3、数组、集合、Lambda、Stream与Optional类
一、数组:
数组保存在JVM堆内存中
1、数组的创建:
(1)、一维数组创建方式一:
//一维数组方式一 Integer[] array01 = {1,2,3};
System.out.println("一维数组创建方式一"); System.out.println("数组长度:"+array01.length); for (int i: array01) { System.out.println("Array01["+(i-1)+"]="+array01[i-1]); }
(2)、一维数组创建方式二:
//一维数组方式二 Integer[] array02 = new Integer[2]; array02[0] = 1; array02[1] = 2;
System.out.println("一维数组创建方式二"); System.out.println("数组长度:"+array02.length); for (int i: array02) { System.out.println("Array02["+(i-1)+"]="+array02[i-1]); }
(3)、一维数组创建方式三:
//一维数组方式三 Integer[] array03 = new Integer[]{1,2,3};
System.out.println("一维数组创建方式三"); System.out.println("数组长度:"+array03.length); for (int i: array03) { System.out.println("Array03["+(i-1)+"]="+array03[i-1]); }
(4)、二维数组同理:
//二维数组同理 Integer[][] array04 = {{1,2},{3,4}}; System.out.println("二维数组创建方式同理"); System.out.println("二维数组长度:"+array04.length); for (int i = 0; i < array04.length; i++) { for (int j = 0; j < array04[i].length; j++) { System.out.println("Array04["+(i)+"]"+"["+(j)+"]="+array04[i][j]); } } Integer[][] array05 = new Integer[][]{{1,2},{3,4}}; for (int i = 0; i < array05.length; i++) { for (int j = 0; j < array05[i].length; j++) { System.out.println("Array05["+(i)+"]"+"["+(j)+"]="+array05[i][j]); } } Integer[][] array06 = new Integer[2][2]; array06[0][0] = 1; array06[0][1] = 2; array06[1][0] = 3; array06[1][1] = 4; for (int i = 0; i < array06.length; i++) { for (int j = 0; j < array06[i].length; j++) { System.out.println("Array06["+(i)+"]"+"["+(j)+"]="+array06[i][j]); } }
2、java.util.Arrays工具类详解:
(1)、Arrays.equals():判断两个数组是否相等
/** * 1、boolean equals(int[] a,int[] b):判断两个数组是否相等。 * @Return false * */ int[] arr1 = new int[]{1,2,3,4}; int[] arr2 = new int[]{1,3,2,4}; boolean isEquals = Arrays.equals(arr1, arr2); System.out.println(isEquals);
(2)、Arrays.toString():输出数组信息
/** * 2.String toString(int[] a):输出数组信息。 * @Return [1, 2, 3, 4] * */ int[] arr1 = new int[]{1,2,3,4}; System.out.println(Arrays.toString(arr1));
(3)、Arrays.fill():将指定值填充到数组中
/** * 3、 * void fill(int[] a,int val):将指定值填充到数组中的每一个元素。 * void fill(int[] a,fromIndex,toIndex,int val):将指定值填充的数组中从fromIndex(包含)到toIndex(不包含)范围内的每一个元素。 * */ int[] arr1 = new int[]{1,2,3,4}; Arrays.fill(arr1,10); //toPrint->[10, 10, 10, 10] System.out.println(Arrays.toString(arr1)); Arrays.fill(arr1,1,3,0); //toPrint->[10, 0, 0, 10] System.out.println(Arrays.toString(arr1));
(4)、Arrays.sort():对数组进行升序排序
/** * 4、 * void sort(int[] a):对数组进行升序排序。 * void sort(int[] a,fromIndex,toIndex):对数组从fromIndex(包含)到toIndex(不包含)范围内进行部分排序。 * 注: * sort() 方法使用快速排序适用于少量数据的排序,parallelSort() 方法使用并行排序适用于大量数据的升序排序 * */ int[] arr1 = new int[]{1,3,2,4}; Arrays.sort(arr1); //toPrint->[1, 2, 3, 4] System.out.println(Arrays.toString(arr1)); int[] arr2 = new int[]{1,3,2,7,4}; Arrays.sort(arr2,1,3); //toPrint->[1, 2, 3, 7, 4] System.out.println(Arrays.toString(arr2));
