MYSQL基础学习笔记
千里之行,始于足下
正文
关系型数据库与非关系型数据库
1、关系型数据库(SQL):主要依据“一对一、一对多、多对多”等关系模型来创建的数据库。
2、非关系型数据库(NoSQL):主要是基于“列模型、键值对模型、文档类模型”等非关系模型的数据库。
MySQL服务端的登录、退出与使用:
1、登录:mysql –h 主机名 –u用户名 –p密码
2、退出:exit
3、使用:
(1)、进入mysql,在命令行中输入:mysql –uroot –p密码
(2)、查看mysql中有哪些个数据库:show databases;
(3)、使用一个数据库:use 数据库名称;
(4)、新建一个数据库:CREATE DATABASE IF NOT EXISTS 数据库名
(5)、查看指定的数据库中有哪些数据表:show tables;
(6)、建表:CREATE TABLE [IF NOT EXISTS] t_表名{字段名1 数据类型 [约束] , .... }
(7)、查看表的结构:desc 表名
(8)、清空表(不能回滚):TRUNCATE TABLE 表名
(9)、删除表:DROP TABLE [IF EXISTS] 数据表1 [, 数据表2, …, 数据表n];
(10)、删除数据库:DROP DATABASE IF EXISTS 数据库名;
注:mysql不区分大小写
SQL语句的分类
1、DQL(数据查询语言):
select语句
语法:
(1)、查询:
select <字段名> [as 别名] from <表或视图名>( join <表名> on <连接条件> )
where <查询条件> group by <分组字段> having <额外添加字段条件>
order by <字段名(升序asc / 降序desc)> limit( startIndex ,length );
2、DML(数据操作语言):
insert、update、delete语句
语法:
(2)、新增:
insert into t_表名 (字段名1,字段名2...) values (值1,值2...);
(3)、修改:
update t_表名 set 字段名1 = 值1 ,字段名2 = 值2 ...where 条件;
(3)、删除:
delete from t_表名 where 条件;
3、DDL(数据定义语言):
drop、create、alter
语法:
(1)、创建:
create tables IF NOT EXISTS t_表名{字段名1 数据类型 [约束], 字段名2 数据类型 [约束] .... };
(2)、删除:
drop table IF EXISTS t_表名;
4、TCL(事物控制语言):
事务提交commit,事务回滚rollback
5、DCL(数据控制语言):
grant授权,revoke撤销权限
SQL的基本使用:
一、基本的SELECT语句的使用:
1、使用关键字DISTINCT去除重复行:
SELECT DISTINCT name FROM t_users;
2、空处理函数IFNULL(expr1,expr2)过滤参与运算字段:
所有数据库规定只要有null参与的运算结果都为null;
IFNULL(expr1,expr2):若expr1不是NULL,IFNULL()返回expr1,否则它返回expr2;
SELECT IFNULL(t_users.number,1) FROM t_users;
3、着重号(` `)解决冲突:
保证表中的字段、表名等没有和保留字、数据库系统名或常用方法名冲突
SELECT * FROM `STUDENT`;
4、LEAST(值1,值2,...,值n)
两个或多个参数的情况下,返回最小值
5、GREATEST(值1,值2,...,值n)
两个或多个参数时,返回值为最大值。假如任意一个自变量为NULL,则GREATEST()的返回值为NULL
二、WHERE子句的操作符:
|
= |
等于 |
|
<>(!=) |
不等于 |
|
> |
大于 |
|
>= |
大于等于 |
|
< |
小于 |
|
<= |
小于等于 |
|
between A and B |
在指定的两个值之间(包含边界) |
|
is null (is not null) |
空值(非空) |
|
like(not like) |
模糊查询: 1、%代表零个或多个字符(任意个字符) 2、_代表一个字符 |
|
in |
等于值列表中的一个 |
|
and |
逻辑并 |
|
or |
逻辑或 |
|
not in |
逻辑否 |
三、WHERE子句中使用正则表达式(REGEXP)查询:
1、查询以特定字符或字符串开头的记录:‘^’
在t_user表中,查询name字段以字母‘a’开头的记录
SELECT * FROM t_user WHERE name REGEXP '^a';
2、查询以特定字符或字符串结尾的记录:‘$’
在t_user表中,查询name字段以字母‘z’结尾的记录
SELECT * FROM t_user WHERE name REGEXP 'z$';
3、替代字符串中的任意一个字符: "."
