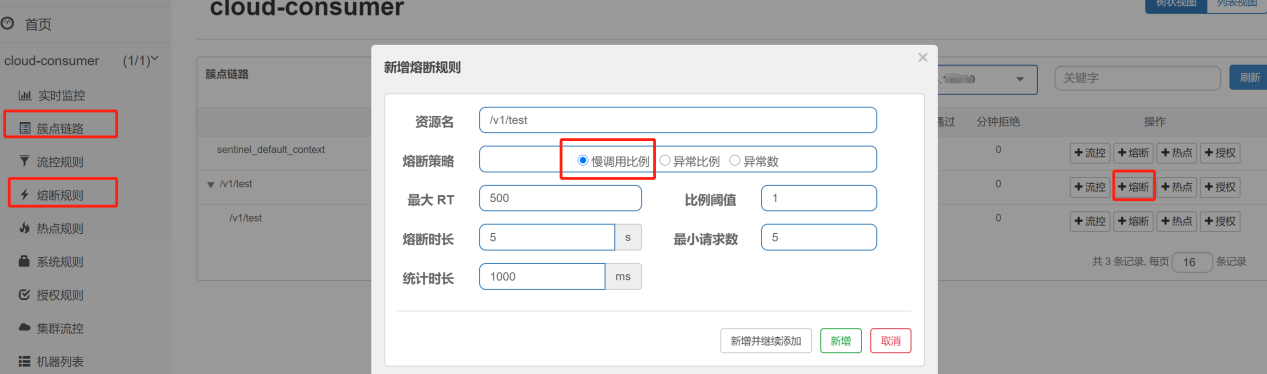
|
属性 |
说明 |
|
最大RT(毫秒) |
最大响应时间,指系统对请求作出最大响应的时间 |
|
比例阈值 |
慢调用次数 / 调用次数,阈值范围是 [0.0, 1.0] |
2)、异常比例 (ERROR_RATIO):
当统计时长内请求数大于设置的最小请求数,并且异常的比例大于设定的比例阈值,则会触发熔断策略,在接下来的熔断时长内请求会自动被熔断。经过熔断时长之后,熔断器会进入探测恢复状态(HALF-OPEN 半开状态),若接下来的一个请求成功完成(没有错误)则结束熔断,否则会再次被熔断。
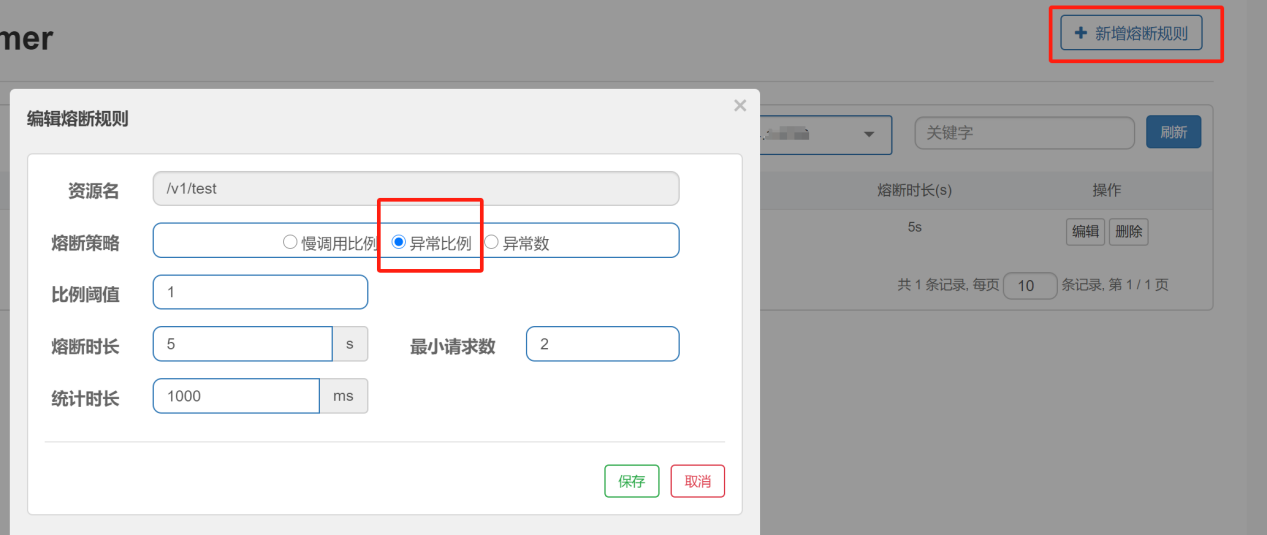
|
属性 |
说明 |
|
比例阈值 |
异常调用次数 / 调用次数,阈值范围是 [0.0, 1.0] |
3)、异常数 (ERROR_COUNT):
只要统计时长内的异常数超过设定的异常数就会自动进行熔断。经过熔断时长之后,熔断器会进入探测恢复状态(HALF-OPEN 半开状态),若接下来的一个请求成功完成(没有错误)则结束熔断,否则会再次被熔断。
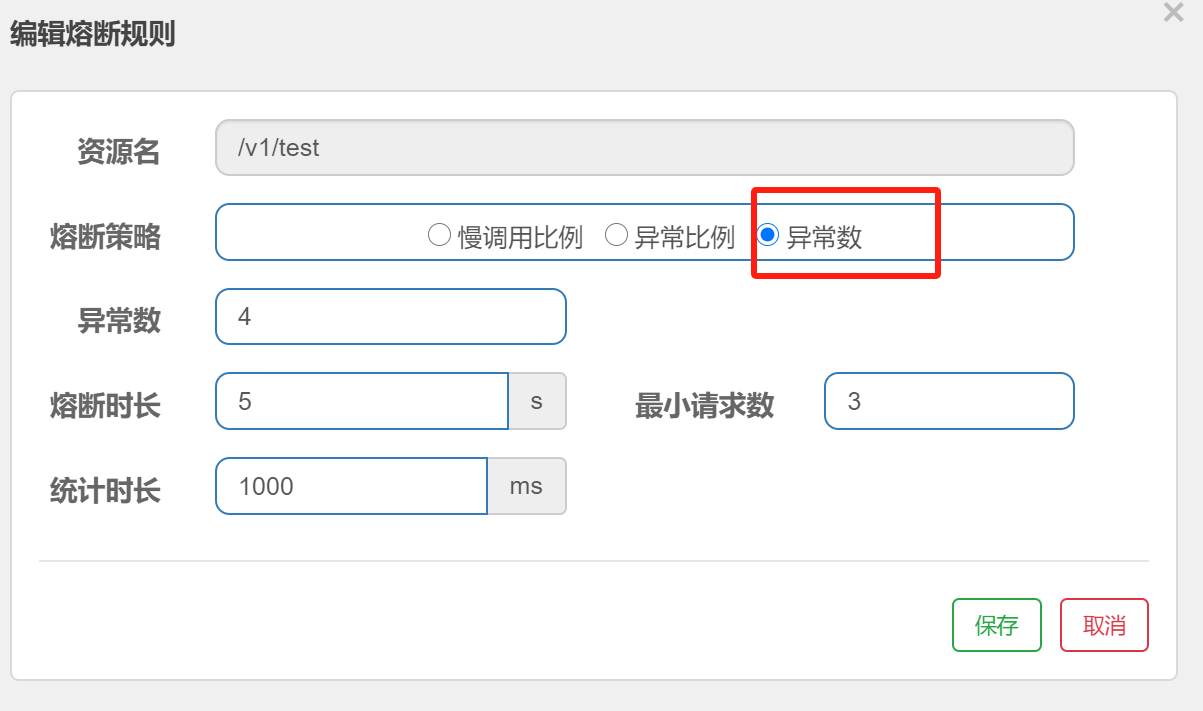
(2)、Sentinel服务降级策略:
1)、采用声明自定义异常信息方式实现降级:
参考自定义返回限流的异常信息设置,在@SentinelResource中配置blockHandler参数,进行方法级别细粒度的限制,blockHandler的目的就是处理这种Sentinel机制上的异常,所以这里其实和之前的限流配置是一个道理,因此下面熔断配置也应该对value自定义名称的资源进行配置,才能作用到此方法上
2)、采用OpenFeign集成Sentinel方式实现降级:
OpenFeign对远程调用声明的接口进行实现(即接口实现类的方法,为降级策略执行方案)
开启feign支持:
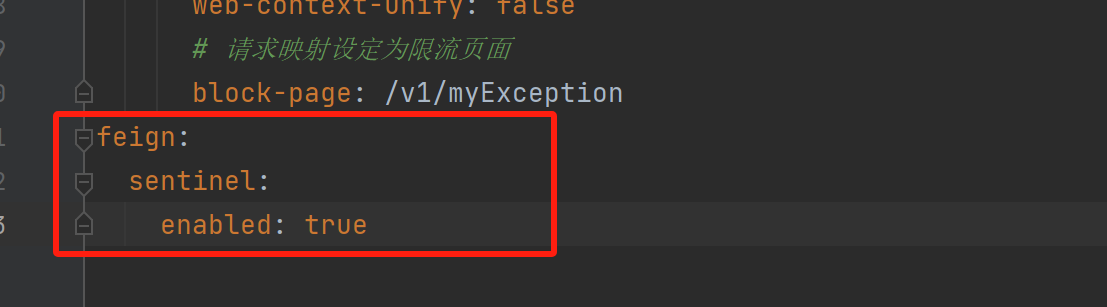
对应服务接口类:
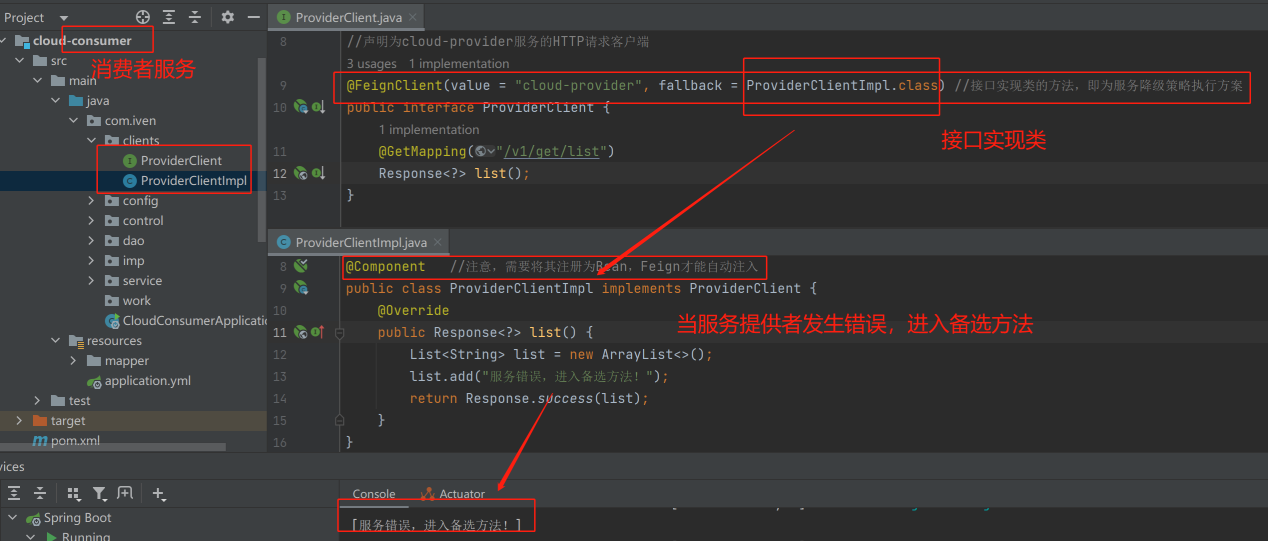
4、Sentinel系统规则:
系统规则(限流总控)是从应用级别的入口流量进行控制,从单台机器的LOAD、CPU使用率、平均RT、入口QPS和并发线程数等几个维度监控应用指标,让系统尽可能泡在最大吞吐量的同时保证系统整体稳定性。系统保护规则是应用整体维度的,而不是资源维度的,并且仅对入口流量生效。入口流量指的是进入应用的流量(EntryType.IN),比如Web服务或Dubbo服务端接收的请求,都属于入口流量。
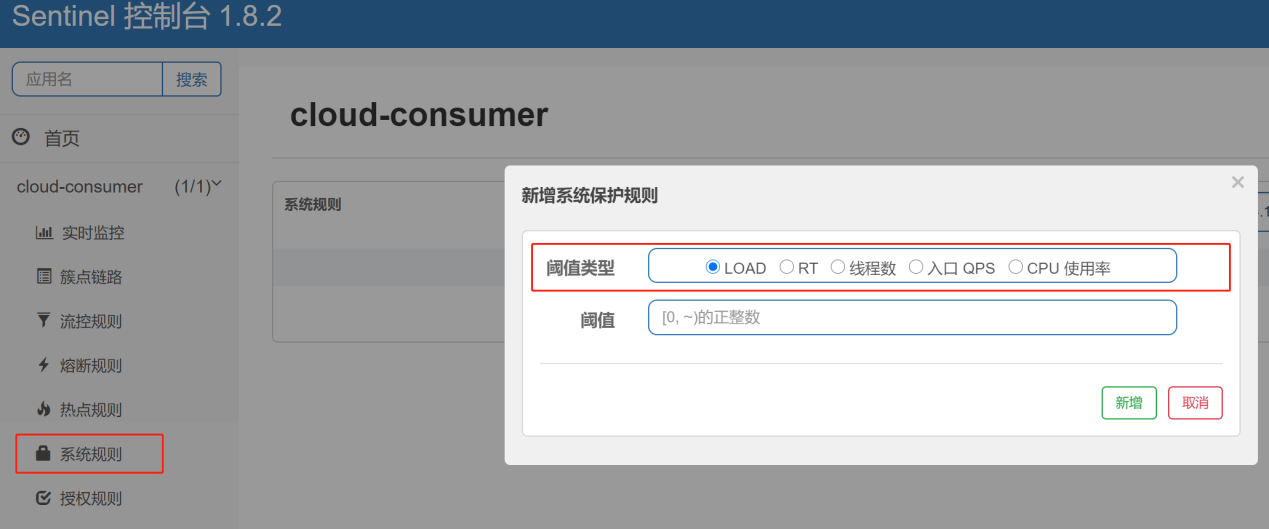
|
系统规则模式 |
说明 |
|
Load自适应(仅对Linux/Unix-like机器生效) |
系统的 load1 作为启发指标,进行自适应系统保护。当系统 load1 超过设定的启发值,且系统当前的并发线程数超过估算的系统容量才会触发系统保护(BBR 阶段)。系统容量有系统的 maxQps * minRt估算得出。设定参考值一般是 CPU cores (CPU核数) * 2.5。 |
|
CPU usage(1.5.0+ 版本) |
当系统 CPU 使用率超过阈值即触发系统保护(取值范围 0.0-1.0),比较灵敏。 |
|
平均RT |
当单台机器上所有入口流量的平均 RT 达到阈值即触发系统保护,单位是毫秒。 |
|
并发线程数 |
当单台机器上所有入口流量的并发线程数达到阈值基础法系统保护。 |
|
入口QPS |
当单台机器上所有入口流量的 QPS 达到阈值即触发系统保护。 |
5、Sentinel规则持久化:
当项目重启后,Sentinel规则就消失了,因此生产环境需要将配置的规则进行持久化。控制台将配置的规则推送到远程的配置中心(Nacos),Sentinel客户端通过监听Nacos,获取配置变更的推送消息,完成本地配置更新。
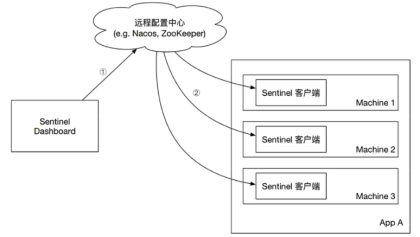
(1)、添加相关依赖:
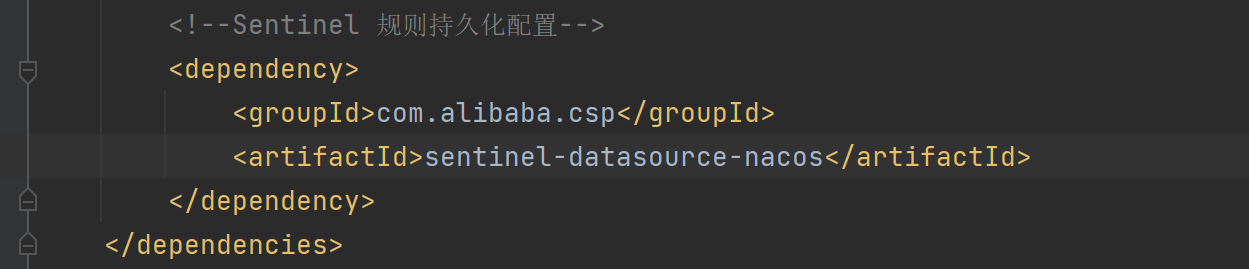
<!--Sentinel 规则持久化配置-->
<dependency>
<groupId>com.alibaba.csp</groupId>