(5)、Arrays.binarySearch():二分查找搜索数组中指定值的位置
/** * 5.int binarySearch(int[] a,int key):使用二分查找搜索指定的值,找到了则返回该值在数组中的下标,没找到则返回一个负数 * @Return 8 * */ int[] arr3 = new int[]{-98,-34,2,34,54,66,79,105,210,333}; int index = Arrays.binarySearch(arr3, 210); if(index >= 0){ System.out.println(index); }else{ System.out.println("未找到"); }
(6)、Arrays.asList():将数组转化成List集合的方法
注: 参考自
1)、该方法适用于对象型数据的数组(String、Integer...),不建议使用于基本数据类型的数组(byte,short,int,long,float,double,boolean);
2)、该方法将数组与List列表链接起来:当更新其一个时,另一个自动更新;
3)、该方法得到的List的长度是不可改变的,添加或删除一个元素时(add()、remove()、clear()等方法)程序就会抛出异常;
总结:
如果你的List只是用来遍历,就用Arrays.asList()。如果你的List还要添加或删除元素,还是乖乖地new一个java.util.ArrayList,然后一个一个的添加元素。
/** * 6.List<T> asList(T... a):将数组转化成List集合的方法,此方法得到的List的长度是不可改变的,添加或删除一个元素时程序就会抛出异常 * */ String[] arr4 = {"a","b","c","d","e","f","g"}; List<String> list = Arrays.asList(arr4); //list.add("k"); //抛出异常:java.lang.UnsupportedOperationException for (String i: list ) { System.out.println(i); }
3、八大排序算法之一:冒泡排序法
/** * 冒泡排序: * 八大排序算法之一 * 1、比较数组中两个相邻的元素,如果第一个数比第二个数大,就交换位置(从小到排) * 2、每次比较,都会产生一个最大,或最小的数 * 3、下一轮则可以少一次排序 * 4、依次循环,直至结束 * */ public static void BubbleSort(int[] array){ for (int i = 0; i < array.length-1; i++){ //每个数字需要循环比较n-1次,随着数据被排序,未匹配数字越来越少,与外层循环形成反比 公式为:length-i-1,没匹配到一个数,减少一次循环 for (int j = 0; j < array.length-i-1; j++){ //每次将数据进行比较,将最大值或最小值放入到比较数中 //如果第一个数大于第二个数,将交换位置,比较数永远是最大数 if (array [j] > array [j+1]){ //将前一个元素,放入到临时位置 int temp = array [j]; //将后一个元素,赋值给前一个元素,进行替换 array [j] = array[j+1]; //在将前一个元素的值,替换到后一个元素中,形成交换 array [j+1] = temp; } } } System.out.println("排序后数组为:"+ Arrays.toString(array)); }
二、集合:
1、集合详解:
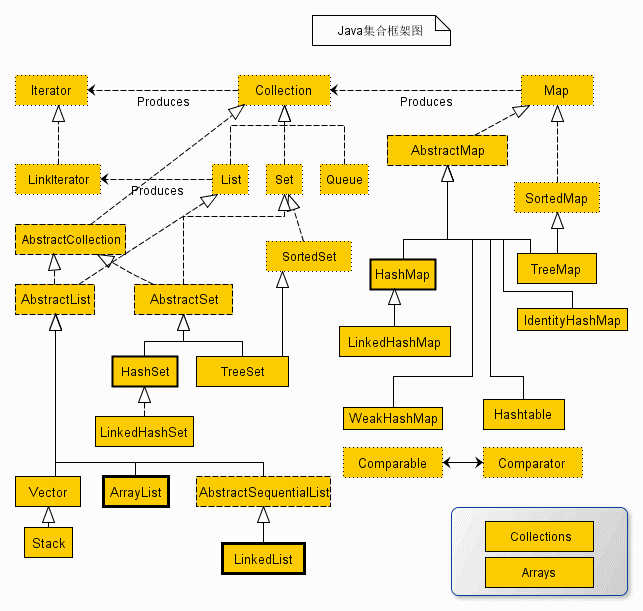
(1)、Collection父接口:
单列集合,以单个方式存储元素对象
- 增:add(Object obj)
- 删:remove(int index) / remove(Object obj)
- 改:set(int index, Object ele)
- 查:get(int index)
1、List接口:
存储有序可重复的数据。常见的List接口的实现类有ArrayList、LinkedList、CopyOnWriteArrayList和Vector。
(1)、ArrayList:
1)、特点:
- 底层数组,检索效率高、增删效率低
- 初始化容量默认10,默认的扩容倍数1.5(即每次扩容容量增加 50%)
- 非线程安全的
2)、底层分析:
数组机制:
- 由于数组是一段连续的内存空间,为了保证数组的连续性,当要在某一索引处进行插入或删除一个元素时,需要将该索引后的所有元素都后移或前移一个单位,故ArrayList检索效率高、增删效率低
扩容机制:
- 底层初始容量为10,容量不足时,会触发扩容
- 扩容策略是通过 grow() 方法来实现的,默认的扩容倍数1.5,即它会将当前容量增加 50%
- 每次扩容都会底层创建一个新的更大容量的数组,然后将原数组中的元素复制到新数组中,最后再插入新的数据
- 为提高效率,减少后续的扩容次数,可以在创建 ArrayList 时指定初始容量,例如 ArrayList<Integer> list = new ArrayList<>(20)
|
如果你向一个初始容量为 10 的 ArrayList 中插入 20 个元素,扩容的过程如下 |
|
一、初始状态:
二、第一次扩容:
三、第二次扩容:
总结:在插入 20 个元素的过程中,ArrayList 总共进行了两次扩容操作。 |

3)、使用场景:
当需要快速随机访问元素且插入和删除操作不频繁时
List<String> arrayList = new ArrayList<>(); arrayList.add("Apple"); arrayList.add("Banana"); String fruit = arrayList.get(0); // 快速随机访问
(2)、LinkedList:
1)、特点:
- 底层双向链表,检索效率低、增删效率高
-
非线程安全的
2)、底层分析:
- LinkedList 没有像 ArrayList 那样的扩容机制,它通过动态的节点连接来管理元素,每次插入操作只需调整指针,而不需要重新分配和复制整个数据结构
