Neo4j图形存储学习笔记
一、Neo4j图数据库:
图形数据库(Graph Database)是NoSQL数据库家族中特殊的存在,用于存储丰富的关系数据。与传统的关系型数据库相比,图形数据库更适合处理具有复杂关系和网络结构的数据。Neo4j是目前最流行的图形数据库之一,它支持完整的事务处理,并采用节点与关系的方式来组织和表示数据,因此在许多领域中得到了广泛的应用:
1、社交网络分析:
社交网络是一个复杂的网络结构,其中包含各种类型的关系(例如朋友关系、关注关系等)。Neo4j可以高效地存储和查询社交网络数据,帮助分析用户行为、发现社区结构等。
2、推荐系统:
Neo4j可以用于构建推荐系统,通过分析用户行为和项目之间的关系来生成准确的推荐。例如,基于用户的历史购买记录和其他相关数据,Neo4j可以预测用户可能感兴趣的项目。
3、网络安全:
在网络安全领域,Neo4j可以用于威胁情报分析和入侵检测。它可以帮助安全团队识别和跟踪网络中的可疑活动,以及快速识别潜在的攻击模式。
4、知识图谱:
知识图谱是一种图形结构,用于表示现实世界中的概念、实体以及它们之间的关系。Neo4j可以用于构建和管理知识图谱,帮助组织和检索大量结构化信息。
5、物流和供应链管理:
在物流和供应链管理中,Neo4j可以用于跟踪和管理复杂的物流过程。它可以帮助企业了解货物的流动情况、预测潜在的延误和问题,并优化供应链性能。
二、基于Docker的Neo4j安装部署:
1、Neo4j版本与JDK版本:
|
Neo4j版本下载: |
|
|
Neo4j版本 |
JDK版本 |
|
Neo4j 3.x 版本 |
JDK8 运行环境 |
|
Neo4j 4.x 版本 |
JDK11 运行环境 |
|
Neo4j 5.x 版本 |
JDK17 运行环境 |
2、Neo4J的安装部署:
|
Docker学习: |
|
下载镜像: |
|
docker pull neo4j:3.5.22-community |
|
启动容器: |
|
docker run -d \ --name neo4j \ --restart always \ #7474:默认HTTP端口 #7687:bolt协议端口 -p 7474:7474 -p 7687:7687 \ #设置环境变量,配置账号与密码 -e "NEO4J_AUTH=neo4j/123456" \ #映射数据存储目录(/data/neo4j-data/data可自定义) -v /data/neo4j-data/data:/data \ #映射日志目录(/data/neo4j-data/logs可自定义) -v /data/neo4j-data/logs:/logs \ #映射配置文件目录(/data/neo4j-data/conf可自定义) -v /data/neo4j-data/conf:/var/lib/neo4j/conf \ #映射导入数据目录(/data/neo4j-data/import可自定义) -v /data/neo4j-data/import:/var/lib/neo4j/import \ neo4j:3.5.22-community |
|
查看日志: |
|
docker logs -f neo4j |
|
Neo4J访问(neo4j/123456): |
|
http://localhost:7474/browser/ |
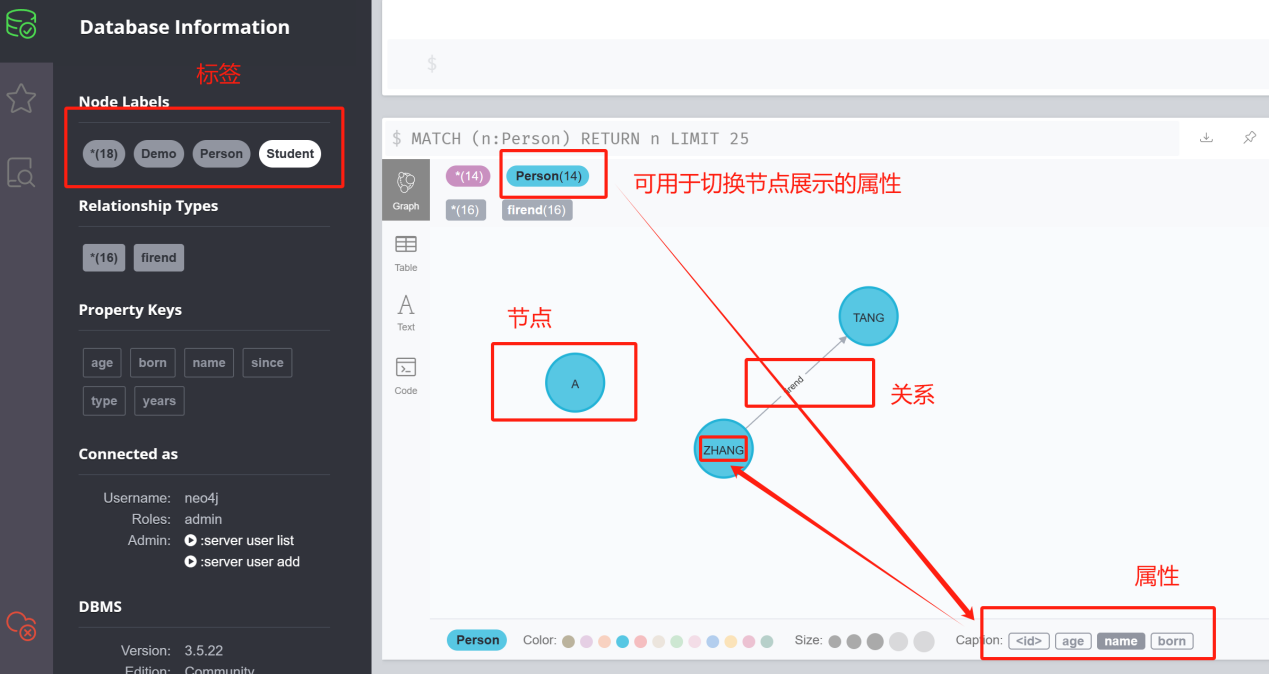
三、Neo4j基础元素:
标签、节点、关系、属性
|
基础元素 |
说明 |
|
标签(Label) |
标签用于给节点添加分类或标记,类似于传统数据库中的表。标签可以帮助我们将节点分组或分类,使得查询和操作更加高效。一个节点可以有一个或多个标签,标签也可以具有属性。 |