在t_user表中,查询name字段值包含字母‘a’与‘z’且两个字母之间只有一个字母的记录
SELECT * FROM t_user WHERE name REGEXP 'a.z';
四、函数的使用:
MySQL常使用的函数大概有四类:时间函数、数学函数、字符函数、控制函数。参考
注:
1、分组函数:count()、avg()、sum()、max()、min()
2、分组函数不能在where后面执行:分组函数通常与group by一起使用,在group by后面执行,而group by是在where后面执行的
五、连接查询的方式
1、内连接inner join on(无主副之分):等值连接、非等值连接、自连接
2、外连接(有主副之分):
(1)、left join on:左外连接(左边主表)、
(2)、right join on:右外连接(右边主表)
3、全连接full join on
4、合并查询结果
(1)、去除重复记录:UNION关键字
(2)、不去除重复记录:UNION ALL关键字
SELECT name,... FROM t_table1 UNION SELECT name,... FROM t_table2
5、SQL99语法新特性
(1)、自然连接NATURAL join :自动查询两张连接表中所有相同的字段
SELECT id, name FROM employees e NATURAL JOIN departments d;
(2)、JOIN...USING:指定数据表里的具体同名字段进行等值连接
SELECT employee_id, department_name FROM employees e JOIN departments d USING (department_id);
六、建表常用的数据类型
|
类型 |
描述 |
|
CHAR(长度) |
定长字符串,存储空间大小固定,适合作为 主键或外键 |
|
VACHAR(指定长度) |
变长字符串,存储空间等于实际数据空间 |
|
DOUBLIE(有效数字位数,小数位) |
数值型 |
|
FLOAT(有效数字位数,小数位) |
数值型 |
|
INT(或INTEGER) (长度) |
整型 |
|
BIGINT(长度) |
长整型 |
|
DECIMAL |
定点数类型 |
|
DATE |
日期型 年月日(格式'YYYY-MM-DD') |
|
DATETIME |
日期型 年月日 时分秒 毫秒 |
|
TIME |
日期型 时分秒 |
|
BLOB |
Binary Large OBject(二进制大对象) |
|
CLOB |
Character Large OBject(字符大对象) |
|
其它…… |
|
七、SQL表中常见约束
1、非空约束(not null):规定某个字段不能为空
2、唯一约束(unique):同一个表可以有多个唯一约束。
3、主键约束(primary key):相当于唯一约束与非空约束的组合,不允许为空,每个表有且最多只允许一个主键约束;
4、外键约束(foreign key):构建于一个表的两个字段或是两个表的两个字段之间的参照关系,保证一个或两个表之间的参照完整性;
5、检查约束(check):MySQL 不支持 check 约束,但可以使用 check 约束,而没有任何效果;
6、缺省约束(Default):在插入数据时某列如果没指定其他的值,那么会将默认值添加到新记录。
7、解释字段(COMMENT):没有任何实际含义,专门用来解释字段的含义
事务的理解与事务的四大特性:
1、事务:
一组完整的DML业务逻辑单元
2、特性:
原子性、一致性、隔离性、持久性
(1)、原子性(Atomicity)
原子性是指事务是一个不可分割的工作单位,事务中的操作要么都成功,要么都失败。
(2)、一致性(Consistency)
事务必须使数据库从一个一致性状态变换到另外一个一致性状态。
(3)、隔离性(Isolation)
事务的隔离性是指一个事务的执行不能被其他事务干扰,即一个事务内部的操作及使用的数据对并发的其他事务是隔离的,并发执行的各个事务之间不能互相干扰。
(4)、持久性(Durability)
持久性是指一个事务一旦被提交,它对数据库中数据的改变就是永久性的,接下来的其他操作和数据库故障不应该对其有任何影响。
3、四大隔离级别:
读未提交——READ UNCOMMITED、读已提交(Oracle默认)——READ COMMITED、