<artifactId>sentinel-datasource-nacos</artifactId>
</dependency>
(2)、配置Sentinel数据源与规则信息:
在application.properties或application.yml配置文件中,配置相关信息。
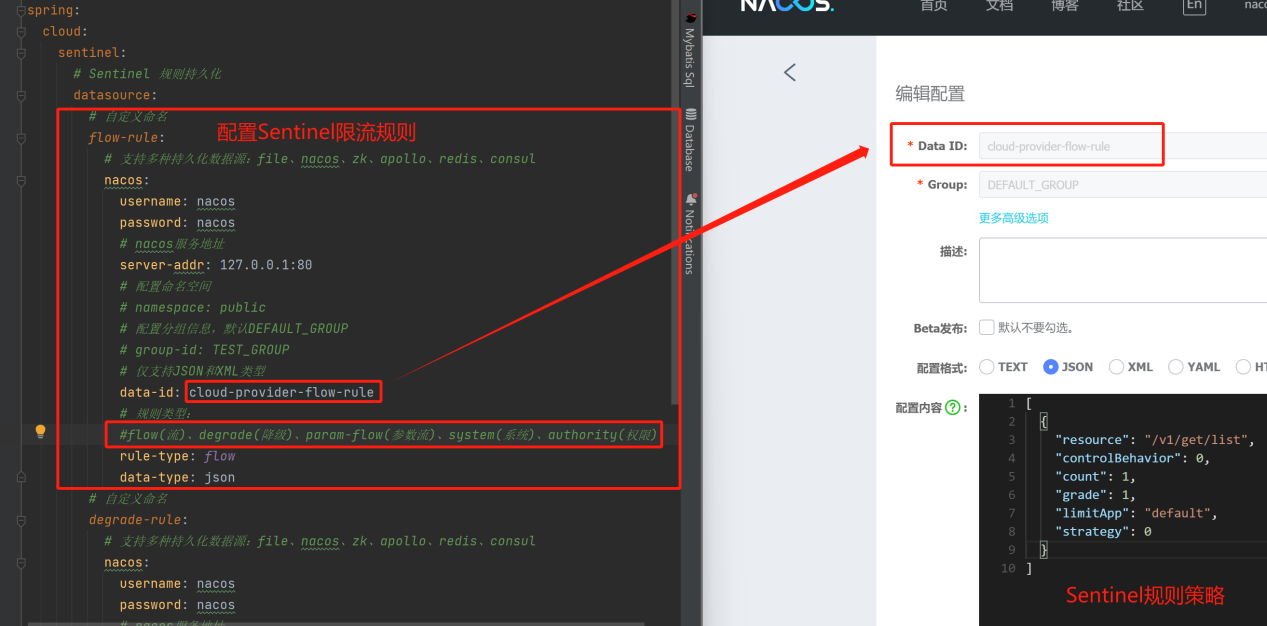
(3)、持久化信息:

(4)、参考:
四、Seata分布式事务框架:
官方文档:https://seata.io/zh-cn/docs/overview/what-is-seata.html
1、分布式事务问题:
在传统的单体服务应用中,事务的控制非常简单,Spring框架提供@Transactional注解就能进行相应的事务控制,但是由于每个服务(单体)内部的数据一致性是由本地事务来保证的,对于全局的数据一致性却没办法保证,总而言之,一次业务操作需要跨多个数据源或需要跨多个服务进行远程调用,就会产生分布式事务问题。
Seata是一款开源的分布式事务解决方案,致力于在微服务架构下提供高性能和简单易用的分布式事务服务。
2、Seata分布式事务处理机制:
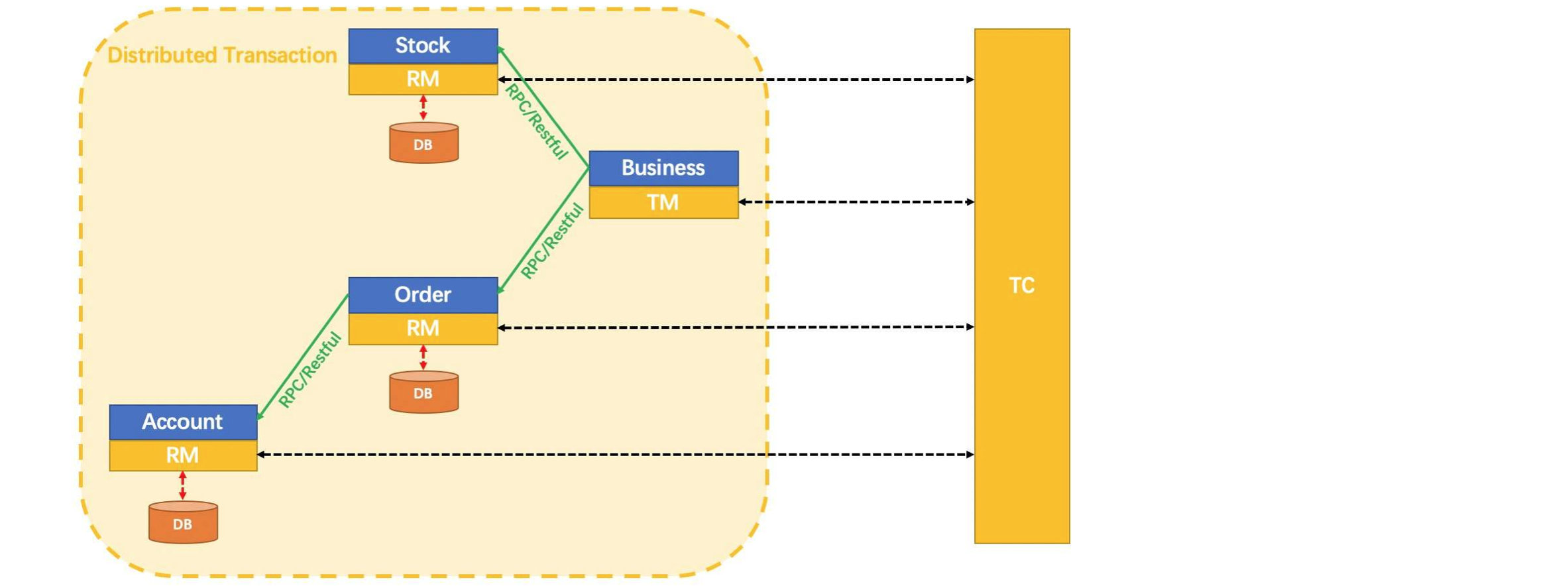
|
属性 |
说明 |
|
XID(TranSaction ID) |
全局唯一的事务 ID |
|
RM(Resource Manager) |
资源管理器。管理分支(单体)事务处理的资源,与 TC(事务协调器)交互,注册分支事务和状态汇报。接受 TC 的指令,并驱动分支(单体)事务的提交与回滚 |
|
TM(Transaction Manager) |
事务管理器。定义全局事务的范围:开始全局事务、提交或回滚全局事务。即全局事务发起者(分布式事务的核心管理者) |
|
TC(Transaction Coordinator) |
事务协调器。即Seata服务器,用于全局控制,维护全局事务的运行状态,负责协调并驱动全局事务的提交和回滚。 |
处理流程:
(1)、TM向TC申请开启一个全局事务,TC会生成一个全局唯一的XID作为该全局事务的编号;(XID会在微服务的调用链路中传播,保证将多个微服务的子事务关联在一起)