|
节点(Node) |
节点是图形数据库中的基本单元,用于表示实体或对象。每个节点可以包含一个或多个属性(Properties),用于描述节点的特征和属性。节点通常用圆圈或方框来表示,并通过唯一标识符来区分。 |
|
属性(Property) |
属性是节点和关系上的键值对,用于存储节点和关系的特征和属性信息。属性可以是基本数据类型(如字符串、整数、浮点数等)或复杂数据类型(如数组、日期等)。属性可以帮助我们更详细地描述节点和关系的属性,以便进行查询和分析。 |
|
关系(Relationship) |
关系用于表示节点之间的连接或关联,描述实体之间的交互和关系。关系可以有方向,即从一个节点指向另一个节点,也可以是无向的。关系还可以具有属性,用于描述关系的特征和属性。关系通常用箭头来表示,箭头的方向表示关系的方向性。 |
四、Neo4j SQL—CREATE创建操作:

1、CREATE创建:
(1)、创建节点:
|
CREATE (node_name:label_type {property1:value1,property2:value2...}) RETURN node_name; |
|
|
参数 |
说明 |
|
node_name |
节点名称,相当于一个只在当前语句生效的局部变量 |
|
label_type |
标签,代表节点的类型 |
|
property:value |
节点属性 |
|
RETURN |
表示返回该数据,可以省略 |
//创建带有name、age属性的单个节点,并返回该数据 CREATE (n:Person {name:"Iven", age:18}) RETURN n //创建多个相同标签节点 CREATE (n1:Person { age: 30 }), (n2:Person { age: 25 }); //创建多个不同标签节点 CREATE (n1:Person { age: 30 }), (n2:Student{ age: 25 });
(2)、创建关系:
|
CREATE (node_name_1:label_type_1) -[relationship_name:relationship_type {property1:value1,property2:value2...}]-> (node_name_2:label_type_2) RETURN node_name_1,relationship_name,node_name_2; |
|
|
参数 |
说明 |
|
node_name |
节点名称,相当于一个只在当前语句生效的局部变量 |
|
label_type |
标签,代表节点的类型 |
|
relationship_name |
关系名称,相当于一个只在当前语句生效的局部变量 |
|
relationship_type |
路径的关系类型,描述两个实体之间的某种关系、依赖或交互 |
|
property:value |
关系属性和值 |
|
RETURN |
表示返回该数据,可以省略 |
//创建带有name属性的两个节点,并创建相应关联关系 CREATE (n:Person{name:'ZHANG'}) -[r:firend {years:2}]-> (m:Person{name:'TANG'}) RETURN n,r,m; //对已创建的节点进行创建关联关系(先查询后创建) MATCH (n:Person{name:'Iven'}),(m:Person{name:'Tom'}) CREATE (n)-[r:firend {years:3}]->(m) RETURN n,r,m;
2、MERGE创建或更新:
|
MERGE (node_name:label_type{property1:value1,property2:value2...}) ON CREATE SET node_name.new_property_1 = value_1,node_name.new_property2 = value_2, ... ON MATCH SET node_name.existing_property = value |
|
|
以指定节点属性property:value为条件,判断该节点是否存在;不存在时,执行ON CREATE SET条件创建节点并更新相应属性,否则执行ON MATCH SET更新相应属性 |
|
|
参数 |
说明 |
|
node_name |
节点名称,相当于一个只在当前语句生效的局部变量 |
|
label_type |
标签,代表节点的类型 |
|
property:value |
节点属性,作为查询条件判断节点是否存在 |
|
ON CREATE SET |
表示创建节点时添加新属性 |
|
ON MATCH SET |
表示更新已存在节点的属性 |
//如果该节点已存在,则不会添加,返回已存在节点数据,否则返回新建节点数据 MERGE (n:Person {name:"Iven", age:18}) RETURN n //若该节点已存在,则不会添加,否则新建节点并更新相应属性 //节点不存在时,执行ON CREATE SET操作,更新name属性,新增born属性与age属性 MERGE (n:Person {name:"Iven", age:18}) ON CREATE SET n.born="1000",n.name="ZHANG" RETURN n //若该节点不存在,新建节点,新增name与age属性 //节点存在时,执行ON MATCH SET 操作,更新name属性,新增或更新born属性 MERGE (n:Person {name:"Iven", age:18}) ON MATCH SET n.born="90",n.name="ZHOU" RETURN n //若该节点已存在,执行ON MATCH SET更新操作 //若该节点不存在,执行ON CREATE SET新增操作 MERGE (n:Person {name:"ZHANG", age:18}) ON CREATE SET n.born="1000",n.name="Iven" ON MATCH SET n.born="90",n.name="ZHOU" RETURN n //判断两个节点之间是否存在关系(years=3是条件),存在则不创建关系,返回已存在 MATCH (n:Person{name:'Iven'}),(m:Person{name:'Tom'}) MERGE (n)-[r:firend {years:3}]->(m) RETURN n,r,m; //判断两个节点之间是否存在关系,存在则更新关系属性,否则创建关系并更新属性 MATCH (n:Person{name:'ZHOU'}),(m:Person{name:'Tom'}) MERGE (n)-[r:firend {years:3}]->(m) ON CREATE SET r.since = '2020' ON MATCH SET r.since= '2024',r.years=4 RETURN n,r,m;
3、Load CSV方式数据导入:
(1)、将CSV文件复制到宿主机的导入目录:
将要导入的CSV文件复制到 /data/neo4j-data/import 容器映射导入数据的目录下。确保CSV文件的路径和名称正确。
(2)、进入Neo4j容器终端:
docker exec -it neo4j bash
(3)、查看Neo4j容器内部的import路径中CSV文件是否存在:
#Neo4j容器内部的import路径 cd /var/lib/neo4j/import
(4)、进入Cypher界面执行导入数据:
cypher-shell
(5)、编写Cypher查询导入数据:
由于没有配置dbms.directories.import参数,所以需要使用全路径导入,可在neo4j.conf中进行配置
1)、创建节点:
#using periodic commit 10:每10条自动提交,防止内存溢出 #方式一:使用with headers using periodic commit 10 load csv with headers from "file:///var/lib/neo4j/import/a.csv" as line merge (:NameSpace{name:line.name,type:line.type}) #方式二:不使用with headers using periodic commit 10 load csv from "file:///var/lib/neo4j/import/a.csv" as line merge (:NameSpace{name:line[0],type:line[1]})
2)、创建关系:
using periodic commit 10 load csv from "file:///var/lib/neo4j/import/b.csv" as line match (n:NameSpace{name:line[0]}),(m:NameSpace{name:line[1]}) merge (n)-[r:firend{age:line[2]}]->(m)
(6)、Ctrl + D 组合键退出Cypher界面
4、Neo4j-Import方式数据备份、还原与导入:
Load CSV方式无法满足大数据量的业务需要,因此官方提供的Neo4j-Import工具
(1)、备份与还原数据:
官方文档:备份或还原数据库graph.db,必须关闭相应的数据库。
由于docker容器中是没办法停止neo4j进程的,因此启动新容器执行相应操作
1)、停止正在运行Neo4j容器:
docker stop neo4j
2)、启动一个带有新的容器用于数据持久化
docker run -it --rm \ -v /data/neo4j-data/data:/data \ --name neo4j-container-dump \ neo4j:3.5.22-community /bin/bash
3)、新的容器中备份数据:
bin/neo4j-admin dump --database=graph.db --to=data/20240120.dump
4)、新的容器中导入备份数据:
bin/neo4j-admin load --from=data/20240120.dump --database=graph.db --force
(2)、Neo4j-Import方式数据导入:
1)、将CSV文件复制到宿主机的导入目录:
将要导入的CSV文件复制到 /data/neo4j-data/import 容器映射导入数据的自定义目录下。确保CSV文件的路径和名称正确。(节点表:nodes.csv,关系表:relationships.csv)
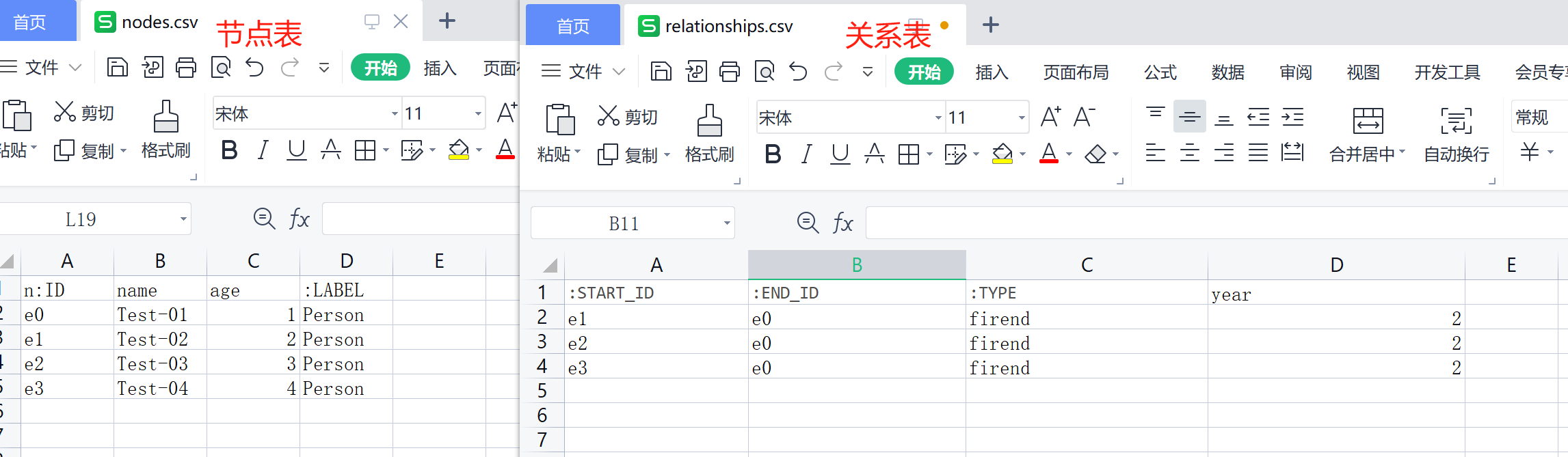
备注:
|
CSV数据表 |
说明 |
|
节点表:nodes.csv |
|
|