可重复读(MySQL默认)——REPEATABLE READ、串行化读——SERIALZABLE
(1)、查看当前的隔离级别:
SELECT @@tx_isolation;
(2)、设置当前 mySQL 连接的隔离级别:
set transaction isolation level 隔离级别;
(3)、设置数据库系统的全局的隔离级别:
set global transaction isolation level 隔离级别;
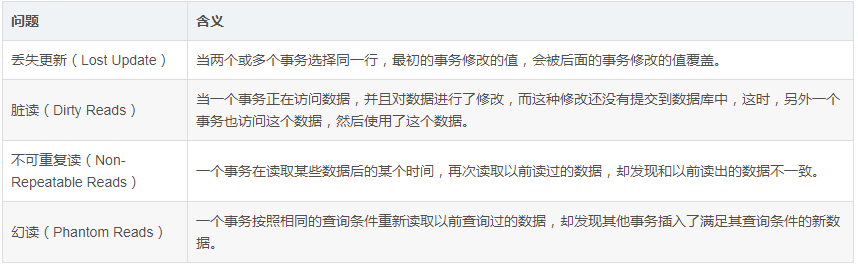
4、并发事务处理带来的问题:
更新丢失,脏读,不可重复读,幻读
视图:
1、视图是一个虚拟表(非真实存在),其本质是根据SQL语句获取动态的数据集,并为其命名,用户使用时只需使用名称即可获取结果集,并可以将其当作表来使用。
2、视图可以提高检索效率,隐藏表的实现细节,只对视图对象进行CRUD操作,保护数据,提高安全性;
(1)、创建视图:
create view 视图名 as select语句;
(2)、删除视图:
drop view if exists 视图名;
存储过程/存储函数/游标/触发器:
1、理解:
存储过程是一个预先编译过SQL语句的代码块,存储过程可以设置用户的操作权限,具有较强的安全性,并且每次使用时只需要调用存储过程,降低网络的通信量,提高通信速率,但存储过程的编码复杂度更高,可移植性较差,调试困难,不适合高并发的场景,只能说,针对某些项目比较好用。(阿里开发规范强制禁止使用)。
2、语法:

DELIMITER 新的结束标记符 #可省 CREATE PROCEDURE 存储过程名( IN | OUT | INOUT 参数名 参数类型,...) [characteristics ...] BEGIN 存储过程体 END 新的结束标记符 DELIMITER ;#恢复默认结束符
注:
(1)、参数
1)、IN :表示输入参数。
2)、OUT :表示输出参数。
3)、INOUT :表示当前参数既可以为输入参数,也可以为输出参数。
(2)、characteristics包括
1)、LANGUAGE SQL:表示当前系统支持的语言为SQL。
2)、{ DETERMINISTIC | NOT DETERMINISTIC }:
DETERMINISTIC:表示相同的输入会得到相同的输出。
NOT DETERMINISTIC:表示相同的输入可能得到不同的输出。
3)、{ CONTAINS SQL | NO SQL | READS SQL DATA | MODIFIES SQL DATA } :指明子程序使用SQL语句的限制。
CONTAINS SQL:表示当前存储过程的子程序包含SQL语句,但是并不包含读写数据的SQL语句;
NO SQL:表示当前存储过程的子程序中不包含任何SQL语句;
READS SQL DATA:表示当前存储过程的子程序中包含读数据的SQL语句;
MODIFIES SQL DATA:表示当前存储过程的子程序中包含写数据的SQL语句。
4)、SQL SECURITY { DEFINER | INVOKER } :执行当前存储过程的权限,即指明哪些用户能够执行当前存储过程。
DEFINER:表示只有当前存储过程的创建者或者定义者才能执行当前存储过程;
INVOKER:表示拥有当前存储过程的访问权限的用户能够执行当前存储过程。
5)、COMMENT '输入的字符串'
(3)、存储过程体
中间包含了多个语句,每个语句都以分号作为结束符。
1)、DECLARE:声明变量
2)、SET:对变量进行赋值。
3)、SELECT… INTO:把从数据表中查询的结果存放到变量中,也就是为变量赋值。
3、案例:
(1)、查看最高工资:
CREATE PROCEDURE show_max_salary() LANGUAGE SQL NOT DETERMINISTIC CONTAINS SQL SQL SECURITY DEFINER COMMENT '查看最高薪资' BEGIN SELECT MAX(salary) FROM emps; END // DELIMITER ;
(2)、将最低薪资通过OUT参数“ms”输出:
DELIMITER // CREATE PROCEDURE show_min_salary(OUT ms DOUBLE) BEGIN SELECT MIN(salary) INTO ms FROM emps; END // DELIMITER ;