(3)、RM请求TC将本地事务注册为全局事务的分支事务,通过全局事务的XID进行关联;
(4)、TM请求TC告诉XID对应的全局事务是进行提交还是回滚;
(5)、TC驱动RM将XID对应的自己的本地事务进行提交还是回滚;
3、Seata四种事务模式:
官网文档:https://seata.io/zh-cn/docs/overview/what-is-seata.html
|
事务模式 |
说明 |
|
AT模式 |
最终一致的分阶段事务模式,无业务侵入,也是Seata的默认模式 |
|
XA模式 |
强一致性分阶段事务模式,牺牲了一定的可用性,无业务侵入 |
|
TCC模式 |
最终一致的分阶段事务模式,有业务侵入 |
|
SAGA模式 |
长事务模式,有业务侵入 |
(1)、AT模式:
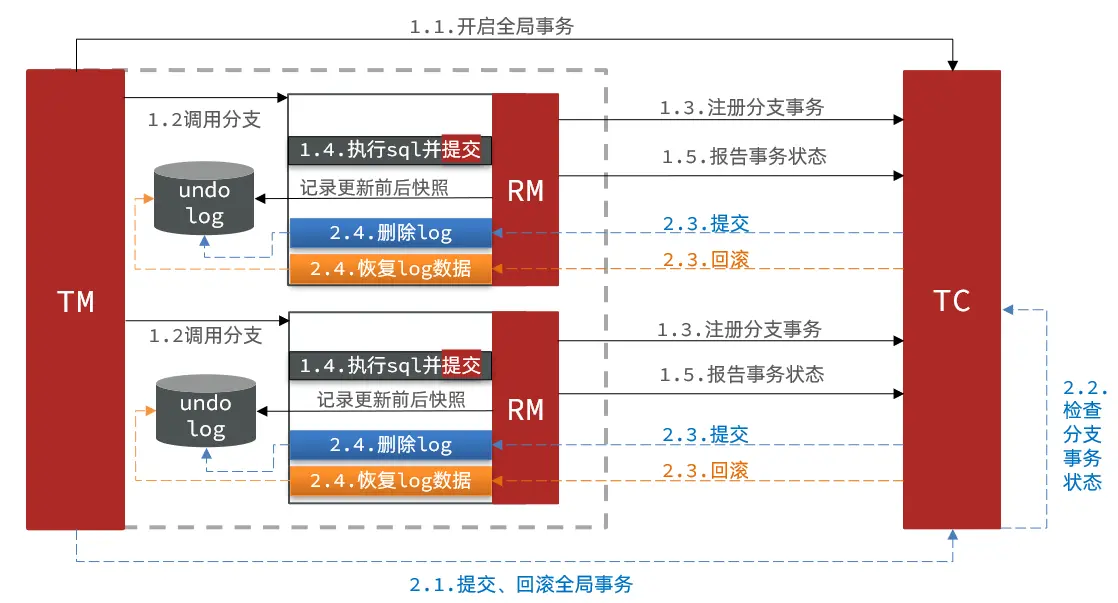
AT模式同样是分阶段提交的事务模型,不过缺弥补了XA模型中资源锁定周期过长的缺陷,本质上就是2PC的升级版,在 AT 模式下,用户只需关心自己的“业务SQL”
- 1)、阶段一RM的工作:
注册分支事务
记录undo-log(数据快照,在业务数据被更新前,将其保存为 before image,在业务数据更新之后,其保存成 after image,最后生成行锁)
执行业务sql并提交
报告事务状态
- 2)、阶段二提交时RM的工作:
删除undo-log即可(将一阶段保存的快照数据与行锁删掉,完成数据清理)
- 3)、阶段二回滚时RM的工作:
根据undo-log恢复数据到更新前(使用before image 还原业务数据;但在还原前要校验脏写,对比数据库当前数据和after image,如果两份数据完全一致就说明没有脏写,可以还原业务数据;如果不一致就说明有脏写,出现脏写就需要转人工处理)
(2)、AT模式的优缺点:
优点:
- 1)、一阶段完成直接提交事务,释放数据库资源,性能比较好
- 2)、利用全局锁实现读写隔离
- 3)、没有代码侵入,框架自动完成回滚和提交
缺点:
- 1)、两阶段之间属于软状态,属于最终一致
- 2)、框架的快照功能会影响性能,但比XA模式要好很多