实体文件格式:<nodeId:ID>, <propertyName1>, <propertyName2>, ..., <:LABEL> 1、<nodeId:ID>:唯一索引:ID,用于创建关系等后续Import操作时索引到指定节点; 2、<propertyName1>:中间为节点属性,最好用英文; 3、<:LABEL>:结束为标签:LABEL不是必须的,一个节点有多个标签 |
|
|
关系表:relationships.csv |
|
|
关系文件格式:<:START_ID>, <:END_ID>, <:TYPE>,<RelationshipPropertiesName1>,...<...2> 1、<:START_ID> :关系起点节点的ID编号,必须有 2、<:END_ID>:关系结束点节点的ID编号,必须有 3、<:TYPE>:关系的类别,必须有 4、<RelationshipPropertiesName>:关系属性,非必须 |
|
2)、进入Neo4j容器终端:
docker exec -it neo4j bash
3)、导入数据
neo4j-admin import --database=graph.db --nodes=/var/lib/neo4j/import/nodes.csv --relationships=/var/lib/neo4j/import/relationships.csv

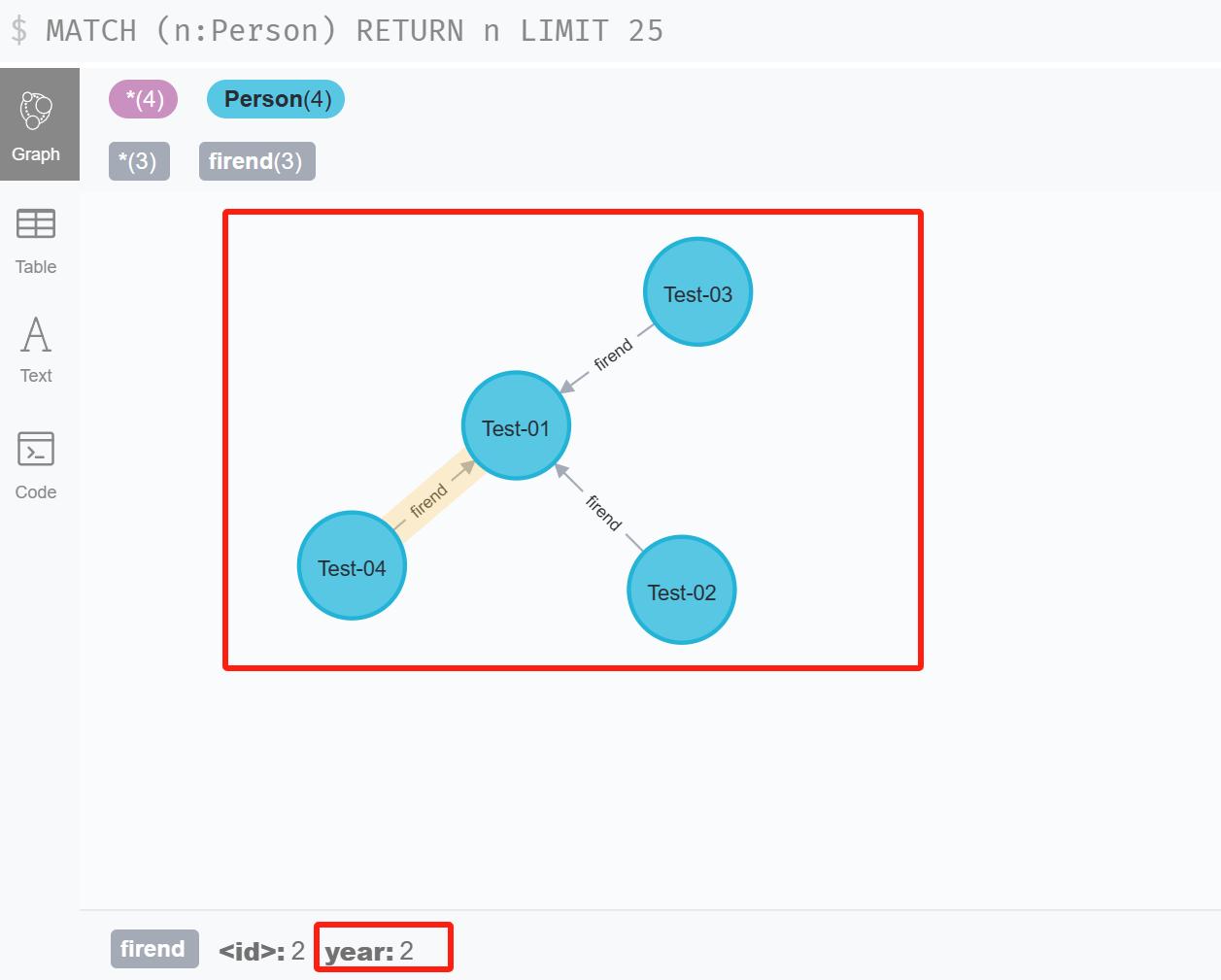
五、Neo4j SQL—MATCH查询操作:
1、MATCH查询:
|
MATCH (node_name:label_type) RETURN node_name; |
|
|
参数 |
说明 |
|
node_name |
节点名称,相当于一个只在当前语句生效的局部变量 |
|
label_type |
标签,代表节点的类型 |
|
RETURN |
表示返回该数据 |
#查询单个标签(Person)内资源信息 MATCH (n:Person) RETURN n.name #查询多个标签(Person、Animal)内资源信息 MATCH (n:Person),(m:Animal) RETURN n.name,m.type #查询标签内某节点的单个上下关系(firend)的节点 MATCH (n:Person{name:'Test-02'})-[:firend]->(m:Person) RETURN m #查询所有有关系的节点(r:即包含多个上级模型) MATCH (n)-[r]->(m) RETURN n,r,m #查询标签内所有上下关系的节点信息(r:即包含多个上级模型) MATCH (n:Animal)-[r]->(m:Person) RETURN n,m #查询标签内有上下关系的节点信息(r:即包含多个上级模型) #r*..4:匹配开始节点到结束节点不超过4条边的所有路径 MATCH (n:Animal)-[r*..4]->(m:Person) RETURN n,m #查询开始节点,最多包含2跳的关系路径中的所有节点 MATCH (n:Animal)-[r*..2]->(m) RETURN n,m #查询某标签内资源所有关联关系 MATCH (n:Person)-[r]-() RETURN n, r
2、LIMIT和SKIP限制返回结果数量,实现分页查询:
|
MATCH (node_name:label_type) RETURN node_name SKIP n LIMIT m; |
|
|
参数 |
说明 |
|
node_name |
节点名称,相当于一个只在当前语句生效的局部变量 |
|
label_type |
标签,代表节点的类型 |
|
RETURN |
表示返回该数据 |
|
n |
表示要跳过的结果集数量 |