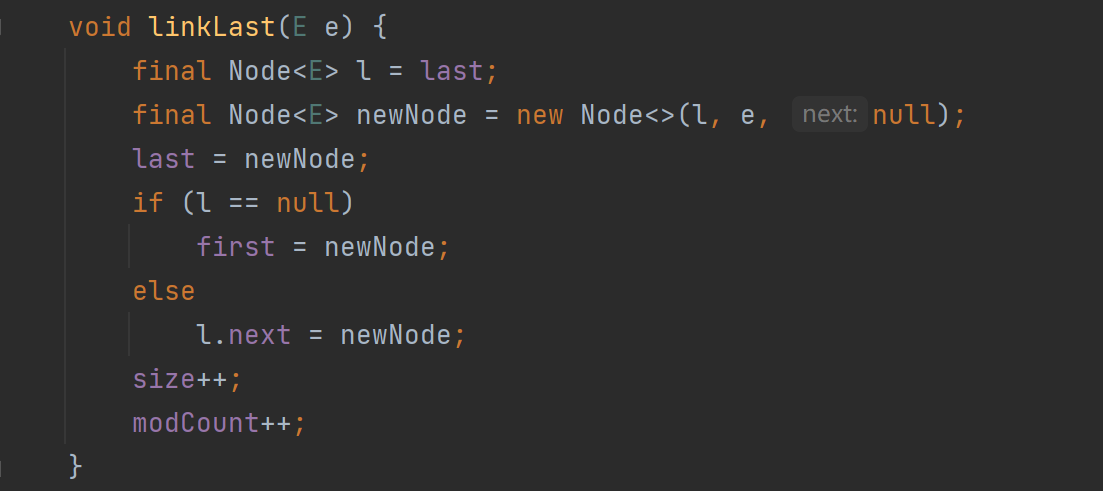
3)、使用场景:
当需要频繁插入和删除元素时,尤其是在列表两端
LinkedList<String> linkedList = new LinkedList<>(); linkedList.add("默认在链表末尾添加一个元素"); linkedList.addFirst("在链表开头添加一个元素"); // 快速插入到列表开头 linkedList.addLast("在链表末尾添加一个元素");
(3)、CopyOnWriteArrayList:
1)、特点:
- 底层采用写时复制机制
- 线程安全
2)、底层分析:
- 当需要对 CopyOnWriteArrayList 进行写操作(如添加或修改元素)时,先将原有的集合进行复制,然后对新的副本进行修改操作,最后将修改后的副本替换原有的集合,这种替换是原子操作(依赖于volatile 关键字和内部实现机制),确保了其他线程在替换过程中仍然可以安全地进行读取操作,保证了读写的并发性。由于每次写操作都会创建一个新的副本,所以CopyOnWriteArrayList占用的内存较大,需要根据具体场景进行权衡。
3)、使用场景:
由于每次写操作都会复制整个集合,因此CopyOnWriteArrayList的写操作性能较低,适用于读操作远多于写操作并且需要线程安全的场景
CopyOnWriteArrayList<String> copyOnWriteArrayList = new CopyOnWriteArrayList<>(); copyOnWriteArrayList.add("Apple");
(4)、Vector:
- 底层数组,作为List接口的古老实现类;线程安全的,效率低;底层都创建了长度为10的数组。在扩容方面,默认扩容为原来的数组长度的2倍。
- 尽管 Vector 提供了线程安全的操作,但由于其同步操作可能导致性能下降,并且在 Java 2 平台 Collections Framework 引入后,更推荐使用非同步的 ArrayList(通过 Collections.synchronizedList 方法得到线程安全的 List)或者并发包中的 CopyOnWriteArrayList 来替代 Vector
2、Set接口:
存储无序不可重复的数据。常见的Set接口的实现类有HashSet、TreeSet和LinkedHashSet。
(1)、HashSet:
- 底层使用 HashMap实现存储, HashSet封装了一系列HashMap的方法。具体来说,HashSet 的元素被存储为 HashMap 的键,而对应的值则是一个固定的占位对象(比如 PRESENT = new Object()),所有元素共享同一个值
- 适合需要快速查找、插入和删除元素的场景,不关心元素顺序,允许存储 null 元素(只能有一个 null 元素)
- 非线程安全的
(2)、TreeSet:
- 基于红黑树(Red-Black Tree)实现
- 适合需要对元素进行排序的场景,有序访问元素,不允许存储 null 元素
- 非线程安全的
(3)、LinkedHashSet:
- 基于哈希表(HashMap)来保存集合元素,同时使用一个双向链表来维护元素的插入顺序
- 适合需要保持元素插入顺序的场景,同时需要较快的查找操作,允许存储 null 元素
- 非线程安全的
(2)、Map父接口:
双列数据,以键值对key-value方式存储元素对象
存储无序不可重复的数据。常见的Map接口的实现类有HashMap、TreeMap、LinkedHashMap、ConcurrentHashMap。
- 添加:put(Object key,Object value)
- 删除:remove(Object key)
- 修改:put(Object key,Object value)
- 查询:get(Object key)
1、HashMap:
(1)、特点:
- 底层jdk7及之前是数组与单向链表的结合体,jdk8是数组、单向链表与红黑树的结合体
- 初始化容量16,默认加载因子是0.75,当达到75%开始扩容,扩容为原容量的2倍数
- 允许存储null的key和value
- 非线程安全的
(2)、底层分析:
扩容机制:
- 在创建时可以指定底层数组初始容量(默认16)和加载因子(默认0.75),当存储的元素数量达到容量75%时,就会触发扩容操作,扩容为原容量的2倍数
- 每次扩容都会底层创建一个新的、容量是原来的两倍的数组,所有的元素会被重新计算哈希值(调用hashcode()得到key的哈希值),并放入新的数组中的新位置(哈希值进行取模(通常是数组的长度)映射到数组上的索引)。存储时,如果出现hash值相同的key,此时有两种情况。
a. 如果key相同,则覆盖原始值;
b. 如果key不同(出现冲突),则将当前的key-value放入链表或红黑树中
- 当链表长度大于阈值(默认为8) 时并且数组长度达到64时,将链表转化为红黑树,以减少搜索时间。
- 扩容resize( ) 时,如果红黑树拆分成的树的结点数小于等于临界值6个,则退化成链表
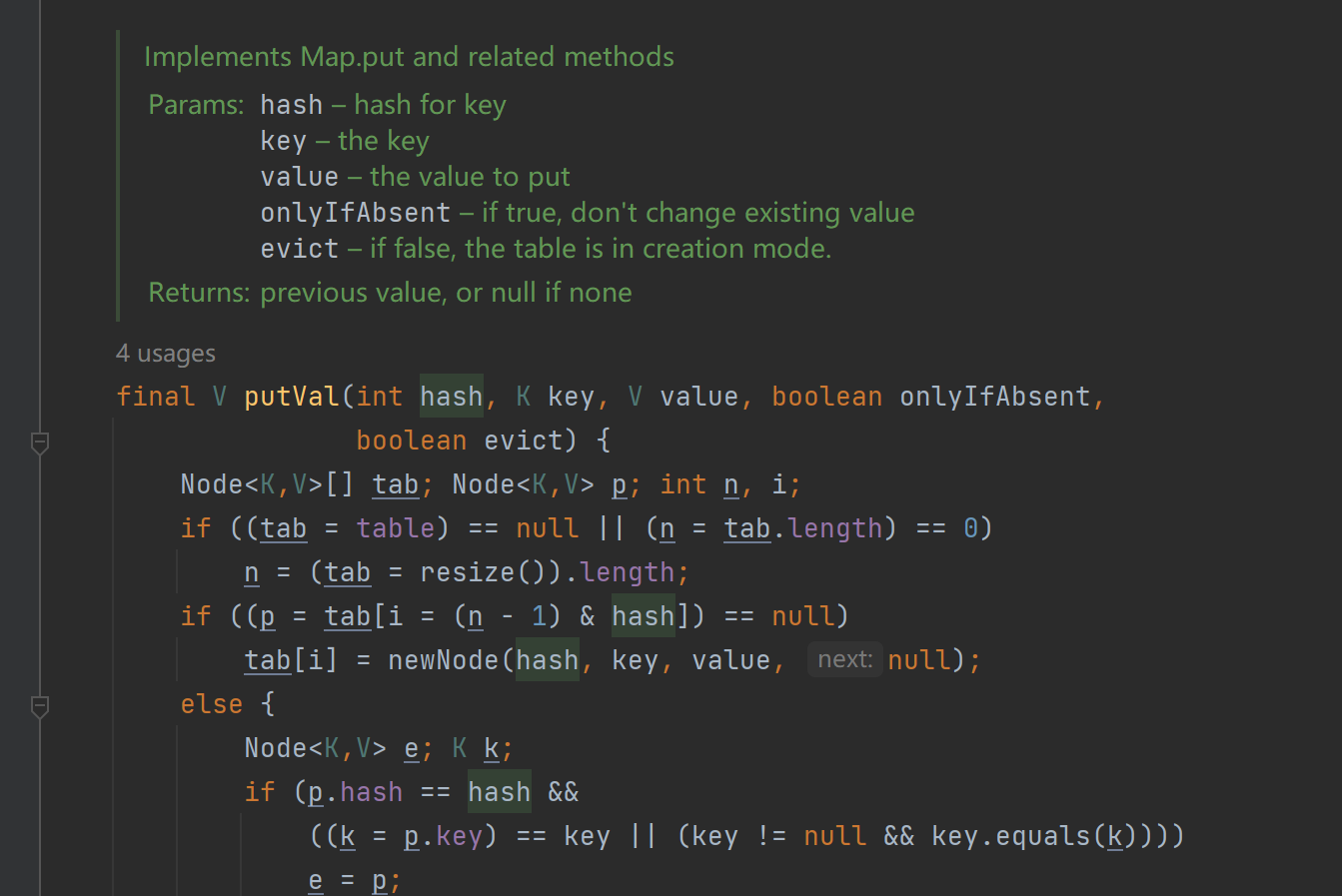
(3)、使用场景:
适合快速存取且不关心顺序的场景
Map<String, Integer> hashMap = new HashMap<>(); hashMap.put("Apple", 1); int count = hashMap.get("Apple"); // 快速查找
2、TreeMap:
- 底层基于红黑树
- 按键的自然顺序或自定义比较器顺序排序,提供有序的键值对存储
- 适合需要键排序的场景
- 非线程安全的
3、LinkedHashMap:
- 底层基于HashMap与双向链表实现,每个元素不仅包含了键值对数据本身,还包含了指向前一个和后一个元素的指针
- 适合需要维护插入顺序或访问顺序的场景
- 非线程安全的
4、ConcurrentHashMap:
- ConcurrentHashMap是一种线程安全的高效Map集合,JDK7与JDK8中做了很多调整。
(1)、在JDK7中:
ConcurrentHashMap底层采用是Segment分段数组+单向链表实现,Segment数组的大小默认为16,一旦初始化之后中间不可扩容。每个Segment都类似于一个小的HashMap,可以挂载一个可扩容的HashEntry数组用来存储具体的元素,如果HashEntry数组中存储的元素发生hash冲突,则可以采用单向链表方式解决。其插入与删除的原理是底层调用hashcode()得到key的哈希值,在经过哈希算法将其转换成相应segment数组下标,结合equals()方法来判断在对应segment分段下hashEntry数组中数据是否已经存在,在进行操作hashEntry数组中的数据之前,会先判断当前segment对应下标位置是否有线程进行操作,为了线程安全使用的是ReentrantLock可重入锁进行加锁,如果需要获取锁则会使用CAS自旋锁进行尝试
(2)、在JDK8中:
ConcurrentHashMap做了较大的优化,首先是它的数据结构与JDK1.8的hashMap数据结构完全一致,底层放弃了Segment分段的臃肿设计,采用是数组+单向链表与红黑树结合体,通过更轻量级的Node + CAS + Synchronized方式来保证集合的并发安全,synchronized只用锁定当前链表或红黑二叉树的首节点,这样的话只要hash不冲突,就不会产生并发 , 效率得到较大提升
- 适合高并发环境下的使用
5、Hashtable:
- 底层实现基于一个哈希表数组和链表。它使用哈希码来确定存储桶位置,并通过链表解决哈希冲突
- 线程安全的
- 由于 Hashtable 的方法是同步的,因此在多线程环境下使用时,不需要额外的同步措施,可以确保线程安全,但是,在并发量大时可能会导致性能瓶颈,因此,通常推荐使用ConcurrentHashMap
-
HashTable不能存储null的key和value,否则报空指针异常
(3)、总结:
选择 List 实现:
- ArrayList:适合频繁的随机访问。
- LinkedList:适合频繁的插入和删除操作,尤其是在列表中间或两端。
- CopyOnWriteArrayList:适合读操作远多于写操作且需要线程安全的场景。
选择 Map 实现:
- HashMap:适合快速存取且不关心顺序的场景。
- LinkedHashMap:适合需要维护插入顺序或访问顺序的场景。
- TreeMap:适合需要键排序的场景。
- ConcurrentHashMap:适合高并发环境下的使用。
2、java.util.Collections工具类详解:
Collections类是Java中针对集合类的一个工具类,其中提供一系列静态方法。
常用静态方法:
(1)、sort():对List集合中的元素默认进行升序排序
/** * 1、sort():对List集合中的元素默认进行升序排序 * 注: * 集合指定的泛型T必须实现Comparable<? super T>接口 * */ public static void sortDemo(){ List<Integer> list = new ArrayList<>(); list.add(1); list.add(5); list.add(2); list.add(4); list.add(3); //默认升序排序 Collections.sort(list); System.out.println(list); //toPrint->[1, 2, 3, 4, 5] //降序排序,Collections.reverseOrder():反向比较器 Collections.sort(list,Collections.reverseOrder()); System.out.println(list); //toPrint->[5, 4, 3, 2, 1] }
(2)、reverse():反转List集合中的元素
/** * 2、reverse():反转List集合中的元素 * */ public static void reverseDemo(){ List<Integer> list = new ArrayList<>(); list.add(1); list.add(5); list.add(2); list.add(4); list.add(3); //默认升序排序 Collections.sort(list); System.out.println(list); //toPrint->[1, 2, 3, 4, 5] //反转List集合元素 Collections.reverse(list); System.out.println(list); //toPrint->[5, 4, 3, 2, 1] }
(3)、shuffle():随机打乱List集合中元素的位置
/** * 3、shuffle():随机打乱List集合中元素的位置 * */ public static void shuffleDemo(){ List<Integer> list = new ArrayList<>(); list.add(1); list.add(5); list.add(2); list.add(4); list.add(3); //默认升序排序 Collections.sort(list); System.out.println(list); //toPrint->[1, 2, 3, 4, 5] //随机打乱位置 Collections.shuffle(list); System.out.println(list); //toPrint->[2, 4, 3, 1, 5](随机) }
(4)、copy():复制并覆盖相应List集合中索引的元素
/** * 4、copy():复制并覆盖相应List集合中索引的元素 * 注: * (1)、第一个参数是目的集合,第二个参数是源集合 * (2)、目的集合必须声明集合大小,即目的集合要等于或者大于源集合的元素的个数。否则报下标界的异常(java.lang.IndexOutOfBoundsException)。 * */ public static void copyDemo(){ List<Integer> list = new ArrayList<>(); list.add(1); list.add(5); list.add(2); list.add(4); list.add(3); System.out.println(list); //toPrint->[1, 2, 3, 4, 5] //copy():复制并覆盖相应List集合中索引的元素,必须指定目的集合大小 //方式一、初始化指定List的大小 List<Integer> list1 = new ArrayList<>(Arrays.asList(new Integer[list.size()])); Collections.copy(list1 , list); System.out.println(list1); //toPrint->[1, 2, 3, 4, 5] //方式二、Collections.addAll()方法将所有指定的元素添加到指定的集合中,从而指定List的大小 List<Integer> list2 = new ArrayList<>(); Collections.addAll(list2,new Integer[list.size()]); Collections.copy(list2 , list); System.out.println(list2); //toPrint->[1, 2, 3, 4, 5] }