(3)、实现累加运算,计算 1+2+…+n:
DELIMITER // CREATE PROCEDURE `add_num`(IN n INT) BEGIN DECLARE i INT; DECLARE sum INT; SET i = 1; SET sum = 0; WHILE i <= n DO SET sum = sum + i; SET i = i +1; END WHILE; SELECT sum; END // DELIMITER ;
4、调用格式:
CALL 存储过程名(实参列表)
(1)、调用in模式的参数:
CALL add_num ('值');
(2)、调用out模式的参数:
SET @ms; CALL show_min_salary (@ms); SELECT @ ms;
(3)、调用inout模式的参数:
SET @name=值; CALL sp1(@name); SELECT @name;
注:
MySQL中的系统变量以两个“@”开头,用户变量以一个“@”开头
5、存储函数:
(1)、语法:
CREATE FUNCTION 函数名(参数名 参数类型,...) RETURNS 返回值类型 [characteristics ...] BEGIN RETURN (函数体) #函数体中肯定有 RETURN 语句 END
(2)、对比:
|
|
关键字 |
调用语法 |
返回值 |
|
存储过程 |
PROCEDURE |
CALL存储过程() |
有0个或多个 |
|
存储函数 |
FUNCTION |
SELECT函数() |
只能是一个 |
6、游标:
(1)、理解:
对结果集中的每一条记录进行定位,充当指针的作用,mysql中游标只适用于存储过程以及函数。
(2)、语法:
1)、定义游标:
declare 游标名 cursor for select语句;
2)、打开游标:
open 游标名;
3)、获取结果:
fetch 游标名 into 变量名[,变量名];
4)、关闭游标:
close 游标名;
7、触发器:
确保操作的原子性(要么全部成功,要么全部失败),但存在最大问题是可读性差。
(1)、语法:
CREATE TRIGGER 触发器名称 { BEFORE(注:事件前触发)| AFTER(注:事件后触发)} {INSERT | UPDATE | DELETE触发事件} ON 表名 FOR EACH ROW 触发器执行的语句块;
Mysql的流程控制结构——实现多分支
1、case结构
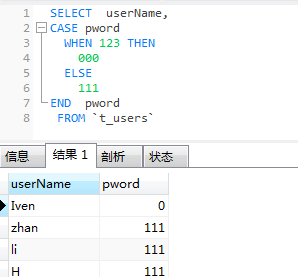
(1)、语法一:
case 表达式或字段 when 值1 then 语句1 when 值2 then 语句2 … else 语句n end [case]
(2)、语法二:
case when 条件1 then 语句1 when 条件2 then 语句2 … else 语句n end [case]
2、if结构
语法一:
if(条件表达式,表达式1,表达式2);
如果条件表达式成立,返回表达式1,否则返回表达式2
语法二(存储过程中使用):
if 条件1 then 语句1; elseif 条件2 then 语句2; … else 语句n; end if;
3、循环结构(存储过程中使用)
(1)、while: 类似java中的while循环
语法格式:
【名称】 while 循环条件 do 循环体; end while 【名称】;
(2)、loop :需要在循环体中添加结束的条件,不然就是死循环。
语法格式:
【名称】 loop 循环体; end loop 【名称】;
(3)、repeat:类似java中的do while
语法格式:
【名称】 repeat 循环体; until 结束循环的条件 end repeat 【名称】;
注:
循环控制语句:
1)、iterate关键字:类似于java中的continue,结束本次循环,继续下一次循环。
2)、leave关键字:类似于java中的break,跳出循环,执行之后的语句。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· winform 绘制太阳,地球,月球 运作规律
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人