|
m |
表示要返回的结果集数量 |
#查询单个标签内资源信息,返回10条数据 MATCH (n:Person) RETURN n LIMIT 10 #查询单个标签内资源信息,跳过10条数据 MATCH (n:Person) RETURN n SKIP 10 #查询单个标签内资源信息,分页查询,每页10条数据: MATCH (n:Person) RETURN n SKIP 0*10 LIMIT 10 //第一页 MATCH (n:Person) RETURN n SKIP 1*10 LIMIT 10 //第二页 MATCH (n:Person) RETURN n SKIP 2*10 LIMIT 10 //第三页
3、WHERE条件匹配:
|
方式一: |
|
|
MATCH (node_name:label_type) WHERE node_name.property1 = value1,node_name.property2 = value2,... RETURN node_name; |
|
|
方式二: |
|
|
MATCH (node_name:label_type{property1:value1,property2:value2,...}) RETURN node_name; |
|
|
参数 |
说明 |
|
node_name |
节点名称,相当于一个只在当前语句生效的局部变量 |
|
label_type |
标签,代表节点的类型 |
|
node_name.property |
节点属性条件 |
|
RETURN |
表示返回该数据 |
//查询标签中某个节点资源信息: MATCH (n:Person{name: 'Test-01'}) RETURN n //方式一 MATCH (n:Person) WHERE n.name = 'Test-01' RETURN n //方式二 #查询某节点的关系节点 MATCH (n:Person{name:'Test-02'})-[:firend]->(m:Person) RETURN m
4、ORDER BY排序:
|
MATCH (node_name:label_type) RETURN node_name ORDER BY node_name.property ASC|DESC |
|
|
参数 |
说明 |
|
node_name |
节点名称,相当于一个只在当前语句生效的局部变量 |
|
label_type |
标签,代表节点的类型 |
|
RETURN |
表示返回该数据 |
|
ASC |
按属性值对结果进行升序排序 |
|
DESC |
按属性值对结果进行降序排序 |
//查询结果按升序排序 MATCH (n:Person) RETURN n ORDER BY n.age ASC LIMIT 25
5、OPTIONAL MATCH执行可选的模式匹配:
|
MATCH (node_name:label_type {property:value}) OPTIONAL MATCH (node_name)-[relation:relationship_type]-(node_name2:label_type2) RETURN node_name,node_name2 |
|
|
用于从图数据库中获取与指定模式匹配的所有节点和关系。与MATCH不同的是,如果没有匹配项,OPTIONAL MATCH仍将返回结果,但是相应的变量将为NULL |
|
|
参数 |
说明 |
|
node_name |
节点名称,相当于一个只在当前语句生效的局部变量 |
|
label_type |
标签,代表节点的类型 |
|
OPTIONAL MATCH |