(5)、max()/min():返回集合中最大/小的元素
/** * 5、max()/min():返回集合中最大/小的元素 * */ public static void sizeDemo(){ List<Integer> list = new ArrayList<>(); list.add(1); list.add(5); list.add(2); list.add(4); list.add(3); System.out.println(list); //toPrint->[1, 2, 3, 4, 5] System.out.println("集合中最大元素:"+Collections.max(list)); //toPrint->集合中最大元素:5 System.out.println("集合中最小元素:"+Collections.min(list)); //toPrint->集合中最小元素:1 }
三、Java函数式操作:
1、Lambda、方法引用、stream与Optional详解:
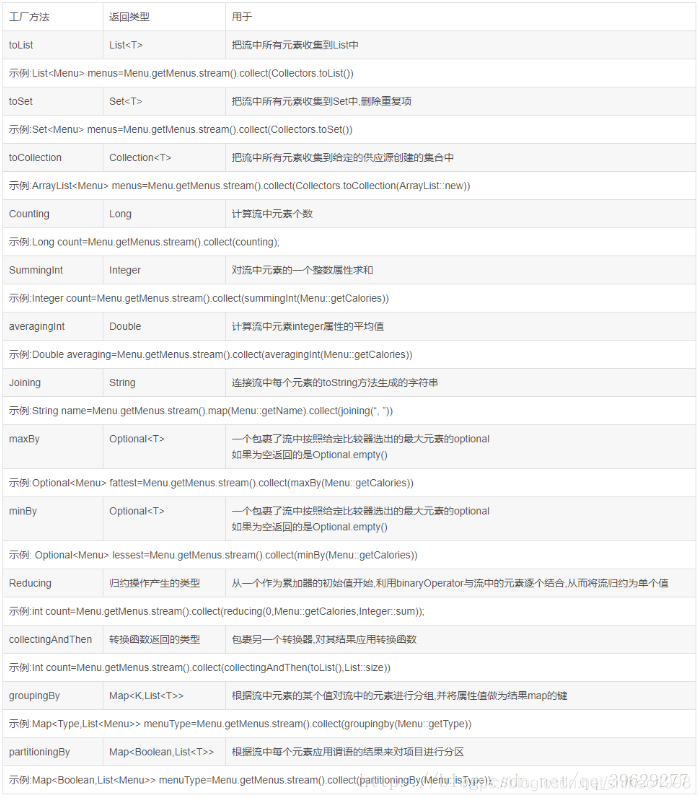
2、java.util.stream.Collectors相关详解:
3、匿名内部类与Lambda表达式的区别:
/** * 比较匿名内部类与lambda表达式的区别: * */ public static void compareToBoth(){ //匿名内部类形式创建线程 new Thread(new Runnable() { @Override public void run() { System.out.println(Thread.currentThread().getName()); } }).start(); //lambda表达式创建线程 new Thread( () -> System.out.println(Thread.currentThread().getName()) ).start(); }
4、接口与函数式接口:
(1)、接口详解:
1)、JDK8前--->接口中只有常量与抽象方法
2)、JDK8--->接口中除了常量与抽象方法外,还有默认方法(default)和静态方法(static)
3)、JDK9--->接口中除了常量、抽象方法、默认方法(default)和静态方法(static)外,还有私有方法(private)
(2)、函数式接口详解:
1)、定义:有且仅有一个抽象方法,但是可以有多个非抽象方法的接口
2)、函数式接口可以被隐式转换为 lambda 表达式
3)、函数式接口一般会加上@FunctionalInterface:主要用于编译级错误检查,当接口不符合函数式接口定义的时候,编译器会报错
/** * 函数式接口(Functional Interface)就是一个有且仅有一个抽象方法,但是可以有多个非抽象方法的接口 * @FunctionalInterface:主要用于编译级错误检查,加上该注解,当接口不符合函数式接口定义的时候,编译器会报错 */ @FunctionalInterface interface LamTest { void demo01(String t); static void demo02() { System.out.println("接口说明:\n" + " 1、JDK8前--->接口中只有常量与抽象方法\n" + " 2、JDK8--->接口中除了常量与抽象方法外,还有默认方法(default)和静态方法(static)\n" + " 3、JDK9--->接口中除了常量、抽象方法、默认方法(default)和静态方法(static)外,还有私有方法(private)\n"); } } class LamTestImp implements LamTest { @Override public void demo01(String t){ System.out.println(t); } }
5、Consumer、Supplier、Predicate与Function函数式接口的区别:
Consumer(消费型),Supplier(供给型)、Predicate(判断型)与Function(转换型)几个函数式接口都处于java.util.function包下
(1)、Consumer(消费型):
1)、源码:
@FunctionalInterface public interface Consumer<T> { void accept(T t); default Consumer<T> andThen(Consumer<? super T> after) { Objects.requireNonNull(after); return (T t) -> { accept(t); after.accept(t); }; } }
2)、使用:
Consumer对应抽象方法:accpet
Consumer<Integer> consumer=new Consumer<Integer>() { @Override public void accept(Integer integer) { System.out.println(integer); } }; consumer.accept(1); }
3)、Consumer总结:
Consumer接口是一个消费型的接口,只要实现它的accept方法,就能作为消费者来输出信息。
lambda、方法引用都可以是一个Consumer类型,因此他们可以作为forEach的参数,用来协助Stream输出信息。
Consumer还有很多变种,例如IntConsumer、DoubleConsumer与LongConsumer等,归根结底,这些变种其实只是指定了Consumer中的泛型而已,方法上并无变化。