(3)、基于NACOS模式部署:
1)、seata-server下载地址:https://github.com/seata/seata/releases/tag/v1.4.2
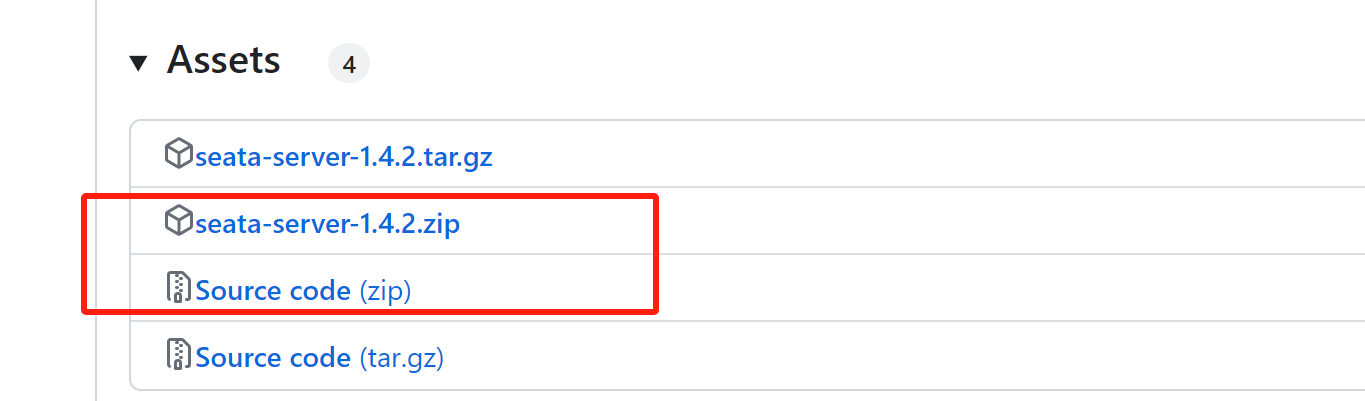
2)、将Source code源文件目录下的script整个文件夹(官方提供的上传脚本)拷贝放到seata-server的解压目录下,便于后续操作。
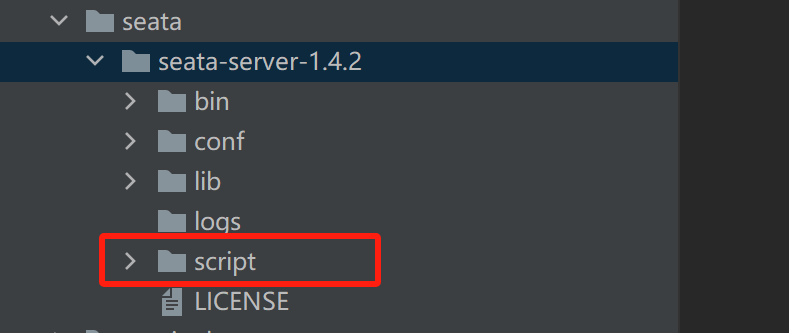
3)、修改conf目录下的file.conf 配置文件:
自定义事务组名称+事务日志存储模式为db+数据库连接信息,实现seata server 高可用
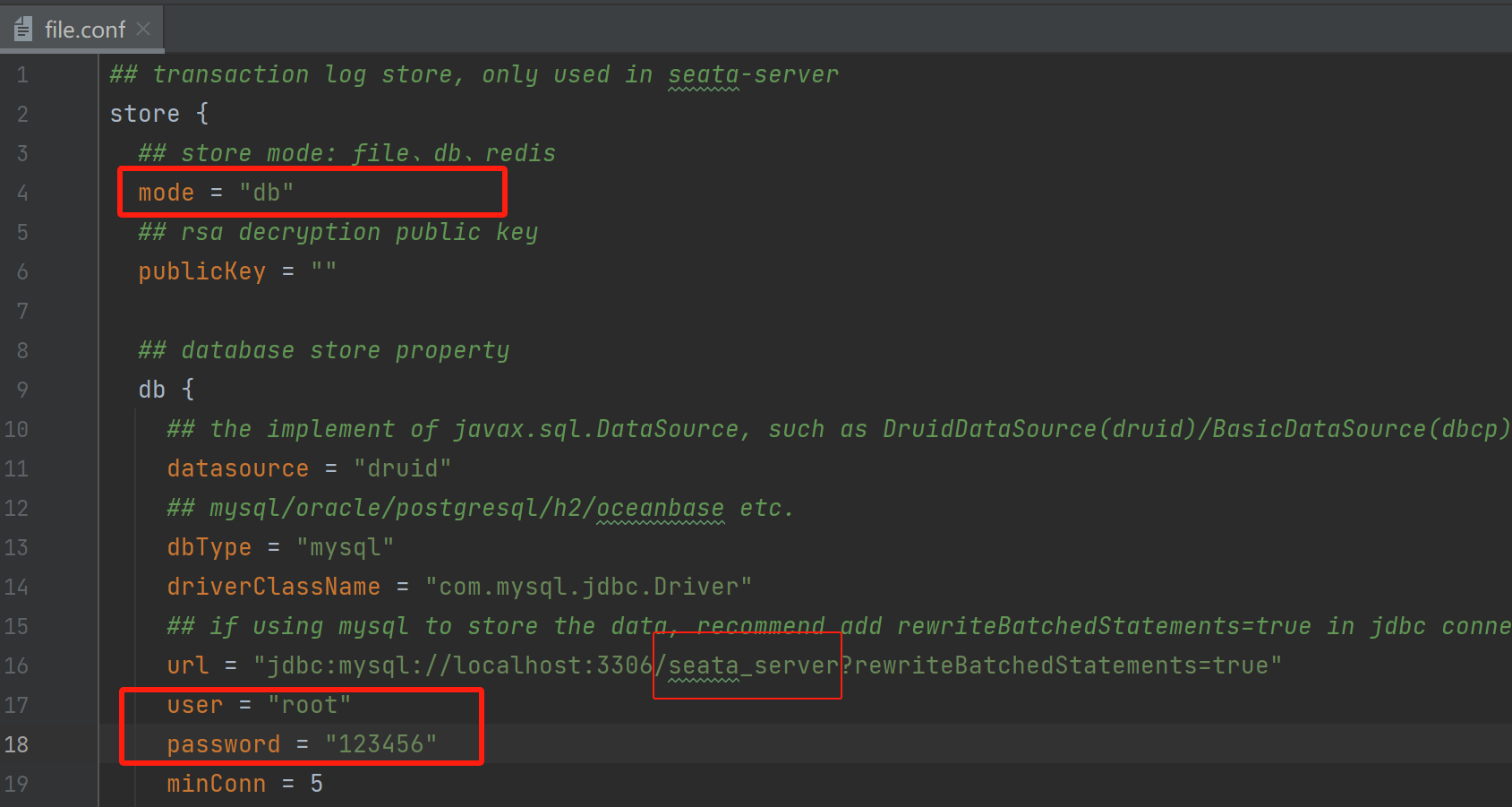
4)、创建数据库:seata_server
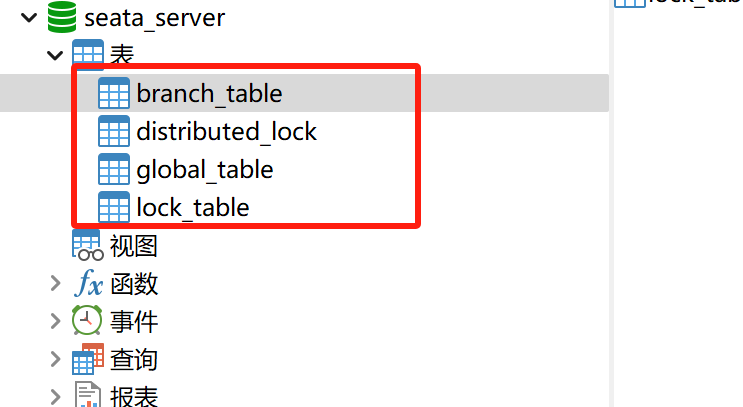
插入相应表:


-- -------------------------------- The script used when storeMode is 'db' -------------------------------- -- the table to store GlobalSession data CREATE TABLE IF NOT EXISTS `global_table` ( `xid` VARCHAR(128) NOT NULL, `transaction_id` BIGINT, `status` TINYINT NOT NULL, `application_id` VARCHAR(32), `transaction_service_group` VARCHAR(32), `transaction_name` VARCHAR(128), `timeout` INT, `begin_time` BIGINT, `application_data` VARCHAR(2000), `gmt_create` DATETIME, `gmt_modified` DATETIME, PRIMARY