
自编码算法与稀疏性
前一章神经网络是有监督学习的,自编码神经网络是无监督学习的,使用反向传播算法,让目标值=输入值。
1)隐藏层单元数少
迫使神经网络进行数据压缩,找到有趣的结构,与PCA相似
做法和普通神经网络一样,只是y=x
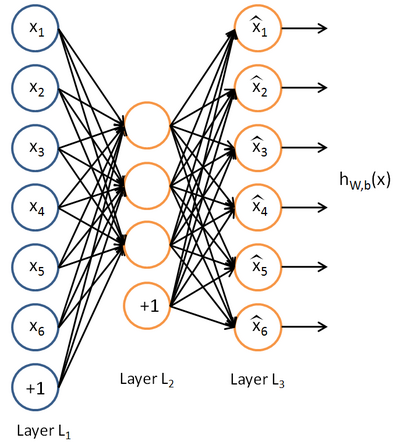
2)隐藏层单元数多
给隐藏层加入稀疏性限制 - 对sigmoid函数来说,输出接近1为激活,输出接近0为抑制 - 要让神经元大部分时间被抑制
![\begin{align}
\hat\rho_j = \frac{1}{m} \sum_{i=1}^m \left[ a^{(2)}_j(x^{(i)}) \right]
\end{align}](http://ufldl.stanford.edu/wiki/images/math/8/7/2/8728009d101b17918c7ef40a6b1d34bb.png) 表示隐藏层神经单元的平均激活度
表示隐藏层神经单元的平均激活度
限制条件: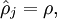 ρ是稀疏性参数,通常是接近0的小数(0.05之类的)
ρ是稀疏性参数,通常是接近0的小数(0.05之类的)
==> 为了实现限制,在优化函数中额外加入惩罚因子 - 当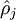 和ρ有显著不同将得到惩罚
和ρ有显著不同将得到惩罚
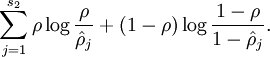 等于
等于 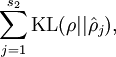 (基于相对熵KL提出的)
(基于相对熵KL提出的)
==> 总体代价函数
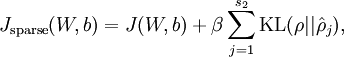 β为控制惩罚因子的权重
β为控制惩罚因子的权重
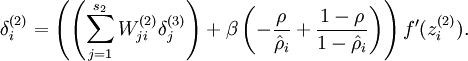
剩下的地方不变,仍然是梯度下降法。
--------------------------------------------------
(* "・∀・)ノ ------◎ 去吧!大师球!!


 浙公网安备 33010602011771号
浙公网安备 33010602011771号