允许查找与指定模式匹配的数据,如果匹配失败,则返回空结果 |
|
RETURN |
表示返回该数据 |
//查询指定节点,并获取与该节点关联的所有关系节点。 //若该节点无任何关系节点,则OPTIONAL MATCH语句仍将返回结果,但是m变量将为空。 MATCH (n:Person {name: 'Test-01'}) OPTIONAL MATCH (n)-[:FRIEND]->(m) RETURN n.name, collect(m.name)
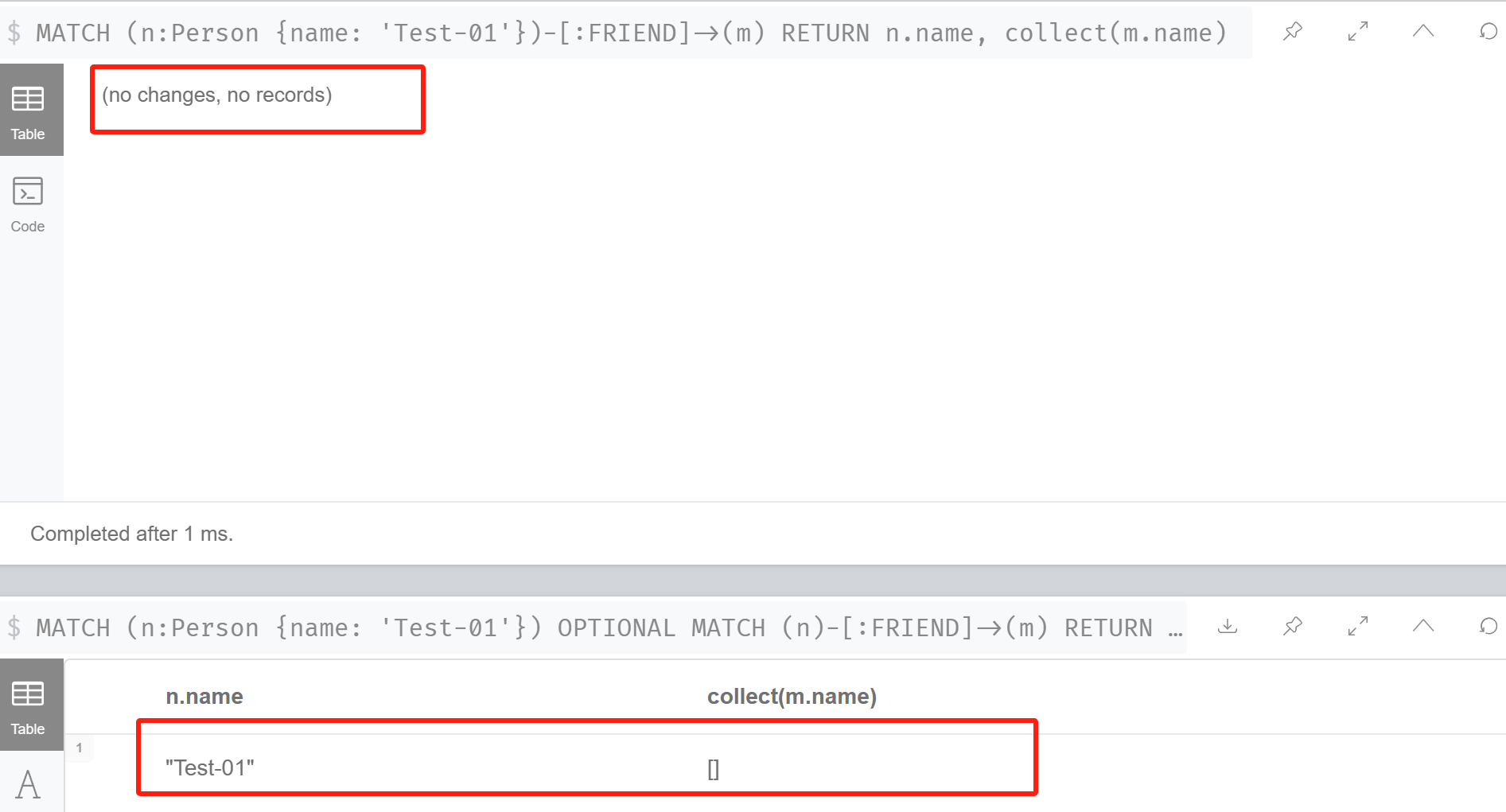
6、IN匹配给定值的集合:
|
MATCH (node_name:label_type) WHERE node_name.property IN [<Collection-of-values>] RETURN node_name; |
|
|
参数 |
说明 |
|
node_name |
节点名称,相当于一个只在当前语句生效的局部变量 |
|
label_type |
标签,代表节点的类型 |
|
node_name.property |
节点属性条件 |
|
IN [<Collection-of-values>] |
查询指定某个属性值是否存在于给定的值列表中,[给定值集合] |
|
RETURN |
表示返回该数据 |
//查询name为Test-01与Test-02的节点 MATCH (n:Person) WHERE n.name IN ['Test-01', 'Test-02'] RETURN n
7、WITH将查询结果传递到下一个查询阶段:
|
MATCH (node_name1:label_type1) WITH node_name1 WHERE node_name.property = value MATCH (node_name1) -[relationship_name:relationship_type {property1:value1,property2:value2...}]-> (node_name_2:label_type_2) RETURN node_name1, node_name_2; |
|
|
参数 |
说明 |
|
WITH |
关键字,用于将查询结果传递到下一个查询阶段 |
//将MATCH 查询数据传递到下一个查询阶段 MATCH (n:Animal)-[:firend]->(m:Person) WITH n, count(m) AS friendCount, collect(m) AS info RETURN n.type, friendCount, info //将MATCH 查询数据传递到下一个查询阶段 MATCH (n:Animal) WITH n WHERE n.type = 'a' OPTIONAL MATCH(n)-[:firend]->(m:Person) RETURN n.type, m.name
8、UNION和UNION ALL合并:
|
UNION |
|
|
MATCH (n:Label) WHERE n.property = 'value' RETURN n.property AS sameName UNION MATCH (m:Label) WHERE m.property = 'other_value' RETURN m.other_property AS sameName |
|
|
UNION ALL |
|
|
MATCH (n:Label) WHERE n.property = 'value' RETURN n.property AS sameName UNION ALL MATCH (m:Label) WHERE m.property = 'other_value' RETURN m.other_property AS sameName |