(2)、Supplier(供给型):
1)、源码:
@FunctionalInterface public interface Supplier<T> { T get(); }
2)、使用:
Supplier对应抽象方法:get
Supplier<Double> supplier=()->new Random().nextDouble(); //当然也可以使用方法引用 Supplier<Double> supplier1= Math::random; System.out.println(supplier.get());
3)、Supplier总结:
Supplier是一个供给型的接口,其中的get方法用于返回一个值。
Supplier也有很多的变种,例如IntSupplier、LongSupplier与BooleanSupplier等
(3)、Predicate(判断型):
1)、源码:
@FunctionalInterface public interface Predicate<T> { boolean test(T t); default Predicate<T> and(Predicate<? super T> other) { Objects.requireNonNull(other); return (t) -> test(t) && other.test(t); } default Predicate<T> negate() { return (t) -> !test(t); } default Predicate<T> or(Predicate<? super T> other) { Objects.requireNonNull(other); return (t) -> test(t) || other.test(t); } static <T> Predicate<T> isEqual(Object targetRef) { return (null == targetRef) ? Objects::isNull : object -> targetRef.equals(object); } }
2)、使用:
Predicate对应抽象方法:test
Predicate<Integer> predicate=i->i>5;
System.out.println(predicate.test(1));
3)、Predicate总结:
Predicate是一个判断型的接口,用一个test方法去测试传入的参数。
当然,Predicate也有对应的变种。
(4)、Function(转换型):
1)、源码:
@FunctionalInterface public interface Function<T, R> { R apply(T t); default <V> Function<V, R> compose(Function<? super V, ? extends T> before) { Objects.requireNonNull(before); return (V v) -> apply(before.apply(v)); } default <V> Function<T, V> andThen(Function<? super R, ? extends V> after) { Objects.requireNonNull(after); return (T t) -> after.apply(apply(t)); } static <T> Function<T, T> identity() { return t -> t; } }
2)、使用:
Function对应抽象方法:apply
List<Student> list= Arrays.asList(new Student("jack",1),new Student("tom",2)); Function<Student,Integer> function= Student::getId; list.stream().map(function).forEach(System.out::print);
3)、Function总结:
Function是一个转换型的接口,其中的apply可以将一种类型的数据转化成另外一种类型的数据。
Function的变种就更多了。
四、List集合操作:
1、遍历List集合:
/** * 1、遍历List集合 * 注:避免空指针异常 * */ public static void demo01(){ UserVO vo = new UserVO(1,"a",null); List<UserVO> list = new ArrayList<>(); list.add(vo); //一、过滤集合为空情况,二、过滤group为空的情况 Optional.ofNullable(list).ifPresent(p -> { p.stream().filter(pi -> !ObjectUtils.isEmpty(pi.getGroup())).forEach(po -> { System.out.println("a".equals(po.getGroup())); }); }); //三、List中取出指定字段等于指定值的对象 UserVO userVO = list.stream().filter(pi -> !ObjectUtils.isEmpty(pi.getUuid())) .filter(pi -> pi.getUuid().equals(1)) .findFirst().orElse(null); System.out.printf("结果:"+userVO); }
2、List集合转Map<k,T>集合:
/** * 2、List集合转Map<k,T>集合 * */ public static void demo02(){ UserVO vo = new UserVO(1,"a",null); UserVO vo1 = new UserVO(1,"b",null); UserVO vo2 = new UserVO(1,"c",null); UserVO vo3 = new UserVO(2,"a",null); UserVO vo4 = new UserVO(3,"b",null); List<UserVO> list = new ArrayList<>(); list.add(vo); list.add(vo1); list.add(vo2); list.add(vo3); list.add(vo4); //uuid为key,UserVO为value //(k1,k2)->k1 如果有重复的key,则保留第一个 //(k1,k2)->k2 如果有重复的key,则保留最后一个 Map<Integer , UserVO> map1 = list.stream().collect(Collectors.toMap(UserVO::getUuid, p -> p, (k1,k2) -> k1)); Optional.ofNullable(map1.get(1)).ifPresent(p -> { System.out.println(p.getName()); }); }
3、List集合转Map<k,List<T>>集合:
/** * 3、List集合转Map<k,List<T>>集合 * */ public static void demo03(){ UserVO vo = new UserVO(1,"a",null); UserVO vo1 = new UserVO(1,"b",null); UserVO vo2 = new UserVO(1,"c",null); UserVO vo3 = new UserVO(2,"a",null); UserVO vo4 = new UserVO(3,"b",null); List<UserVO> list = new ArrayList<>(); list.add(vo); list.add(vo1); list.add(vo2); list.add(vo3); list.add(vo4); //groupingBy:分组 Map<Integer , List<UserVO>> map = list.stream().collect(Collectors.groupingBy(UserVO::getUuid)); Optional.ofNullable(map.get(1)).ifPresent(p -> { p.stream().forEach(po -> { System.out.println(po.getName()); }); }); }
4、List集合全部/部分复制到另一个List集合:
/** * 4、List集合全部/部分复制到另一个List集合 * 注: * (1)、list集合的全部内容复制到list1集合中 * (2)、list集合中部分(uuid与name)字段的全部内容复制到list2集合中 * (3)、list集合的截取部分内容复制到list3集合中 * */ public static void demo04(){ List<UserVO> list = new ArrayList<>(); List<UserVO> list1 = new ArrayList<>(); List<UserVO> list2 = new ArrayList<>(); List<UserVO> list3 = new ArrayList<>(); UserVO vo = new UserVO(1,"a",null); UserVO vo1 = new UserVO(1,"b",null); UserVO vo2 = new UserVO(1,"c",null); UserVO vo3 = new UserVO(2,"a",null); UserVO vo4 = new UserVO(3,"b",null); list.add(vo); list.add(vo1); list.add(vo2); list.add(vo3); list.add(vo4); //一、list集合的全部内容复制到list1集合中 list1.addAll(list); //二、list集合中部分(uuid与name)字段的全部内容复制到list2集合中 list2 = list.stream().map(p -> new UserVO(p.getUuid(),p.getName())).collect(Collectors.toList()); System.out.println(list2); //三、list集合的截取部分内容复制到list3集合中 list3.addAll(list.subList(0 , 2)); System.out.println(list3); }
5、List集合中根据对象某属性进行计算(求和、最大值与最小值):
/** * 5、List集合中根据对象某属性进行计算(求和、最大值与最小值) * 注: * (1)、对list集合UserVO对象中uuid字段求和 * (2)、对list集合UserVO对象中uuid字段求最大值 * (3)、对list集合UserVO对象中uuid字段求最小值 * (4)、整合操作 * Comparator:比较器 * */ public static void demo05(){ List<UserVO> list = new ArrayList<>(); UserVO vo = new UserVO(1,"a",null); UserVO vo1 = new UserVO(1,"b",null); UserVO vo2 = new UserVO(1,"c",null); UserVO vo3 = new UserVO(2,"a",null); UserVO vo4 = new UserVO(3,"b",null); list.add(vo); list.add(vo1); list.add(vo2); list.add(vo3); list.add(vo4); //一、对list集合UserVO对象中uuid字段求和 Integer sumVO = list.stream().mapToInt(UserVO::getUuid).sum(); System.out.println(sumVO); //二、对list集合UserVO对象中uuid字段求最大值 Integer maxVO = list.stream().max(Comparator.comparing(UserVO::getUuid)).get().getUuid(); System.out.println(maxVO); //三、对list集合UserVO对象中uuid字段求最小值 Integer minVO = list.stream().min(Comparator.comparing(UserVO::getUuid)).get().getUuid(); System.out.println(minVO); //四、List集合中根据对象某属性进行计算 IntSummaryStatistics cal = list.stream().collect(Collectors.summarizingInt(UserVO::getUuid)); System.out.println("总和"+cal.getSum()); System.out.println("最大"+cal.getMax()); System.out.println("最小"+cal.getMin()); System.out.println("平均"+cal.getAverage()); System.out.println("计数"+cal.getCount()); }