KEY (`xid`), KEY `idx_status_gmt_modified` (`status` , `gmt_modified`), KEY `idx_transaction_id` (`transaction_id`) ) ENGINE = InnoDB DEFAULT CHARSET = utf8mb4; -- the table to store BranchSession data CREATE TABLE IF NOT EXISTS `branch_table` ( `branch_id` BIGINT NOT NULL, `xid` VARCHAR(128) NOT NULL, `transaction_id` BIGINT, `resource_group_id` VARCHAR(32), `resource_id` VARCHAR(256), `branch_type` VARCHAR(8), `status` TINYINT, `client_id` VARCHAR(64), `application_data` VARCHAR(2000), `gmt_create` DATETIME(6), `gmt_modified` DATETIME(6), PRIMARY KEY (`branch_id`), KEY `idx_xid` (`xid`) ) ENGINE = InnoDB DEFAULT CHARSET = utf8mb4; -- the table to store lock data CREATE TABLE IF NOT EXISTS `lock_table` ( `row_key` VARCHAR(128) NOT NULL, `xid` VARCHAR(128), `transaction_id` BIGINT, `branch_id` BIGINT NOT NULL, `resource_id` VARCHAR(256), `table_name` VARCHAR(32), `pk` VARCHAR(36), `status` TINYINT NOT NULL DEFAULT '0' COMMENT '0:locked ,1:rollbacking', `gmt_create` DATETIME, `gmt_modified` DATETIME, PRIMARY KEY (`row_key`), KEY `idx_status` (`status`), KEY `idx_branch_id` (`branch_id`) ) ENGINE = InnoDB DEFAULT CHARSET = utf8mb4; CREATE TABLE IF NOT EXISTS `distributed_lock` ( `lock_key` CHAR(20) NOT NULL, `lock_value` VARCHAR(20) NOT NULL, `expire` BIGINT, primary key (`lock_key`) ) ENGINE = InnoDB DEFAULT CHARSET = utf8mb4; INSERT INTO `distributed_lock` (lock_key, lock_value, expire) VALUES ('HandleAllSession', ' ', 0);
5)、修改conf目录下的registry.conf配置文件:
NACOS配置:
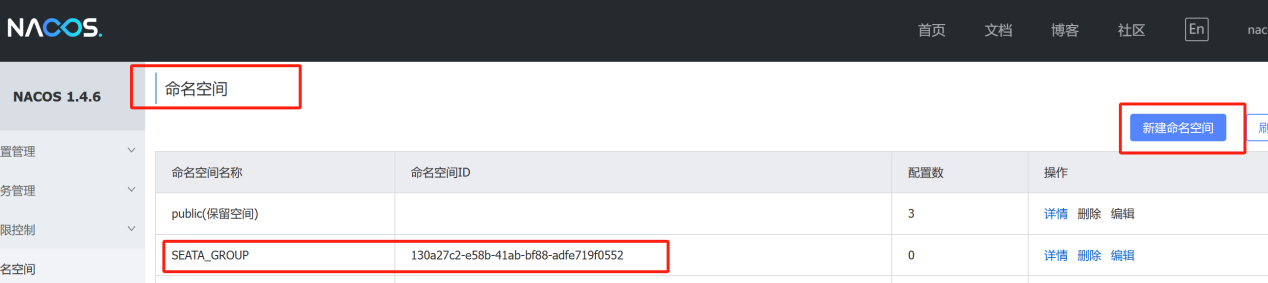
registry.conf配置:
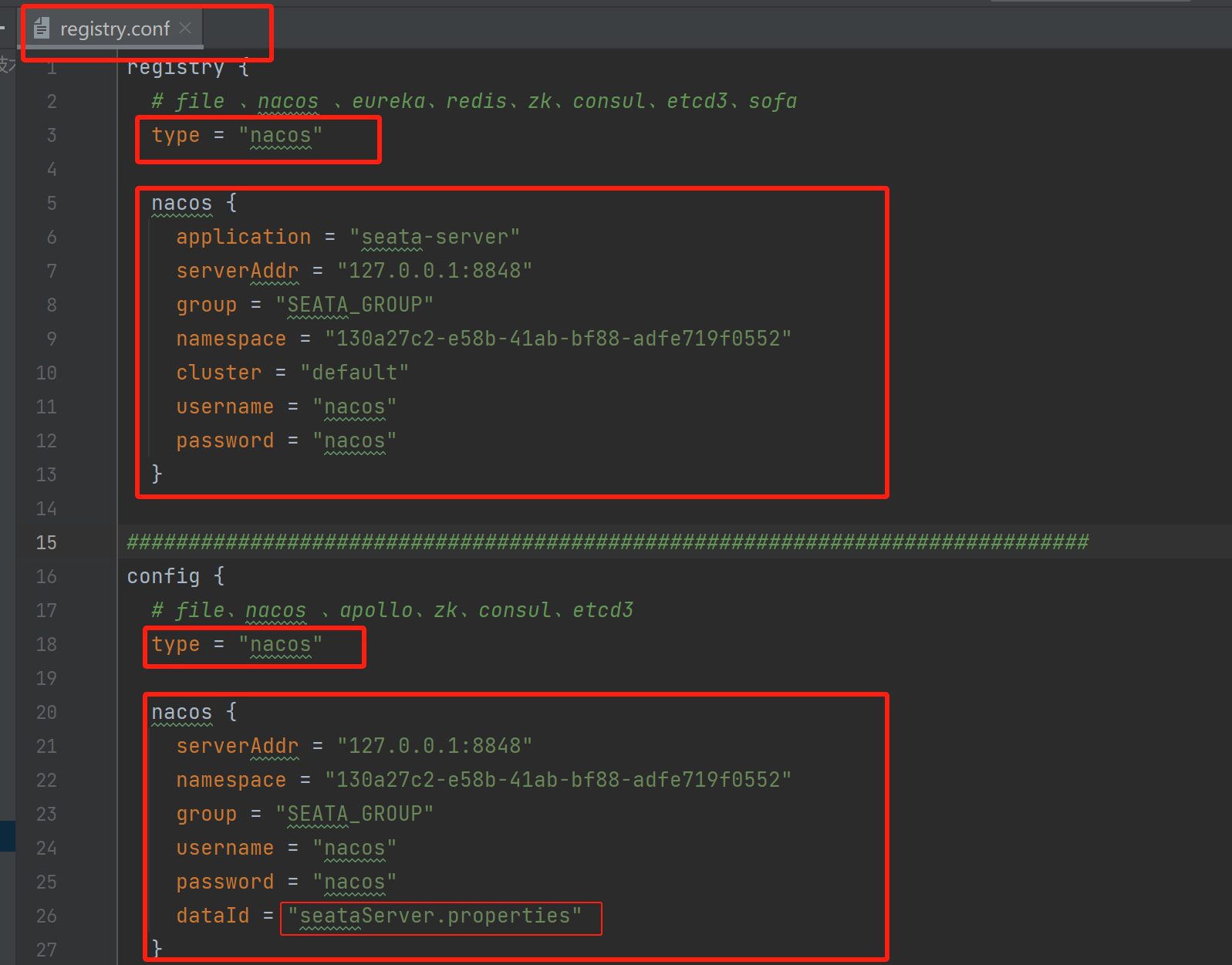
6):修改/script/config-center/config.txt配置信息:
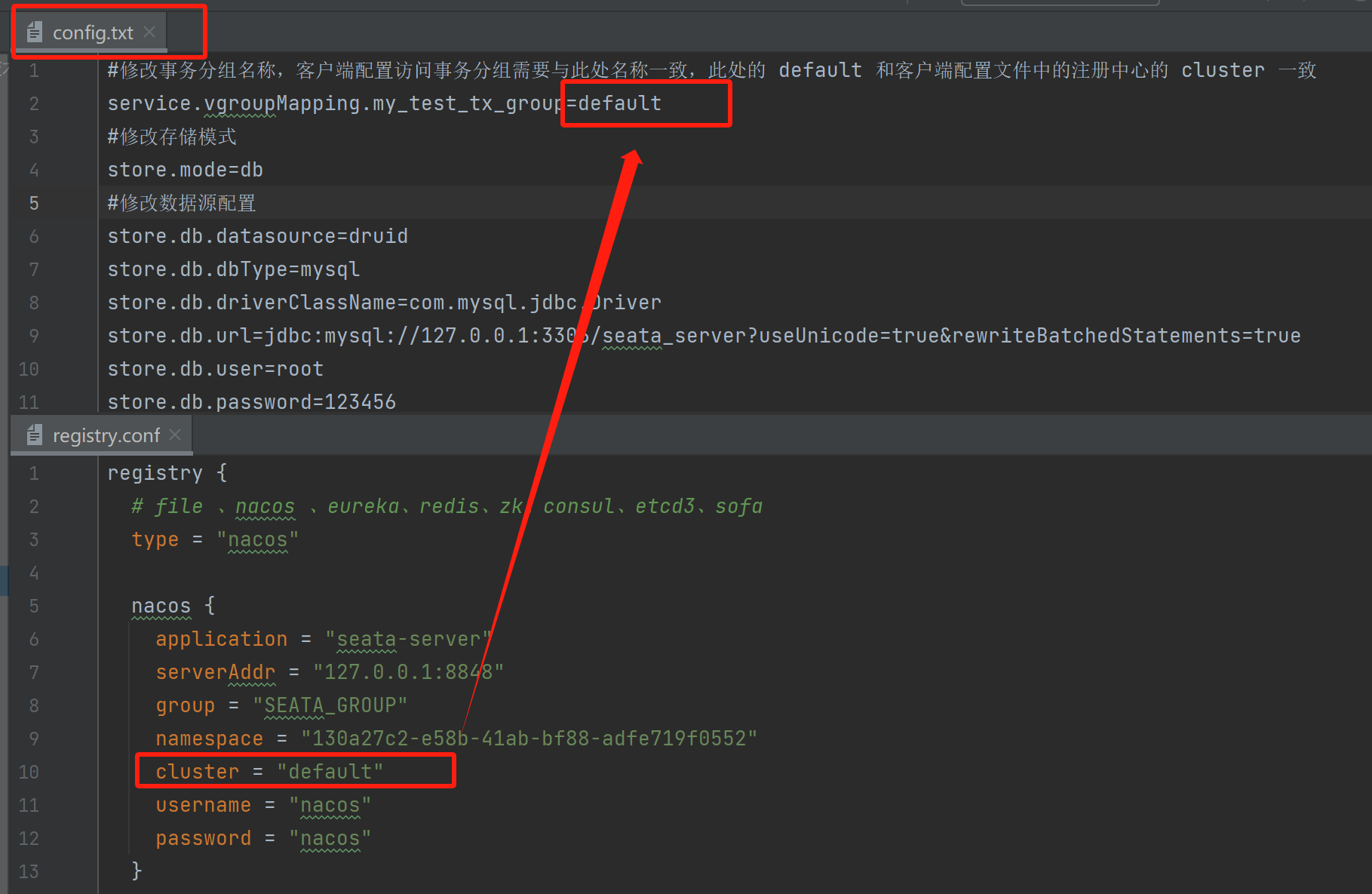
7)、配置参数同步到NACOS:
执行相应脚本:源码包路径\script\config-center\nacos
#Window下执行: sh nacos-config.sh -h localhost -p 8848 -g SEATA_GROUP -t 130a27c2-e58b-41ab-bf88-adfe719f0552 -u nacos -w nacos
8)、Seata启动:
Windows环境下:
直接双击解压目录下的bin目录下的 seata-server.bat即可完成 seata 服务的启动。
Linux 环境下:
sh ${SEATAPATH}/bin/seata-server.sh -h localhost -p 8091 -m db -n 1 -e dev
9)、Seata实现分布式事务:
添加相关依赖:

<!--Seate的客户端-->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-seata</artifactId>
</dependency>
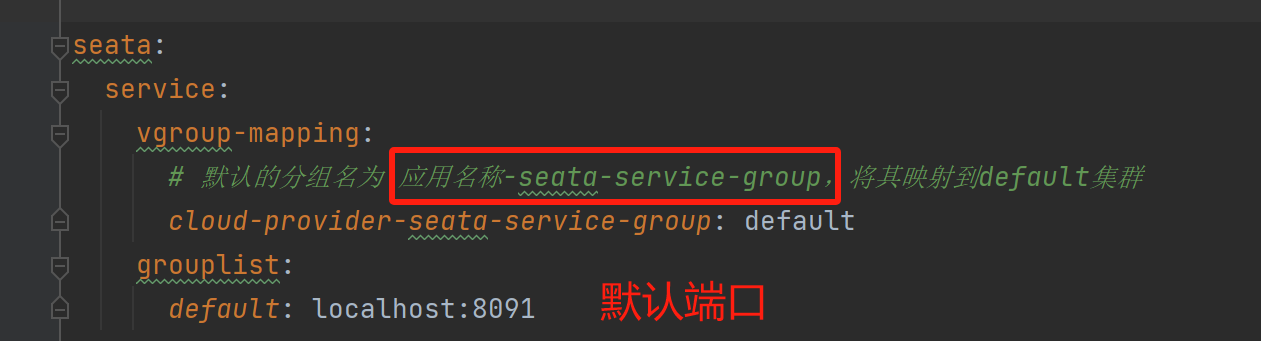
配置声明:
在相应服务连接的数据库下创建undo-log表(数据快照,分支提交回滚):
CREATE TABLE `undo_log`( `id` BIGINT(20) NOT NULL AUTO_INCREMENT, `branch_id` BIGINT(20) NOT NULL, `xid` VARCHAR(100) NOT NULL, `context` VARCHAR(128) NOT NULL, `rollback_info` LONGBLOB NOT NULL, `log_status` INT(11) NOT NULL, `log_created` DATETIME NOT NULL, `log_modified` DATETIME NOT NULL, `ext` VARCHAR(100) DEFAULT NULL, PRIMARY KEY (`id`), UNIQUE KEY `ux_undo_log` (`xid`, `branch_id`) ) ENGINE = InnoDB AUTO_INCREMENT = 1 DEFAULT CHARSET = utf8;
开启分布式事务:
在方法上添加@GlobalTransactional注解开启分布式事务:

通过在栈追踪信息中查看seata相关的包,那么说明分布式事务已经开始工作了
![]()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号