|
|
参数 |
说明 |
|
UNION |
关键字,会合并重复的结果集 |
|
UNION ALL |
关键字,不会合并重复的结果集 |
|
UNION/UNION ALL中的所有子查询都必须具有相同的列名 |
|
9、DISTINCT去重:
|
MATCH (node_name1:label_type1) RETURN DISTINCT node_name1.property; |
|
|
参数 |
说明 |
|
DISTINCT |
关键字,用于处理查询结果中存在重复数据的情况 |
六、Neo4j SQL—SET修改操作:
1、SET新增或修改匹配节点的属性:
|
MATCH (node_name:label_type {property:value}) SET node_name.property = value; |
|
|
参数 |
说明 |
|
SET |
关键字,用于新增或修改指定属性 |
//新增或修改属性 MATCH (n:Animal{type:'cat'}) SET n.age = 2
2、REMOVE删除匹配节点的指定属性:
|
MATCH (node_name:label_type {property:value}) REMOVE node_name.property = value; |
|
|
参数 |
说明 |
|
REMOVE |
关键字,用于删除匹配节点的指定属性 |
//删除指定属性 MATCH (n:Animal{type:'cat'}) REMOVE n.age
七、Neo4j SQL—DELETE删除操作:
|
MATCH (node_name:label_type {property:value}) DELETE node_name; |
|
|
参数 |
说明 |
|
DELETE |
关键字,用于删除不存在关系的节点 |
//删除指定节点(该节点不存在其他关系) MATCH (n:Animal{type:'tiger'}) DELETE n //删除指定节点及其连接所有关系 MATCH (n:Animal{type:'tiger'}) OPTIONAL MATCH (n)-[r]-() DELETE n, r; //删除两节点的指定关系 MATCH (m:Animal{name:'cat'})-[r]->(n:Person{name:'Test-02'}) DELETE r
八、Neo4j SQL—函数:
|
常用函数 |
|
|
函数 |
说明 |
|
COLLECT() |
将查询结果整合成一个集合 |
|
COUNT() |
计算指定表达式的行数 |
|
SUM() |
计算指定表达式的总和 |
|
AVG() |
计算指定表达式的平均值 |
|
MIN() |
找到指定表达式的最小值 |
|
MAX() |
找到指定表达式的最大值 |
|
TOUPPER()/UPPER() |
将字符串转换为大写 |
|
TOLOWER()/LOWER() |
将字符串转换为小写 |
|
TRIM() |
去除字符串两端的空格 |
|
SUBSTRING() |
返回字符串的子串 |
|
REPLACE() |
替换字符串中的指定部分 |
|
ABS() |
返回数值的绝对值 |
|
CEIL() |
向上取整 |
|
FLOOR() |
向下取整 |
|
ROUND() |
四舍五入 |
|
LABELS() |
返回标签 |
九、SpringBoot整合Neo4j:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号