6、List集合转Map<k,List<T>>集合再进行遍历:
/** * 6、List集合转Map<k,List<T>>集合再进行遍历 * */ public static void demo06(){ UserVO vo = new UserVO(1,"a",null); UserVO vo1 = new UserVO(1,"b",null); UserVO vo2 = new UserVO(1,"c",null); UserVO vo3 = new UserVO(2,"a",null); UserVO vo4 = new UserVO(3,"b",null); List<UserVO> list = new ArrayList<>(); list.add(vo); list.add(vo1); list.add(vo2); list.add(vo3); list.add(vo4); //groupingBy:分组 Map<Integer , List<UserVO>> map = list.stream().collect(Collectors.groupingBy(UserVO::getUuid)); if(!ObjectUtils.isEmpty(map)) { Set<Map.Entry<Integer , List<UserVO>>> en = map.entrySet(); for (Map.Entry<Integer , List<UserVO>> entry : en) { //获取KEY值 Integer key = entry.getKey(); //获取VALUE值 List<UserVO> userVOList = entry.getValue(); System.out.println("KEY值:"+key+",VALUE值:"+userVOList); } } }
注:
//List<Integer> intList = Lists.newArrayList(1, 2, 3, 4, 5, 6, 7, 8); //Map<Integer, List<Integer>> groups = intList.stream().collect(Collectors.groupingBy(s -> (s - 1) / 3)); //List<List<Integer>> subSets = new ArrayList<List<Integer>>(groups.values());
五、属性转换:
1、相同属性值的对象复制:
BeanUtils.copyProperties(对象A,对象B);
注:浅拷贝
(1)、说明:
将两个字段相同的对象进行属性值的复制。如果 两个对象之间存在名称不相同的属性,则 BeanUtils 不对这些属性进行处理,需要程序手动处理。
(2)、org.springframework.beans.BeanUtils类的方法:
1)、相同属性进行全量复制
//a对象拷贝到b对象 BeanUtils.copyProperties(a.toString(), b.toString());
2)、过滤属性值为空的相同属性进行复制
BeanUtils.copyProperties(a.toString(), b.toString(), getNullPropertyNames(a));
注:
public static String[] getNullPropertyNames (Object source) { final BeanWrapper src = new BeanWrapperImpl(source); PropertyDescriptor[] pds = src.getPropertyDescriptors(); Set<String> emptyNames = new HashSet<>(); for(PropertyDescriptor pd : pds) { Object srcValue = src.getPropertyValue(pd.getName()); // 值为NULL的参数 if (srcValue == null) { emptyNames.add(pd.getName()); } } String[] result = new String[emptyNames.size()]; return emptyNames.toArray(result); }
(3)、 org.apache.commons.beanutils.BeanUtils类的方法:
//b对象拷贝到a对象 BeanUtils.copyProperties(a, b);
2、Object对象转Map:
/** * Object转map * * */ public static Map<String,Object> objToMap(Object obj){ Map<String,Object> map=new LinkedHashMap<>(); Field[] fields = obj.getClass().getDeclaredFields(); for(Field field:fields){ field.setAccessible(true); try { map.put(field.getName(), field.get(obj)); } catch (IllegalAccessException e) { throw new IllegalArgumentException("属性转换失败。"+ e); } } return map; }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号